
회사 업무를 하던 중 속도 개선 건을 맡게되었다..🥲
하나 하나 다 이해하고 작업해야 하는 속도 개선 건이 조금은 싫지만..
이번 건은 꽤 간단하게 해결할 수 있었어서 해결 방법을 간략하게 정리해 보겠습니다!
우선, 간략하게 로직 먼저 알려드리자면
권한 설정을 하는 기능에서 사원 여러 명을 선택한 후, 권한을 일괄 등록하는 기능을 구현하였습니다.
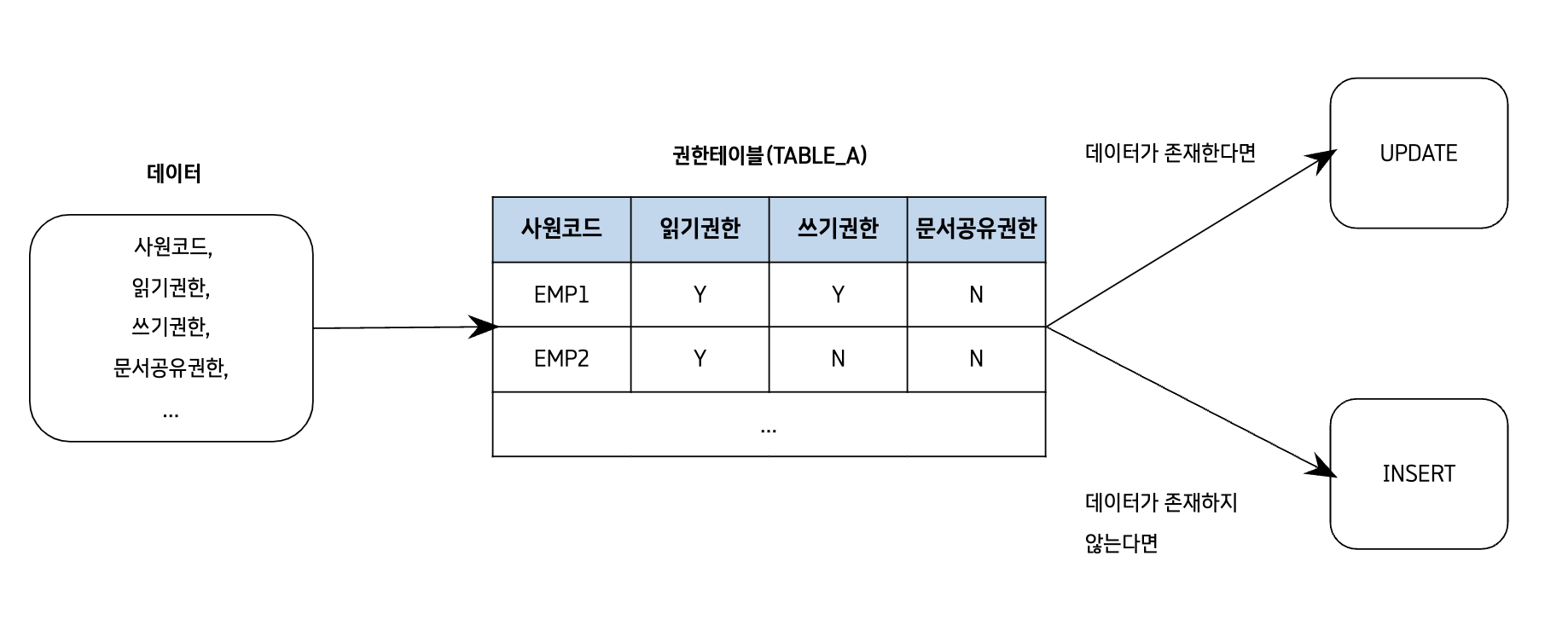
- 사원정보를 넘겨받고
- 해당 사원이 권한 관리테이블 (이하 Table A) 에 존재하는지 확인
- 존재한다면 Table A에 UPDATE / 존재하지 않는다면 Table A에 INSERT
✅ 기존 로직
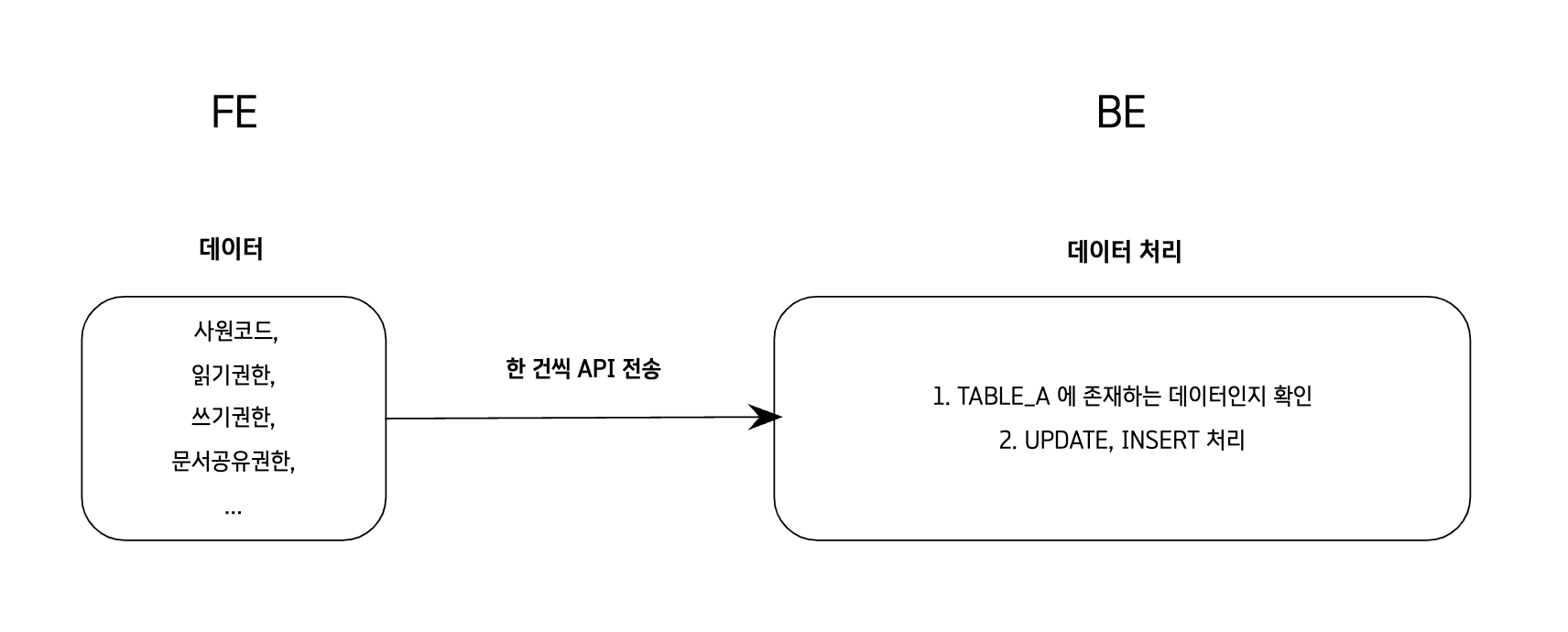
사원정보(ex/5000명)를 한 건씩 API를 호출하여 존재하는지 확인하고
UPDATE or INSERT 처리
- 문제점
사원 정보가 늘어나면 늘어날수록 속도 저하가 심해짐
✅ 개선방안
- 개선방안 1
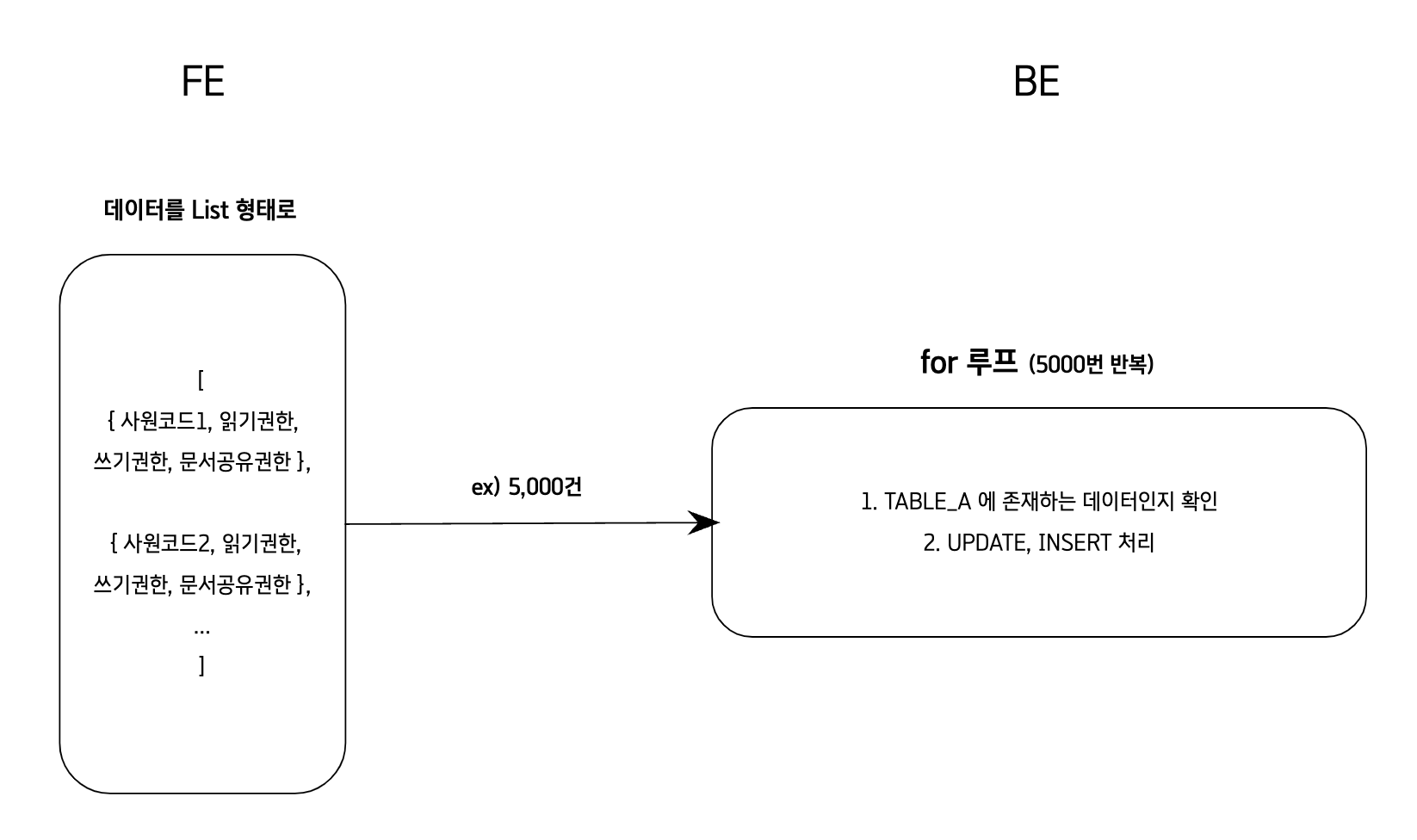
- 사원정보(ex/5000명)을 List 형태로 한 번에 넘겨서
- for문을 돌면서 한 건씩 권한 확인
- 확인 후 UPDATE or INSERT 처리
- 개선방안 2
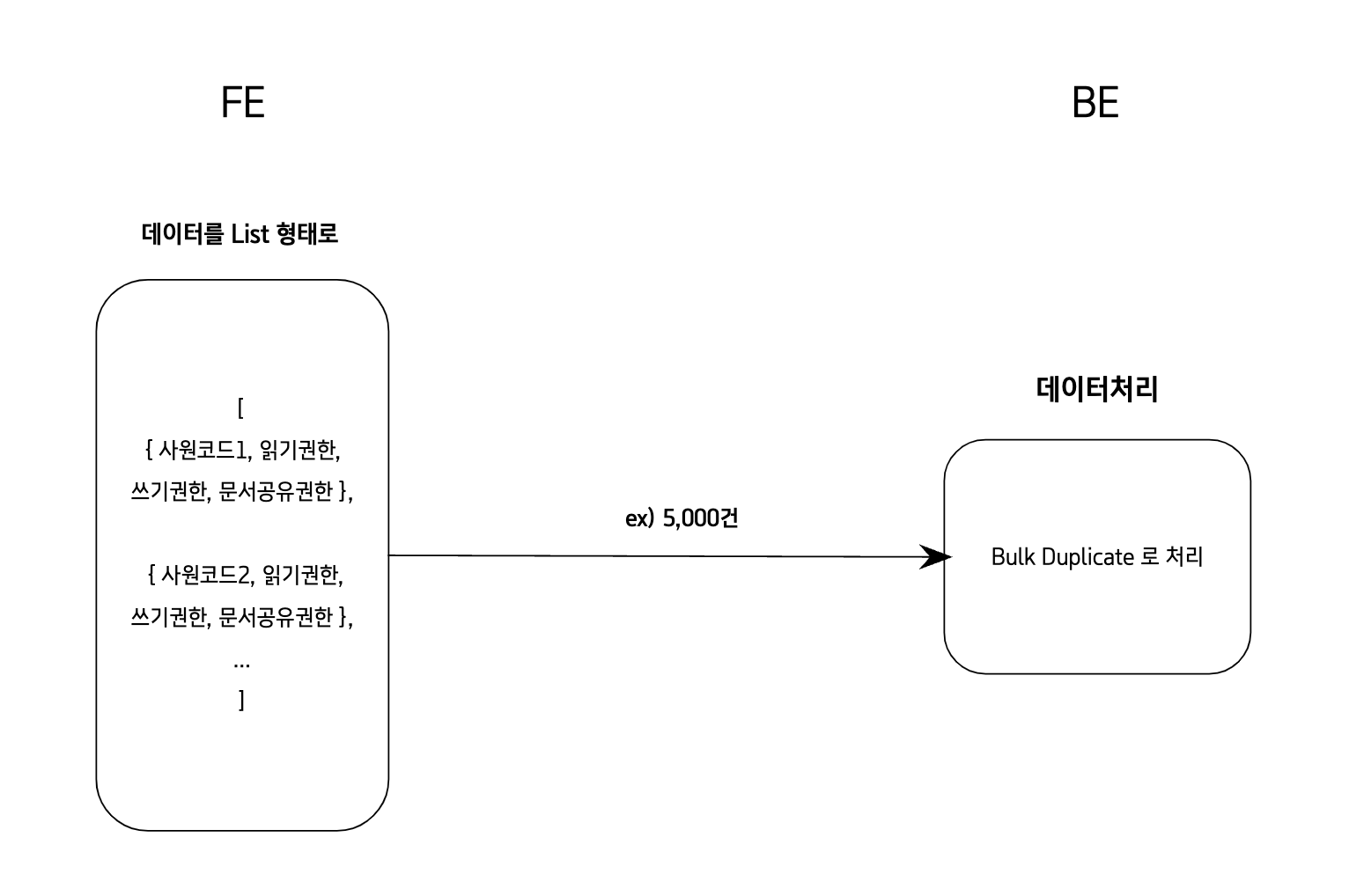
- 사원정보(ex/5000명)을 List 형태로 한 번에 넘겨서
Bulk Duplicate사용하여 한 번에 처리 (Bulk Duplicate 가 올바른 용어인지는 잘 모르겠습니다..ㅎ)
✅ 사용한 해결방법
개선방안 2번으로 해결을 하였습니다.
<!--
empList: 사원코드, 권한정보들이 담긴 데이터
-->
INSERT INTO TABLE_A
(
<!--
INSERT or UPDATE 할 컬럼,
여기 있는 컬럼들과 UPDATE문에 해당하는 부분에서 차이가 나는 컬럼이 해당 테이블에 식별자가 되어 테이블에 동일한 데이터가 존재한다면 UPDATE
존재하지 않는다면 INSERT 하게 됩니다!
이 예시에서는 EMPLOYEE_CODE가 식별자가 됨
-->
EMPLOYEE_CODE,
A1,
A2,
A3,
A4,
A5
)
VALUES
<foreach collection="empList" item="item" separator=",">
(
#{item.empCode},
#{a1},
#{a2},
#{a3},
#{a4},
#{a5}
)
</foreach>
ON DUPLICATE KEY UPDATE
<!-- TABLE_A에 동일한 값(사원코드)이 존재할 때 UPDATE 하는 부분 -->
A1 = #{a1}
A2 = #{a2}
A3 = #{a3}
A4 = #{a4}
A5 = #{a5}사원수를 6000명 정도로 했을 때 위 방법으로도 시간이 많이 단축되었지만
다른 방법이 있나 찾다보니 1,000건, 10,000건 이상정도 되는 데이터를 Bulk INSERT 할 때는 일정 건수로 분할하여 삽입 하는 방법도 있다고 하더라고요
그래서 최종 해결방안은 !
✅ 500건씩 쪼개서 Bulk Duplicate 하는 방법
- batchSize 만큼 쪼갠 후, 배열로 리턴해주는 메서드
public <T> List<List<T>> partitionList(List<T> list, int batchSize) {
List<List<T>> partitions = new ArrayList<>();
for (int i = 0; i < list.size(); i += batchSize) {
int endIndex = Math.min(i + batchSize, list.size());
partitions.add(list.subList(i, endIndex));
}
return partitions;
}- 500건 이상일 때 아래처럼 처리
// param.getList() -> 사원리스트 로 수정
// RSelectEmp -> 사원정보를 담은 모델 클래스
// 사원리스트가 500건 이상일 때 | 500개 쪼개어 Bulk Duplicate
if(param.getList().size() > 500) {
List<List<RSelectEmp>> empList = this.partitionList(param.getList(), 500);
for(int i=0; i<empList.size(); i++) {
param.setList(empList.get(i));
mapper.bulkDuplicate(param);
}
} else {
mapper.bulkDuplicate(param);
}결과확인
| 코드 작성 방식 | 실행 시간 |
|---|---|
| 6000건 한 번에 처리 | 1.704s |
| 500건씩 나누어 처리 | 0.828s |
* 테스트결과는 컴퓨터 사양에 따라 달라질 수 있습니다.
* bulk insert를 이용하여 10,000건 이상 삽입 시 성능이 좋지 않을경우에는 위 방법처럼 일정 건수로 분할하여 삽입하거나 엑셀파일로 export한 후 DBMS에서 엑셀파일을 읽는 방식으로 진행하는 방안도 존재합니다.
이미지 출처
황정민아저씨 - https://www.digitaltoday.co.kr/news/articleView.html?idxno=69324

틀린 부분이나 궁금하신 점이 있으시다면 댓글 달아주시면 공부하겠습니다 !