elasticsearch에서 한국어를 검색할 땐 한글 형태소 분석기 "nori"를 설치해야 한다.
기본인 standard analyzer를 사용해도 white space 기준으로 tokenize는 되다보니 검색이 되긴 하지만 한국어의 원형을 찾지 못해 그닥 성능이 좋지 않을 것이다.
1. nori analyzer 설치
bin/elasticsearch-plugin install analysis-nori
elasticsearch가 저장되어있는 bin 폴더에 elasticsearch-plugin을 통해 위와 같이 install 할 수 있다.
보통 그냥 위 명령어만 쓰면 설치 끝이지만 본인은 사내 보안규정상 아래처럼 SSL 에러가 발생했다.
Exception in thread "main" javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target해결 방법 : local에 다운 받아서 설치
bin/elasticsearch-plugin install file:{저장한 폴더 경로}/analysis-nori-{elasticsearch 버전}.zip
2. code
- setting.json
{
"settings": {
"analysis": {
"analyzer": {
"my_nori": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"decompound_mode": "mixed"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text"
},
"charactor": {
"type": "text"
},
"episode": {
"type": "text"
},
"text": {
"type": "text",
"analyzer": "my_nori"
}
}
}
}- elastic.ipynb
def create_index(body=None):
if not es.indices.exists(index=INDEX):
return es.indices.create(index=INDEX, body=body)
def insert(texts, title, charactor, episode=None):
global index
texts = re.sub(r'\[[^]]*\]', ' ', texts)
texts = custom_split(seps, texts)
text_lst = [re.sub('[^가-힣0-9.% ]', '', text).strip() for text in texts if text]
for idx, text in enumerate(text_lst):
body = {"text": text, "title": title, "episode": episode, "charactor": charactor}
es.index(index=INDEX, id=idx+index, body=body)
# print(index+idx, body)
index += idx + 1
print(f"총 {index-1}개 데이터 저장")
es = Elasticsearch('http://localhost:9200', verify_certs=False)
INDEX = 'test_nori'
index = 0
with open('es_setting.json', 'r', encoding='utf-8') as f:
setting = json.load(f)
create_index(setting)setting.json에서 filter의 기준이 될 title, episode, charactor는 my_nori를 사용하지 않아야 한다. 사용하면 filter하면 결과 아무것도 안 나옴.
3. result
형태소 분석 결과
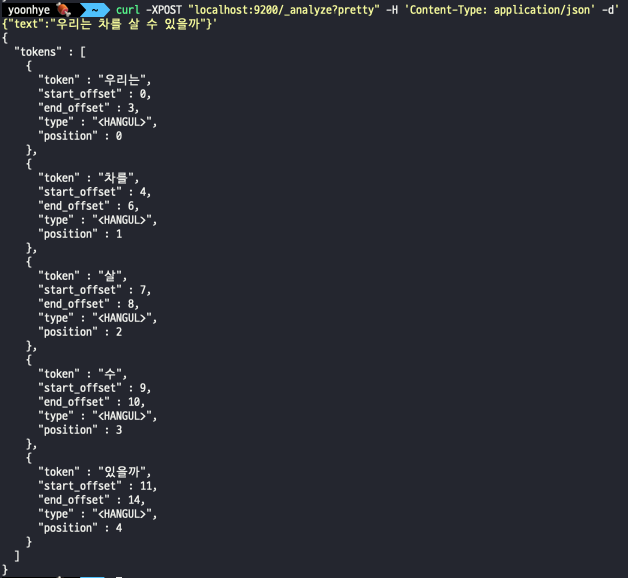
Standard VS. Nori
- standard analyzer
- nori
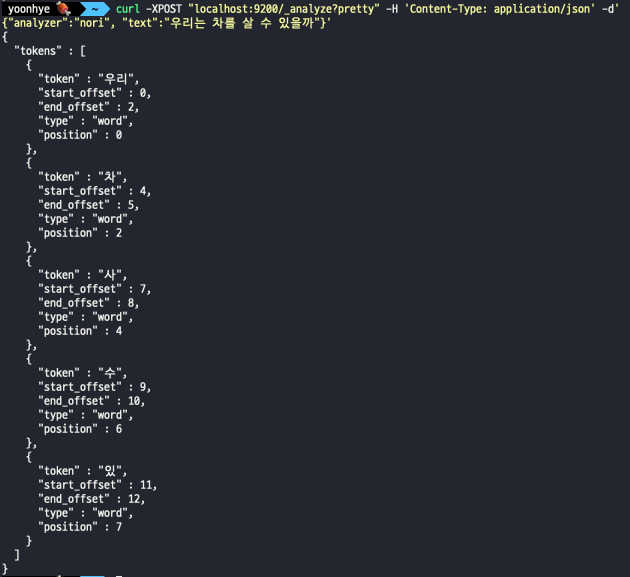
-> nori를 써야 원형을 잘 찾을 수 있다.
실제 검색 결과
Query
'앵커: 나희도 선수가 금메달리스트 고유림 선수를 꺾고 경주 아시안 게임의 금메달을 가져갑니다!\n찬미: 나희도 금메달! 나희도 금메달! 나희도!\n앵커: 네\n찬미: 나희도 일낼 줄 알았다, 이 가스나야! 나희도, 니 일낼 줄 알았어, 내가 나희도 금메달!\n앵커: 대단한 역전승입니다!\n찬미: 나희도가 금메달을 땄습니다!\n앵커: 아, 멋지군요'
- standard

- nori

=> nori를 통해 한국어의 원형을 잘 찾았기 때문에 점수가 전체적으로 높다.
=> 대화가 이루어지는 상황으로 더 적합한 문장을 추출한다.
