Q: 불균형 데이터를 어떻게 해결할 수 있을까요?
1. Undersampling & Oversampling
많은 데이터를 줄이거나(Undersampling) 적은 데이터를 증강하는(Oversampling) 방법
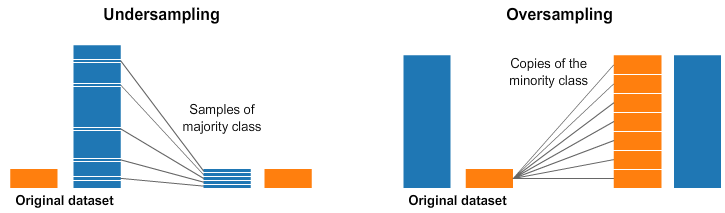
예시
from imblearn.under_sampling import NearMiss
from imblearn.over_sampling import SMOTE
2. Weight balancing
머신러닝 사용 예시
model = LGBMClassifier(scale_pos_weight=8, …)
딥러닝 사용 예시
class_weight = {"buy": 0.75,
"don't buy": 0.25}
model.fit(X_train, Y_train, epochs=10, batch_size=32, class_weight=class_weight)3. focal loss
현재까지의 클래스 별 정확도를 고려한 weight 를 줌으로서 전반적인 모델의 정확도를 높이고자 하는 loss function
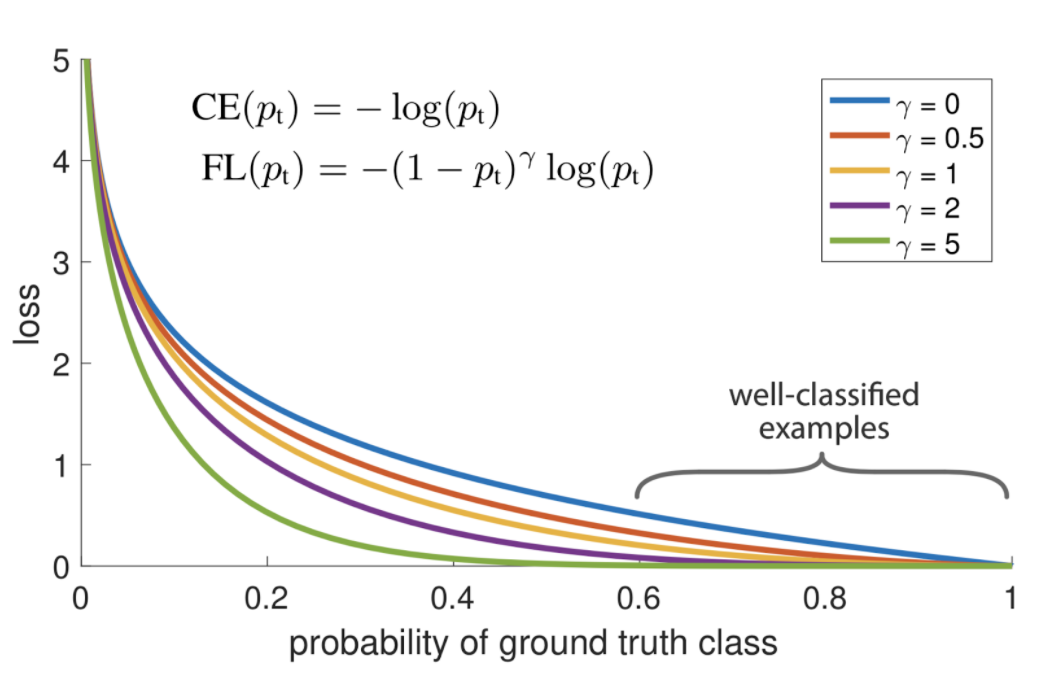
CE에 를 곱한 형태.
잘 맞춘다 = p가 크다 = 곱해지는 항이 작다 ⇒ 잘 맞추는 클래스에 대한 가중치 줄임
못 맞춘다 = p가 작다 = 곱해지는 항이 크다 ⇒ 못 맞추는 클래스에 대한 가중치 키움
참고
https://inhovation97.tistory.com/61
https://gaussian37.github.io/dl-concept-focal_loss/

NLP Researcher / Information Retrieval / Search