관계형 데이터 베이스 _ like Excel
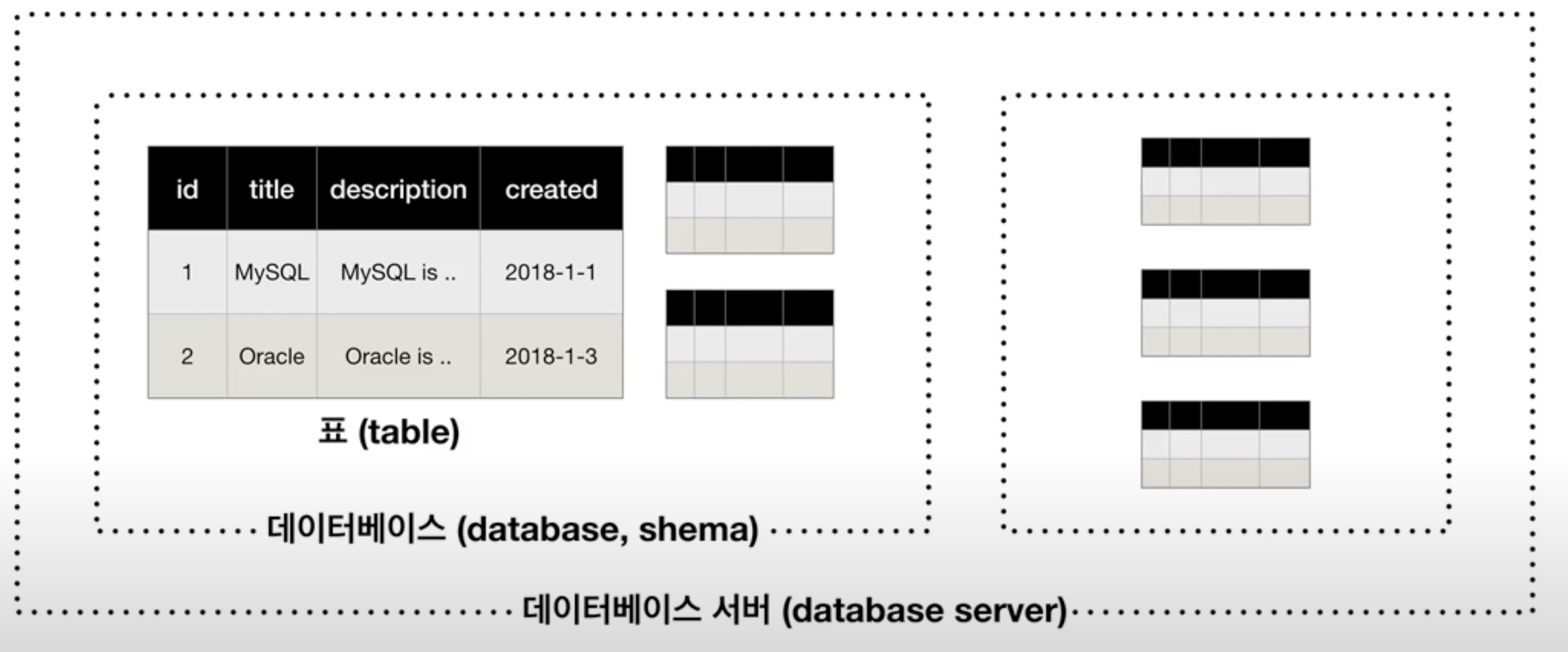
- column이 정해져 있는 것들..!!
- 데이터는 최종적으로 표(TABLE)로 구성되어진다.
- 서로 연관되어 있는 표(TABLE)들을 GROUP으로 묶은것이 DATABASE == SCHEMA이다.
- 이러한 SCHEMA가 모여있는 곳이 DATABASE SERVER라고 한다.
- 보안관리가 쉬워짐.
- root사용자는 모든 접근이 가능함.
SQL이란
- Structured Query Language
- row == record == 행
- column == data_type == 열
문법
- DATA_BASE(SCHEMA) 생성하기
CREATE DATABASE 'db_name' - DATA_BASE(SCHEMA) 삭제하기
DROP DATABASE 'db_name' - DATA_BASE(SCHEMA) 출력하기
SHOW DATABASES - TABLE(표) 사용하기
USE 'table_name'
DATA TYPE(m)
- m : data를 얼만큼 노출시킬 것인가 | 얼만큼 반영할 것인가
- 숫자 : INT, BIGINT,
- 조건 지정 : NULL(값이 없어도 OK), NOT NULL(값이 없으면 추가 X)
- 자동 증가 : AUTO_INCREMNET
- 문자 : VARCHAR, TEXT, LONGTEXT
- 시간 : DATE, DATETIME (데이터 삽입 시 NOW()함수와 자주 사용)
-HOUR(DATETIME) -> 시간
-YEAR(DATETIME) -> 년도
-MONTH(DATETIME)
-DAY(DATETIME)
-MINUTE(DATETIME)
-SECOND(DATETIME) - PK(Primary Key) : 테이블의 데이터를 구별할 수 있는 key(식별자)
CRUD
- Create, Read, Update, Delete
-
TABLE Column 만들기
CREATE TABLE 'table_name'('col_name' col_type Default(NULL_condition) Extra(AUTO_INCREMENT_데이터 추가시 자동으로 ++), PRIMARY KEY(id)
ex) CREATE TABLE topic( id INT(11) NOT NULL AUTO_INCREMENT, title VARCHAR(100) NOT NULL, description TEXT NULL, created DATETIME NOT NULL, PRIMARY KEY(id)); -
column 확인하기
DESC table_name -
column 추가하기
ALTER TABLE 'table_name'
ADD 'new_col' col_type Extra(FIRST, AFTER 'col_name', default = 맨뒤) -
row(data) 추가하기
INSERT INTO 'table_name' (col1, col2, col3) VALUES (data1, data2, data3); -
전체 데이터 확인하기
SELECT * FROM 'table_name; -
특정 데이터만 확인하기 (projection)
SELECT 'col1', 'col2' FROM 'table_name'; -
조건 설정하기
- 조건
WHERE 'condition(col == col_name)'-> AND OR NOT 연산가능
- 부분 조건
LIKE 'col' LIKE '문자%'
- 정렬
ORDER BY 'col_name' DESC|ASC
- 정렬이 여러개일 경우,,
SELECT 'col1', 'col2' From 'table_name' ORDER BY 'col1' DESC, 'col2'(DEFAULT)
- 제한
LIMIT 'Number'
- 제한 범위
LIMIT 3,10;-> 인덱스 시작이 0임 (4번째부터~11번째까지)
-최대값/최솟값
SELECT MAX('col') FROM 'table'; -
별칭 AS 로 바꾸기..
-
UPDATE 하기(수정하기)
UPDATE 'table_name' SET 'col_id' = "수정사항", 'col_id2' = "수정사항2" WHERE 'condition' -
DELETE 하기
DELETE FROM table_name WHERE 'condition'; -
중복제거하기 (컬럼에 중복되는 데이터들을 묶어준다) 주로 COUNT와 사용하여 Column에 나타냄
GROUP BY 'col_name' -
집계함수 조건비교
HAVING '집계결과' condition
중복되는 TABLE 분리하기
-
별도로 테이블을 나누게되면, 인덱스(KEY)를 활용하여 중복/동명이인을 막을 수 있지만 데이터를 참조할 때, 관계가 생기기 때문에 한눈에 보기 어려움 -> JOIN으로 해결
-
JOIN 하기
SELECT * FROM 'table1' LEFT JOIN 'table2' ON 'table1.col_id = table2.col_id';
*join시 col명이 겹치면 ambiguous하므로, table1.col_name으로 명시하여 projection하면 된다. -
Table 이름 변경하기
RENAME TABLE 'table_name' TO 'table_rename';
