Apache NiFi
문제 상황 시나리오
서비스 환경에 다수의 노드로 구성된 웹 앱이 실행 중이며 대용량의 데이터 A가 생성되고 있다.
분석 환경은 데이터 분석을 위한 세팅이 되어 있다.
서비스 환경에 있는 A 데이터를 분석 환경에서 연산을 해야한다.
어떻게 해야 효율적일까?
후보1
서비스 환경과 분석 환경 사이의 데이터 이동을 자유롭게 한다.
데이터를 분석 환경으로 옮긴 후 작업을 수행한다.
대용량의 데이터를 옮겨야 하므로 네트워크 부하가 크다.
분석 환경에서 서비스 환경으로 접근할 수 있게 되니 보안상 좋지 않다.
수동으로 하게 되니 사용자의 실수가 발생할 수 있다.
후보2
작업 스크립트를 작성하여 데이터를 이동시킨다.
cron 등으로 서비스 환경에서 분석 환경으로 데이터 이동을 수행하는 스크립트를 실행시킨다.
복잡한 환경일 수록 스크립트 개발에 시간이 더 많이 든다.
작업을 실행하는 호스트에 문제가 생기면 동작하지 않는다.
배치 작업이기 때문에 실시간성을 가질 수 없다.
후보3
웹 앱 자체에서 데이터를 분석 환경에 저장하도록 한다.
개발 시간이 오래 걸린다. 시스템 환경 변화가 있거나 데이터가 변하는 경우 추가 개발을 해야한다.
대량의 입출력이 생기는 경우 대응하지 못할 수 있다.
해결
세 후보 모두 적절하지 않은 해결 방법이다.
아래와 같은 특징을 갖는 해결 방법이 필요하다.
- 시스템 다운에도 정상 동작을 할 수 있어야 한다.
- 평소보다 데이터가 몰려도 대응할 수 있어야 한다.
- 다양한 형태의 데이터를 처리할 수 있어야한다.
- 시스템 및 환경의 변경에 유연하게 동작해야한다.
- 보안 및 데이터 거버넌스에 안전해야한다.
Apache NiFi를 사용하면 해결이 된다.
Aapche NiFi
시스템 간 데이터 흐름을 Web UI로 설계 및 관리하여 자동화할 수 있는 플랫폼이다.
미국 국가안보국(NSA)가 개발하고 오픈소스로 공개했다.
코드 없이 GUI로 Directed Graph를 디자인하고 이것에 따라 데이터 흐름이 일어난다.
구성 요소
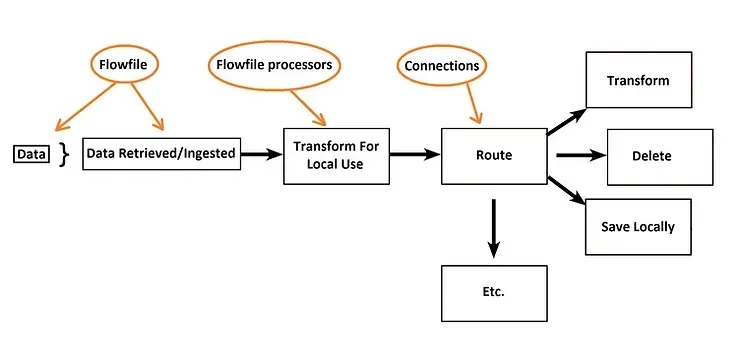
- FlowFile
- 시스템 내에서 움직이는 오브젝트이다.
- content와 attribute가 있다.
- content: 실제 데이터
- attribute: 오브젝트 생성 날짜 등 FlowFile에 대한 메타 정보
- Processor
- FlowFile에 대한 작업을 수행한다.
- 데이터 라우팅, 데이터 변형, 시스템 간 이동 등을 할 수 있다.
- 주어진 FlowFile에 대한 content와 attribute에 접근 권한을 갖는다.
- Connection
- Processor 사이 연결을 제공한다.
- 큐처럼 다음 Processor에서 처리되어야 할 FlowFile이 쌓인다.
작업 흐름
Processor, Connector가 Directed Graph를 구성한다.
만들어진 Graph를 따라서 FlowFile이 이동하고 생성된다.
Connection에 너무 많은 FlowFile이 쌓이는 경우 back pressure를 통해 들어오는 속도를 조절할 수 있다.
Back pressure가 일어나게 되면 이전의 Processor 들에게 작업 속도를 조절하라고 전달함으로써 Connection에 쌓인 FlowFile을 처리할 시간을 벌 수 있다.
아키텍처
- Web Server: API를 처리하고 UI를 제공한다.
- Flow Controller: 전체적인 작업을 스케줄링한다.
- FlowFile Repository: FlowFile의 상태를 추적할 수 있도록 상태를 저장한다.
- Content Repository: FlowFile의 content가 저장된다.
NiFi 클러스터를 구성해서 실행시킬 수도 있다.
클러스터의 각 노드는 같은 일을 한다.
한 노드에서 flow 변경이 일어나면 전체 클러스터에 해당 변경 사항이 전달된다.
ZooKeeper가 Cluster Coordinator와 Primary Node를 선출한다.
Cluster Coordinator
클러스터의 모든 노드는 Cluster Coordinator에게 Heartbeat와 상태 정보를 전송한다.
가장 최신의 flow를 갖고 있어서 새로운 노드가 추가되면 flow 정보를 전달해준다.
Primary Node
Primary Node에서 Isolated Processor 실행이 가능하다.
Web UI의 Cluster Management 페이지에서 어떤 노드가 Primary Node인지 알 수 있다.
Isolated Processor
모든 노드가 동일한 DataFlow를 갖고 있기 때문에 같은 동작을 하게 된다.
특정 프로세서의 동작은 모든 노드가 하지 않길 바랄 수 있다.
예를 들어 GetSFTP와 같은 프로세서는 원격에서 데이터를 받아오는데 이 동작을 모든 노드에서 한다면 원격 서버에 부담이 갈 수 있다. 이럴 때 Primary Node에서만 GetSFTP 프로세서를 추가함으로써 부담을 줄일 수 있다.
장점 및 단점
장점
- Web based UI
- 웹 UI를 통해 코드 없이 Dataflow 디자인, 모니터링 등을 할 수 있다.
- Highly configurable
- Low latency vs high throughput를 설정으로 조절할 수 있다.
- Back pressure 기능을 설정으로 사용할 수 있다.
- Data Provenance
- Dataflow의 처음부터 끝까지 트래킹을 한다.
- Designed for extension
- 기본 제공하는 Processor 외에 사용자가 직접 만들 수 있다.
- Secure
- SSL 설정으로 보안 통신이 가능하다.
- 각 컴포넌트에 대해 사용자 별로 접근 제어가 가능하기 때문에 멀티 테넌트 지원이 된다.
단점
- 패키지 크기
- 1.10.0 tarball 경우 크기가 1.2GB이다.
- 스케일의 한계
- 스케일 아웃으로는 한계가 있다.
- 부하가 높은 데이터 처리는 Flink나 Storm에서 처리를 해주는 것이 좋다.
- GUI
- Dataflow를 수정했을 때 이전 그래프와의 차이점을 알기 힘들다.
- 변경 사항에 대한 리뷰를 받기가 어렵다.
활용
- 마이크로 서비스 간의 데이터 흐름 설계
- 각 마이크로서비스 컴포넌트의 데이터를 NiFi로 얻음으로써 시스템의 통합적인 Dataflow를 설계할 수 있다.
- 각 스토리지에 보관되고 있는 데이터를 받아서 가공한 뒤에 다시 서비스로 활용할 수 있도록 내보낼 수 있다.
- 플랫폼 사이를 넘는 데이터 흐름 설계
- 다양한 플랫폼이 있는 경우 플랫폼 사이의 데이터 이동을 간편하게 해준다.
- 처음 시나리오가 해당하는 활용 방법이다.
Kafka 데이터를 RDB에 저장하기 — Stateful
- Flow File Repository: FlowFile의 위치나 상태 등을 저장한다.
- Content Repository: FlowFile의 content를 저장한다.
각 노드의 로컬 디스크에 저장한다.
NiFi가 재시작되어도 모든 데이터가 로컬 디스크에 저장되어 있기 때문에 마지막 state부터 시작할 수 있다.
Kafka offset을 commit하기 전에 session을 commit함으로써 at least once를 보장한다.
Kafka 데이터를 RDB에 저장하기 — Stateless
콜백들이 하나의 Processor이 끝날 때마다 수행되지 않고 전체 flow가 성공적으로 끝났을 때 수행된다.
전체 flow 수행이 하나의 transaction처럼 여겨진다.
전체 flow 중 하나라도 실패하면 전체가 실패된 걸로 간주되고 onSuccess 콜백은 수행되지 않는다.
로컬 저장소를 사용하지 않고 인메모리를 사용하기 때문에 NiFi가 중간에 종료된다면 데이터는 소실되고 다시 수행해야한다.
References
https://nifi.apache.org/docs.html https://github.com/apache/nifi
https://techblog.yahoo.co.jp/entry/2021121230233787/ https://techblog.yahoo.co.jp/entry/20191224797450/
https://nifi.apache.org/minifi/index.html
https://bryanbende.com/development/2021/11/10/apache-nifi-stateless
https://www.youtube.com/watch?v=5cuij8J0GG0&t=58s
https://www.slideshare.net/Hadoop_Summit/eventdriven-messaging-and-actions-using-apache-flink-and-apache-nifi
