01. 이루다 2.0
구조

- 1차적으로 수집된 데이터에 가명처리하여 연구용 데이터베이스 구성 → 언어 모델 (어뷰징, 리트리버, 랭커) 학습
- 생성 모델(GPT-2)로 생성한 데이터로 답변 데이터베이스를 구성함. → 개인정보 침해 가능성 차단
- 답변 데이터베이스에서 적절한 답변을 선정하는 방식. = Retrieval
- 어뷰징 탐지 및 분류 모델 : 어뷰징 O →어뷰징 대응 답변
사람처럼 느끼게 하는 요소
- 루다의 개인 스케쥴 주제
- 시간, 접속 일수 기반 주제
- 사용자 개인 정보 활용 주제
- 반말/존댓말 구분
- 이미지 코멘팅
02. DPR
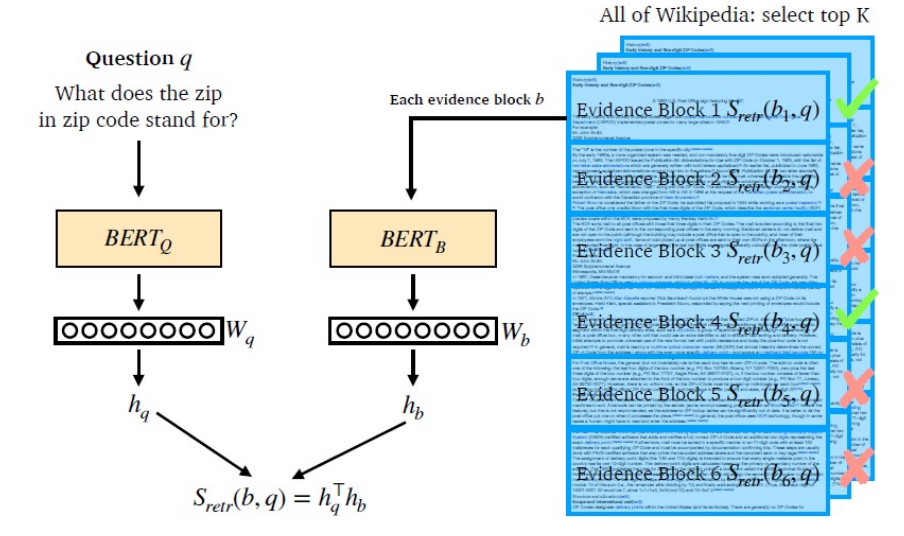
- dual-encoder : passage_encoder, query_encoder
- loss function : log_softmax + nll_loss = CrossEntropy
- 논문에서 사용한 negative sampling
- Random : Corpus 내의 random passage 사용
- BM25 : 정답을 포함하지 않지만 BM25 기준 top-k passage 사용
- Gold : 다른 질의에 대한 positive passage 사용
- in-batch negative sampling ⇒ 연산에 사용되는 메모리 줄임, batch-size를 키운 경우 성능 향상
- Random samples에 BM25 negative samples을 1,2개 추가하는 경우 성능 향상
→ 어려운 negative sampling의 필요성 - BM25 + DPR 성능이 가장 높았음. (BM25로 top-2000개 후보를 선정 & reranking)
- 데이터베이스 크기가 크면 inference time이 길어짐. → FAISS를 사용하여 가속화 가능
03. DR-BERT
구조
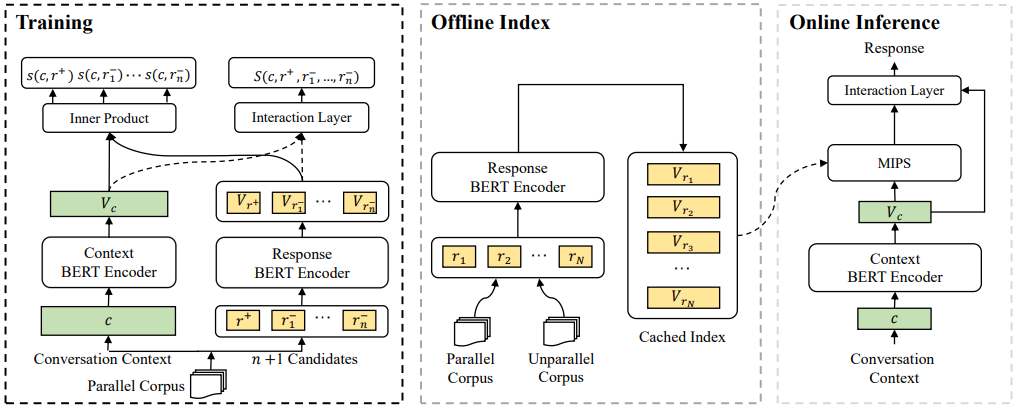
Training
- dual-encoder : Context BERT Encoder, Response BERT Encoder
- Interaction Layer : Transformer Decoder를 활용한 Layer를 추가. ⇒ 풍부한 interaction 정보를 활용하여 ranking
Offline Index
- response bert encoder를 통해 출력한 embedding 저장 (cached index)
Online Inference
- dialogue history context 입력 → Context Bert Encoder → Cache된 Response의 임베딩과 MIPS(내적) → interaction layer → 답변
학습
Loss function
- dual-encoder : nll (crossentropy)
- interaction : CrossEntropy
Stratgies
- In-batch Contrastive Learning
- Pretrain on Nonparallel Data : NDAP (pretraining on the nonparallel corpus)
- Data Augmentation
- multi-turn 대화 k개로 쪼개기 → short & fine-grained training samples
- hard negative sampling
04. BERT-FP (SOTA)
구조
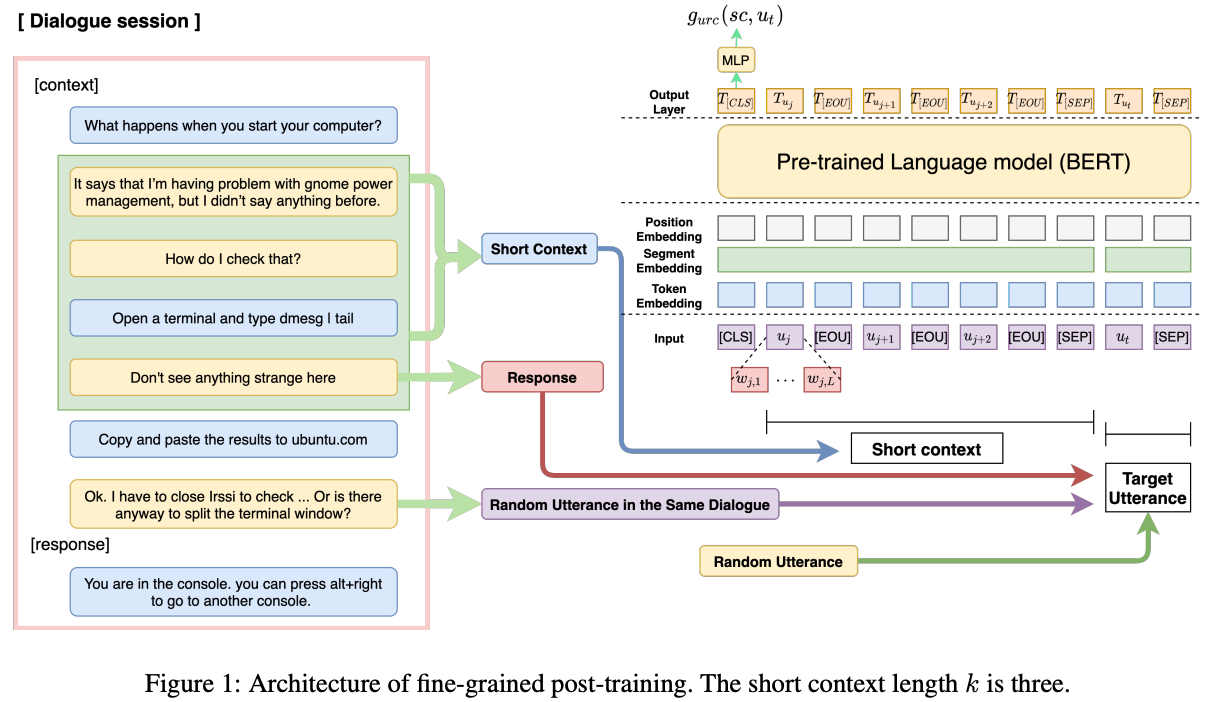
-
Short Context-response Pair Training
모든 utterance를 response로 활용, response 앞 k개의 utterances를 short context로 활용
⇒ 대화 내 모든 utterances 간 관계를 이해할 수 있음.
-
Utterance Relevance Classification
topic’s semantic relevance와 coherence를 모두 잘 학습하기 위해 제시한 새로운 training objective
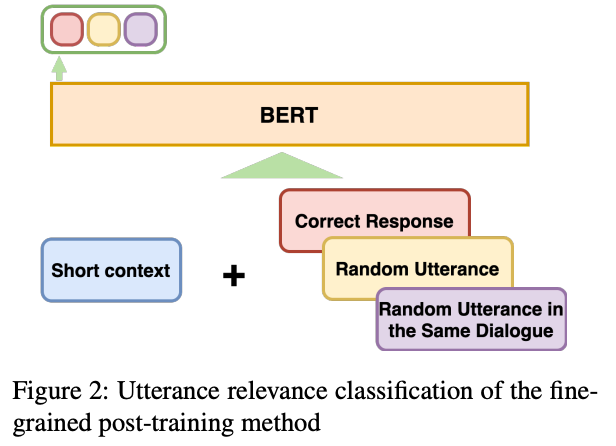
세가지 labels 중 Short context의 Correct Response를 classify하도록 학습.
-
label 1 : Random Utterance (0)
→ topic’s semantic relevance 학습
-
label 2 : 같은 dialogue session에서 random으로 추출한 utterance (0)
→ coherence 학습
-
label 3 : Correct Response (1)
⇒ 3가지 case의 utterance와 short context 간 관계를 분류하면서 semantic relevance와 coherence 정보를 모두 학습함.
-

NLP Researcher / Information Retrieval / Search