
아래의 내용을 배우는 이유는,
컴퓨터는 문자열을 이진법으로 이해하기 때문이다.
1. Encoding & Decoding
- encoding : 문자를 컴퓨터가 이해할 수 있는 이진법으로 변환하는 것
(인코딩 = 부호화 = 코드화 = 암호화)- decoding : 이진법 코드를 문자로 변환하는 것
(디코딩 = 복호화 = 역코드화)
이 때 인코딩과 디코딩의 기준이 되는 코드들이 있다.
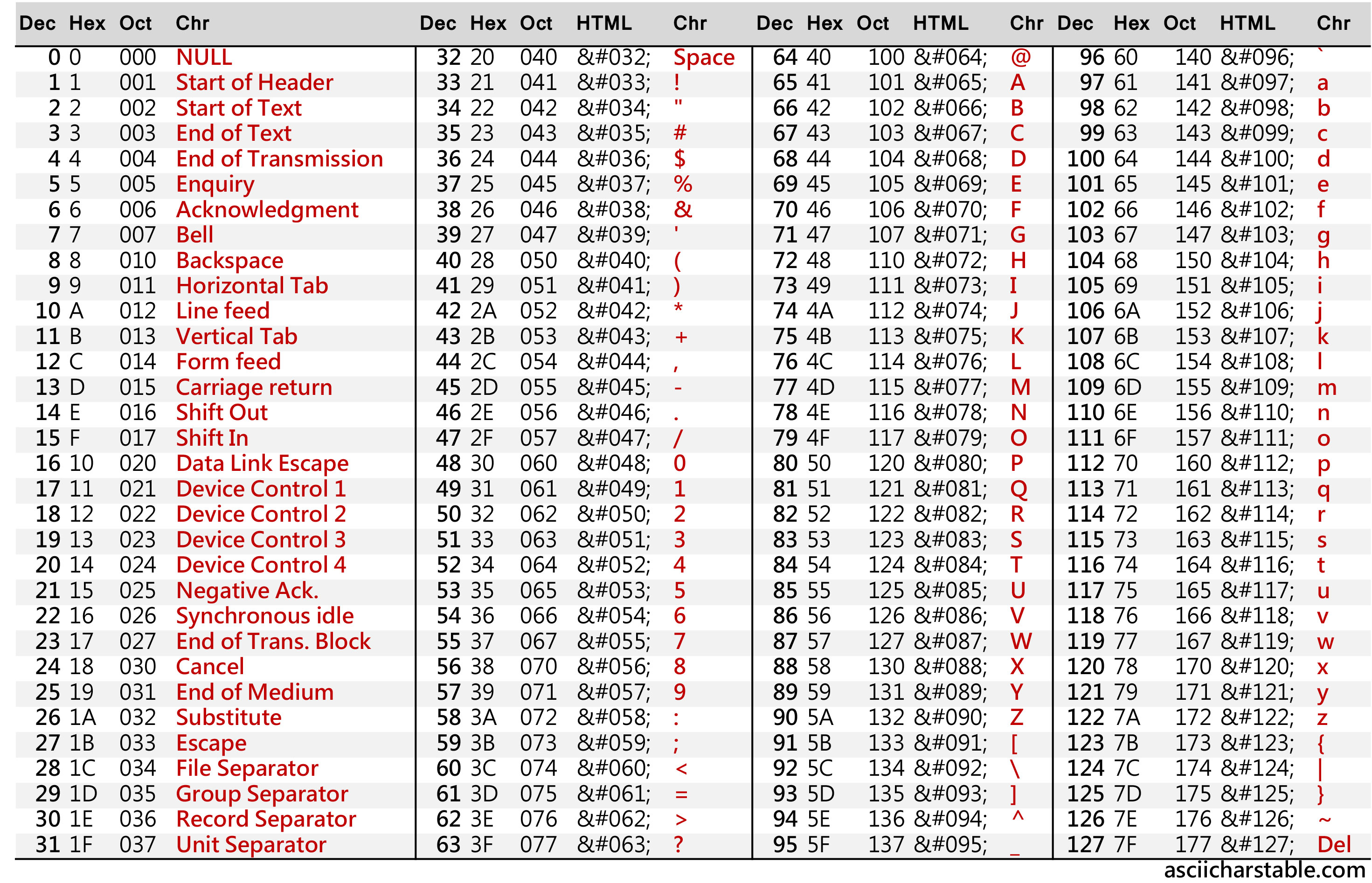
2. ASCII (아스키 코드)
-
미국 ANSI에서 표준화한 정보 교환용 7비트(2*7=128) 부호체계
-
사실 8비트이지만 한 개의 비트는 '체크섬'으로 제외
-
000~127까지 총 128개의 문자집합 중 인쇄 및 전송제어용으로 사용되는 32개의 제어 문자와 DEL을 의미하는 127번째 문자를 제외한 95개의 코드
-
매우 단순하고 간단하여 어느 시스템에도 적용할 수 있으나 2byte 이상의 코드를 표현할 수 없다.
-
한글, 한자와 같은 문자는 2개 이상의 특수문자를 합쳐서 표현해야 했으며, 문자가 깨지는 경우가 잦았다.
- 확장 아스키
ASCII 1바이트 구성에 사용되지 않았던 나머지 1비트까지 활용하여 추가로 문자를 정의한 것으로, 확장 ASCII에서 추가된 128개의 문자는 각 국가/기업에서 필요에 따라 다르게 정의하여 사용한다.
인터넷의 발달로 다른 언어를 사용한 문서 교환이 활발해졌으며, 이러한 문제를 극복하기 위해 유니코드가 등장했다.
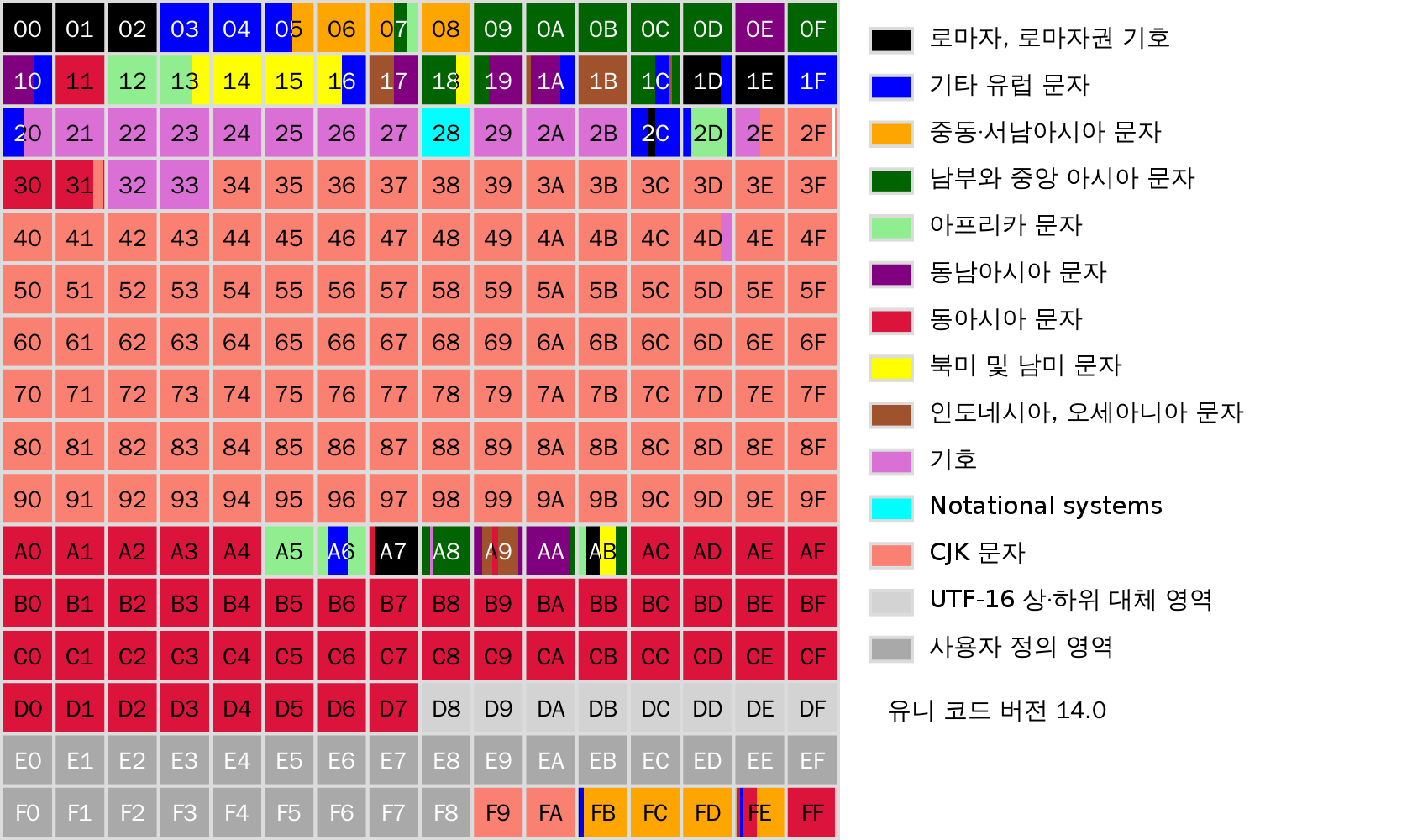
3. 유니코드
-
전 세계의 모든 문자를 컴퓨터에서 표현하기 위해 2~4바이트를 사용한다.
-
ASCII를 확장한 형태
-
인코딩/디코딩의 기준이 되는 문자열 세트(charset)의 국제 표준
-
문자에 따라 다른 길이의 바이트를 차지하기 때문에 가변길이 인코딩 방식이다.
-
길이가 가변적이므로 길이가 고정된 다른 인코딩 방식에 비해 메모리를 적게 차지한다.
-
대표적인 유니코드 인코딩 방식으로 UTF-8이 있다.
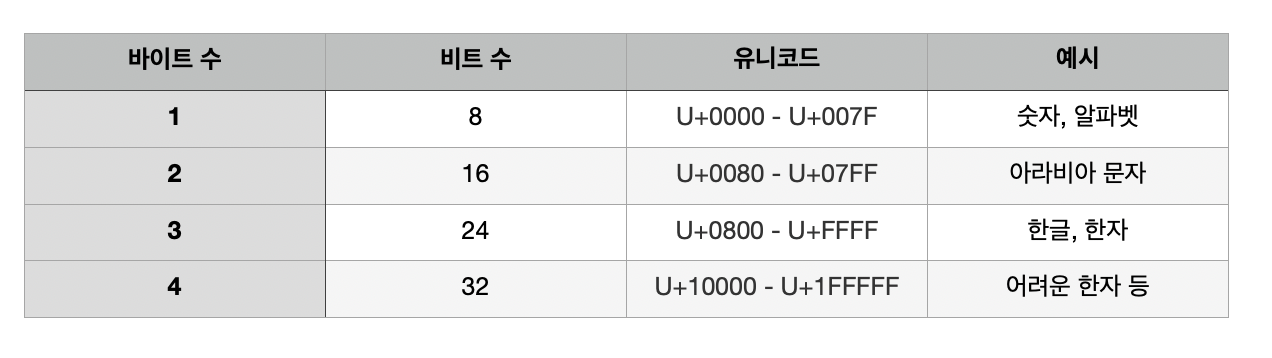
3-1. UTF-8 (가변 길이 인코딩)
-
하나의 문자를 1~4바이트의 가변 길이로 표현
-
가변 길이라 다루기 어렵지만, 영문/숫자가 1바이트로 한글이 3바이트로 표현되어 문서 크기가 작아진다.
(ASCII 코드 1바이트 / 영어 외 문자 2~3바이트 / 보조글자 및 이모지😎 4바이트) -
1바이트 영역은 ASCII 코드와 하위 호환되어, ASCII 코드의 128개 문자 집합은 UFT-8과 호환된다.
-
현재 가장 많이 쓰이는 인코딩 방식으로 뛰어난 크로스플랫폼 호환성을 갖고 있다.
3-2. UTF-16 (대부분 고정 길이 인코딩)
-
대부분의 문자를 2바이트의 고정 길이로 표현
-
고정 길이라 다루기 쉽지만, 1바이트로 표현 가능한 영문/숫자가 2바이트로 표현되어 문서의 크기가 커진다.
(한글은 2바이트를 차지한다.) -
마찬가지로 1바이트 영역은 ASCII 코드와 하위 호환된다.
-
바이트 순서가 정해지지 않아 리틀/빅 엔디안 문제가 발생해 인터넷에서 사용을 권고하지 않는다.
