MapReduce란?
- 2004년 구글에서 발표한 Large Cluster에서 Data Processing 을 하기 위한 알고리즘
- Hadoop MapReducesms 구글 알고리즘 논문을 소프트웨어 프레임 워크로 구현한 것
- Key - Value 구조가 알고리즘의 핵심
- 모든 문제를 해결하기에 적합하기 보단, 데이터 분산 처리가 가능한 연산에 적합함.
- 현재 MapReduce로 개발을 하지는 않지만, 스파크 및 다른 기술들로 큰 데이터 처리를 하는 과정에서 내부 동작 방식이 이 방식과 동일하게 이루어짐.
MapReduce 장단점
-
장점
- 알고리즘이 단순하고 사용이 편리
- 특정 데이터 모델이나 스키마, 질의에 의존적이지 않은 유연성
- 데이터 복제에 기반한 내구성과 재수행을 통한 내고장성확보
- 개발자는 비지니스 로직에만 집중
- 높은 확장성
-
단점
- 고정된 단일 데이터 흐름
- 단순한 스케줄링
- 작은 데이터를 저장/처리하기에 적합하지 않음
- 개발도구의 불편함
- 기술 지원의 어려움
MapReduce 알고리즘

- Map Function, Reduce Funcion이 존재함
- Key, Value의 쌍으로 이루어짐
- HDFS에 분산 저장되어 있는 데이터를 병렬로 처리하여 취합하는 역할
- Java를 기본으로 C++, Python 등 다양한 Language를 지원하지만, Java를 사용한다고 보면 됨
- Job에 대한 구동 및 관리는 하둡이 관리해서 개발자는 비지니스 로직 구현에 집중할 수 있음.
MapReduce의 구동방식
1) Local
- 단일 JVM에서 전체 Job을 실행하는 방식
2) Classic
- Hadoop 버전 1.0대까지 유지하던 MapReduce 분산처리 방식으로 Job Tracker (Master) 와 Task Tracker (Slave) 를 사용하는 MapReduce 버전 1
- Job Tracker와 NameNode는 다른 개념 (data 처리 이냐 저장이냐 차이 )
3) YARN (Yet Another Resource Negotiator)
- Hadoop 2.0v 이상에서 사용하는 MapReduce 분산처리 방식으로 MapReduce 이외의 워크로드 수용이 가능한 MapReduce 버전 2
- Job들을 관리
- 하둡의 디폴트 리소스 관리도구
- 하둡에서 YARN을 쓰지 않고 쿠버네틱스에게 관리를 넘길 수 있음.
MapReduce의 Component
- 클라이언트 (client) : 구현된 맵리듀스 Job을 제출하는 실행 주체
- 잡 트래커 (JobTracker) : 맵리듀스 Job이 수행되는 전체 과정을 조정하며, Job에 대한 마스터 (Master)역할 수행 / TaskTracker의 부하를 보고 판단함.
- 태스크트래커(TaskTracker) :
- Task를 수행하며 실질적인 Data Processing 주체
- 수행 후 처리된 데이터들이 꼭 다시 HDFS로 들어갈 필요는 없음.
- 하둡분산파일 시스템 (HDFS) : 각 단계들 간의 Data와 처리 과정에서 발생하는 중간 파일들을 공유하기 위해 사용
InputSplits

- 자바의 클래스 구현체
- InpusSplits는 물리적으로 Block들을 논리적으로 그룹핑 한 개념
- Mapper를 실행하는 것이 TaskTracker
- Mapper의 입력으로 들어오는 데이터를 분할하는 방식을 제공하기 위해 데이터의 위치와 읽어 들이는 길이를 정의함.
MapReduce 분산 처리
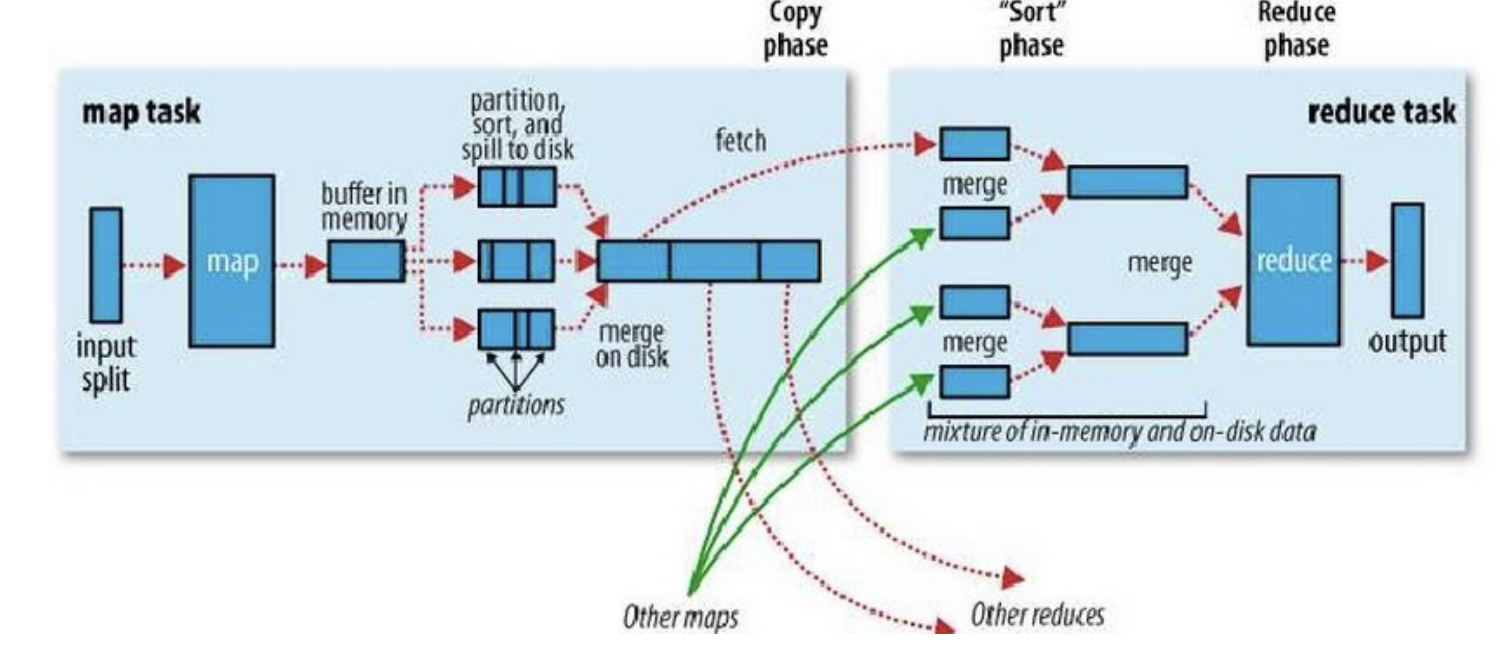

- 기본적으로 MapReduce는 위 사진과 같은 과정을 거쳐서 분산처리를 진행함.
- Map task와 reduce task가 존재함.
- 우리가 구현해야 하는 필수적인 요소는 Mapper이며, optional 한 요소는 Combiner, Parititioner, Reducer가 있음.
- 보통 Map function과 Reducer function을 함께 구현하여서 .jar 파일로 만듦
- 인터페이스로 규격이 정해져 있음.
inputtype
- input format의 종류는 다양함.
- 보통 TextInput Format을 많이 사용함.

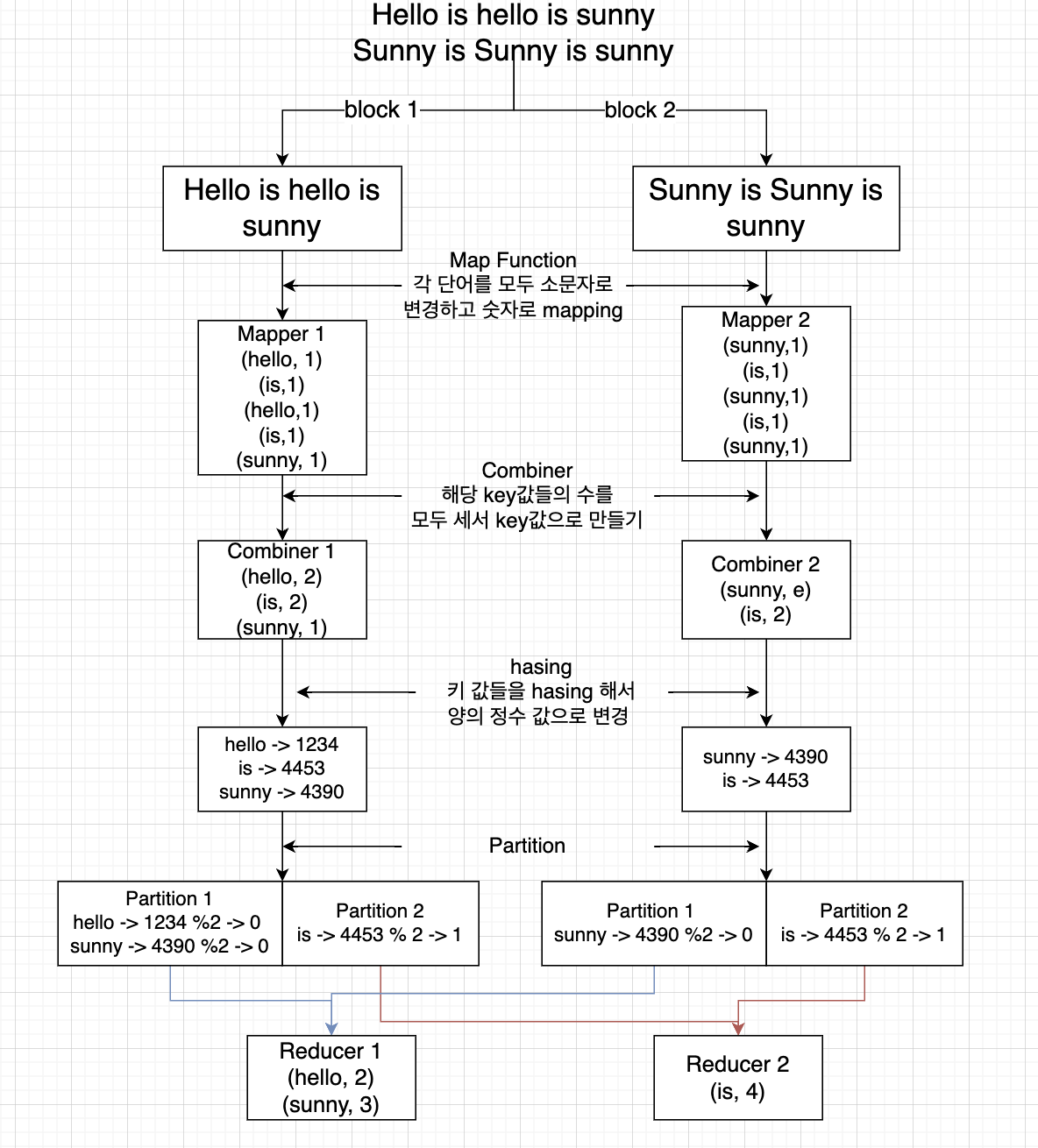
예시 - input (block 단위로 해당 tasktracker의 데이터로 입력됨)

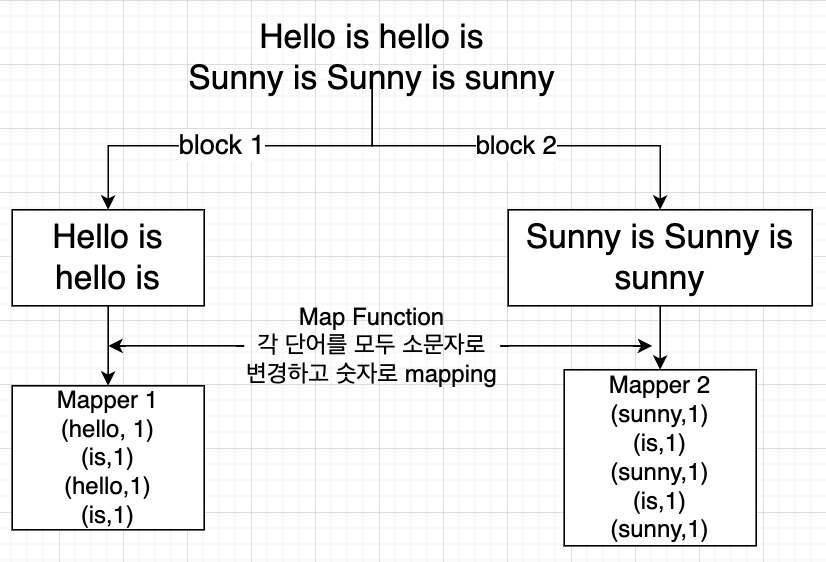
Mapper
- input 이 들어왔을때 어떠한 키값과 어떠한 value값으로 데이터를 Mapping 할건지에 대한 로직이 있는 곳
- 하나의 taskTracker의 child JVM이 담당
- 하나의 블럭의 데이터 값들을 원하는 기준에 따라서 (jar파일에 따라) mapping 하는 것
- mapper 기본적으로 Block수에 맞춰서 생성됨.
예시 -> map function 구현 하여 mapping 함
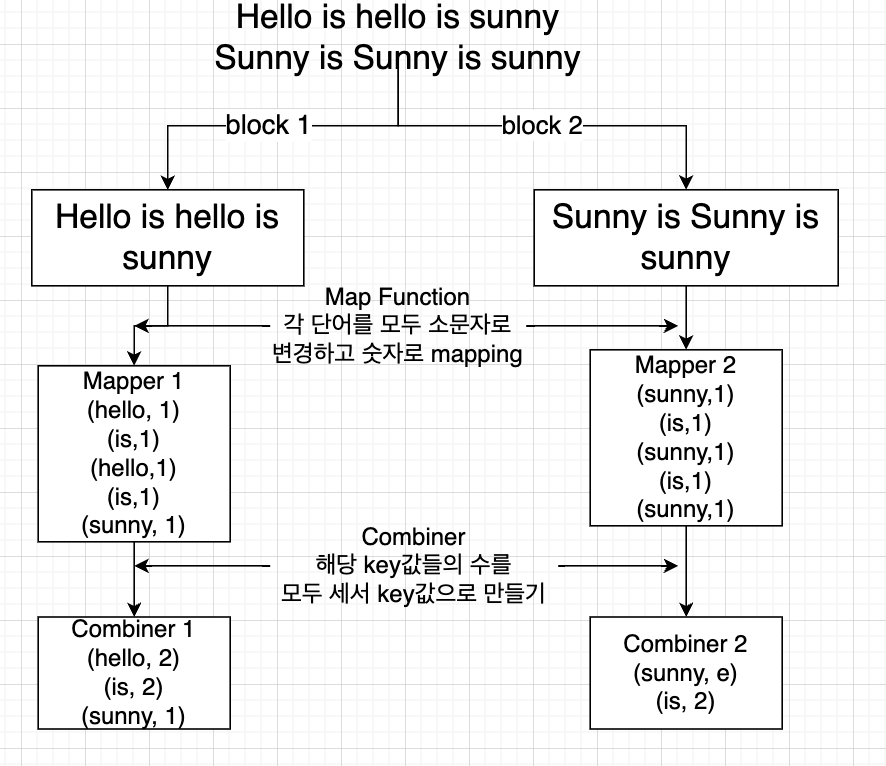
Combiner
- reducer에게 데이터를 주기 전 reducer의 역할을 해주는 중간단계
- ruducer에게 데이터를 줄 때 다른 서버로 너무나 많은 데이터 이동이 있으면 부하가 생김
- 따라서 데이터의 수를 줄여주는 역할 (같은 서버에서 )
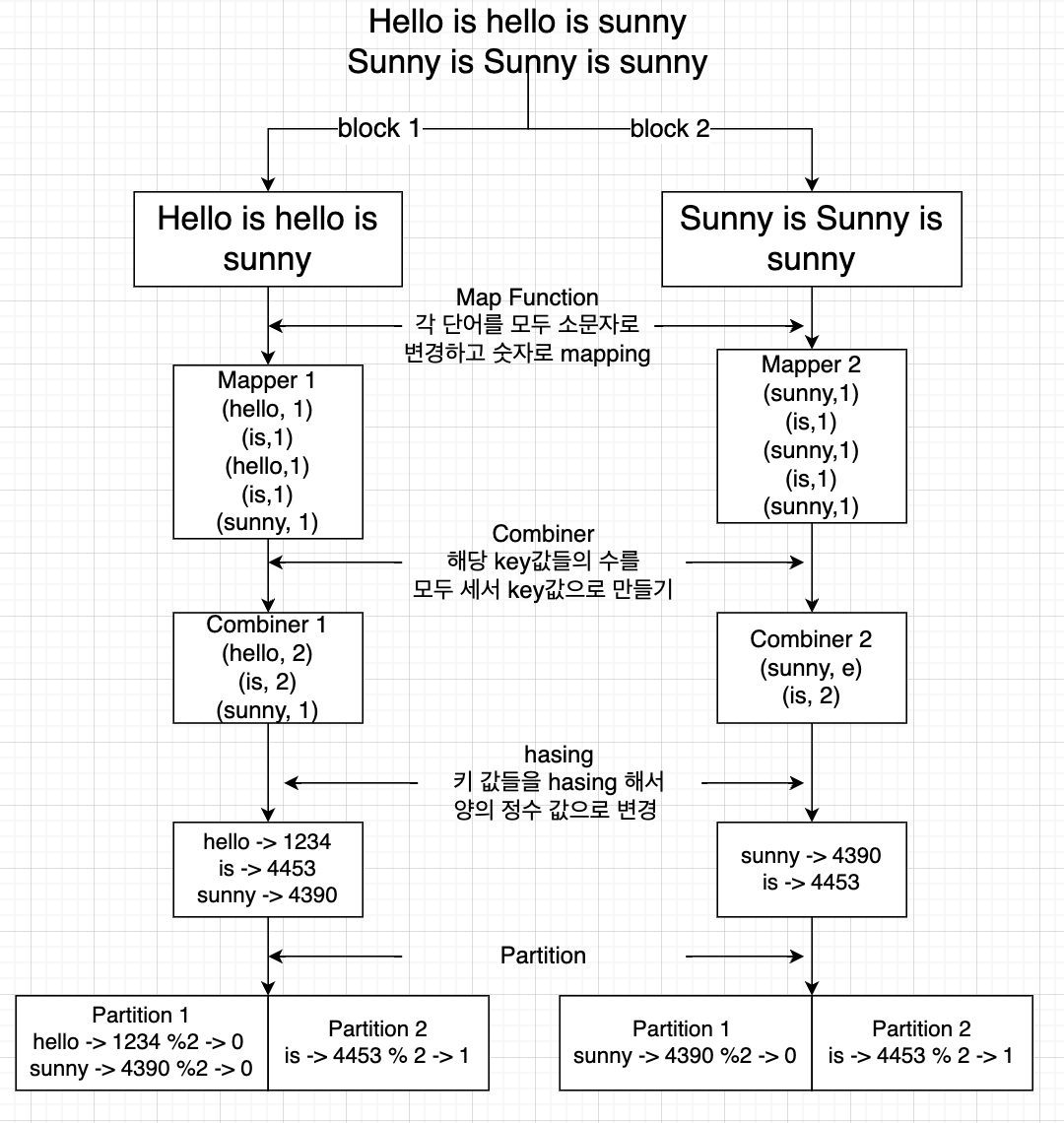
Partitioner
- 서로다른 Mapper 에서 생성된 중간 결과 key- value pair 들을 key 중심으로 같은 키를 자는 데이터는 물리적으로 동일한 Reducer로 데이터를 보내기 위한 용도로 사용
Reducer를 판단하는 방법
- key 값을 hasing 하면 양의 정수 값으로 나오게 됨.
- key 값이 같다면 hasing 한 정수 값도 동일함.
- 이를 우리가 정해준 reducer의 수로 나눠서 나머지를 받음
- 해당 값에 reducer로 보내짐
예시에서는 rudecer를 2개로 지정
Reducer
- 위의 combiner의 function과 동일한 것을 함
- 보통 reducer를 정하고 이에 따라 combiner를 사용하는 편
- reducer와 Mapper는 서버가 다를수도, 아닐 수도 있음.
- 예시에서 reducer는 총 단어의 수를 파악하는 함수
- 정확하게 말하면 해당 키값들에 대한 값들을 모두 리스트 형식으로 만들고 , 이를 어떤 연산을 처리할지 확인
- sunny([1,2]) => sum => (sunny,3)
MapReduce Task 처리 과정
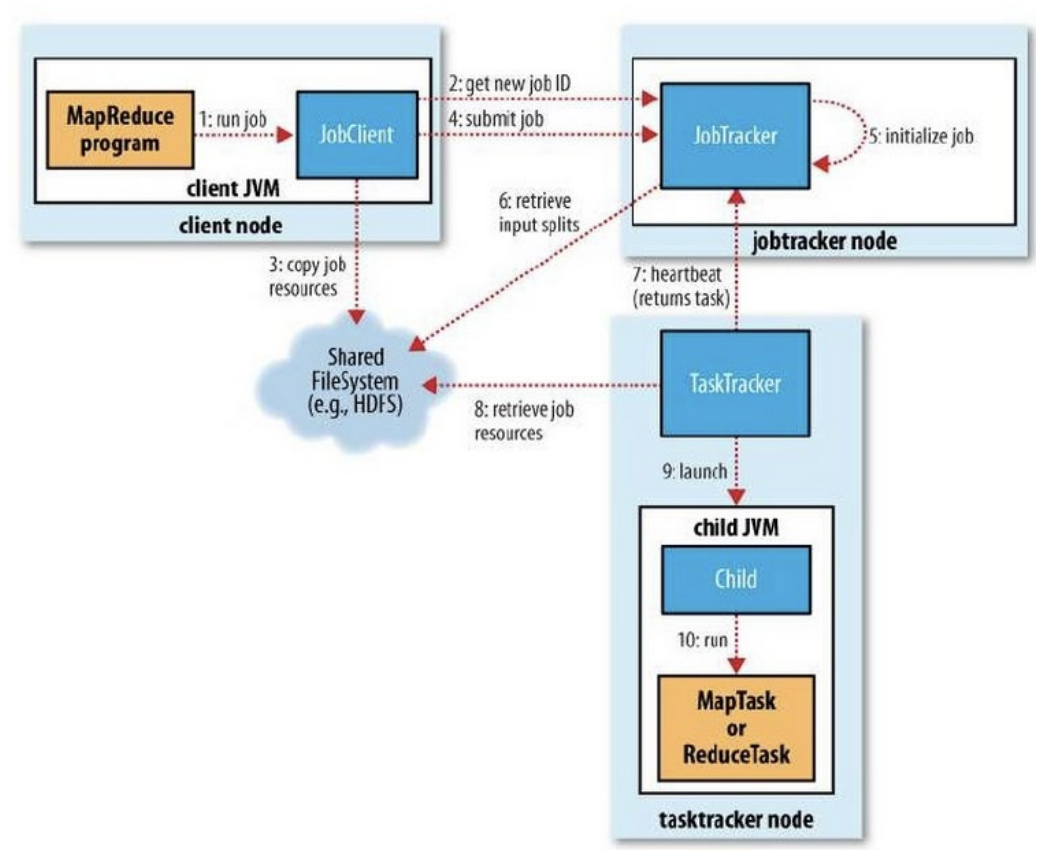
1) Job client가 Map, Partition, Reduce 함수들이 들어가 있는 .jar 파일을 HDFS에 업로드
- .jar 파일 안에는 job을 처리할 data가 무엇인지 적혀있음.
2) Job Tracker가 .jar 파일을 실행해야 한다는 것을 client 로 부터 알게 됨.
3) Job Tracker가 HDFS의 Name Node에게 해당 Data가 어디있는지 물어보게 됨.
- 데이터는 분산되어서 저장되어 있기 때문에 그 정보를 받아옴.
- 동일한 데이터여도 다른 서버에 복제되어 저장되어 있음.
- 각 데이터가 존재하는 서버에 있는 Task Tracker에게 해당 일을 줘야함. => locailty
4) Job Tracker가 호출을 받게 되면 Job을 내부 Queue에 저장
- Task Tracker에게 일을 할당하기 전에 임시로 job을 넣어둠 (pending 상태)
- Task Tracker가 일이 끝나면 그때 하나씩 일을 부여함.
5) Job Tracker가 Task Tracker들의 부하를 판단함.
- Task Tracker는 Heartbeat를 보내는 단순한 루프를 수행하여 Job Tracker가 Live 상태를 체크할 수 있게 함.
- 처리할 데이터를 가지고 있는 서버 중 부하가 적은 Task Tracker 을 선택하여 일을 할당함
6) Task Tracker는 자신이 해야할 일을 1번에서 업로드한 .jar 파일을 가져다가 해당 task를 처리
- task Tracker는 해당 테스크를 처리할 child JVM을 만들어서 처리
- 지역 datenode에서 data도 함께 복제해서 처리
MapReduce의 성능 저하
1) Key들이 하나의 Reducer로 몰리는 경우
2) mapping 된 데이터들을 reducer로 줄 때, 트래픽이 너무 많은 경우 (combiner로 어느정도 해결 )

신윤재입니다