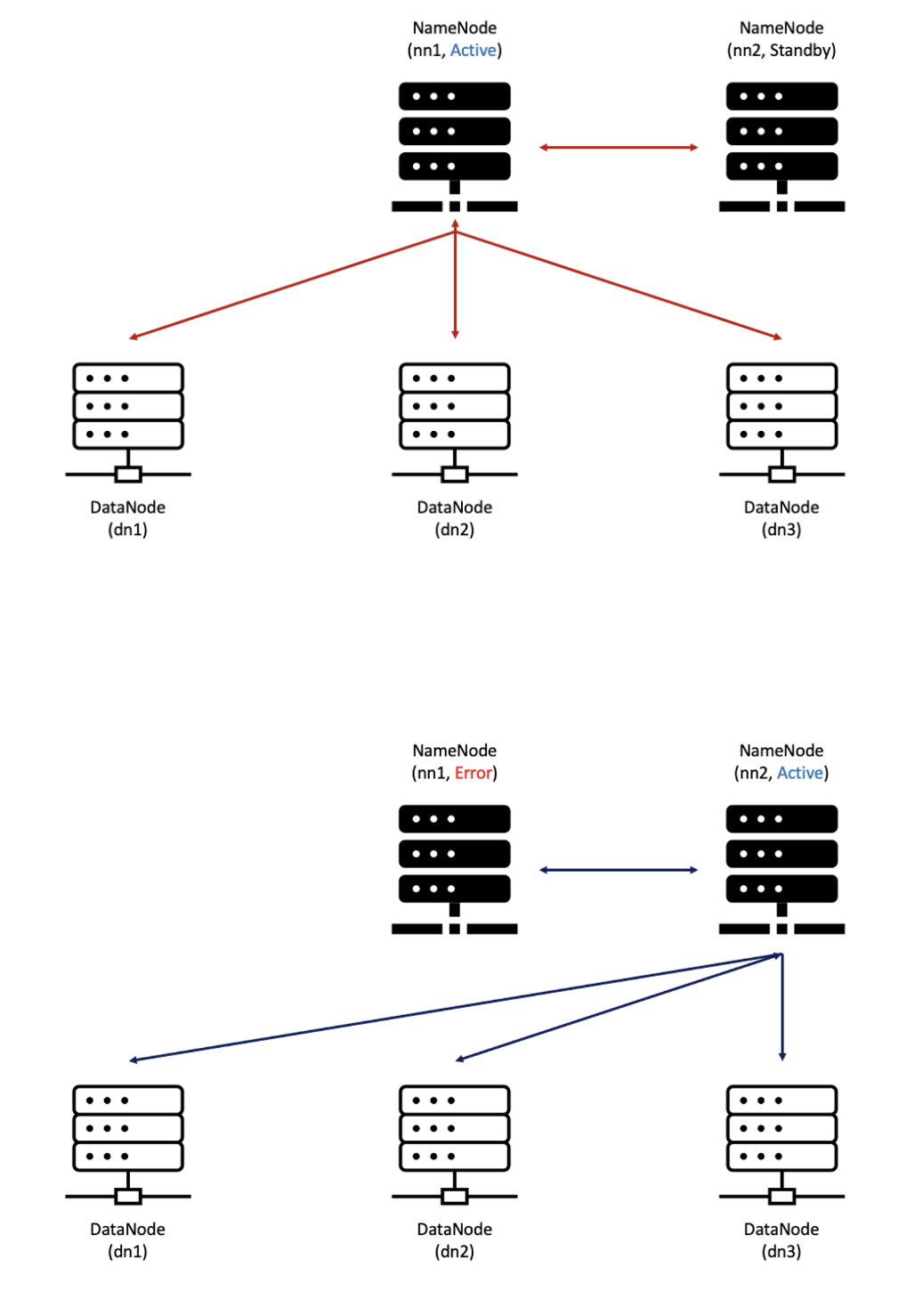
Hadoop 구성
구성 방식
| 정상 | error |
|---|---|
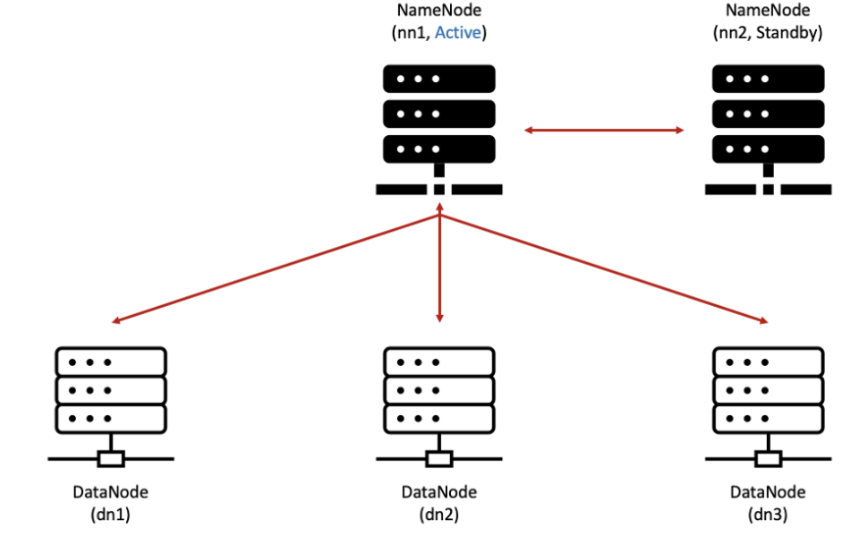 | 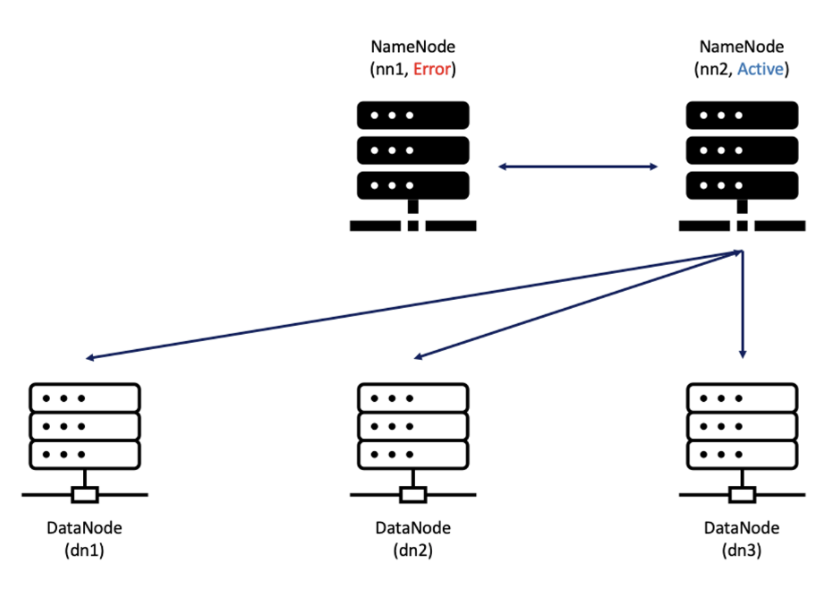 |
총
마스터 3개
- hadoop-master-1
- NameNode
- ZooKeeper
- ReourceManager
- HiveServer2
- hadoop-master-2
- NameNode
- ZooKeeper
- ReourceManager
- hadoop-master-3
- ZooKeeper
- RDB ( Hive 이용)
클러스터로 띄우기 위해서는 Zookeeper가 꼭 필요함
슬래이브 3개
- hadoop-slave-1
- NodeManager
- DataNode
- Kafka Broker
- worker
- hadoop-slave-2
- NodeManager
- DataNode
- Kafka Broker
- worker
- hadoop-slave-3
- NodeManager
- DataNode
- Kafka Broker
- worker
EC2 설정
- ubuntu 24.04 LTS
- t3.large
- 보안 그룹은 all traffic 열어줌 ( 내 ip만 )
- 40GB
- key pair
key pair
ubuntu 접속
.ssh/authorized_keys 보면 맨 뒤의 내가 만든 키 있음
ssh-keygen -t rsa하고 계속 엔터치면 키가 생성됨

id_rsa : key 값 (들어갈 때 사용하는 열쇠) [pem파일] / 클라이언트의 개인 키 파일
id_rsa.pub : 죄물쇠 (인증) / 클라이언트의 공개 키 파일
authorized_keys
- 서버에 저장되어 클라이언트의 공개 키를 검증하는 파일.
- 접속할 때 인증 key값이 제대로 들어왔는지 확인하는 값들이 들어있는 것
- 처음 ubuntu 서버에 들어가면 내가 다운받은 key에 맞는 .pub값만 들어가 있음
- 따라서 key pair를 생성했으면 authorized_keys에 append 해줘야함
cat >> ~/.ssh/authorized_keys < ~/.ssh/id_rsa.pub
=> 이를 해주는 이유는 내가 만든 ec2에 모두 쉽게 접근하기 위함
=> 왜냐면 우리는 지금까지 만든 ec2 를 만들고 img를 만들어서 복제해줄 것 이기 때문에
서버에 java 설치
1) 라이브러리 설치 : apt-get 라이브러리 설치
# EC2 Ubuntu terminal
# 설치 가능한 리스트 업데이트
$ sudo apt-get -y update
# 업데이트한 패키지들을 최신 버전에 맞게 업그레이드
$ sudo apt-get -y upgrade
# 의존성까지 체크해서 업그레이드
$ sudo apt-get -y dist-upgrade
# 필요 라이브러리 설치
$ sudo apt-get install -y vim wget unzip ssh openssh-* net-tools tree
# Ubuntu 20.4 에는 native libray 인 snappy 가 설치되어 있지 않다.
# 아래 snappy 설치를 하지 않으면 하둡 설치 후 snappy 사용 시 에러가 발생한다.
$ sudo apt install libsnappy-dev -y
2) java 8 설치
# EC2 Ubuntu terminal
# Java 8 설치
$ sudo apt-get install -y openjdk-8-jdk
# Java 버전 확인
$ java -version
# Java 경로 확인
$ sudo find / -name java-8-openjdk-amd64 2>/dev/null
# /usr/lib/jvm/java-8-openjdk-amd643) java 환경변수 설정
# EC2 Ubuntu terminal
# Java 시스템 환경변수 등록 및 활성화
$ sudo vim /etc/environment
# 아래 내용 추가 후 저장
PATH 뒤에 ":/usr/lib/jvm/java-8-openjdk-amd64/bin" 추가
JAVA_HOME="/usr/lib/jvm/java-8-openjdk-amd64"
# 시스템 환경변수 활성화
$ source /etc/environment
# 사용자 환경변수 등록
$ sudo echo 'export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64' >> ~/.bashrc
# 사용자 환경변수 활성화
$ source ~/.bashrc4) 등록 확인
env | grep JAVA하둡 에코시스템 베이스 이미지 설치
1) Snappy native library 설치
sudo apt install libsnappy-dev -y2) Mariadb Client 설치
- Hive 에서 사용하는 Metastore 로 Mariadb 사용
- meta 정보 관리
sudo apt-get install -y mariadb-client3) Python 설치
sudo apt-get install -y python3-pip4) Anaconda 설치
- 설치 스크립트 다운로드
mkdir ~/downloads && cd downloadswget https://repo.anaconda.com/archive/Anaconda3-2023.03-Linux-x86_64.sh- 아나콘다 설치 스크립트 실행
bash Anaconda3-2023.03-Linux-x86_64.sh- 설치과정
Enter키를 누름- MORE 나오면
스페이스바클릭 - 라이선스 동의:
yes입력 - 설치 경로: 기본 경로를 사용하려면
Enter키를 누르세요. conda init실행: 설치 완료 후 Conda를 초기화하려면yes를 입력
- 환경 변수 적용
source ~/.bashrc5) 가상환경 생성
- pyspark 콘다 가상환경 생성
conda create --name pyspark python=3.8- 가상환경 활성화
conda activate pyspark6) PySpark 설치
- 콘다로 PySpark 설치 (오래 걸림)
conda install -c conda-forge pyspark7) 플랫폼 설치
-
버전 관리 진짜 힘들다!
-
플랫폼 다운로드 디렉토리 생성 및 플랫폼 다운로드
cd ~/downloads
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz- spark 다운로드
wget https://dlcdn.apache.org/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgz
- zookeeper 다운로드
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz
- kafka 다운로드
wget https://downloads.apache.org/kafka/3.6.2/kafka_2.12-3.6.2.tgz
- hive 다운로드
wget https://downloads.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
- zeppelin 다운로드
wget https://dlcdn.apache.org/zeppelin/zeppelin-0.10.1/zeppelin-0.10.1-bin-all.tgz
- flume 다운로드
wget https://dlcdn.apache.org/flume/1.11.0/apache-flume-1.11.0-bin.tar.gz- 압축 해제
sudo tar -xzvf hadoop-3.3.6.tar.gz -C /usr/local
sudo tar -xzvf spark-3.5.1-bin-hadoop3.tgz -C /usr/local
sudo tar -xzvf apache-zookeeper-3.8.4-bin.tar.gz -C /usr/local
sudo tar -xzvf kafka_2.12-3.6.2.tgz -C /usr/local
sudo tar -xzvf apache-hive-3.1.3-bin.tar.gz -C /usr/local/
sudo tar -zxvf zeppelin-0.10.1-bin-all.tgz -C /usr/local/
sudo tar -xzvf apache-flume-1.11.0-bin.tar.gz -C /usr/local- 심볼릭 링크 생성
cd /usr/local
sudo ln -s hadoop-3.3.6 hadoop
sudo ln -s spark-3.5.1-bin-hadoop3 spark
sudo ln -s apache-zookeeper-3.8.4-bin zookeeper
sudo ln -s kafka_2.12-3.6.2 kafka
sudo ln -s apache-hive-3.1.3-bin hive
sudo ln -s zeppelin-0.10.1-bin-all zeppelin
sudo ln -s apache-flume-1.11.0-bin flume
- 소유권 변경
sudo chown -R $USER:$USER /usr/local/8) 환경변수 설정
- 환경 변수 설정을 한다.
sudo vim /etc/environment- 전체 내용을 아래로 변경
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/usr/lib/jvm/java-8-openjdk-amd64/bin:/usr/local/hadoop/bin:/usr/local/hadoop/sbin:/usr/local/spark/bin:/usr/local/spark/sbin:/usr/bin/python3:/usr/local/zookeeper/bin:/usr/local/kafka/bin:/usr/local/hive/bin:/usr/local/zeppelin/bin:/usr/local/flume/bin"
JAVA_HOME="/usr/lib/jvm/java-8-openjdk-amd64"
HADOOP_HOME="/usr/local/hadoop"
SPARK_HOME="/usr/local/spark"
ZOOKEEPER_HOME="/usr/local/zookeeper"
KAFKA_HOME="/usr/local/kafka"
HIVE_HOME="/usr/local/hive"
ZEPPELIN_HOME="/usr/local/zeppelin"- .bashrc 에 환경변수 등록 및 적용
source /etc/environment
sudo echo 'export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64' >> ~/.bashrc
sudo echo 'export HADOOP_HOME=/usr/local/hadoop' >> ~/.bashrc
sudo echo 'export HADOOP_COMMON_HOME=$HADOOP_HOME' >> ~/.bashrc
sudo echo 'export HADOOP_HDFS_HOME=$HADOOP_HOME' >> ~/.bashrc
sudo echo 'export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop' >> ~/.bashrc
sudo echo 'export HADOOP_YARN_HOME=$HADOOP_HOME' >> ~/.bashrc
sudo echo 'export HADOOP_MAPRED_HOME=$HADOOP_HOME' >> ~/.bashrc
sudo echo 'export SPARK_HOME=/usr/local/spark' >> ~/.bashrc
sudo echo 'export PYTHONPATH=/usr/bin/python3' >> ~/.bashrc
sudo echo 'export PYSPARK_PYTHON=/usr/bin/python3' >> ~/.bashrc
sudo echo 'export ZOOKEEPER_HOME=/usr/local/zookeeper' >> ~/.bashrc
sudo echo 'export KAFKA_HOME=/usr/local/kafka' >> ~/.bashrc
sudo echo 'export KAFKA_HEAP_OPTS="-Xmx512m -Xms512m"' >> ~/.bashrc
sudo echo 'export HIVE_HOME=/usr/local/hive' >> ~/.bashrc
sudo echo 'export ZEPPELIN_HOME=/usr/local/zeppelin' >> ~/.bashrc
source ~/.bashrc9) Hive MySQL Connector
- 하이브에서 사용할 mysql-connector 를 다운로드 받아서 lib 폴더로 넣어줍니다.
curl -o $HIVE_HOME/lib/mysql-connector-java-8.0.22.jar https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.22/mysql-connector-java-8.0.22.jar10) 하둡과의 Guava 파일 버전 충돌 문제 해결
- hive가 hadoop의 설정파일을 참고함.
- hadoop 과 guava 버전 충돌 나는 플랫폼들의 lib 에 hadoop 의 guava 파일을 복사해줍니다.
rm $HIVE_HOME/lib/guava-19.0.jar
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
신윤재입니다