
Intro
성능 개선에 앞서 yoonnsshop의 API를 몇 가지 구현해두었습니다.
이번 포스팅에서는 locust를 통해 시나리오 부하테스트를 진행하고, 부하테스트 결과 개선이 필요해보이는 조회 API를 선택하여 단계 별로 개선해나가는 내용을 다룹니다.
🍋 코드 링크
API 목록
| Method | Endpoint | Description |
|---|---|---|
| GET | /members | 모든 회원 정보 조회 |
| POST | /members/join | 신규 회원 가입 |
| GET | /members/{memberId} | 특정 회원 정보 조회 |
| GET | /items | 모든 상품 정보 조회 |
| GET | /items/{itemId} | 특정 상품 정보 조회 |
| GET | /admins/items | 관리자용 모든 상품 정보 조회 |
| POST | /admins/items | 관리자용 신규 상품 등록 |
| GET | /admins/items/{itemId} | 관리자용 특정 상품 정보 조회 |
| PATCH | /admins/items/{itemId} | 관리자용 특정 상품 정보 수정 |
| DELETE | /admins/items/{itemId} | 관리자용 특정 상품 삭제 |
| POST | /admins/authenticate | 관리자 인증 |
| GET | /orders | 사용자의 주문 정보 조회 |
| POST | /orders | 신규 주문 생성 |
| GET | /carts | 사용자의 장바구니 조회 |
| PUT | /carts/{itemId} | 장바구니 내 특정 상품 수량 변경 |
| POST | /carts/{itemId} | 장바구니에 특정 상품 추가 |
| DELETE | /carts/{itemId} | 장바구니에서 특정 상품 제거 |
| GET | /oauth/code/google | 구글 OAuth 콜백 처리 |
Scenario
본 성능 테스트에서는 yoonnsshop API의 실제 사용 패턴을 시뮬레이션하기 위해 세 가지 주요 사용자 시나리오를 설정했습니다. 이러한 시나리오는 실제 사용자의 행동을 반영하여 더 현실적인 부하 테스트 결과를 얻을 수 있도록 설계되었습니다.
시나리오 테스트에 앞서, 대규모 데이터셋을 준비했습니다:
- Items: 1,000,000건
- Orders: 1,000,000건
- Order Items: 3,000,000건
유저 시나리오
- 기본 구매 시나리오 (80% 비중)
- 상품 리스트 조회
- 특정 상품 상세 조회
- 장바구니에 상품 추가
- 장바구니 확인
- 주문 생성
- 수량 변경 후 구매 시나리오 (15% 비중)
- 상품 리스트 조회
- 특정 상품 상세 조회
- 장바구니에 상품 추가
- 장바구니 확인
- 장바구니 내 상품 수량 변경
- 주문 생성
- 장바구니 삭제 시나리오 (5% 비중)
- 상품 리스트 조회
- 특정 상품 상세 조회
- 장바구니에 상품 추가
- 장바구니 확인
- 장바구니에서 상품 제거
Validation
테스트 시나리오에 따라 부하 테스트를 진행합니다. 이번 부하 테스트를 통해 어떤 API를 처리하는 데 시간이 많이 소요되는지 측정해보기로 했습니다. python 기반의 부하 테스트 도구인 locust를 이용해서 빠르게 테스트를 진행할 수 있었습니다.
테스트 데이터 준비
items를 100만 건, orders 100만 건, order_items를 300만 건 생성해주었습니다.
⌈code⌋ sql/testdata.sql
# title: generate item mock data
DELIMITER $$
CREATE PROCEDURE generateItemData(IN numRows INT)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= numRows DO
INSERT INTO items (item_name, item_description, item_price, item_stock_quantity, create_at, updated_at)
VALUES (
CONCAT('Item ', i),
CONCAT('Description for Item ', i),
RAND() * 1000, -- 0부터 1000 사이의 임의 가격
FLOOR(RAND() * 1000), -- 0부터 999 사이의 임의 재고량
NOW(),
NOW()
);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL generateItemData(1000000);위와 같이 mock 데이터를 생성하는 프로시져를 만들어 사용하면 쉽게 mock 데이터를 만들 수 있습니다.
시나리오 구현
사용자의 주요 동작에 따라 시나리오를 작성해주어야 합니다. 예측해볼만한 세가지 사용자 행동 시나리오를 작성하고, 각 비율을 16:3:1로 설정 해주었습니다. @task 데코레이터를 붙이면 요청 비율을 설정할 수 있습니다.
⌈code⌋ scenario1.py
from locust import HttpUser, task, between
class WebsiteUser(HttpUser):
wait_time = between(0.1, 5) # 각 태스크 사이의 대기 시간 설정 (초 단위)
def on_start(self):
# 로그인 등의 초기 설정 작업 수행
pass
@task(80)
def scenario_1(self):
self.client.get("/items") # 상품 리스트 조회
self.client.get("/items/1") # 상품 상세 조회
self.client.post("/carts/1", params={"quantity": 1}) # 장바구니 추가
self.client.get("/carts") # 장바구니 확인
self.client.post("/orders", json={"orderItems": [{"itemId": 1, "quantity": 10}]}) # 주문
@task(15)
def scenario_2(self):
self.client.get("/items") # 상품 리스트 조회
self.client.get("/items/1") # 상품 상세 조회
self.client.post("/carts/1", params={"quantity": 1}) # 장바구니 추가
self.client.get("/carts") # 장바구니 확인
self.client.put("/carts/1", params={"quantity": 2}) # 장바구니 추가
self.client.post("/orders", json={"orderItems": [{"itemId": 1, "quantity": 10}]}) # 주문
@task(5)
def scenario_3(self):
# 5%의 사용자 시나리오
self.client.get("/items") # 상품 리스트 조회
self.client.get("/items/1") # 상품 상세 조회
self.client.post("/carts/1", params={"quantity": 1}) # 장바구니 추가
self.client.get("/carts") # 장바구니 확인
self.client.delete("/carts/1") # 장바구니 삭제테스트 결과
시나리오 테스트 결과
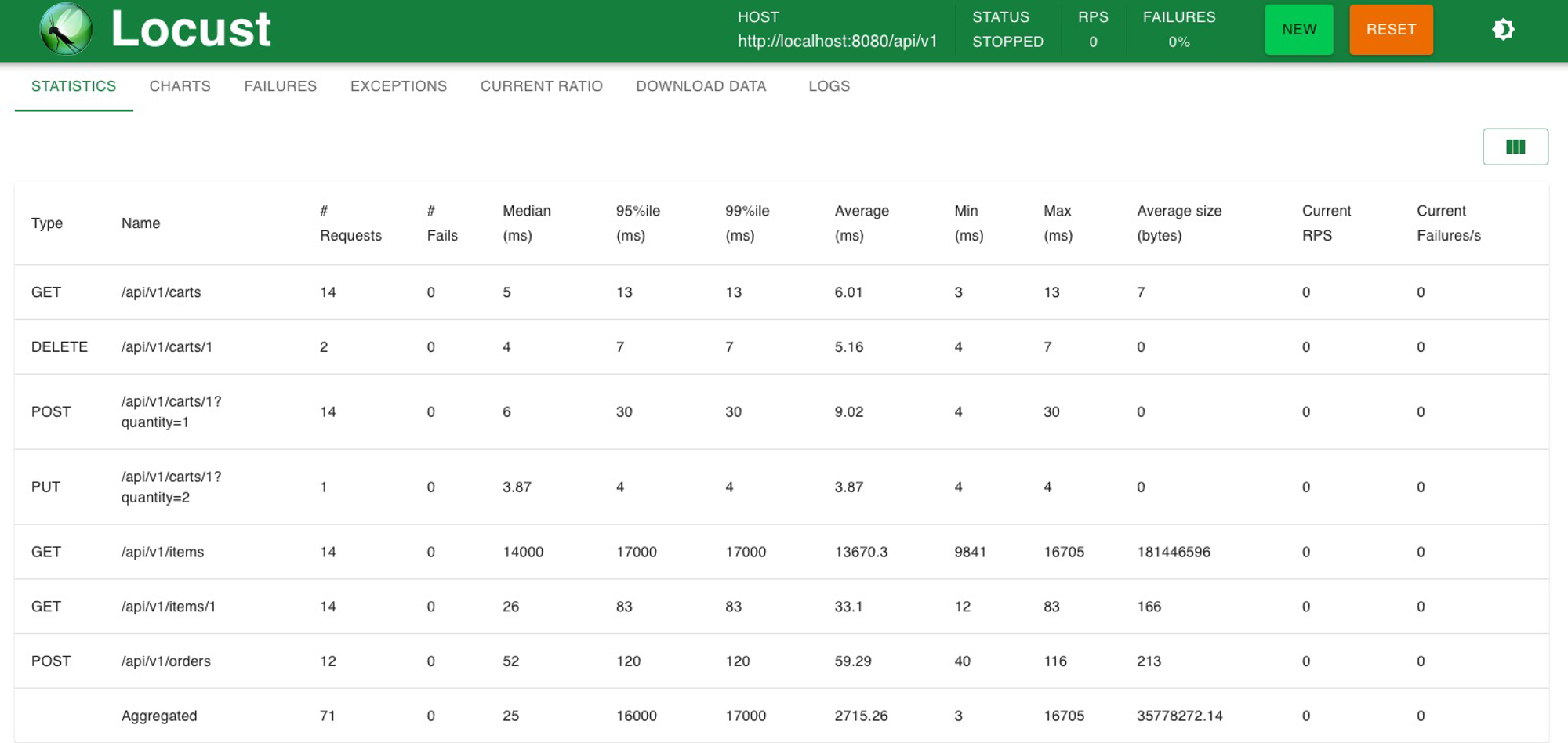
초기 테스트 결과, 상품 리스트 조회 API에서 심각한 성능 문제가 발견되었습니다.
- 총 처리된 요청 : 71건
- 상품 리스트 조회 API 평균 응답 시간 : 약 13.6s
이에 따라 상품 리스트 조회 API에 대한 성능 개선 작업이 필요합니다.
단일 API 벤치마크 테스트
개선 대상 API가 선정된 후, 전체 시나리오 테스트 대신에 보다 효율적이고 집중적인 성능 측정을 위해 해당 API에 대한 단일 벤치마크 테스트를 진행했습니다. 이를 위해 Apache Bench(ab)를 사용하였습니다.
> ab -c 1 -n 10 http://localhost:8080/api/v1/itemsThis is ApacheBench, Version 2.3 <$Revision: 1903618 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software:
Server Hostname: localhost
Server Port: 8080
Document Path: /api/v1/items
Document Length: 181446302 bytes
Concurrency Level: 1
Time taken for tests: 125.389 seconds
Complete requests: 10
Failed requests: 0
Total transferred: 1814465770 bytes
HTML transferred: 1814463020 bytes
Requests per second: 0.08 [#/sec] (mean)
Time per request: 12538.864 [ms] (mean)
Time per request: 12538.864 [ms] (mean, across all concurrent requests)
Transfer rate: 14131.58 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 0
Processing: 12050 12539 440.2 12590 13484
Waiting: 10313 10769 445.9 10799 11719
Total: 12050 12539 440.2 12590 13484
Percentage of the requests served within a certain time (ms)
50% 12590
66% 12659
75% 12688
80% 12919
90% 13484
95% 13484
98% 13484
99% 13484
100% 13484 (longest request)10번의 요청 결과로 평균적으로 13s 정도가 소요되었습니다.
개선
개선1: 페이지네이션 도입
현재 가장 큰 문제는 해당 API를 호출할 때마다 100만 건의 item들을 모두 조회하고 결과로 반환하고 있다는 점입니다. 일반적으로 한 번의 조회로 그렇게 많은 데이터를 보고 싶은 경우는 많지 않습니다. 등록된 item의 개수가 10개도 채 안 된다면 문제가 없었겠지만, 현재는 많은 item이 테이블에 등록되어 있습니다.
이를 해결하기 위해 item을 나눠서 보내기로 결정했습니다. 단순하게 offset과 limit을 query parameter로 받는 것을 코드에 적용했고, 한 번에 조회하는 양을 10으로 줄였습니다. items를 조회할 때 limit 기준에 따라 데이터를 나눠서 가져오게 될 것이며, 추가적으로 전체 item 개수 데이터와 total page 정보를 반환하도록 했습니다.
이러한 변경 후 다시 벤치마킹을 진행한 결과는 다음과 같습니다.
~ ab -c 1 -n 10 http://localhost:8080/api/v1/items/v2
This is ApacheBench, Version 2.3 <$Revision: 1903618 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software:
Server Hostname: localhost
Server Port: 8080
Document Path: /api/v1/items/v2
Document Length: 1999 bytes
Concurrency Level: 1
Time taken for tests: 2.093 seconds
Complete requests: 10
Failed requests: 0
Total transferred: 22740 bytes
HTML transferred: 19990 bytes
Requests per second: 4.78 [#/sec] (mean)
Time per request: 209.288 [ms] (mean)
Time per request: 209.288 [ms] (mean, across all concurrent requests)
Transfer rate: 10.61 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.0 0 0
Processing: 30 209 323.7 34 918
Waiting: 30 208 323.7 33 917
Total: 31 209 323.7 34 918
Percentage of the requests served within a certain time (ms)
50% 34
66% 37
75% 264
80% 679
90% 918
95% 918
98% 918
99% 918
100% 918 (longest request)Total transferred가 1,814,465,770 bytes에서 22,740 bytes로 줄었고, 요청-응답 시간은 95% 평균 13s에서 900ms로 줄어든 것을 확인했습니다. 그동안 얼마나 무거운 요청을 처리해왔는지 단숨에 많이 가벼워졌습니다.
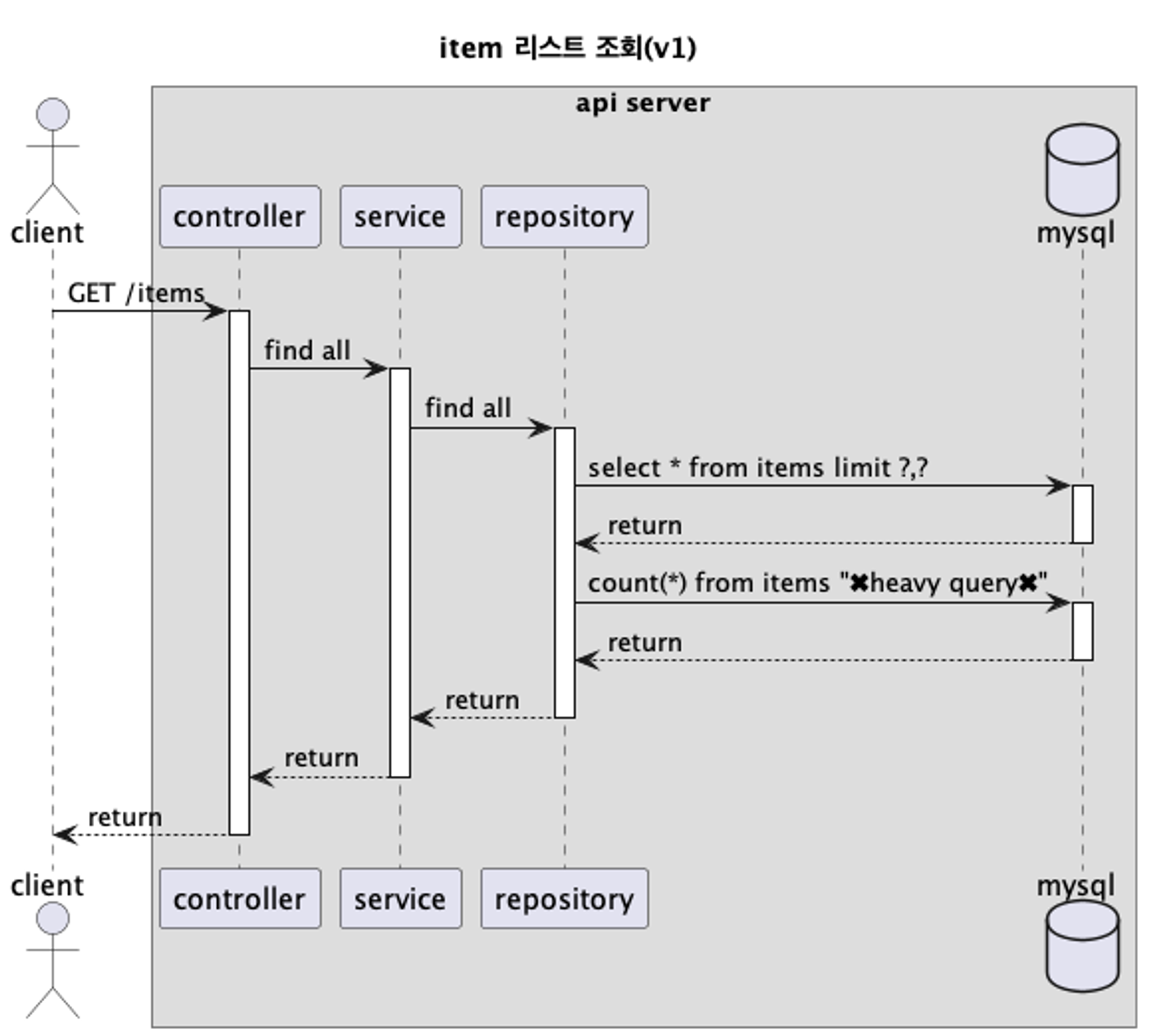
위 sequence diagram에서 총 2번의 데이터베이스를 조회한다고 했습니다. 그렇다면, 각 쿼리를 조회하는 데 소요되는 시간은 얼마였을까요?
Hibernate:
select
i1_0.item_id,
i1_0.create_at,
i1_0.item_description,
i1_0.item_name,
i1_0.item_price,
i1_0.item_stock_quantity,
i1_0.updated_at
from
items i1_0
limit
?, ?
2024-06-18T10:04:32.570+09:00 DEBUG 99622 --- [shop] [nio-8080-exec-1] o.h.stat.internal.StatisticsImpl : HHH000117: HQL: [CRITERIA] select i1_0.item_id,i1_0.create_at,i1_0.item_description,i1_0.item_name,i1_0.item_price,i1_0.item_stock_quantity,i1_0.updated_at from items i1_0 limit ?,?, time: 27ms, rows: 10
# 27msHibernate:
select
count(i1_0.item_id)
from
items i1_0
2024-06-18T10:05:17.851+09:00 DEBUG 99622 --- [shop] [nio-8080-exec-2] o.h.stat.internal.StatisticsImpl : HHH000117: HQL: [CRITERIA] select count(i1_0.item_id) from items i1_0, time: 4425ms, rows: 1
# 4425ms여기서 추가적인 문제를 발견했습니다. 전체 item 개수를 조회하는 쿼리가 4,425ms나 소요되는 것을 확인했습니다. EXPLAIN으로 들여다보니 전체 row를 스캔하는 것을 확인할 수 있었습니다. 이를 개선할 필요성이 대두되었습니다.

개선2: 캐싱 도입
count 조회는 매번 할 필요가 있는지 고민해보았습니다. item count는 어느 기간 정도는 메모리에서 가지고 있으면서 관리해도 충분하다고 판단했습니다. 만일 정확한 count 값을 전달하지 못하더라도 사용자가 다음 액션을 하는 데 심각한 문제를 가져다줄 것 같지는 않았습니다.
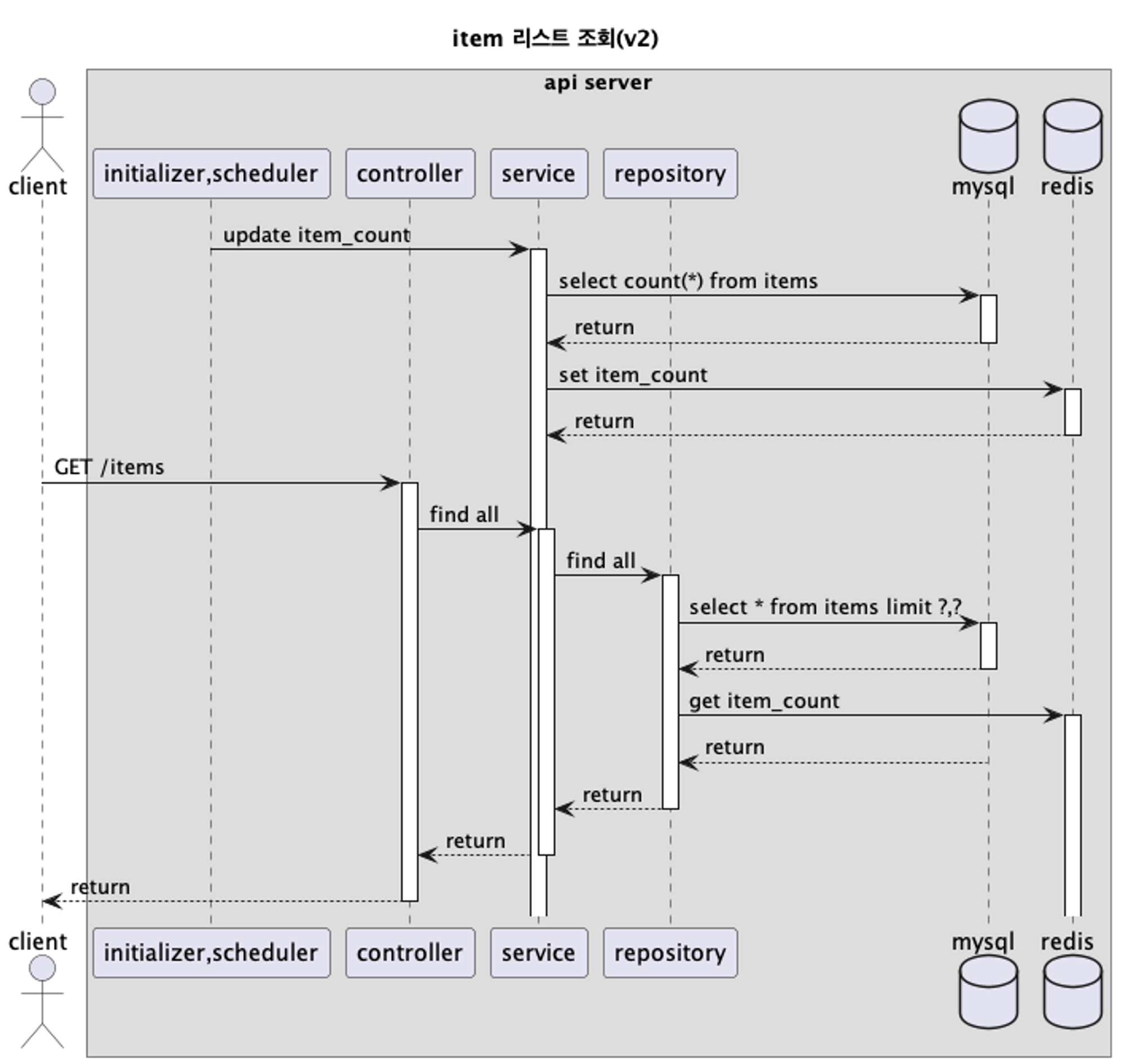
이에 따라 initializer를 추가했습니다. initializer는 우선 최초로 서비스가 올라올 때 database로부터 item count 데이터를 조회하고, redis에 저장합니다. 그리고 주기적으로(코드에는 1시간으로 설정) item count 데이터를 갱신하도록 했습니다.
이제는 item 리스트 조회 API를 호출할 때마다 items 테이블 전체를 스캔할 필요가 없어졌습니다. 사용자가 요청한 양만큼의 item을 조회하고 redis에 저장된 item count를 꺼내서 조합하고 반환하면 됩니다.
✘ ~ ab -c 1 -n 10 http://localhost:8080/api/v1/items/v3
This is ApacheBench, Version 2.3 <$Revision: 1903618 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software:
Server Hostname: localhost
Server Port: 8080
Document Path: /api/v1/items/v3
Document Length: 1999 bytes
Concurrency Level: 1
Time taken for tests: 0.203 seconds
Complete requests: 10
Failed requests: 0
Total transferred: 22740 bytes
HTML transferred: 19990 bytes
Requests per second: 49.38 [#/sec] (mean)
Time per request: 20.253 [ms] (mean)
Time per request: 20.253 [ms] (mean, across all concurrent requests)
Transfer rate: 109.65 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.1 0 0
Processing: 7 20 38.0 7 128
Waiting: 7 20 37.5 7 126
Total: 7 20 38.0 8 128
Percentage of the requests served within a certain time (ms)
50% 8
66% 8
75% 10
80% 12
90% 128
95% 128
98% 128
99% 128
100% 128 (longest request)이러한 개선 후 다시 벤치마킹을 진행한 결과, 95% 기준 900ms 걸리던 것이 128ms까지 줄어든 것을 확인할 수 있었습니다.
이처럼 성능 테스트를 진행할 때는 하나를 개선해보고 다시 테스트해보고, 또 다른 것을 개선해보고 다시 테스트해보는 과정을 반복해야 합니다. 이를 통해 점진적으로 성능을 개선해 나갈 수 있습니다.
다시 시나리오 테스트
개선 작업이 끝났으면 어느 정도로 개선이 되었는지 확인하기 위해 시나리오 부하테스트를 다시 진행해주어야 합니다.
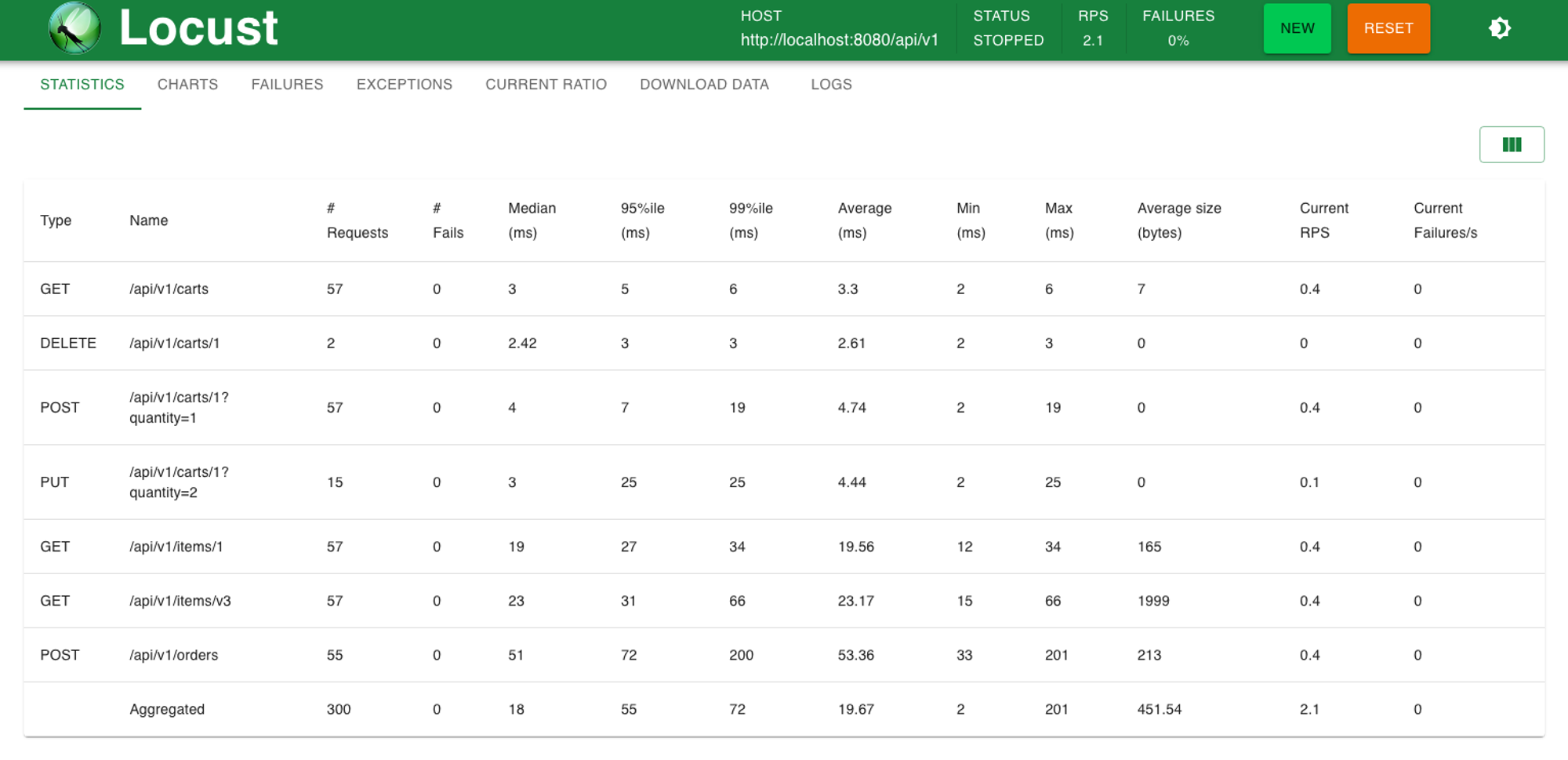
/api/v1/items/v3(개선 과정별로 api endpoint에 버저닝을 했습니다.)을 확인해보면 평균 처리 속도는
23ms입니다.
결과적으로 처음 locust 테스트와 비교했을 때, 해당 API의 속도는 13,67s에서 23ms로 줄어든 것을 확인할 수 있었습니다.
Conclusion
이번 포스트에서 진행한 yoonnsshop API의 성능 개선 과정을 요약하면 다음과 같습니다:
1. 사용자 시나리오 기반 Locust 부하 테스트를 실시하여 성능 병목 지점을 파악했습니다.
2. 테스트 결과, 상품 리스트 조회 API가 가장 큰 성능 문제를 보여 주요 개선 대상으로 선정했습니다.
3. 다음 두 가지 방법으로 API를 개선했습니다:
- 1) Pagination 도입: 한 번에 반환하는 데이터량을 축소하여 응답 시간을 단축했습니다.
- 2) Redis 캐싱: 전체 아이템 개수 조회를 최적화하여 반복적인 무거운 연산을 회피했습니다.
4. 각 개선 단계마다 Apache Bench(ab)를 사용해 단일 엔드포인트에 대한 성능 향상을 측정했습니다.
이러한 과정을 통해 아래와 같은 성능 향상을 달성했습니다.
- 상품 리스트 조회 API 응답 시간: 13.67s → 23ms (약 594배 성능 향상)
이번 성능 개선 과정을 통해 얻은 주요 교훈은 다음과 같습니다:
1. 실제 사용 시나리오 기반 테스트의 중요성
2. 데이터 조회량 최적화의 필요성
3. 캐싱 전략을 통한 반복적인 무거운 연산 회피의 효과
4. 단계별 성능 측정을 통한 정확한 개선 효과 파악
향후 계획으로는 다른 API들의 성능도 검토하고 개선해 나갈 예정입니다.
(실제 서비스라면 지속적인 성능 모니터링과 최적화 및 사용자 수 증가에 대비한 스케일링 전략도 필요합니다..)
Reference
- locust : https://locust.io/
- 전문가가 알려주는 웹 퍼포먼스 튜닝 - 후지와라 슌이치로 (도서)
- index merge : https://dev.mysql.com/doc/refman/8.4/en/index-merge-optimization.html
