YOLOv5
오늘은 YOLO v5 모델에 대해서 공부해보겠습니다 두둥
욜로~
욜로는 딥러닝 기반으로 객체를 인식해주는 모델이랍니다
실행 환경
Colab 환경에서 실행해주겠습니다.
우선 깃헙에서 모델을 가져올게요
런타임 유형을 GPU로 바꾸고
여러 사양들을 확인해봤습니다
데이터셋 준비
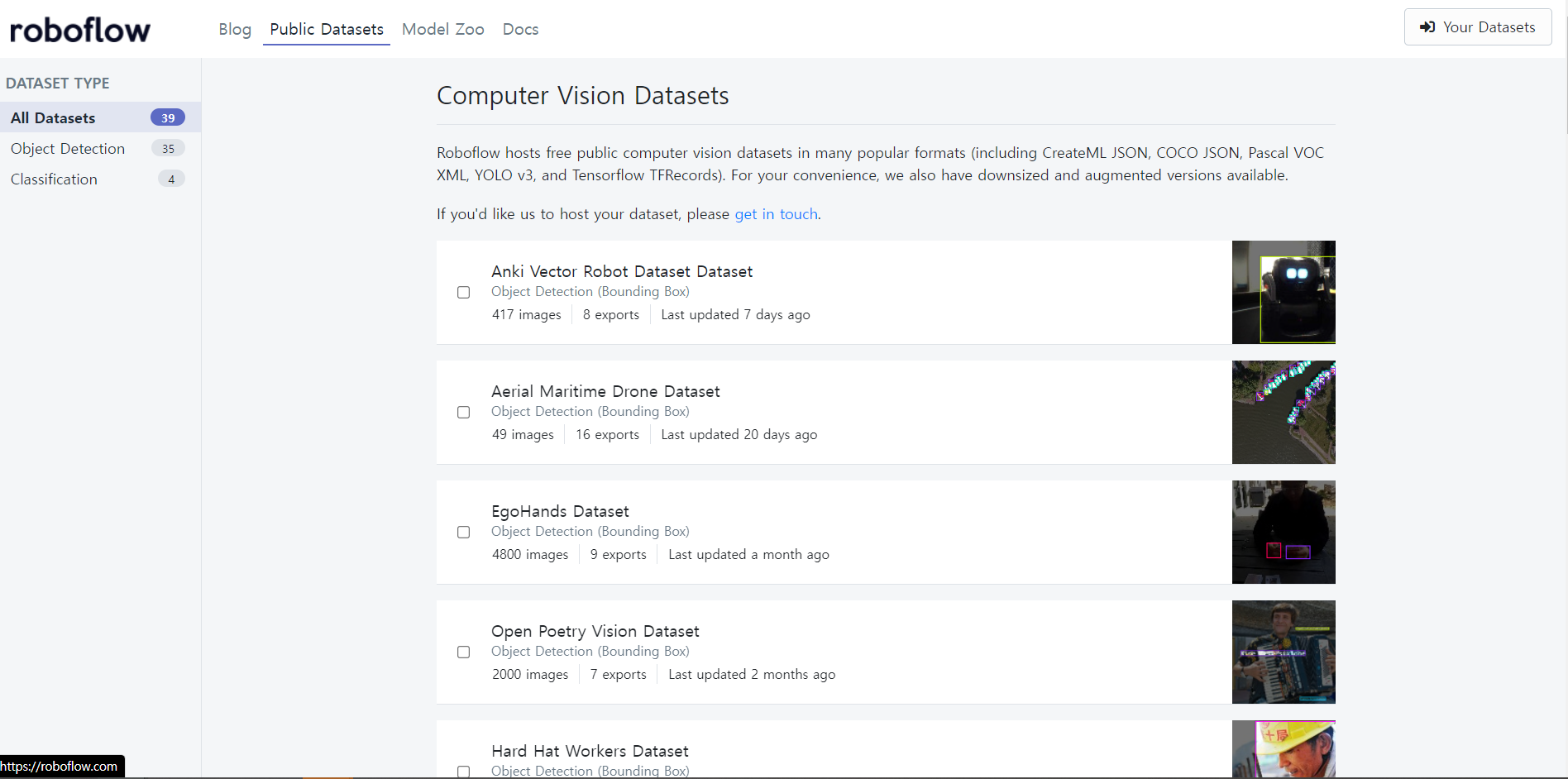
Roboflow 에서 dataset을 다운받아줍니다.
오늘은 Hard Hat Workers Datasets를 쓸게요
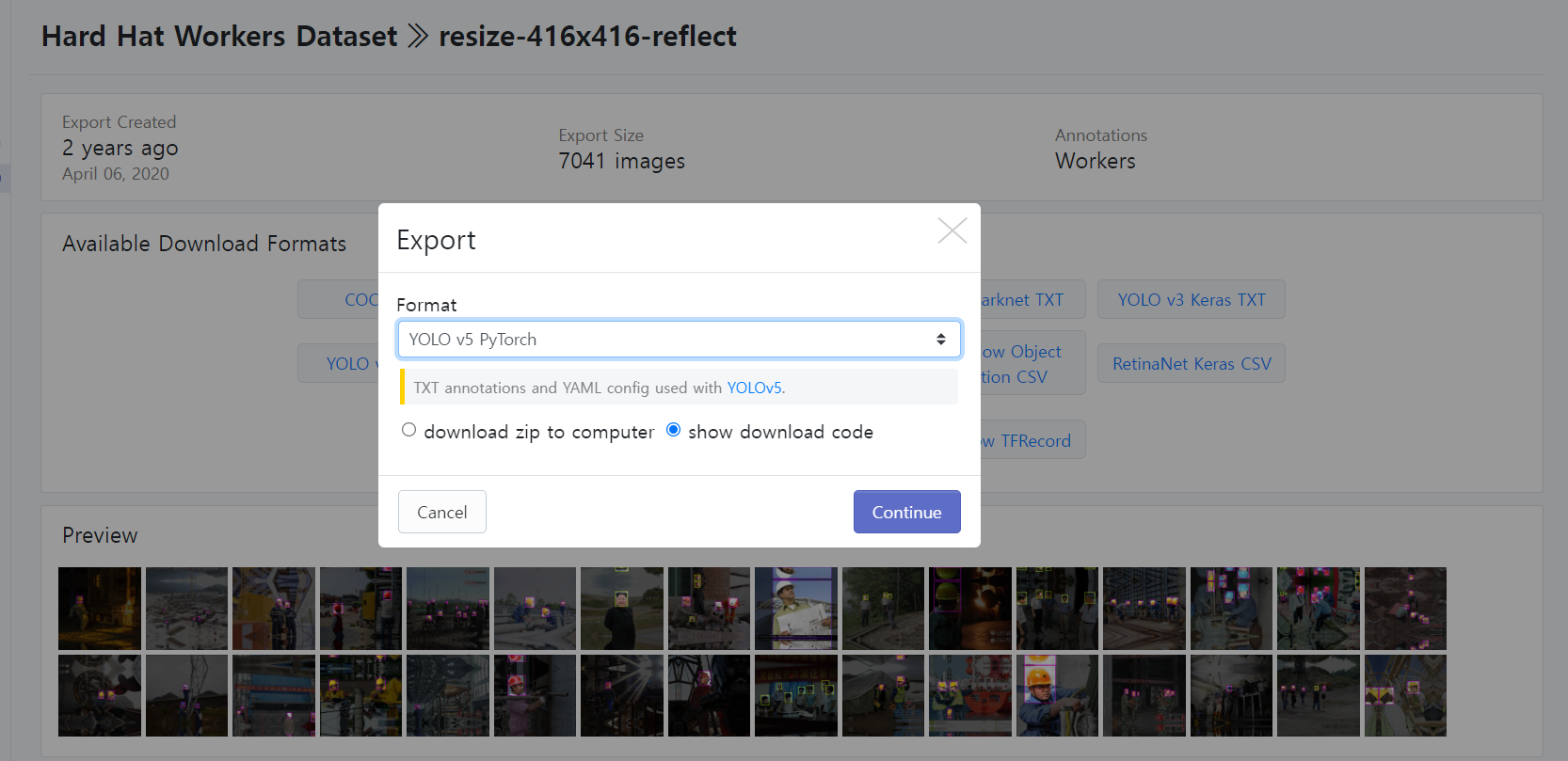
포맷은 YOLO v5에서 돌릴거니까 YOLO v5 PyTorch로 설정해주고
깃허브로 로그인 하면 다운받을 수 있는 링크가 나온답니다
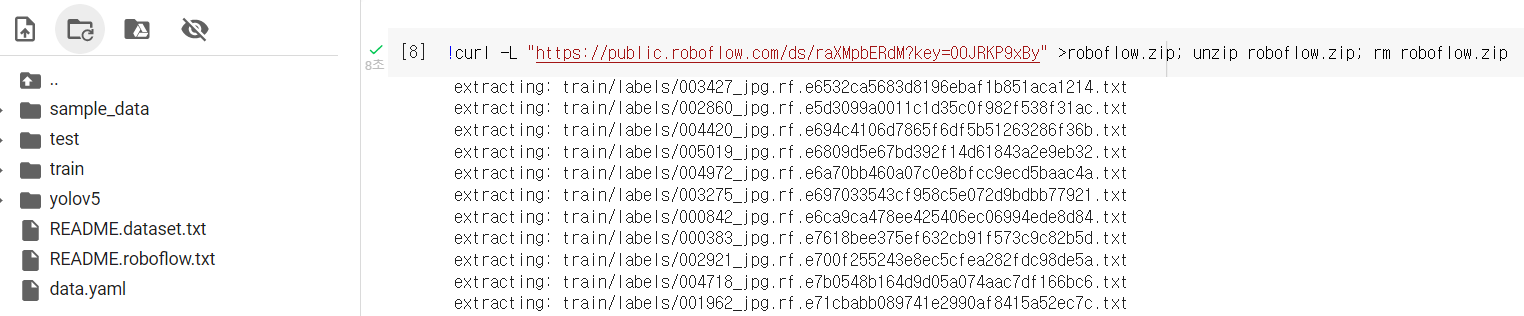
링크 복사해서 데이터셋 다운받아주기!!
옆에 파일 목록에서 새로고침 했더니 잘 받아진걸 볼 수 있군요

train 데이터를 살펴보니 이미지와
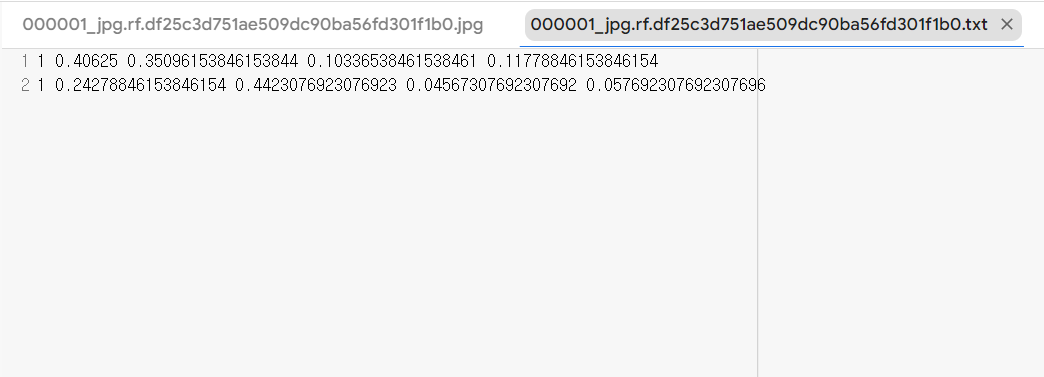
해당 이미지의 label이 있네요
이 데이터는 헬맷을 쓴 인부들의 이미지에서 헬맷을 탐색하기 때문에
label의 각 줄은 object가 있는 X좌표, Y좌표, Width, Height을 뜻합니다
..데이터가 너무 흩어져있길래 모아줬습니다
YOLOv5를 실행하기 위한 준비
오른쪽의 requirements.txt는 yolov5모델을 실행하기 위해 요구되는 실행환경들입니다
설치설치~
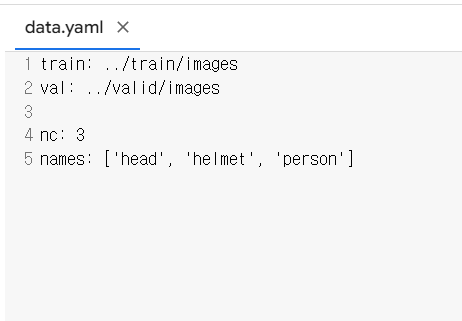
아까 다운받은 dataset폴더에 있는 data.yaml 파일을 보면
train, validation data의 경로, Nc(클래스 개수), Names(클래스 이름)이 있네요
여기서 제 경로에 맞게 데이터 경로를 수정하고,
train데이터와 validation data를 나눠주겠습니다
train data:모델 학습을 위한 데이터
validation data:모델 검증을 위한 데이터
train, validation data 나누기
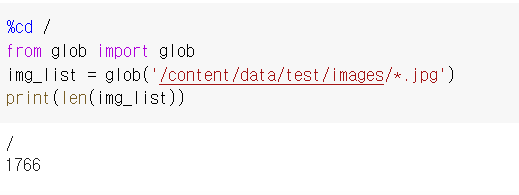
glob 패키지를 사용해서 dataset에 있는 모든 jpg이미지를 불러왔습니다
총 1766개의 이미지가 있군요

sckit-learn 에서 train_test_split 을 import 하고
train_img_list 와 val_img_list를 나누어줄게요
train:val = 8:2 로 설정했기 때문에 test_size는 0.2
그래서 위의 1766개의 이미지가 train data 1412 개 validation data 354개로 잘 나눠졌답니다
train / val data list를 담은 txt 파일을 만들어줬어요

앞서 말했던 yaml 파일의 파일 경로들을 수정해줄게요
학습하기
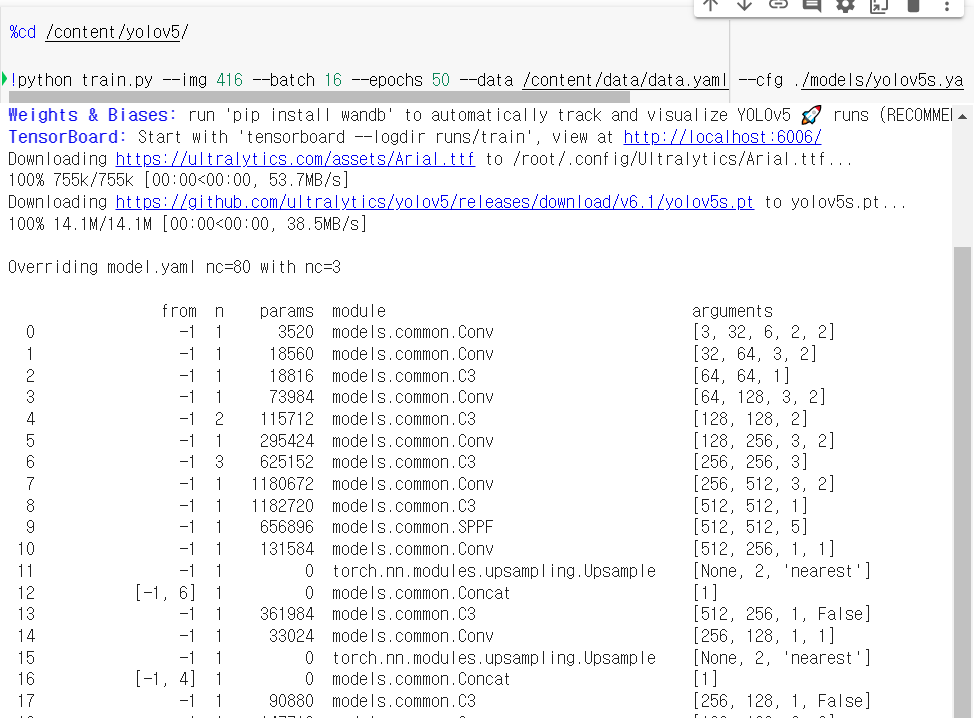
%cd /content/yolov5/
!python train.py --img 416 --batch 16 --epochs 50 --data /content/data/data.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt --name hat_yolov5s_result
각종 arguments 값을 지정해주고 train코드를 돌렸습니다

epoch 50까지 열심히 돌아가는중...
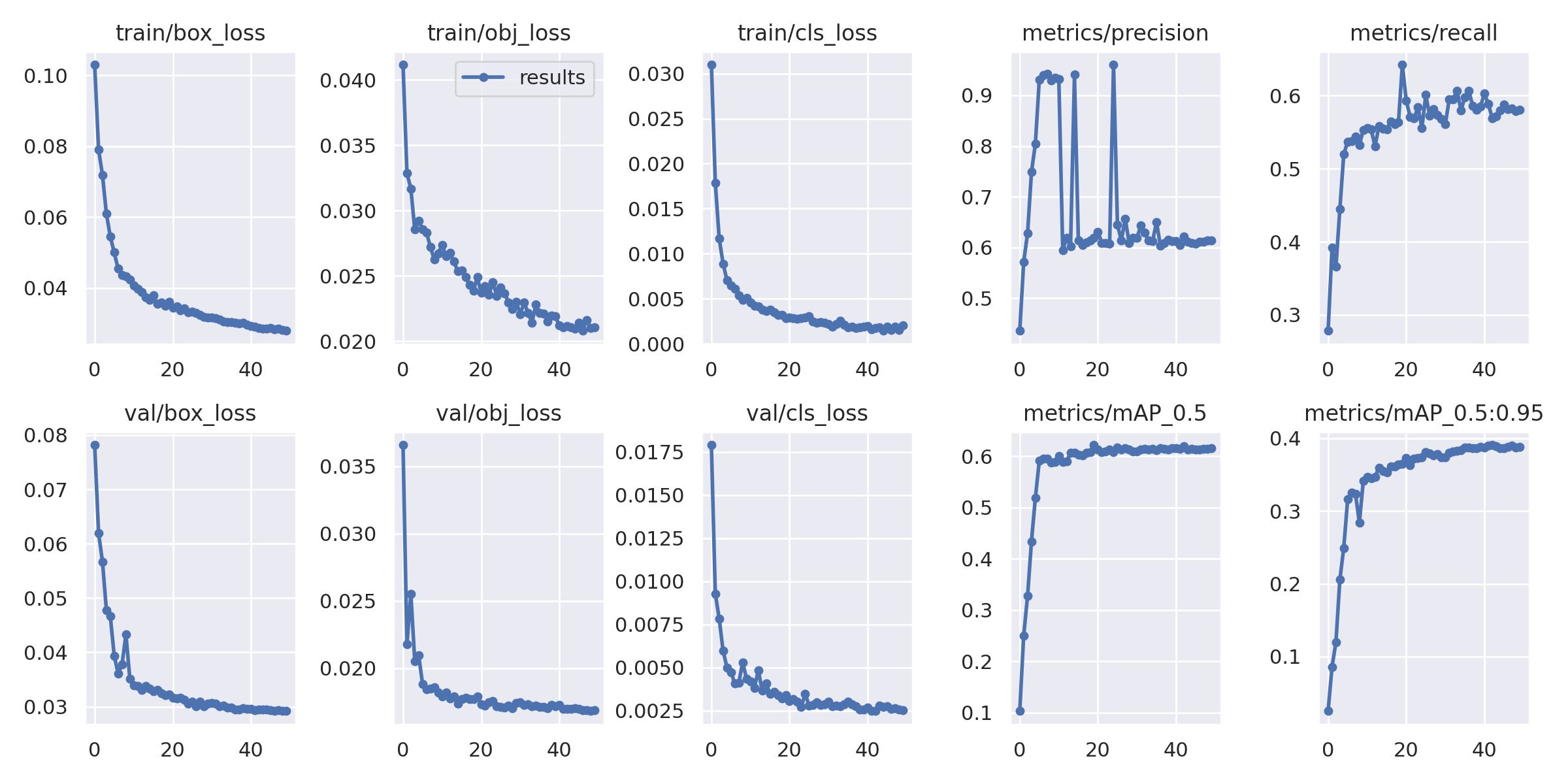
학습 결과

짜잔
train data의 라벨링 결과입니다

이건 validation data의 라벨이구요

validation data의 예측결과입니다
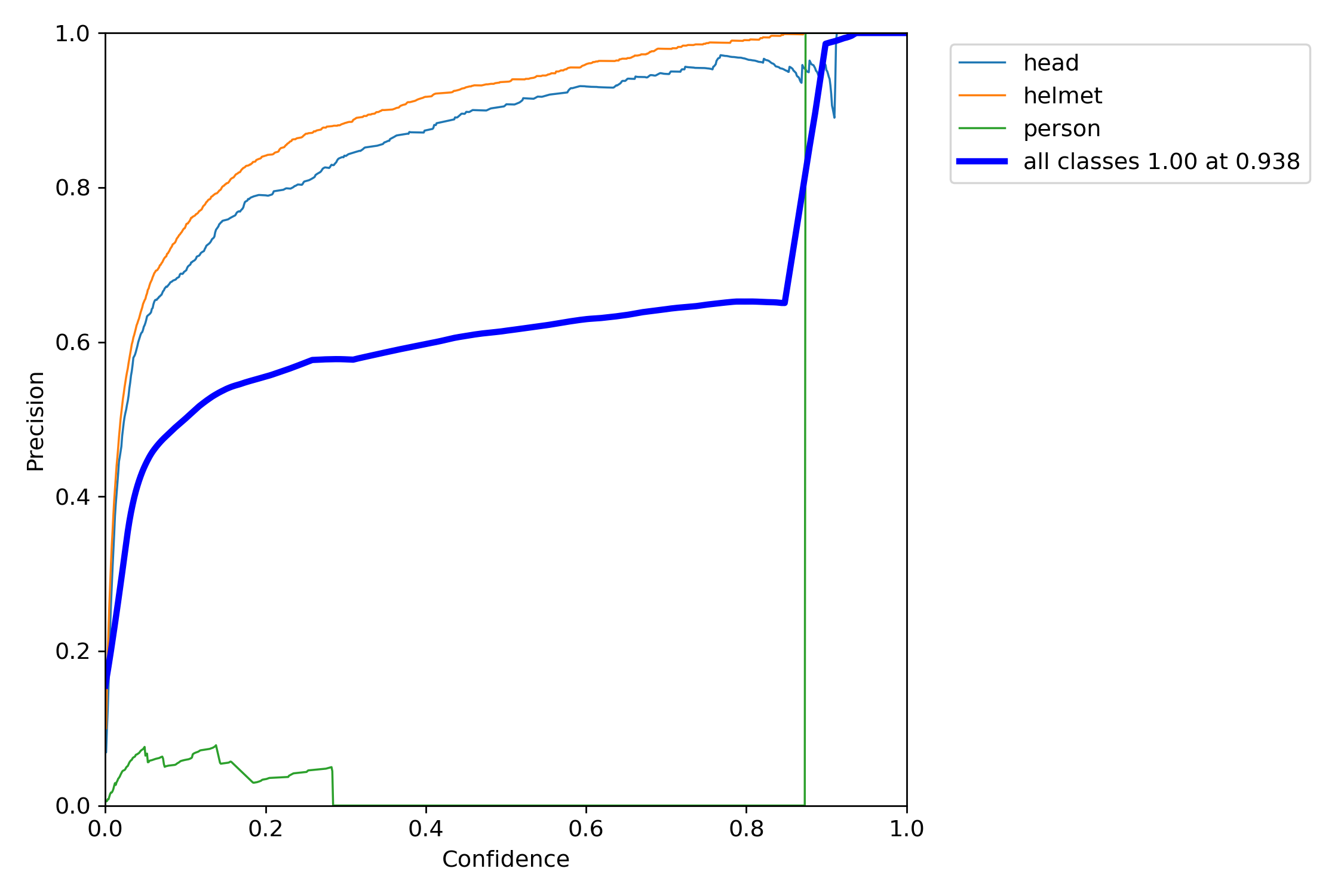
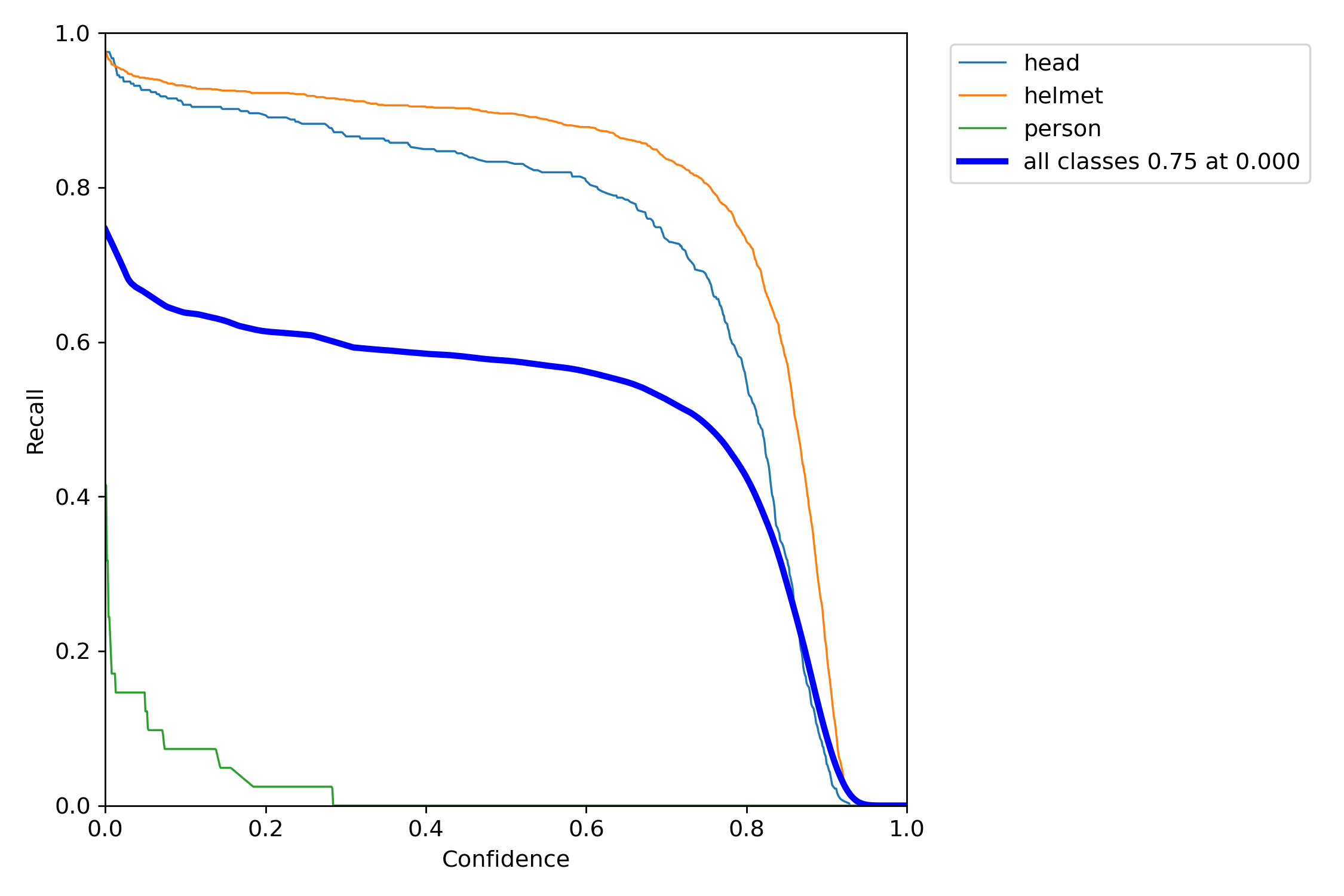
성능 평가
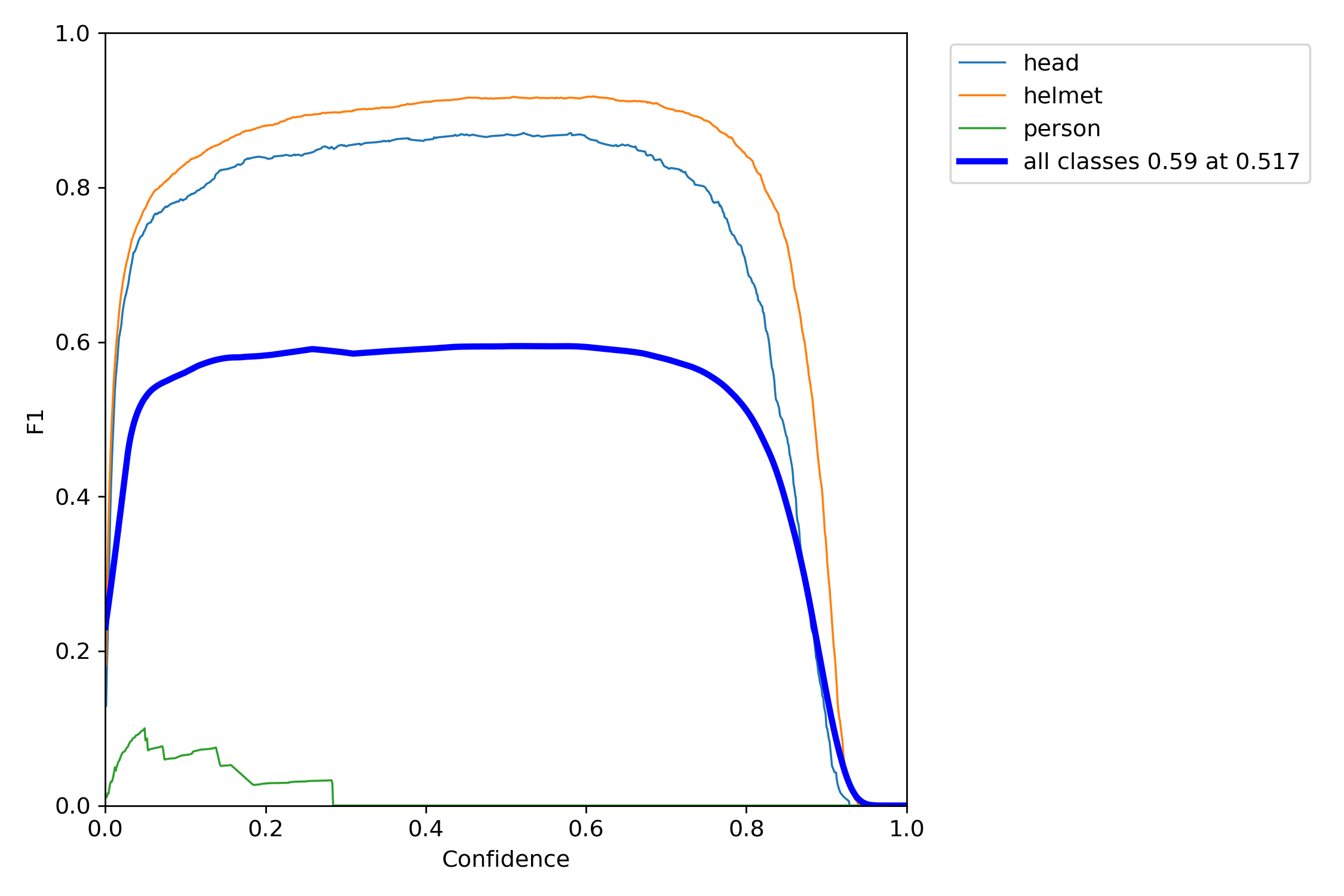
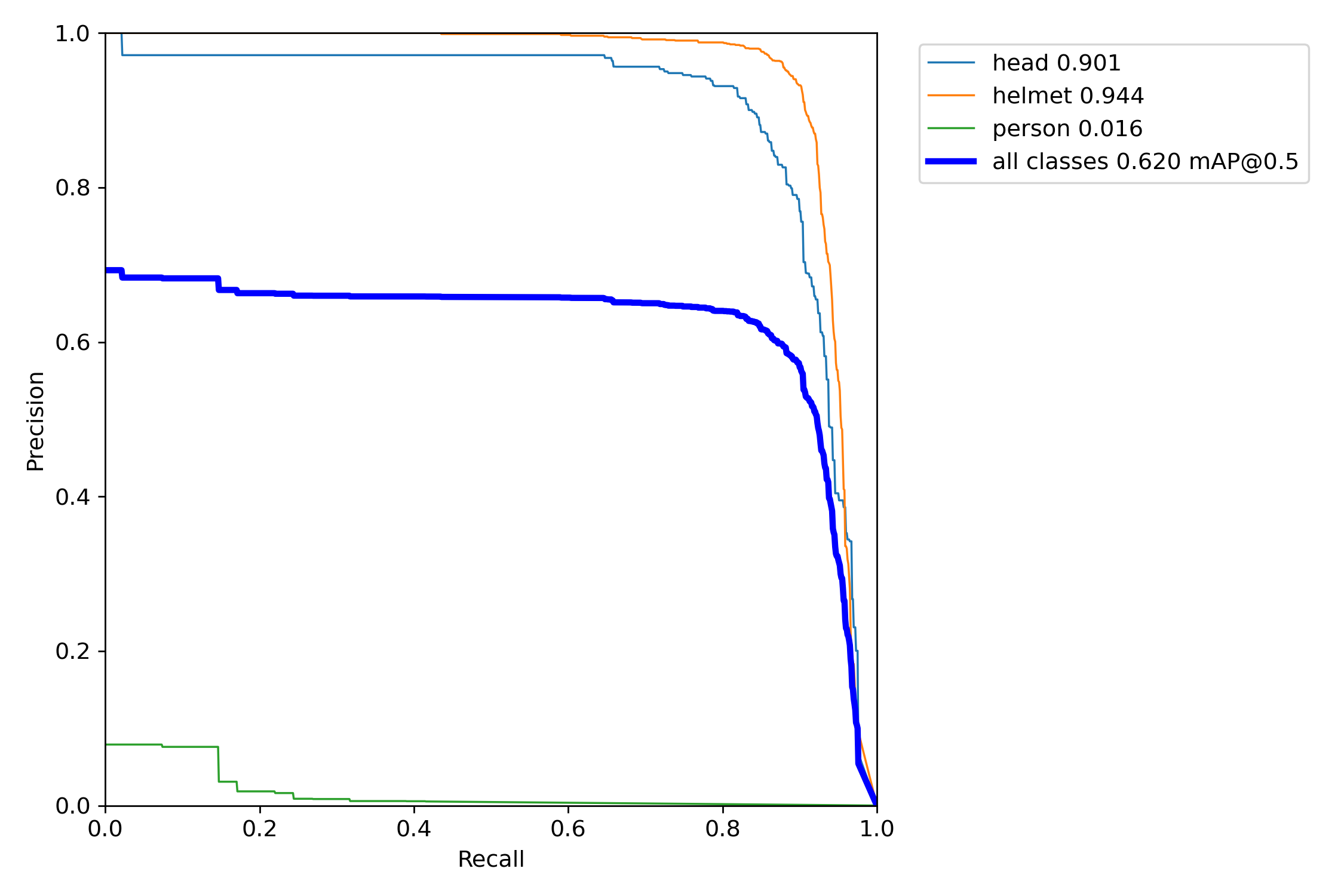
네가지 지표로 성능을 평가해볼게요
F1 score
PR score
P score
R score
loss