Contents
- Word2Vec
- Optmization basics
- GloVe
- Evaluating word vectors
- Word Senses
01. Word2Vec
Main idea of word2vec
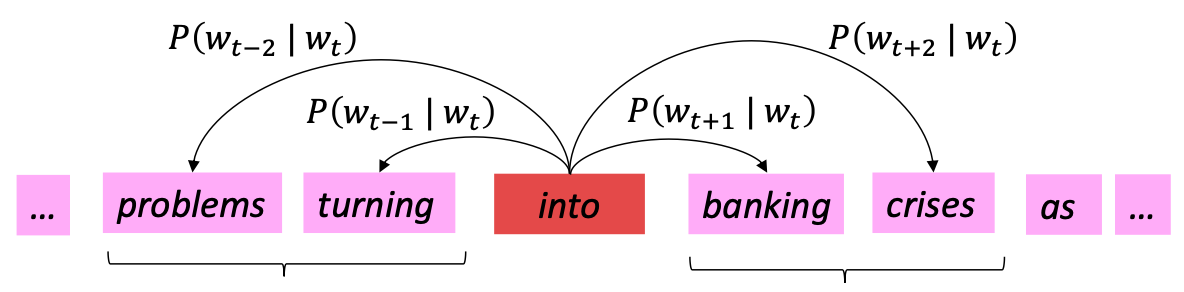
- 처음에는 임의의 word vectors를 부여
- center word(중심 단어)와 함께 어떤 단어가 출현하는지 확률값 예측
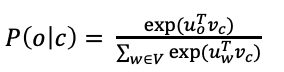
-> center word와 context word(주변 단어)의 내적 관점에서 확률값 계산
- Main idea: 주변 단어에 대한 예측 확률값을 높이도록 vectors를 update
즉, 위 그림에서 'into'라는 단어가 나올 때 'problems', 'turning', 'banking', 'crises' 라는 단어에 대한 확률을 높이는 것
위와 같은 간단한 알고리즘만으로 wordspace에서 단어 간 유사성과 의미를 잘 포착할 수 있다.
word2vec parameters and computations
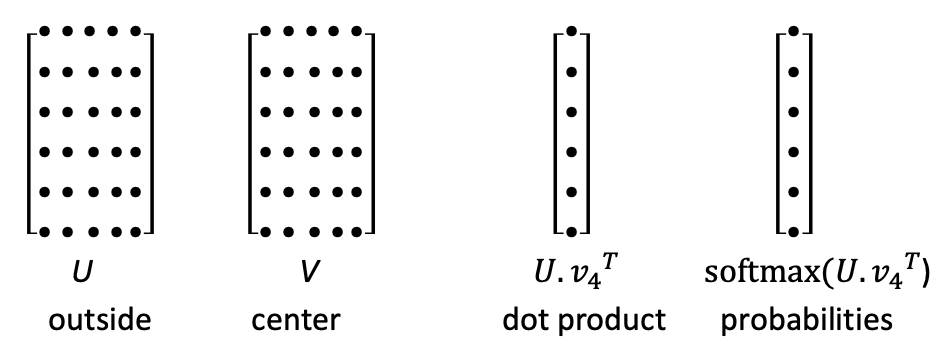
word2vec 모델의 parameter는 오직 word vector만 있음.
각 단어에 대해 outside vectors, center vectors가 존재.
outside words와 center word의 내적을 통해 함께 나타날 가능성에 대한 score를 구함.
score를 확률값으로 변환하기 위해 softmax 사용.
Bag of words model
- 단어의 순서나 위치를 고려하지 않음.
-> center word와의 거리와 관계없이 모든 단어의 probability estimate이 동일함.
context words에 대해 합리적으로 높은 확률을 제공하는 모델을 원하기 때문에 word2vec은 이를 반영하도록 함.

=> 고차원 벡터공간 상에서 유사한 단어는 가깝게 배치함.
그럼 이 word vector를 어떻게 학습하는가?
02. Optimization: Gradient Descent
- 0에 가까운 random word vector로 초기화하여 시작
- Gradient Descent(경사하강법): 𝜽를 update하여 cost function을 최소화하는 반복적인 알고리즘
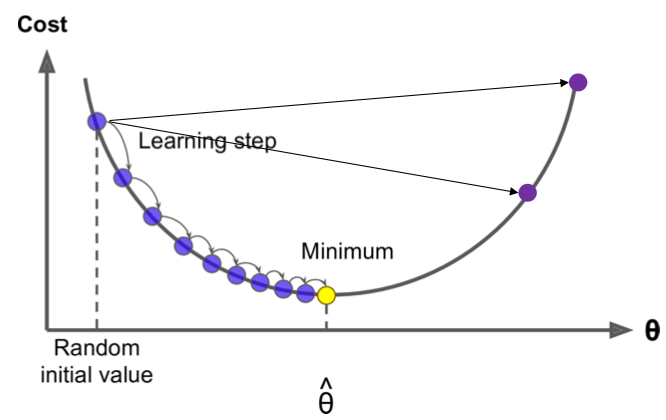
Minimum으로 이동하기 위해 gradient의 음의 방향으로 작은 step을 이동한다.
+) step이 너무 작으면 수렴이 너무 오래 걸려서 epochs 내에 수렴하지 못함.
step이 너무 크면 minimum에 도달하지 못하고 이리저리 튀어 수렴이 어려움.
+) 그림은 Convex한 2차원 함수를 예시로 들었지만, 실제 Neural Network는 일반적으로 Convex하지 않음.
Update equation
in matrix notation)
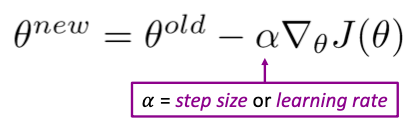
for a single parameter)
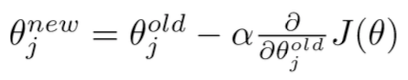
현재 parameter 에 대해 gradient의 negative 방향으로 이동하여 파라미터를 update한다.
Stochastic Gradient Descent
위와 같은 Gradient Descent의 문제점
: courpus의 모든 단어에 대한 함수
전체 corpus의 모든 center word에 대해 gradient 계산을 수행해야 한다.
보통 마주할 corpus는 대부분 매우 많은 단어로 구성되기 때문에 gradient update에 아주 오랜 시간이 소요됨. 최적화가 매우 느린 문제가 발생.
Stochastic Gradient Descent 란?
전체 corpus에 대해 gradient를 계산하는 대신 하나의 단어 또는 작은 batch에 대해 gradient를 계산하는 알고리즘.
--> 전체를 한 번 훑어 update하는 것보다 noisy 하지만 학습이 훨씬 빠르다.
따라서 Neural Network에서는 대부분 경사하강법이 아닌 SGD를 사용한다.
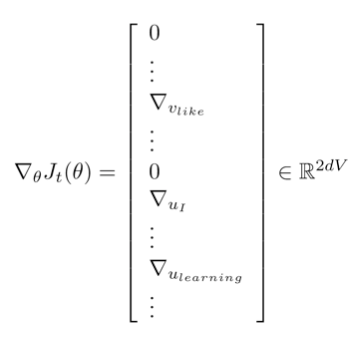
하지만 word2vec의 입출력 형태인 One-Hot Encoding을 stochastic gradient descent에 사용하면 각 윈도우에 해당하는 단어들을 기반으로 업데이트되기 때문에 나머지 수많은 단어들은 업데이트되지 않는다.
예를 들어 윈도우 사이즈가 5이면 11개 단어에 대한 gradient 정보를 갖게 되지만 나머지 단어에 대한 gradient 정보가 없다.
따라서 아주 sparse한 gradient update를 하게 되어 불필요한 계산이 이루어진다.
word2vec: More details
- 앞 부분에서 보았듯이 word2vec은 각 단어마다 outside vectors와 center vectors가 있어, 내적과 softmax를 통해 center word와 outside word가 얼마나 자주 함께 나오는지에 대한 확률값을 계산하였다.
만약 하나의 vectors만을 사용하여 word2vec를 구현하면 center word와 context word가 같은 단어가 되는 경우가 생겨 x dot x 내적값을 가지게 되어 계산이 복잡해지는 문제가 있다.
The skip-gram model with Negative sampling(SGNS)
일반적으로는 확률을 구하기 위해 다음과 같은 naive softmax를 사용한다.
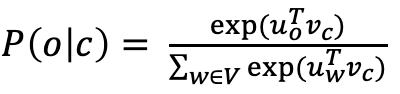
하지만 이를 활용하면 분모에서 모든 단어에 대해 내적 계산을 해야 하기 때문에 만약 10만개의 단어가 있는 경우 10만개의 단어의 확률값을 구하기 위해 매 계산마다 10만번의 내적을 해야 한다. 즉 연산량이 크다는 문제가 있습니다. (computationally expensive)
Main idea: true pair(center word, context word)와 noise pairs(center word, negative word)를 이진 분류하는 binary logistic regressions을 학습하자.
다음은 skip-gram의 목적함수이다.
각 특정 center word에 대한 목적함수는 다음과 같다.
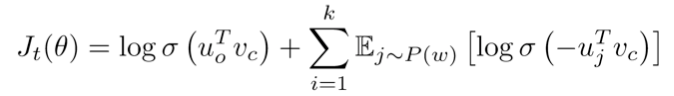
목적함수를 maximize하여 최적화 한다.
이 목적 함수는 softmax 대신 logistic/sigmoid function을 사용한다.
따라서 목적함수를 최대화하기 위해 window 안에 있는 outside word와 center word의 내적에 log를 취한 값은 커야 한다.
그리고 center word와 negative word의 내적값은 음수가 도출되는데, 음수일 경우 sigmoid 함수를 통과할 경우 값이 작기 때문에 sigmoid 함수의 대칭성을 이용해 내적값에 음수를 취해주어 더 큰 값을 얻도록 한다.
(* negative word: random sampling으로 추출한 window에 해당하지 않는 단어들)
이 목적함수를 최대화하는 방식은 negative likelihood를 최소화하는 것과 같다. (그냥 -만 취해준 형태이기 때문)
따라서 negative likelihood는 다음과 같다.
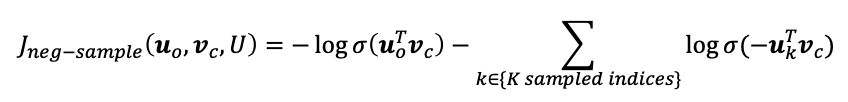
결과적으로 positive word와 center word의 내적값은 크게, negative word와 center word의 내적값은 작게(음수)끔 학습한다.
Q: negative sampling은 어떻게 하는가?
A: 단어를 sampling 할 때 균일한 확률로 샘플링하지 않는다. corpus에서 단어의 빈도수를 고려하지만 지나치게 많이 나오는 'a', 'the' 같은 단어들에 대해서는 제한을 주기 위한 함수를 사용한다.
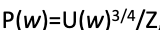
각 단어의 유니그램 확률값(빈도수를 고려한 확률값)을 3/4승으로 가져오고 이를 z로 나누어 정규화한 값을 확률값으로 사용한다. 따라서 추출 시 빈도수의 영향은 받지만 common word와 rare word의 추출 차이를 완화시킨다.
co-occurrence matrix
- window length 1 (일반적으로는 5-10)
- Example corpus: "I like deep learning.", "I like NLP", "I enjoy flying"
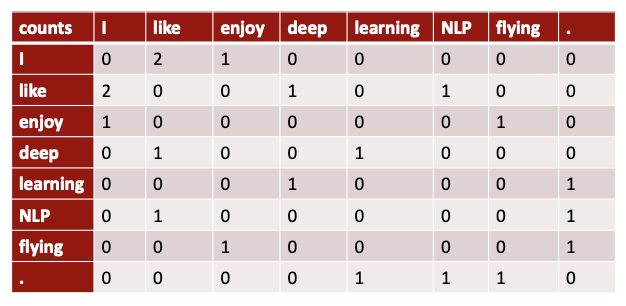
이렇게 하면 비슷한 의미를 가진 단어끼리 비슷한 벡터를 가지게 됨을 알 수 있다.
예를 들어 'you'와 'i'는 유사한 벡터를 가질 것이다. I like, you like, i enjoy, you enjoy 등 주변 단어가 비슷하기 때문이다.
이러한 방법은 성능이 나쁘진 않았지만 sparsity 문제가 있다.
즉 차원은 아주 크고 sparse하게 word vector를 표현한다.
예를 들어 50만개의 단어가 있으면 각 단어에 대해 50만 차원 벡터를 가진다.
=> 차원이 매우 크기 때문에 희소성이 커진다. => noisy하고 less robust해지는 경향이 생긴다.
따라서 고정된 차원수로 단어를 표현하여 저차원 벡터를 사용하는 것이 더 나은 결과를 보인다.
일반적으로 사용되는 차원수는 25-100이다.
따라서 co-occurrence matrix의 차원을 SVD, LSA, COALS 등 선형대수적 접근인 특이값 분해를 통해 축소합니다.
03. Glove
Glove는 각각 장단점을 가진 선형대수 기반의 co-occurrence matrix와 neural updating 알고리즘을 connect하기 위해 개발되었다.
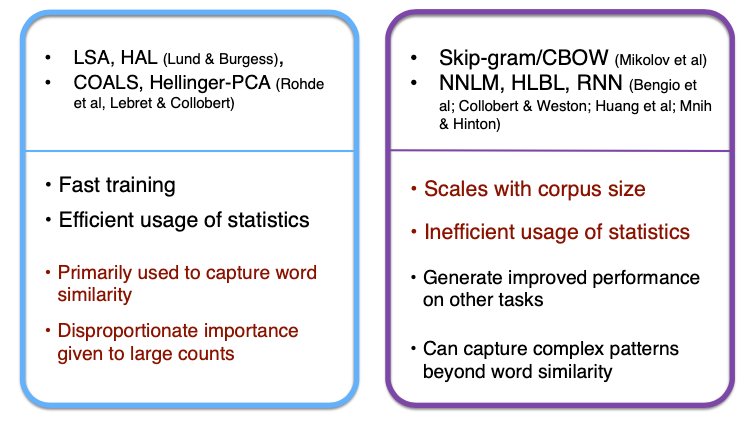
co-occurrence matrix (count-based)
장점
- 빠른 훈련 속도
- 효율적으로 통계정보 사용
단점 - 주로 단어 유사성 여부만을 파악함. 단어 간 관계는 파악할 수 없음.
- 빈도수가 클수록 과도한 중요성을 부여하여 불균형함.
neural updating algorithm
장점
- 높은 수준의 성능
- 단어 유사성 이상의 복잡한 패턴을 파악 가능
단점 - corpus의 크기가 성능에 영향을 미침.
- 효율적으로 통계정보를 사용하지 못함. (비교적)
Crucial insight: vector의 뺄셈이나 덧셈을 통한 유추를 가능하게 하려면 해당 단어의 component를 알아야 하는데, 이를 알아내기 위해 통계정보인 co-occurrence probabilites의 비율을 활용할 수 있다.
(* 유추: 얼음 - 고체 = 물)
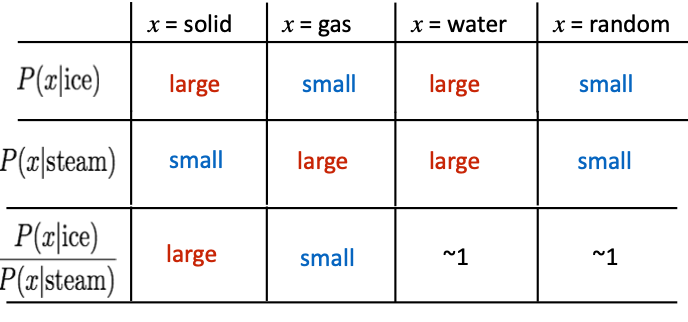
ice이라는 단어에 대해 solid와 water라는 단어는 유사성이 높다.
steam이라는 단어에 대해서는 solid와의 유사성이 낮고 gas와 water라는 단어와 유사성이 높다.
ice와 steam 간의 관계를 알아내기 위해서 ice에 대한 단어의 확률과 steam에 대한 단어의 확률의 비율을 사용할 수 있다.
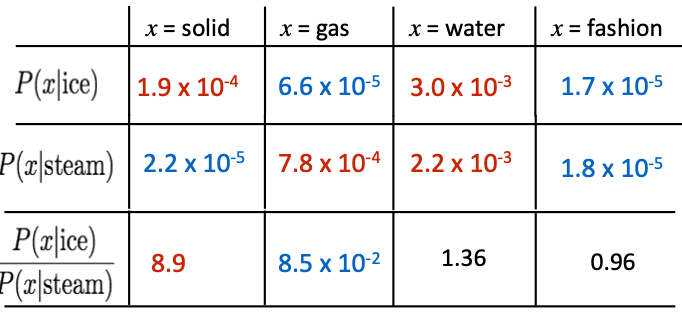
예를 들어 다음과 같은 수치로 구성되어있다면,
ice와 solid의 유사도에 steam과 solid의 유사도를 나누었을 때 8.9라는 높은 수치가 도출된다.
하지만 water나 fashion과 같이 두 단어에 대해 유사성의 정도가 비슷한 경우에는 1에 가까운 수치가 나온다. 따라서 이러한 co-occurrence 확률의 비율을 통해 단어의 components를 알아낼 수 있다.
Encoding meaning in vector differences
그렇다면 어떻게 이 동시출현 발생 확률의 비율을 선형 의미를 갖는 meaning component로 활용할 수 있을까?
Log-bilinear model
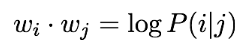
두 단어 간의 내적을 co-occurrence probabilities의 로그에 근사하도록 한다.
Log-bilinear model with vector differences
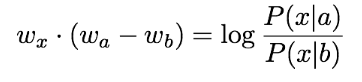
a와 b 단어 벡터 간의 차이와 x 단어와의 유사도가 위에서 보았던 동시 출현 확률의 비율의 로그값에 대응하도록 한다.
따라서 GloVe 모델의 목적함수는 다음과 같다.
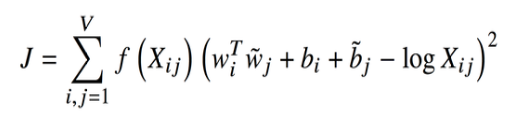
위에서 설명한 것처럼 두 단어의 내적과 동시 출현 확률의 비율에 로그를 취한 값이 유사하도록,
두 단어의 dot prouct와 co-occurrence 확률의 로그 간 오차제곱을 최소화한다.
앞의 f 함수는 단어 빈도수에 대해 스케일링하는 함수이다.
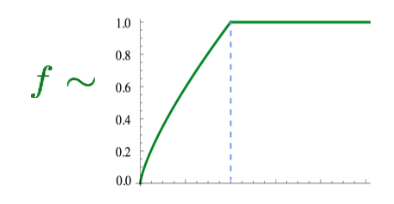
많이 등장하는 common word의 영향에 지배받지 않도록 이 함수를 통해 빈도수가 지나치게 높은 단어들에 대한 영향을 제한한다.
GloVe results

GloVe 모델을 통해 'frog' 단어와 의미적으로 유사한 단어를 출력한 결과, 상위 5개의 단어가 개구리에 해당하는 단어로 선택되어 잘 작동하는 것으로 생각된다.
그렇다면 이 모델이 얼마나 잘 작동하는지는 어떻게 평가할 수 있을까?
04. How to evaluate word vectors?
- intrinsic evaluation: 평가를 위한 substack(데이터)에 모델을 적용하여 성능을 평가한다.
-> 계산 속도가 빠르지만 현실에서 유용하게 쓰일 수 있을지 알 수 없다. - extrinsic evaluation: 실제 현실 문제에 직접 적용하여 성능을 평가한다.
-> 각종 NLP task에 embedding 결과를 직접 적용하여 성능을 측정할 수 있다. 하지만 성능의 결과가 임베딩 모델 때문인지 다른 요소 때문인지 알 수 없다. 계산 속도가 느리다.
Intrinsic word vector evaluation
* Word Vector Analogies (단어 유추)

? 에 해당하는 단어를 유추하는 것을 의미한다. 이는 위와 같은 식을 통해 유추한다.
ex1) GloVe Visualizations
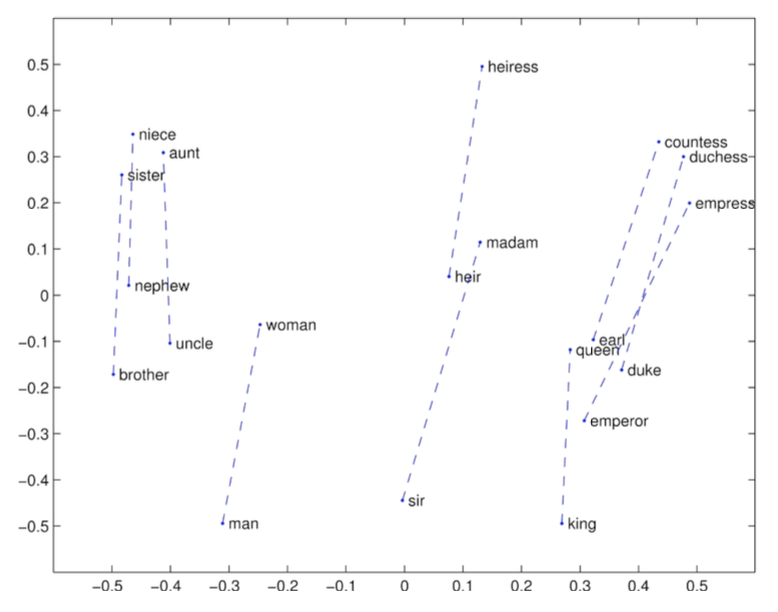
각 유사한 단어 간에 강한 선형 관계를 보인다. 따라서 단어를 빼고 더함으로써 단어의 유추가 가능하다.
ex2) GloVe Visualizations: Company - CEO
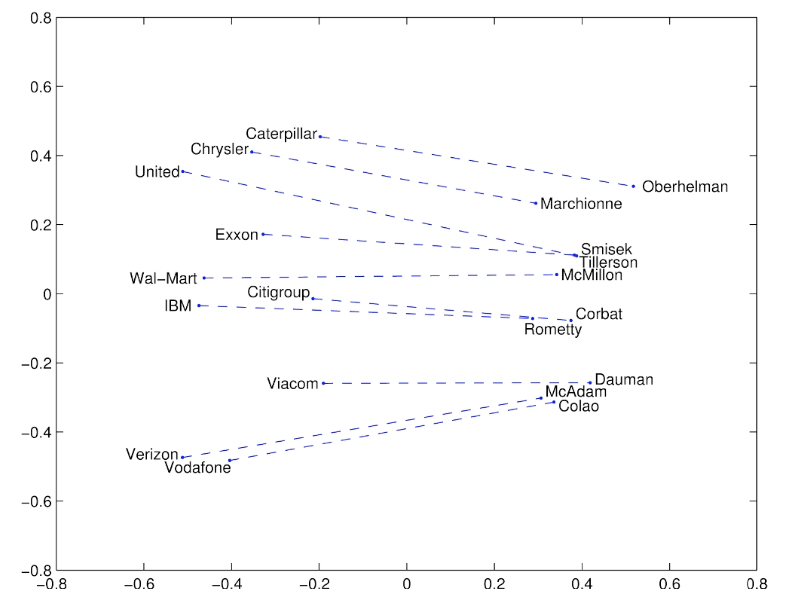
회사와 CEO에 대한 데이터를 학습한 결과 회사와 CEO의 관계도 선형적이기 때문에 단어의 유추가 가능하다.
ex3) GloVe Visualizations: Comparatives and Superlatives
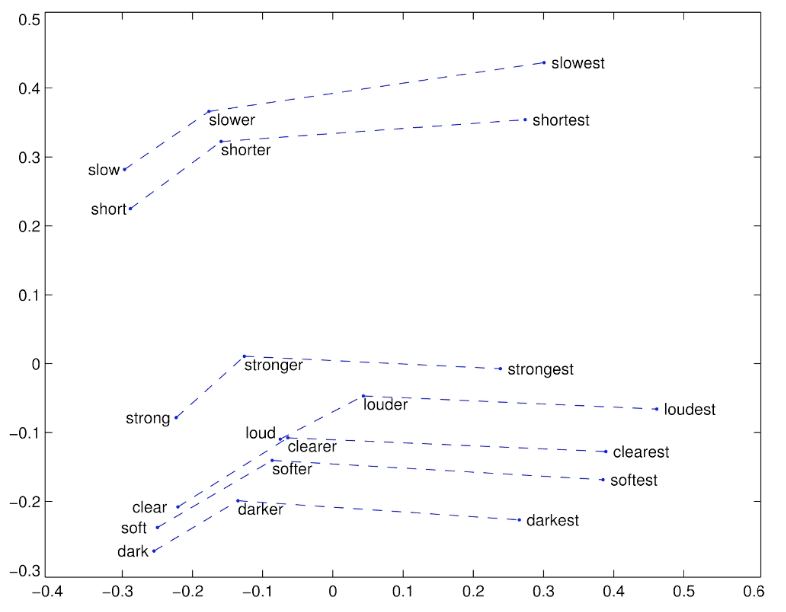
원형-비교급-최상급에도 대략 선형 component로 구성된 것을 확인할 수 있다.
의미론적, 구문론적 외에도 문법에 대해서도 학습함을 알 수 있다.
- Analogy evaluation
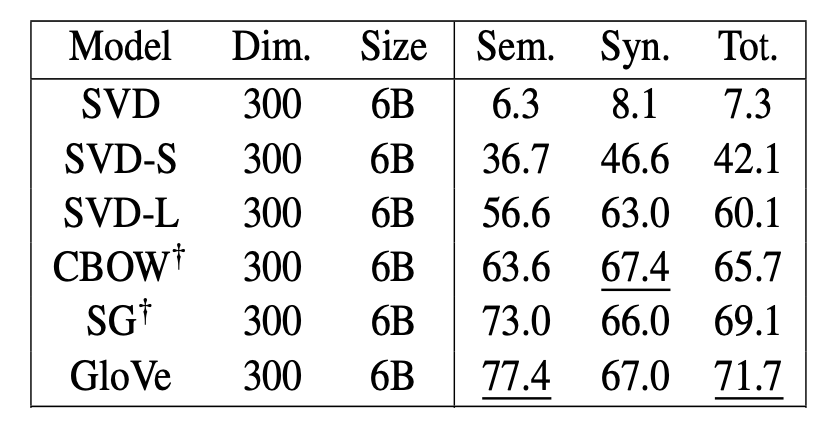
유추에 대한 semantics(의미적) / syntactics(문법적) / Total(전체) 평가
: GloVe > word2vec > co-occurrence matrix 순으로 성능이 좋다.
하지만 GloVe가 가장 높게 나온 이유는 평가에 더 유리한 데이터를 학습했기 때문이라고 한다.
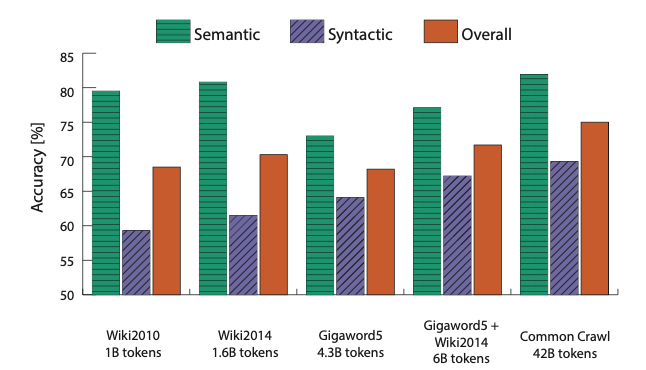
GloVe는 일부 Wikepedia 데이터에 대해 학습했지만 word2vec은 뉴스 데이터들을 위주로 학습했기 때문에 의미론적으로 성능이 좋을 수 밖에 없다.
Wikipedia는 백과사전 데이터의 특성상 의미론적인 데이터를 많이 포함하고 있기 때문에 wikipedia 데이터를 학습한 경우 semantic적으로 성능이 높아진다.
article 데이터인 Gigaword를 학습했을 때의 의미론적 성능은 wikipedia를 학습했을 때에 비해 1/4 정도 떨어지는 것을 보아 wikipedia를 학습하면 의미론적 성능이 높아진다는 것을 증명한다.
하지만 어떤 데이터든 무조건 많은 데이터를 학습했을 때 가장 성능이 좋았다.
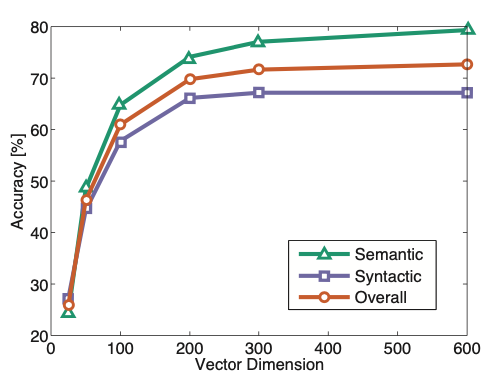
또한 벡터의 차원이 300차원 정도일 때 가장 성능이 좋았다.
이는 GloVe 뿐만 아니라 Word2Vec 등 잘 알려진 임베딩 모델에 적용된다.
Another intrinsic word vector evaluation
모델의 단어 간 유사성에 대한 판단과 인간의 판단을 비교하는 intrinsic eval
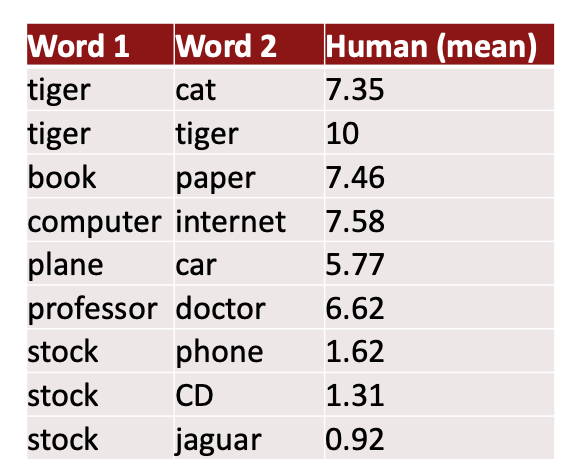
지난 수십년 동안 단어의 유사성에 대해 인간이 0-10 사이로 점수를 매겨 수집한 데이터를 활용해 모델의 성능을 평가한다.
- 결과
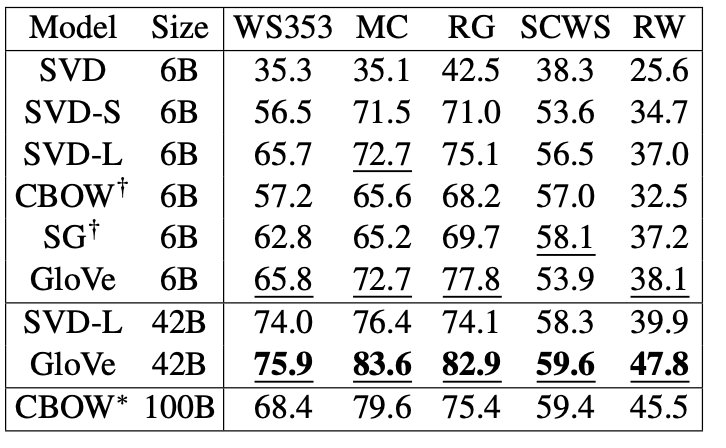
인간의 판단과 word vector 거리의 상관관계를 통해 평가한 결과,
GloVe > Word2Vec > co-occurrence matrix 순으로 성능이 좋았다.
Extrinsic word vector evaluation
좋은 vector를 사용하면 NLP task의 성능이 좋아진다.
따라서 GloVe를 통해 구한 Embedding vector가 NLP task에 얼마나 도움이 되는지를 평가한다.
- Named Entity Recognition(개체명 인식)에 대한 성능 평가
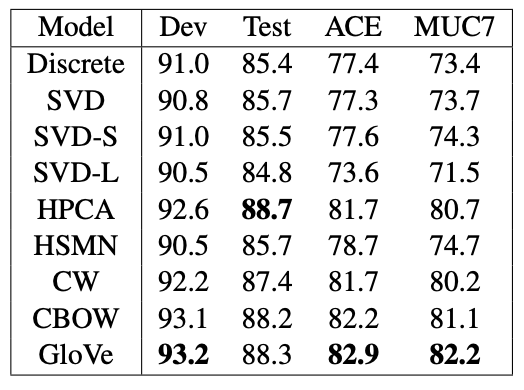
GloVe > word2vec > co-occurrence matrix 순으로 성능이 좋다.
