내용보충 https://velog.io/@yoonee1126/Day37-%EB%AC%B4%EA%B2%B0%EC%84%B1%EC%A0%9C%EC%95%BD%EC%A1%B0%EA%B1%B4#%EC%9D%B8%EB%8D%B1%EC%8A%A4
인덱스
- 데이터의 위치를 나타내는 색인을 만들어 주는 것
- 도서의 맨 뒷페이지 '찾아보기'와 비슷
- 검색 시 데이터 전체가 아닌, index를 검색하게 되므로 속도가 빨라짐
- 테이블과 독립적
- select에서는 성능 향상에 도움을 주지만 update, delete, insert를 자주 사용할 경우 성능이 느려짐
- join이나 order by에 자주 사용되는 열은 index 사용 시 효율이 높아짐
B-tree 인덱스
- Leaf-Intermediate(Branch)-Root 순으로 생성되며, 탐색은 반대 순서로 실행
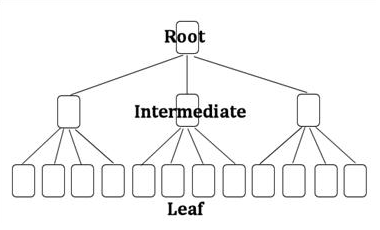
- 각 Block은 용량에 따로 자동 분할됨
- Root Block은 하나만 존재하며 데이터가 추가되어 블록이 2개가 되면 해당 Root Block은 Intermediate로 변경되고, 이를 요약한 새로운 RootBlock이 생성됨
Unique 인덱스
create unique index 인덱스명 on 테이블(컬럼)- 인덱스 내에 중복 데이터 없음
- 중복 데이터 Insert 불가
Non-Unique 인덱스
create index 인덱스명 on 테이블(컬럼)- 중복 데이터 가능
Function Based 인덱스 (함수기반 인덱스)
create unique index 인덱스명 on 테이블(가공된 컬럼)- 가공된 컬럼으로 생성 된 인덱스
- 컬럼이 연산자등으로 가공되면 해당 인덱스(연산자가 없을때 생성된 순수 인덱스)는 사용이 불가능하게 됨. 따라서 가공된 컬럼으로 인덱스 따로 생성
create index testidx on emp(pay*2)
-- 혹은 조회 시 where pay=100/2로 조회- 이 경우 가공된 컬럼의 조건이 바뀔 경우 사용불가. 인덱스 재생성 필요
Descending 인덱스
create [unique] index 인덱스명 on 테이블(컬럼 desc)- 값이 내림차순으로 정렬된 인덱스
Composite 인덱스 (결합 인덱스)
create index 인덱스명 on 테이블(컬럼1, 컬럼2)- 두 개 이상의 컬럼을 합쳐서 인덱스를 만드는 것
-- 인덱스의 실행
select 컬럼3
from 테이블
where 컬럼1="조건1"
and 컬럼2="조건2"Bitmap 인덱스
- 데이터값의 종류가 적고, 양이 많을 때 사용
성별: m, f
사원수: 10,000명
-> 데이터 수는 10,000개이지만 종류는 m,f 두개 뿐- 데이터가 존재하는 곳은 1, 아닌 곳은 0으로 표현
| 이름 | 성별 |
|---|---|
| 조진웅 | M |
| 허성태 | M |
| 장원영 | F |
| 이수혁 | M |
| 수지 | F |
M: 11010
F: 00101
- 데이터 값의 종류가 많으면 종류만큼 맵이 생성되고, 효율이 떨어짐
다루기
생성
create [bitmap|unique] index 인덱스명
on 테이블(컬럼 [desc])- 하나의 열 - 하나의 인덱스 또는 여러 열 - 하나의 인덱스 생성 가능(결합인덱스)
- Primary key 혹은 Unique key 지정 시 자동으로 생성 됨
삭제
drop index 인덱스명조회
- 생성된 인덱스 정보 조회하기
select *
from user_indexes;- 인덱스 적용여부 조회하기
- where절까지 삽입한 SQL문 선택 후 F10(계획설명)-Options에서 확인 가능

Index로 검색 했을 때

Index로 검색하지 않았을 때
