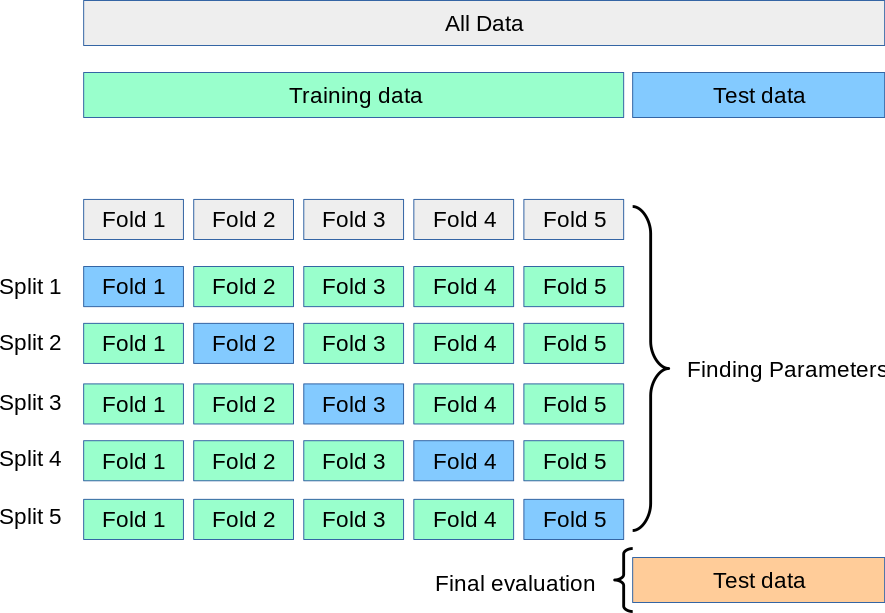
교차 검증은 데이터의 편중을 막기 위해 데이터를 여러 부분으로 나누어 각각의 부분을 학습 및 검증에 사용하는 방법이다.
Scikit-Learn에서는 cross_val_score() 함수를 이용해서 교차 검증 기법을 활용해서 정확도를 측정할 수 있다. y가 이진 클래스 또는 다중 클래스인 경우 이 함수는 StratifiedKFold를 사용한다. 다른 모든 경우, 예를 들어 회귀 문제나 다중 출력 회귀 문제인 경우에는 KFold가 사용된다.
해당 함수의 매개변수 중 cv는 정수값을 넣을 수 있다. 기본값은 5이다.
cross_val_score : sk-learn 공식 문서
StratifiedKFold vs K-fold
1. K-fold
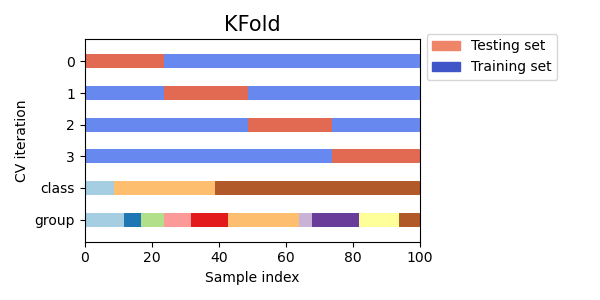
K-fold는 가장 보편적으로 사용되는 교차 검증 기법으로, K개의 데이터 폴드 세트를 만들어서 K번만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행한다.
sk-learn 공식 문서를 읽어보면, cross_val_score()에서 K-fold 사용시엔 shuffle=False로 인스턴스화(초기화)된다고 설명하고 있다. 무작위로 섞이는 것이 없어지니, 분할 자체는 원래 데이터의 순서대로 된다는 것을 알 수 있다.
2. StratifiedKFold
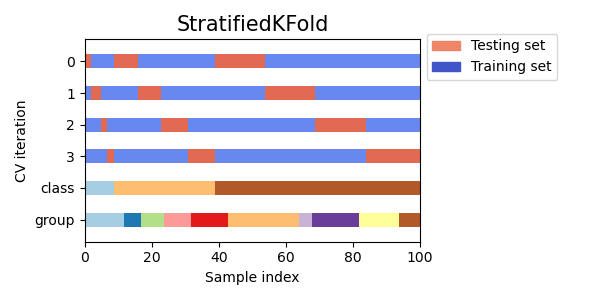
StratifiedKfold는 K-Fold의 변형으로, 계층화된 폴드를 반환한다. 각 세트는 전체 세트와 거의 동일한 비율의 각 타겟 캘래스 샘플을 포함한다.
데이터의 클래스 분포를 균형 있게 유지하면서 폴드를 나누는 것을 목적으로 하기에, 이 기법은 불균형한 데이터셋에 사용된다. 한 클래스가 다른 클래스보다 훨씬 많은 경우더라도, 각 폴드가 원본 데이터셋의 클래스 분포와 유사하도록 하여 모델이 각 클래스 샘플을 고르게 학습할 수 있도록 도와준다.
데이터 클래스 분포가 불균형하면 왜 문제일까?
5인 경우와 5가 아닌 경우를 분류하는 이진 분류기를 생각해보자. 이때 전체 10개의 숫자들은 모두 고른 비율로 데이터셋에 들어있기에, 숫자 5가 차지하는 비율은 전체의 10%라고 가정해보자.
만약 모델이 항상 5가 아니다 라고 예측하면 90%의 정확도를 쉽게 도달할 수 있다. 그러나 이는 모델이 실제로 잘 예측하는 것이 아니라 단지 클래스 불균형을 이용한 것에 불과하다.
데이터셋의 불균형으로 인해 Accuracy 항목은 성능 평가에 항상 적합할 수 없다. 높은 정확도가 곧 모델이 실제로 잘 작동한다는 것을 의미하지는 않는다. 정밀도(precision), 재현율(recall), F1-score 등 다른 평가 지표를 사용하는 것이 더 적절할 수 있다.
