The Google File System
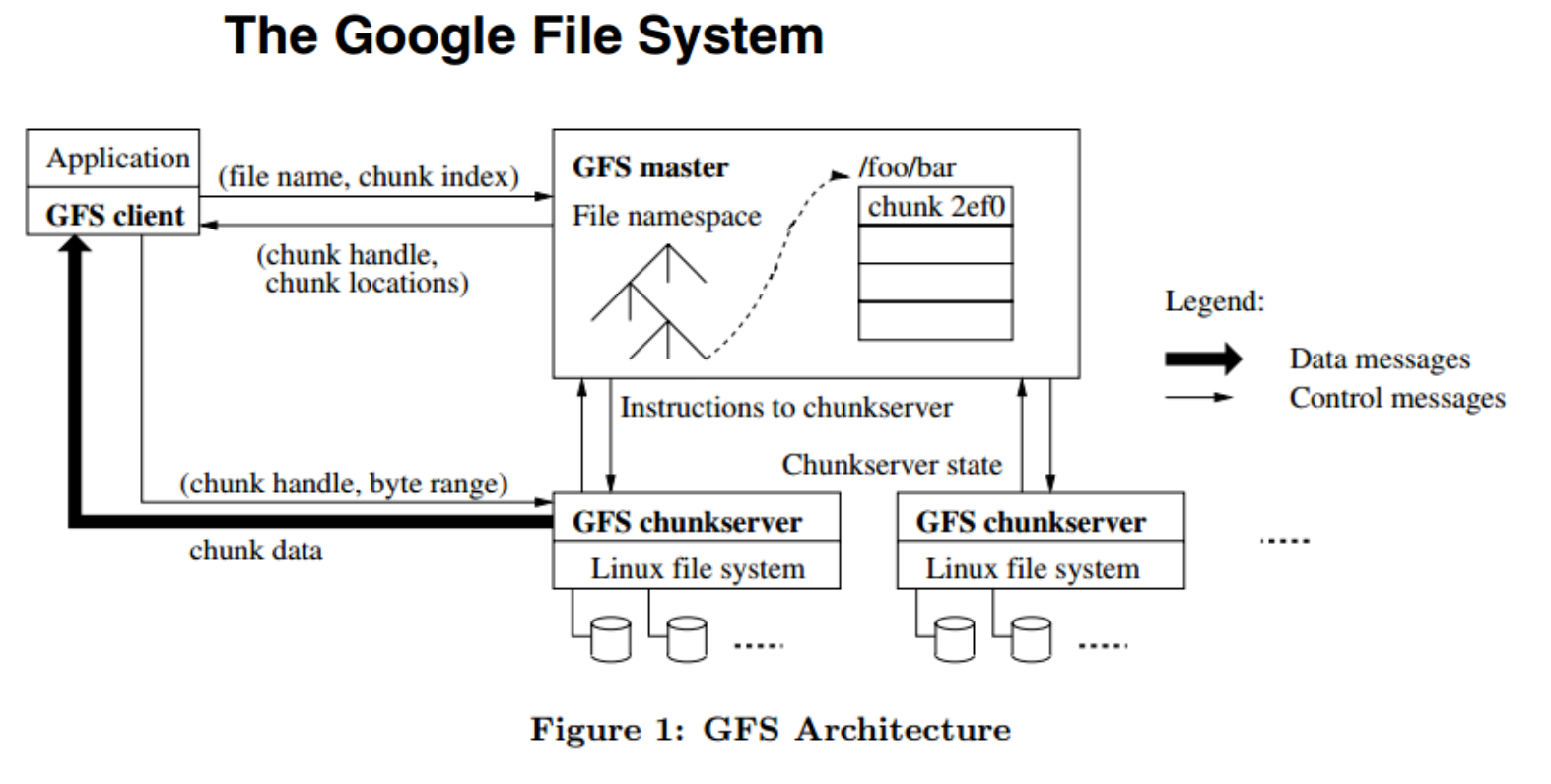
- 하둡 분산 파일 시스템은 GFS의 논문을 보고 따라 만든 것
- 따라서 GFS와 동일하게 master - slave 구조로 이루어져 있음
- 분산 처리 시스템은 master/slave 구조 혹은 master가 없는 구조 (모두가 같이 공유, 관리) 로 나뉨
- 데이터 저장의 확장성이 높음
GFS 구조
- client : GFS client
- master : GFS master
- slave : GFS chunkserver
client --요청--> master --응답--> client
- 요청 : 내가 저장한 파일 어디있는지 알고싶어
- 응답 : 해당 쪼개진 데이터 (chunk data) 가 어디에 저장되어 있는지 알려줄께 (어떤 chunkserver가 가지고 잇는지)
- control 메세지들만 왔다갔다함.
client --데이터요청--> chunkserver --응답--> client
- 데이터 요청 : client가 master에서 어느 데이터가 어디있는지 알아왔으니 해당 chunkserver로 가서 데이터를 요청
- 응답 : 요청한 곳에 있는 데이터를 반환
- 실제 데이터들이 왔다갔다함.
HDFS
HDFS architecture
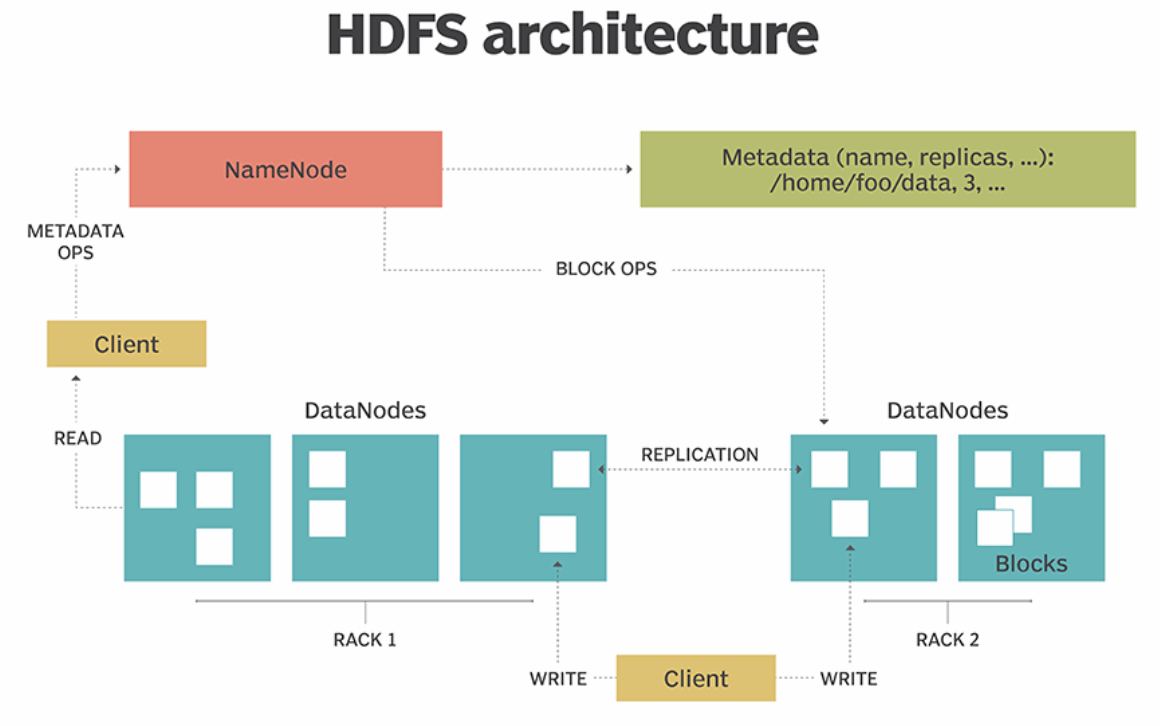
- 마스터(Namenode) , 슬레이브(DataNode) 구조
- 큰 파일을 여러개의 Block으로 나누어서 저장
- 슬레이브 노드의 쉬운 확장 가능
- 신뢰성 보장 : 데이터 복제본 자동 관리
- 한번 쓰고 많은 읽기가 있는 오퍼레이션에 최적화 (log성 데이터)
- rack 안에 여러 서버들이 껴져있음.
Block
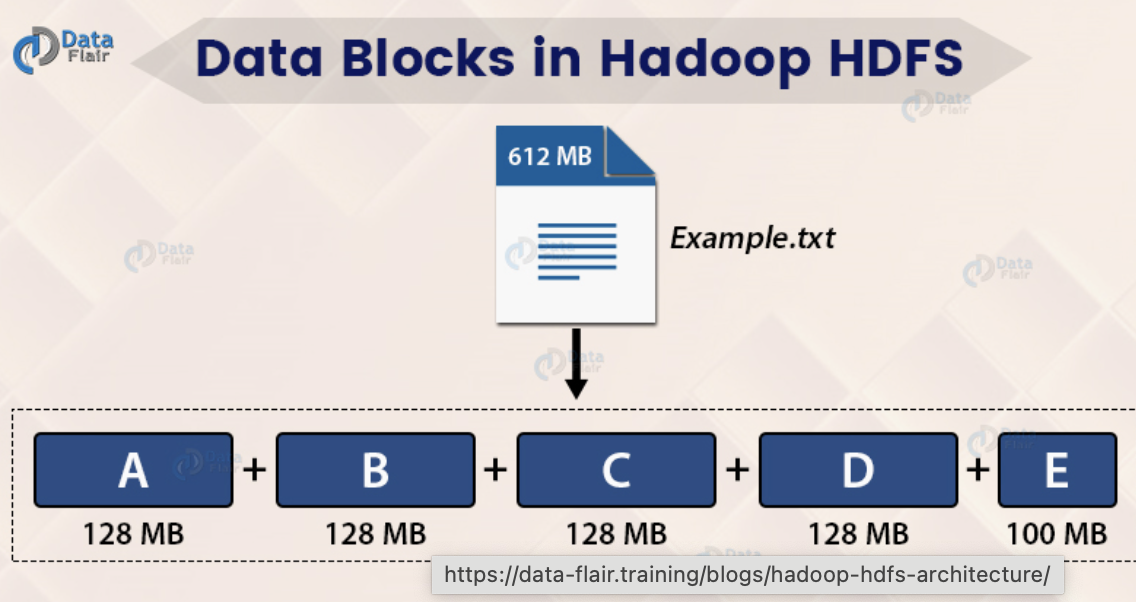
Block 기본
- 하둡은 큰 데이터(파일 자체가 큰 데이터)를 빠르게 저장하기에 최적화 (작은 데이터라면 적합하지 않음)
- 하나의 파일을 여러개의 Block으로 저장을 함
- 큰 데이터가 들어오면 각각 나누어서 DataNodes에 저장되어 있고 이에 대한 정보는 Name Node가 처리
- 현재, default 값이 128MB이며 64MB도 가능함
- 블록 크기가 128MB 보다 적은 경우 실제 크기 만크만 용량을 차지함
예시
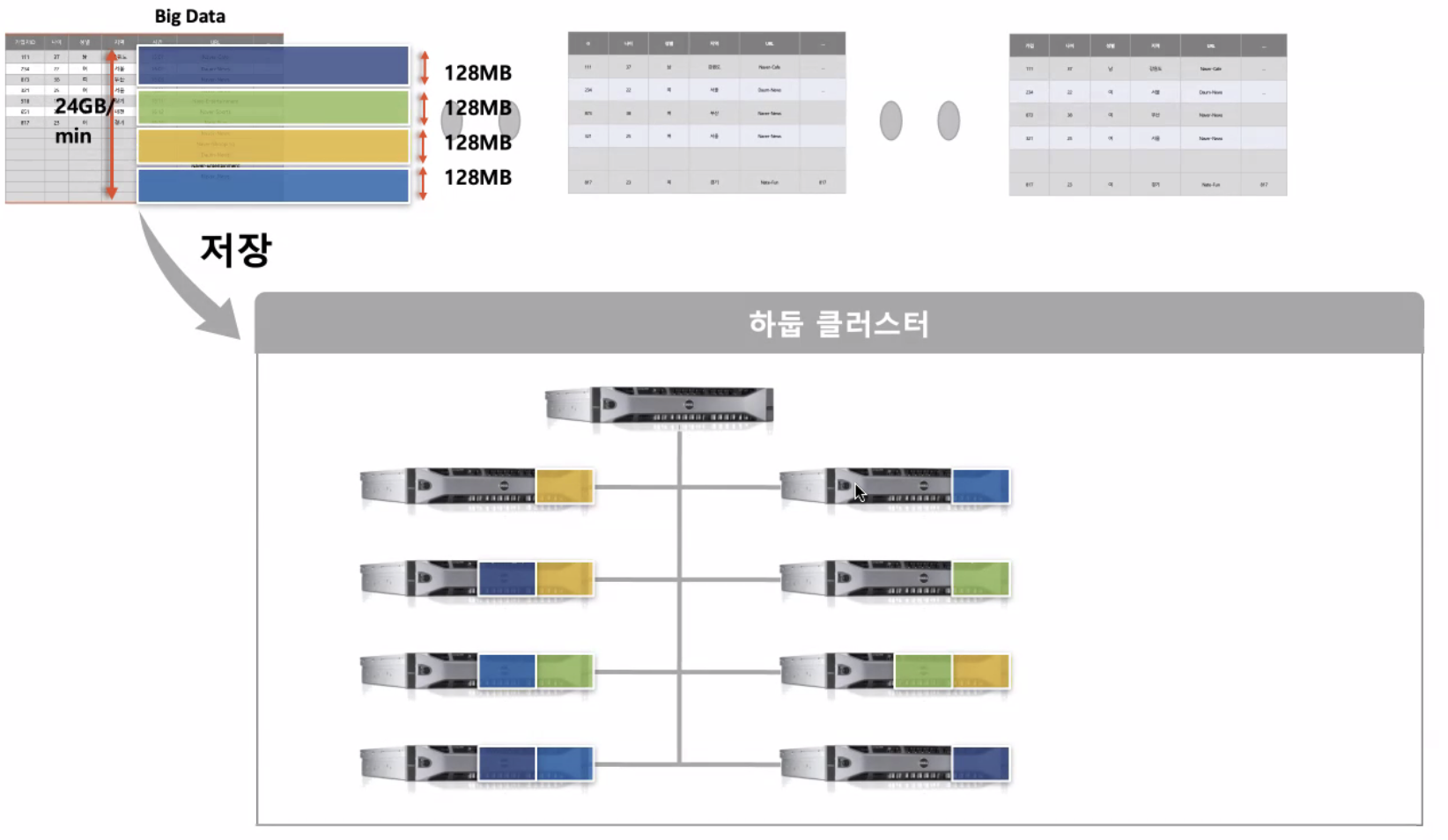
- log 데이터가 분당 2.4GB로 들어온다고 생각해보자.
- 하둡에 128MB 씩 저장을 하게 됨.
-
하나의 블럭이 3개의 서로 다른 서버로 나누어서 저장이 됨(복제).
-
이때 맨 위, Name node에는 데이터의 위치와 형식을 보관
-
Data node(slave)에는 실 데이터가 저장됨.
-
만약 한개의 서버에 장애가 나면(네트워크 통신), Name node는 Heartbeat을 통해서 장애가 난 것을 판단함.
- 몇초 마다 한번씩 data node는 Heartbeat 통신으로 자신이 잘 띄워져 있다고 Name node에게 알림
-
Name node는 해당 서버가 가진 데이터가 어디에 복제되어있는지 판단할 수 있음.
-
해당 데이터들을 다른 서버에 복사해서 넣어놓음.
-
그리고 난 후 해당 서버가 고쳐지게 되면 (Heartbeat 통신이 다시 오면) 복제본이 4개이기 때문에 다른 서버에서 지워서 3개로 유지시켜줌. -> 안전성 보장
하둡 클러스터가 장애가 날 수 있는 point
- 네임 노드 고장 -> 버전 관리로 해결 (이중화)
- 복제본을 만들 서버가 없을 때,즉 동시에 여러대가 장애 발생 시.(화재..)
- 하나의 렉에 전원이 꺼졌을 때. (렉 스위치 고장, 전원 꺼짐 등등) -> 스위치, 전원 이중화 혹은 각 block의 복제본들의 rack 분리 설정 가능 [rack awarness]
Block 메모리
- HDFS의 블록은 128MB와 같은 매우 큰 단위
block 하나의 크기가 큰 이유는?
- 전체 블록 정보에 대한 메타 정보 크기가 작아짐 (네임노드 메모리 효율적 사용가능)
- 탐색 비용 최소화 (I/O 비용이 크기 때문에)
- 하드디스크에서 블록 시작점을 탐색하는데에 시간이 적게 걸림. => 네트워크를 통해 데이터 전송하는데 더 많은 시간 할당 가능
Block 장점
블록 크기 분할과 추상화에 따른 이점
- 같은 파일을 분산 처리하여 데이터 처리 성능을 개선할 수 있음.
- 블록 단위로 나누어 저장하기 때문에 디스크 사이즈보다 더 큰 파일을 보관할 수 있음.
- 파일 단위보다 블록 단위로 추상화를 하면 스토리지의 서브 시스템을 단순하게 만들 수 있음.
- 파일 탐색 지점이나 메타정보를 저장할 때 사이즈가 고정되어 있어서 구현이 용이
- 내고장성을 제공하는데 필요한 복제(replication)을 구현할때 매우 적합
- 같은 노드에 같은 블록이 존재하지 않도록 복제하여 노드 고장시 다른 노드의 블록으로 복구할 수 있음.
Block 의 지역성
- 네트워크를 이용한 데이터 전송 시간 감소 ( 다른 datanodes에 있는 것을 확인하고 복제할 필요가 없어서)
- 대용량 데이터 확인을 위한 디스크 탐색시간 감소
- 적절한 단위의 블록 크기를 이용한 CPU 처리 시간 증가
Node
Name Node
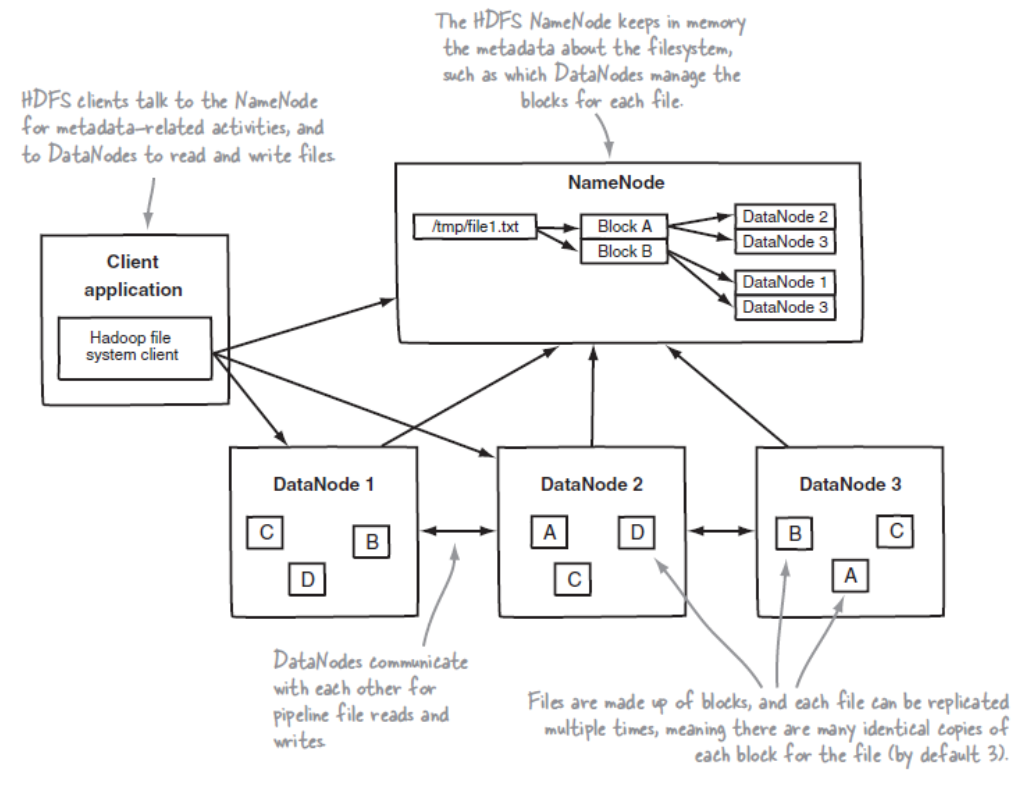
역할
-
DateNode들의 메타데이터들을 가지고 있음.
-
전체 HDFS에 대한 Name Space 관리
-
DataNode로 부터 Block 리포트를 받음
- 정상적 상황에서 있다가도 disk 장애가 나기도 함.
- 이를 인지하고 복구를 해야함.
- dataNode가 주기적으로 자신을 스캔해서 정상, 비정상 정보들을 namenode에게 알려줌.
-
Data에 대한 Replication 유지를 위한 커맨더 역할 수행 -> Relication 갯수 설정 가능
-
파일 시스템 이미지 관리 (fsimage)
-
파일시스템에 대한 Edit Log 관리(edits)
- name node에 메모리를 프로세스 메모리에 저장함
- 메모리는 휘발성이기 때문에 사라지지 않도록 관리가 필요함
- 파일 시스템의 메타정보가 변경, 추가, 삭제에 대해 메모리에 먼저 반영
- 변경이력을 Edit log에 적어줌
- 메모리가 사라지더라도 log를 보면서 하나하나 반영함. (restart하면 )
보조 네임노드 (SNN)
-
네임노드와 보조네임 노드가 존재함
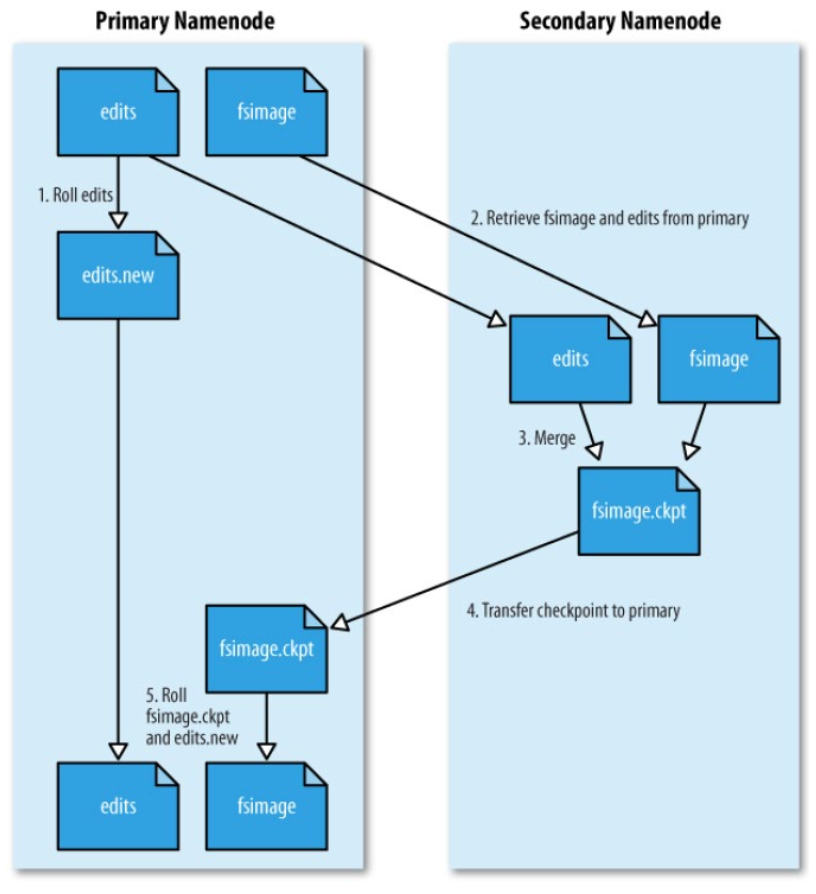
-
네임 노드는 Active/standby 구조가 아님
- 서버가 이상해졌을때 대신 사용하는 거 아님
-
fsimage 와 edits 파일을 주기적으로 병합함 (배치처리)
-
image의 check point
- 한시간 주기로 실행
- edits 로그가 일정 사이즈 이상히면 실행
-
edits 로그가 무한대로 커지지 않기 위한 방안
-
이슈
- 네임노드가 SPOF
- 보조네임노드의 장애 상황 감지 툴 없음
DataNode
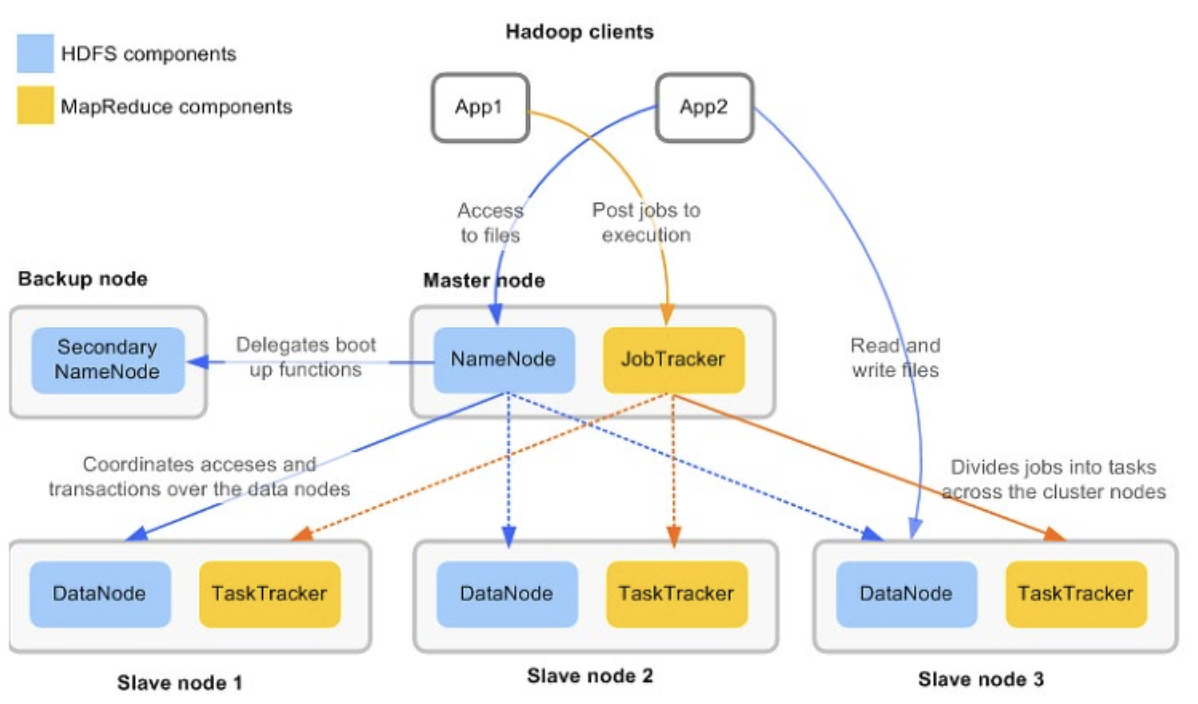
-
파란색 : 데이터 저장 (HDFS)
-
노란색 : 데이터 처리 (MapReduce)
-
데이터 노드는 물리적으로 로컬 파일시스템에 HDFS데이터를 저장
-
DataNode는 HDFS에 대한 지식이 없음
-
일반적으로 레이들르 구성하지않음
-
블록 리포트 : NameNode가 시작될 때, 주기적으로 로컬 파일 시스템에 있는 모든 HDFS블록들을 검사한 후 정상적인 블록의 목록을 만들어 NameNode에 전송
-
slave node에는 datanode(파일 저장시스템) , tasktracker(맵리듀스 파일 처리 시스템) 함께 있음.
HDFS 연산 처리
- 읽기
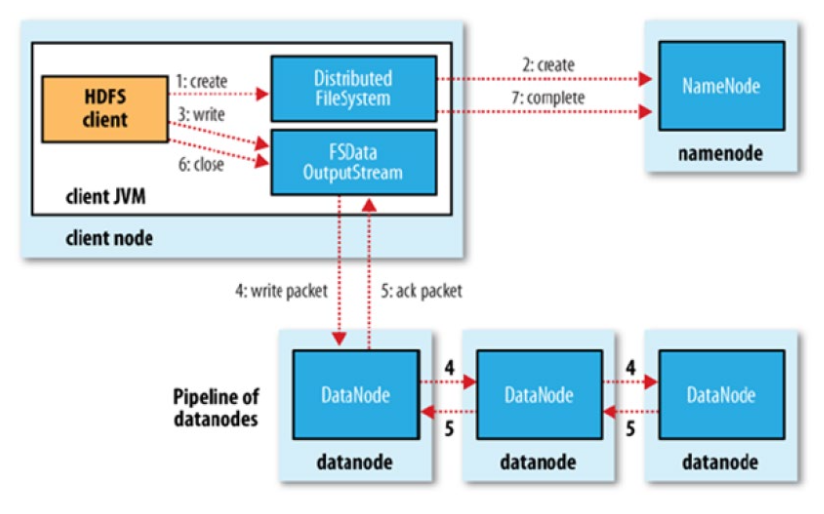
- 쓰기

