RAGAS Evaluation
- RAG 구조의 각 모듈을 평가하는 evaluation 매커니즘
- https://docs.ragas.io/en/latest/concepts/metrics/index.html 참고
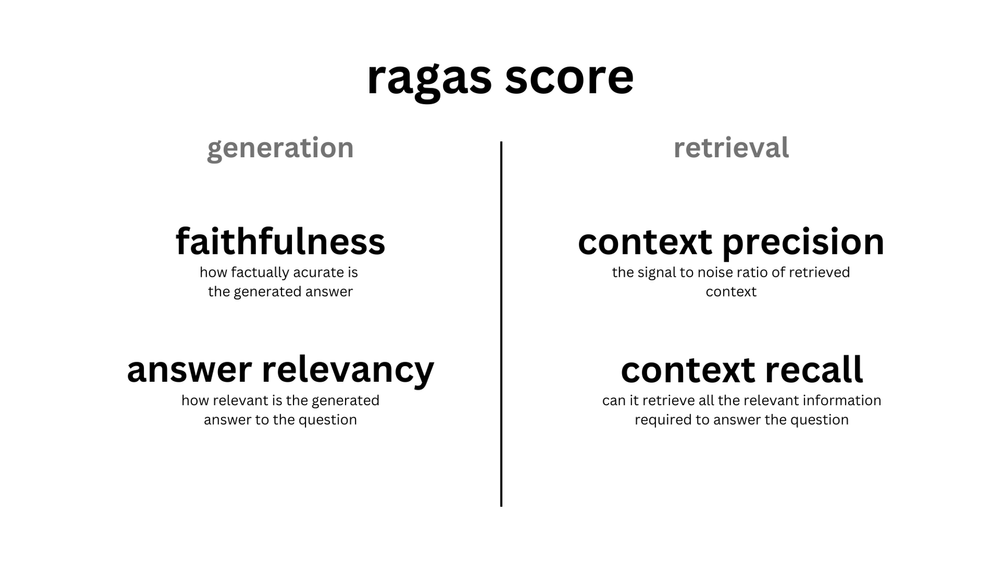
generation
- faithfulness: answer - context
- answer relevancy: answer - question
retrieval
- context precision: context - ground truth
- context recall: context - question
Faithfulness
- 주어진 문맥을 얼마나 잘 반영하여 답변을 생성하였는지 평가
- 점수 범위: 0~1 (1에 가까울수록 좋음)
- context에서 답변에 대한 claims를 유추할 수 있는 경우 점수를 줌.
Calculation
Step1. 생성된 답변으로부터 statements를 추출함. (llm 활용)
Step2. 추출한 statements가 주어진 context에서 추론될 수 있는지 여부를 판별함. (llm 활용)
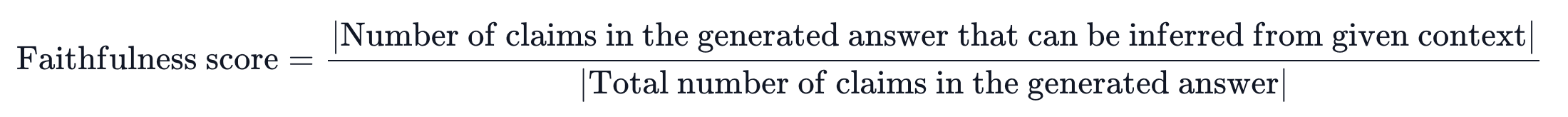
Answer Relevance
- 생성된 답변이 질문에 얼마나 잘 부합하는지 평가
- 점수 범위: -1~1 (1에 가까울수록 좋음)
- 생성된 답변을 기반으로 생성한 질문과 원래 질문의 cosine 유사도를 활용함.
- answer과 context만으로 question을 재구성할 수 있다는 개념을 활용한 방식.
Calculation
Step1. 컨텍스트를 기반으로 생성된 답변에 대한 질문을 생성함. (Reverse-engineer, llm 활용)
Step2. 실제 질문과 생성 질문 사이의 cosine similarity를 연산함.
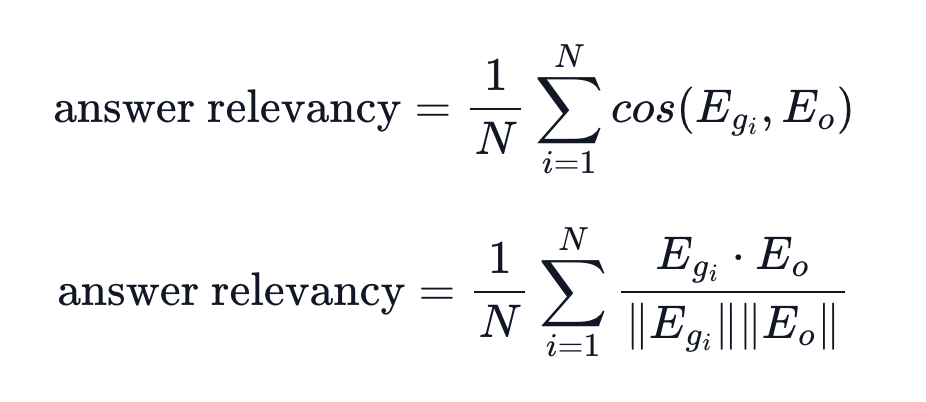
Context Precision
- 검색된 각 k개의 context가 question, ground truth와 연관이 있는지 평가.
- 점수 범위: 0~1 (1에 가까울수록 좋음)
- 검색 결과와 유효성을 기반으로 precision을 계산함.
Calculation
Step1. 검색된 k개의 context(chunk)가 question, ground truth와 연관이 있는지 판별. (llm 활용)
Step2. 각 context에 대한 precision 계산
Step3. precision의 평균을 구함

Context Recall
- 검색된 context가 ground truth와 얼마나 잘 일치하는지 평가.
- 점수 범위: 0~1 (1에 가까울수록 좋음)
- ground truth의 각 claim이 검색된 context와 얼마나 일치하는지 계산함.
Calculation
Step1. ground truth를 독립된 statements로 분리함.
Step2. 각 statements의 정보를 검색된 contexts에서 찾을 수 있는지 판별함.
Step3. step2의 결과를 기반으로 recall을 계산함.
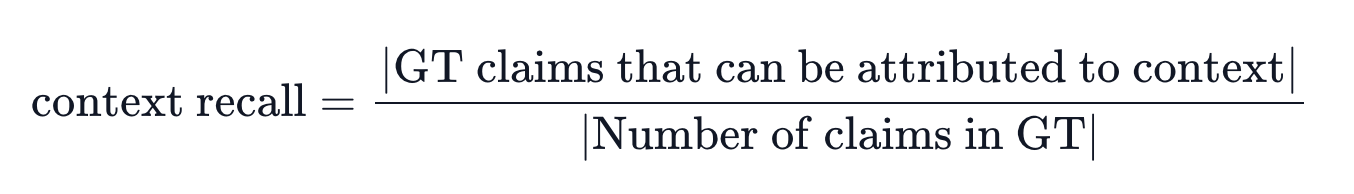
Reference
RAGAS docs: https://docs.ragas.io/en/latest/concepts/metrics/index.html

NLP Researcher / Information Retrieval / Search