Scaling Sentence Embeddings with Large Language Models
Abstract
-
propose: sentence embedding의 성능을 향상하는 것이 목표인 in-context learning-based method.
-
approach:
- 기존의 프롬프트 베이스의 representation method를 autoregressive 모델로 adapting
- LLMs이 in-context learning을 수행할 수 있도록 demonstration set을 구성. (입증 셋)
- LLM을 다양한 사이즈 스케일링 업
-
in-context learning을 통해 LLMs이 높은 퀄리티의 문장 임베딩을 finetuning 없이 잘 생성할 수 있게 함.
이는 최신 contrastive learning 방법과 견주는 성능을 달성한다. -
100억 이상의 파라피터로 스케일링하는 것은 STS(semantic textual similarity) tasks에 나쁨.
-
반면 transfer tasks에 대해서는 가장 큰 모델의 성능이 SOTA를 달성.
-
current constrastive learning 접근법을 통해 LLMs을 파인튜닝하고 본 논문의 프롬프트 베이스 방법론을 통합
- 2.7B OPT model이 4.8B ST5를 능가하며 STS tasks에 SOTA를 달성했다.
Introduction
- 기존에는 contrastive learning (ex. SimCSE)을 통한 임베딩 모델이 성행?했음.
- 현재(23년 상반기) LLM을 활용해 contrastive learning을 위한 데이터를 augmentation하는 작업이 많음.
- 하지만 LLMs을 활용하여 직접 sentence embeddings을 생성하는 것에는 두 가지 주요 챌린지가 있음. 1) LLM은 autoregressive models이라 vectors가 아닌 text가 출력되기 때문에 output을 vectorizing해야 한다. 2) in-context learning을 sentence embeddings에 통합하는 효과적인 방법론을 결정하는 것이 중요함.
- LLM을 통해 sentence embedding을 수행하는 연구를 위해 다음 연구적인 question을 세움. 1) LLM은 문장 임베딩을 표현하는 데 어떻게 사용될 수 있으며, promptBERT에 입증된 것처럼 프롬프트 엔지니어링을 수행할 수 있는지 2) in-context learning이 sentence embedding의 품질을 향상시킬 수 있는지 3) 파라미터의 수가 수십억 개를 초과할 때에도 모델 파라미터의 스케일을 키우는 게 여전히 먹히는지 4) current contrastive learning framework를 LLM과 통합했을 때 어떤 개선점을 얻을 수 있는지
- LLAMA, OPT에 STS와 transfer task를 평가하는 연구를 진행.
This sentence: “ [text] ” means와 같은 프롬프트를 활용함. (해당 논문을 참고함.)
→ 이러한 방법은 output tokens의 평균을 represent sentences로 averaging하는 등의 전통적인 representation 방식보다 성능이 좋음.
Example 데이터 구성 (for in-context learning)
- 단어 사전의 정의 문장을 문장 임베딩 학습한 방법에서 영감을 받아, 정의 문장과 그 연관 단어를 in-context learning을 수행하기 위한 예시로 추가하면 성능이 크게 향상되는 것을 확인함.
- 예시와 입력 문장 사이의 차이를 줄이기 위해 STS-B 학습셋의 문장들과 문장의 의미를 표현하는 싱글 워드를 ChatGPT가 생성하게 하여 examples를 구성하였다. → STS-B development set을 기반으로 한 demonstration examples를 통해 evaluate했을 때, 기존의 unsupervised data로 fine-tuned된 contrastive learning 기반 sentence models에 비해 성능 굿.
LLM의 파라미터를 스케일링 업
- 수백만에서 수십억으로 파라미터를 스케일링 업한 것이 STS 테스크에서 성능 향상을 확인함.
- 하지만 그 이상의 스케일랑 업은 성능 향상 X
- in-context learning에서도 66B OPT가 6.7B OPT보다 STS 테스크에서 별루.
- transfer tasks는 스케일을 키울수록 좋음. 수백억 파라미터가 파인튜닝 없이도 소타 달성함.
LLMs contrastive learning
- lora, qlora 그리고 qptq로 LLMs를 contrastive learning을 수행하기 위해 큰 배치 사이즈로 fine-tuning 했음.
→ qlora로 학습한? 2.7b OPT 모델이 4.8B ST5 모델보다 성능이 뛰어났고 STS에서 sota를 달성함.
contribution 정리
- in-context learning 을 통합하여 파인튜닝 없이 LLM을 통해 높은 퀄리티의 문장 임베딩 수행.
- LLM의 스케일링업을 통해 transfer tasks에서 소타 달성. (근데 저 테스크가 뭐임)
- contrastive learning을 함께 적용하면 STS 테스트에서도 소타 달성함.?
Methodology
without fine-tuning: in-context learning 활용
with fine-tuning: contrastive learning 적용
- 2023년 7월 기준) Prompt-BERT는 prompt 기반 방법을 사용하여 문장을 표현
This sentence: “ [text] ” means [MASK].하는 메뉴얼 템플릿을 사용함.- [MASK] 토큰의 output vector를 sentence embeddings으로 활용.
- output hidden vectors나 [CLS] 토큰의 output vector를 averaging하는 이전의 방법들에 비해 성능이 뛰어났다.
- [CLS] 또는 [MASK] 이 없는 autoregression models인 LLMs을 고려하여, promptbert의 prompt 기반 방법론을 LLMs에 맞게 수정함. →
This sentence: “ [text] ” means을 LLMs의 프롬프트로 사용하여, LLM이 다음 토큰을 생성하고 마지막 토큰의 히든 백퍼를 추출하여 sentence embeddings으로 활용하게 했음.
Represent Sentence with LLMs
-
prompt-based method with LLMs를 평가하기 위해 두가지 다른 methods와 비교함. (last token averageing 또는 sentence embeddings으로 사용하는 방법)
-
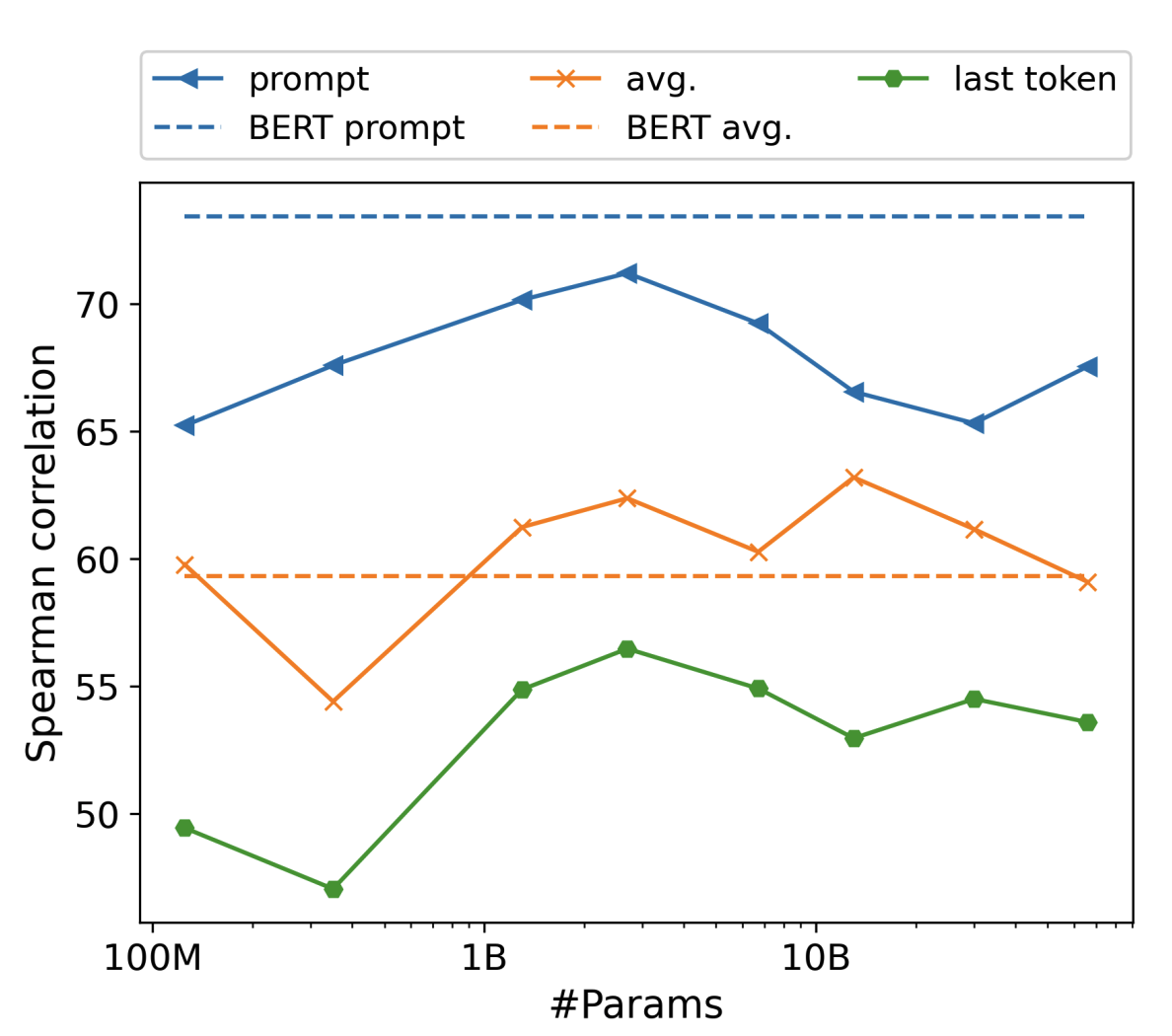
OPT (125millions ~ 66 billions) 모델, STS-B development set 활용
-
모든 크기의 OPTs에서 prompt-based method가 성능을 개선할 수 있음을 확인.
-
하지만 그럼에도 BERT보다 성능이 떨어짐.
Bert보다 성능이 떨어지는 이유
- BERT는 양방향 attention이기 때문에,
“This sentence: “ [text] ” means [MASK].”.와 같은 템플릿을 사용하여 BERT가 문장의 전반적인 semantic 정보를 하나의 [MASK] 토큰에 함축할 수 있다고 가정함. - 마침표가 있어 BERT는 하나의 단어로 의미를 함축하게 강제됨.
- BERT에 마침표를 빼보니 성능이 73.44 → 33.89로 떨어짐. (Spearman correlation, STS-B dev)
- 단방향 어텐션을 사용하는 autoregression models(like OPT)는 이거 안 먹힘. 한 단어로 제한을 주지 못함.
→ 그래서 LLMs에도 한 단어 제한을 주면 성능이 오르겠거니 하여 방법을 연구함!
PromptEOL
- prompt-based method for LLMs에 “one word limitation”를 주기 위한 방법
- PromptEOL (Prompt-based method with Explicit One word Limitation)라는 새로운 방법론 제안
- 그저 템플릿에 토큰 몇개를 추가한 단순한 방법.
This sentence: “ [text] ” means in one word: “- semantic information을 next token으로 예측하도록 제한을 주기 위해
in one word추가 This sentence: "가 입력 문장을 지시하는 것처럼: "을 추가하여 모델이 다음 토큰으로 문장부호를 생성하는 것을 방지함.
→ 이 템플릿을 OPT에 적용하여 BERT와 비슷하거나 높은 성능을 달성한 것을 확인함.
Improve Sentence Embeddings with In-context Learning
- in-context learning은 예시를 단순히 프롬프트에 입력하여 성능을 개선할 수 있는 방법론.
- 하지만 우리는 문장을 vector로 project해야 하고,
- sentence embeddings에는 in-context learning을 수행하기 위한 예시로 사용할 textual outputs가 부족함.
- 또한 주어진 문장에 대한 gold vectors가 존재하지도 않는다.
→ 즉 문장 임베딩 문제에서 프롬프트에 넣어줄 예시가 없다는 뜻
⇒ 자동으로 demonstration sets를 빌드하고 demonstation을 찾는 프레임워크를 제안함.

- 문장의 semantic information을 표현하는 단어 페어나 문장을 생성하는 것이 목표 → 두가지 방법 사용
1) ChatGPT 활용
- STS-B traning set의 문장에 상응하는 단어들을 생성
- 100 pairs
2) 사전 활용
- Oxford dictionary를 사용하여 단어-문장 페어를 구성
- 200 pairs
⇒ 300 pairs 데이터 구성
Constrastive Learning with Efficient Fine-tuning
- SimCSE와 같은 constrastive learning을 LLMs에 적용함
- supervised setting 사용. : natural language inference (NLI) datasets 사용
- constrastive learning은 negative samples의 개수를 키우기 위해 큰 batch size가 요구됨. → 이는 많은 GPU memory가 필요함.
- SimCSE는 110M BERT를 학습하기 위해 512 batch size를 사용함.
- 각 배치는 1536개 문장을 포함함. → 4개 gpus에서 58GB의 gpu memory가 필요함.
→ 파라미터 사이즈가 매우 큰 모델의 경우 매우 많은 메모리가 필요한 문제.
⇒ QLoRA로 fine-tuning
-
LoRA parameters
- 감마 = 64, 알파 = 16, dropout = 0.05, 모든 linear layers에 로라 모듈 적용
-
training parameters
- dataset: NLI datasets(simcse)
- temperature = 0.5, lr= 5e-4, epoc=1
-
resource
- 7B 이하: 2 GPUS, 256 batch size
- 7B: 4 GPUS, 256 batch size
- 13B: 8 GPUS, 200 batch size
-
SNLI, MNLI datasets 사용. (supervised)
-
제안한 prompt-based method를 사용하여 hidden states를 얻음. (l: the number of hidden states)
hi1, . . . , hil = LLM(This sentence: “xi” means in one word: “)- 마지막 hidden state를 문장임베딩으로 사용.
hi = hil - objective function
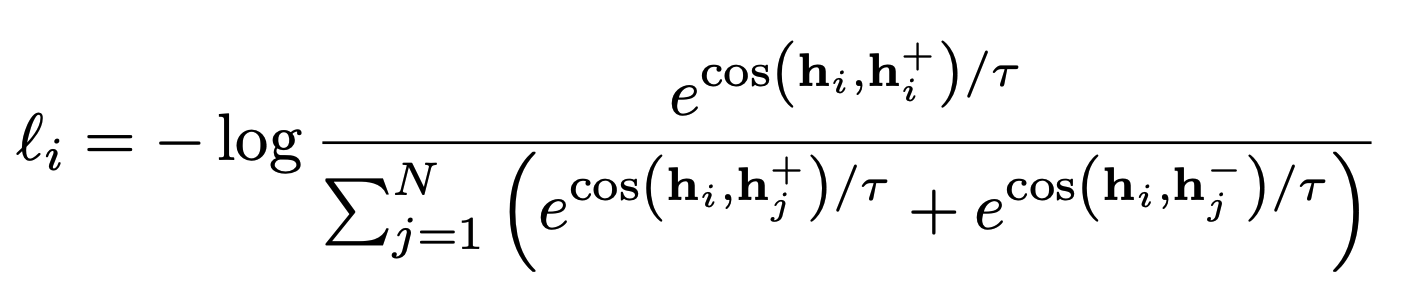
- N: batch size
- T: temperature
- 마지막 hidden state를 문장임베딩으로 사용.
Results
- SBERT, SimCSE, PromptBERT, ST5, SGPT 중 ST5가 STS, transfer learning tasks에서 모두 SOTA 달성 (ft 4.8B parameters T5 encoder with contrastive learning)
- in-context learning 해야 좋다.
- PromptEOL + CSE OPT/LLAMA
- PromptEOL + OPT/LLAMA
Conclusion
- PromptEOL + CSE + 2.7B OPT/클수록 좋았음.
