처음으로 다뤄보는 빅데이터. 행이 무려 십만 줄이 넘는다. 열도 많아서 프로그램에 전부 나타나지도 않는다. 근데 참 신기하게도 첫 전처리 미션이 내가 늘 보던 호텔 데이터다. 오늘 하루에 다 처리하진 못했지만, 그래도 즐거운 마음으로 데이터를 들여다볼 수 있었다. 이런 방식으로 호텔 DB를 만들 수도 있겠구나 하는 생각이 들었다. 이번 데이터를 처리하면서 강의 듣는 것보다 더 값진 깨달음을 얻었다. 역시 인생은 실전이라더니 그 말이 딱 맞다.
전처리를 해보니 자주 사용하는 명령어가 분명 있다. 근데 아직 기억이 잘 나지 않아서 검색하느라 시간이 오래 걸린다. 아무래도 전처리 명령어를 모아서 따로 포스팅을 하든지 해야겠다.
학습시간 09:00~23:00(당일14H/누적116H)
1. 오늘 깨달은 것
- 코드 한 줄만 추가하면 모든 열이 다 보인다.
pd.set_option('display.max_columns', None)- 내가 보고 싶은 열만 꺼내볼 수 있다.
df[['A', 'B', 'C', 'D']]- str.zfill(2)로 1단위 수를 10단위로 출력할 수 있다.
df['date'] = (
df['year'].astype(str) + '-' +
df['month'].astype(str).str.zfill(2) + '-' +
df['day'].astype(str).str.zfill(2)
)- describe를 역배열로 볼 수 있다.
df.describe(include='all').T- where 함수로 이상치 처리 조건을 걸 수 있다.
# A열이 10이하면 그대로 두고, 그게 아니면 A열을 mode한다.
df['A'] = df['A'].where(df['A'] < 10, df['A'].mode())2. 호텔 데이터 전처리
(1) 전처리 목표
호텔 관리인으로서 예약 취소와 관련이 있는 요소들을 파악해보고, 예약 취소율을 줄이기 위한 아이디어도 생각해 보시오.
- 어떤 조건에서 예약 취소가 빈번하게 발생하는지?
- 예약 취소와 관련이 있는 요소들이 무엇인지?
- 어떻게 하면 예약 취소율을 개선할 수 있는지?
(2) 라이브러리 & 데이터 준비
시작은 언제나 같다. 라이브러리와 데이터를 불러온다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 열이 많아서 중략되길래 전부 표시하는 코드를 넣었다.
pd.set_option('display.max_columns', None)
df = pd.read_csv('folder/file.csv')(3) 결측값 처리
# 결측치 존재열과 결측 수
df.isnull().sum()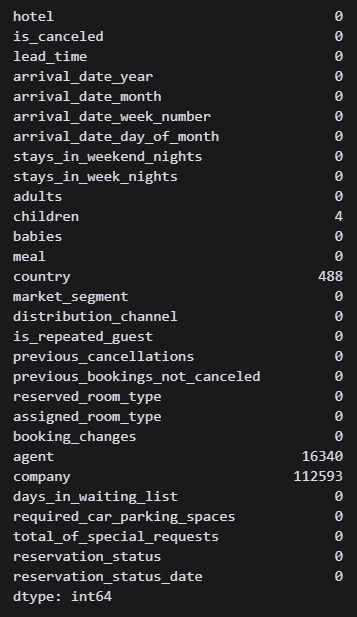 결측값을 가진 열이 4개 존재한다. 이제 각 열마다 어떻게 생겨먹었는지 확인해야 한다.
결측값을 가진 열이 4개 존재한다. 이제 각 열마다 어떻게 생겨먹었는지 확인해야 한다.
# children열의 무슨 값이 있는지 확인
df['children'].value_counts()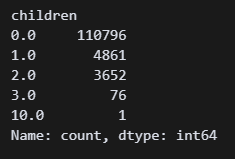 1.0 처럼 소수 형태인 것 같다. 타입도 확인해 보자.
1.0 처럼 소수 형태인 것 같다. 타입도 확인해 보자.
# children열의 dtype 확인
df['children'].info()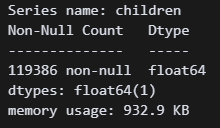 타입을 보니 역시 float다.
타입을 보니 역시 float다.
df['children'].median()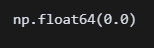 median 값은 0.0이다. mean 값은 0.1정도 되던데 자식을 0.1명 가질 수는 없으니까 결측치는 0.0 으로 해야겠다.
median 값은 0.0이다. mean 값은 0.1정도 되던데 자식을 0.1명 가질 수는 없으니까 결측치는 0.0 으로 해야겠다.
# children열 결측값에 0.0 입력
df['children'] = df['children'].fillna(0.0)
df.isnull().sum() children열 결측치 처리 완료!
children열 결측치 처리 완료!
이번엔 country 열이다. 위와 같은 순서로 확인해준다.
# country열의 dtype 확인
df['country'].info()
# country열의 모든 값 도표로 확인
df['country'].value_counts() 타입은 object, 즉 문자열이다. 종류가 엄청 많네.. 뭐가 있는지 들여다 봐야겠다.
타입은 object, 즉 문자열이다. 종류가 엄청 많네.. 뭐가 있는지 들여다 봐야겠다.
# country열의 고유값 확인
df['country'].unique()
들여다 보니 나라를 대문자 3개로 표기하는 것 같다.
음,, 488개면 날려도 되긴하는데 일단 OTH(others)로 바꿔놔야겠다. 호텔 다녀보니 아예 쓸모없는 데이터는 없었다.
# country열 빈값에 OTH 입력
df['country'] = df['country'].fillna('OTH')
df.isnull().sum()
 country열도 결측치 처리 완료! 다음은 agent열이다.
country열도 결측치 처리 완료! 다음은 agent열이다.
# agent열의 dtype 확인
df['agent'].info()
# agent열값 확인
df['agent'].value_counts() 타입은 float고 숫자가 막 적혀있다. 여행사 코드인 것 같다. 결측치 15,000개면 데이터의 약 10%인데,,, 일단 0.0 넣어서 살려줘야겠다.
타입은 float고 숫자가 막 적혀있다. 여행사 코드인 것 같다. 결측치 15,000개면 데이터의 약 10%인데,,, 일단 0.0 넣어서 살려줘야겠다.
# agent열 빈값에 0.0 입력
df['agent'] = df['agent'].fillna(0.0)
df.isnull().sum() agent열도 결측치 처리 완료!
agent열도 결측치 처리 완료!
# company열의 dtype 확인
df['company'].info()
df['company'].value_counts() company열도 float type이다. 이것도 회사 코드인듯. 회사 코드가 많이 들어가지 않은 것 보니 단발성으로 오는 일반 회사인 것 같다. 호텔에서 일해보니 FIT, 일반사, 제휴사 별로 특징이 많이 다르다.
company열도 float type이다. 이것도 회사 코드인듯. 회사 코드가 많이 들어가지 않은 것 보니 단발성으로 오는 일반 회사인 것 같다. 호텔에서 일해보니 FIT, 일반사, 제휴사 별로 특징이 많이 다르다.
열 삭제하긴 아까운데 일단 0.0을 넣어서 살려줘야겠다.
# 수치를 확인하기 위해 정렬
np.sort(df['company'].unique())바꾸기 전에 0.0을 넣어도 되는지 확인!
# company열 빈값에 0.0 입력
df['company'] = df['company'].fillna(0.0)0.0을 입력해준다.
df.isnull().sum()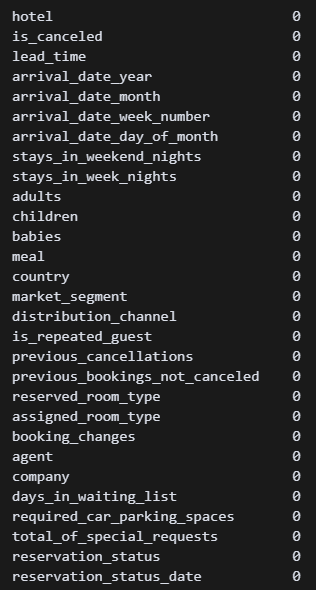 모든 결측치 처리 완료!! (아마도!?)
모든 결측치 처리 완료!! (아마도!?)
(3) 중복값 처리
이제 중복값을 처리할 차례다.
# 중복값 확인
df.duplicated().sum()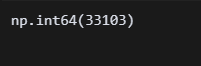 중복값이 33,103개...!!!??? 이걸 어쩐다... 뭘 어떻게 확인해야 할지 아직 감이 안 잡힌다. 호텔 데이터가 그리 엉성할 리 없으니 그냥 쓰자고 생각했는데,,, 강사님에게 물어보니 중복값은 대부분 삭제한다고 한다.
중복값이 33,103개...!!!??? 이걸 어쩐다... 뭘 어떻게 확인해야 할지 아직 감이 안 잡힌다. 호텔 데이터가 그리 엉성할 리 없으니 그냥 쓰자고 생각했는데,,, 강사님에게 물어보니 중복값은 대부분 삭제한다고 한다.
일단 실력이 더 늘기 전까지는 중복값은 전부 삭제!
# 중복값 삭제
df.drop_duplicates(inplace=True)
# 삭제 후 확인
df.duplicated().sum() 삭제 완료!
삭제 완료!
이제 이상치 처리를 하기 전에 필요한 데이터만 남기고 타입을 통일해야 한다. 원래 이걸 제일 먼저 했어야 했는데 ㅠ
df.dtypes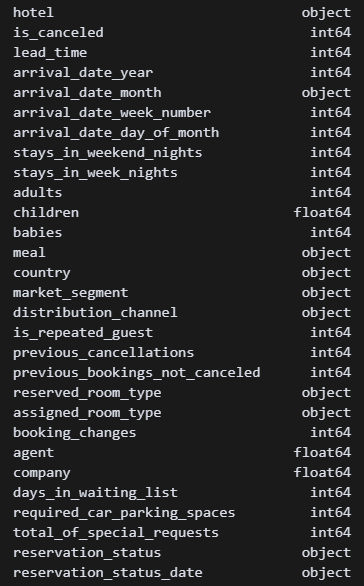 타입이 뒤죽박죽이다. 일단 도착일과 예약일 타입부터 맞춰야겠다.
타입이 뒤죽박죽이다. 일단 도착일과 예약일 타입부터 맞춰야겠다.
df[['arrival_date_year',
'arrival_date_month', 'arrival_date_week_number',
'arrival_date_day_of_month', 'reservation_status_date']]보기 좋게 날짜 관련된 특정 열만 출력!
 arrival_date 컬럼을 만들어서 관련 컬럼을 yyyy-mm-dd 포맷으로 만든다. week number는 딱히 필요 없을 것 같다.
arrival_date 컬럼을 만들어서 관련 컬럼을 yyyy-mm-dd 포맷으로 만든다. week number는 딱히 필요 없을 것 같다.
''' 1. month 포맷 문자에서 숫자로 변환 '''
df['arrival_date_month'] = pd.to_datetime(df['arrival_date_month'], format='%B').dt.month
''' 2. arrival_date열에 yyyy-mm-dd 포맷으로 합체 '''
df['arrival_date'] = (
df['arrival_date_year'].astype(str) + '-' +
df['arrival_date_month'].astype(str).str.zfill(2) + '-' +
df['arrival_date_day_of_month'].astype(str).str.zfill(2)
)
''' 3. 필요없는 열 4개 삭제 '''
df.drop(columns=['arrival_date_year', 'arrival_date_month', 'arrival_date_week_number', 'arrival_date_day_of_month'], inplace=True)
''' 4. 생성된 열 확인 '''
df[['reservation_status_date','arrival_date']] 이제 숫자는 다 int로, 날짜는 다 datetime 포맷으로 변경해준다.
이제 숫자는 다 int로, 날짜는 다 datetime 포맷으로 변경해준다.
''' float -> int 포맷 변환 '''
df['children'] = df['children'].astype(int)
df['agent'] = df['agent'].astype(int)
df['company'] = df['company'].astype(int)
''' object -> datetime 포맷 변환 '''
df['arrival_date'] = pd.to_datetime(df['arrival_date'])
df['reservation_status_date'] = pd.to_datetime(df['reservation_status_date'])
df.dtypes 아주 깔끔하고 좋구만 그래! 이제 이상치를 파악해 보자!
아주 깔끔하고 좋구만 그래! 이제 이상치를 파악해 보자!
(4) 이상치 처리
일단 문자열부터 정제해야겠다.
''' 문자열 확인 '''
df['hotel'].unique()
df['meal'].unique()
df['country'].unique()
df['market_segment'].unique()
df['distribution_channel'].unique()
df['reserved_room_type'].unique()
df['assigned_room_type'].unique()
df['reservation_status'].unique()

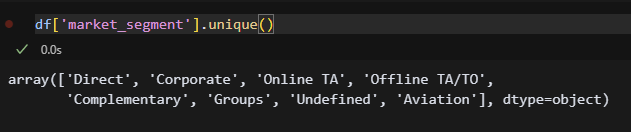


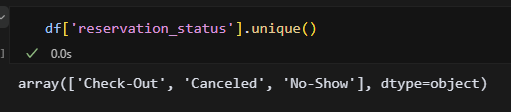
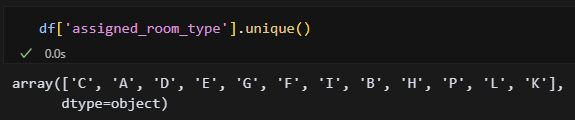 object 8개 다 확인해 봤는데 오타는 없는 것 같다! 지금은 하나씩 확인하긴 했는데 나중에 진짜 열이 많은 데이터를 받으면 하나씩 확인을 못할 것 같다. 한방에 해결할 수 있는 방법을 찾아봐야겠음.
object 8개 다 확인해 봤는데 오타는 없는 것 같다! 지금은 하나씩 확인하긴 했는데 나중에 진짜 열이 많은 데이터를 받으면 하나씩 확인을 못할 것 같다. 한방에 해결할 수 있는 방법을 찾아봐야겠음.
이제 수치를 확인해 볼까!
''' 수치 확인 '''
df.describe(include='all').T열이 많아서 한 눈에 보이도록 역배열을 해줬다. 이제 상관관계를 보기 전 마지막 단계이니 만큼 내가 어떤 열을 가져갈 것인지 잘 정해야 한다.
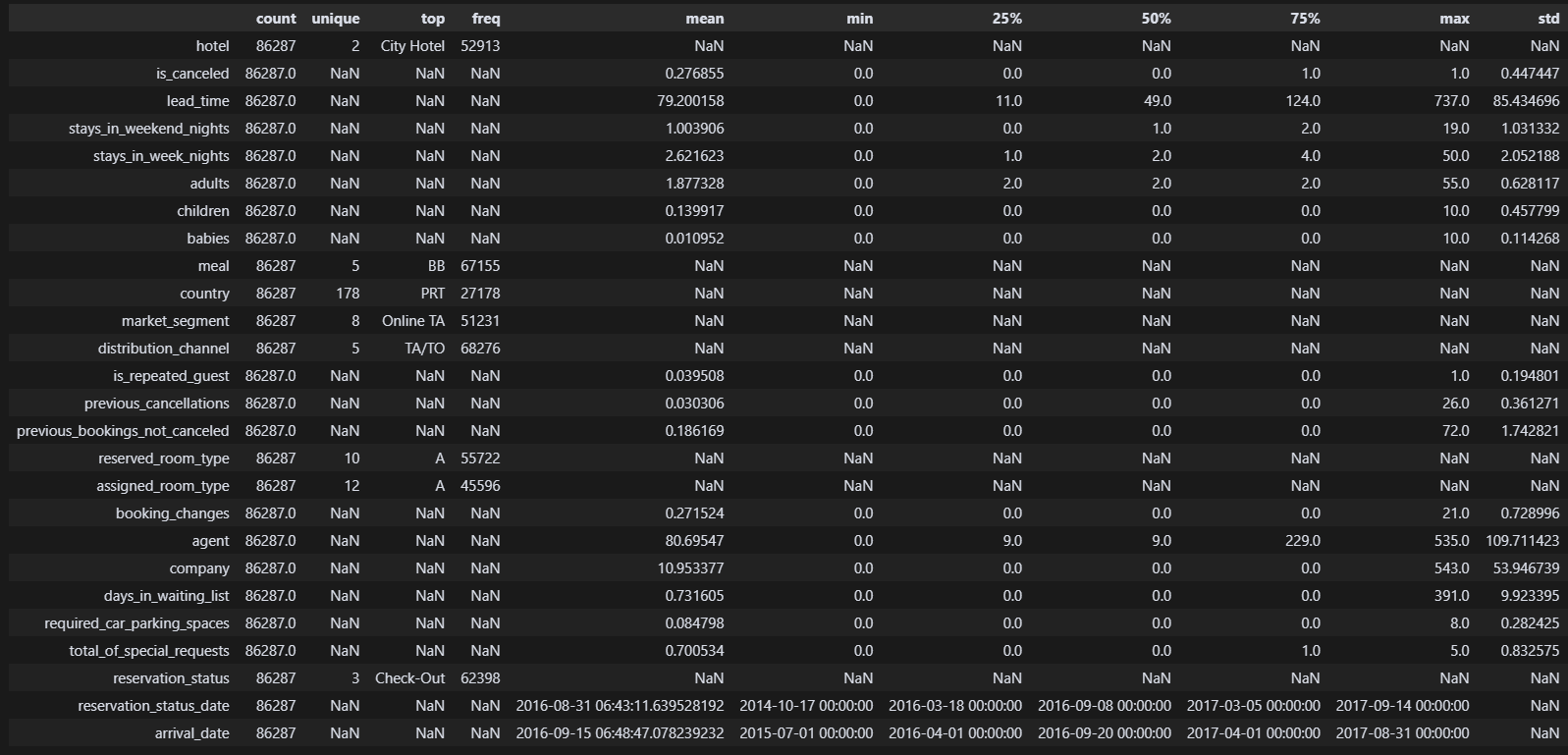 생각해 보자. 예약 취소와 연관이 아예 없는 건 뭘까?
생각해 보자. 예약 취소와 연관이 아예 없는 건 뭘까?
예컨대 agent와 company는 정말 중요한 정보이지만, int형식으로 저장된 이상 유의미한 숫자가 나온다 한들 어느 기업인지 알 수가 없다.
취소와의 상관관계를 보는 것이니 투숙 완료한 기간 또한 큰 의미가 없다. lead_time, stays_in_weekend_nights, stays_in_week_nights도 필요 없을 것이다.
현장에서 조율 가능하거나 곧장 확답을 내릴 수 없는 특이사항 또한 의미가 없다. required_car_parking_spaces, total_of_special_requests도 필요 없을 것이다.
일단 여기까지는 다 삭제하도록 하자!
''' 필요없는 열 삭제 '''
df.drop(columns= ['agent', 'company', 'lead_time', 'stays_in_weekend_nights', 'stays_in_week_nights', 'required_car_parking_spaces', 'total_of_special_requests'], inplace=True)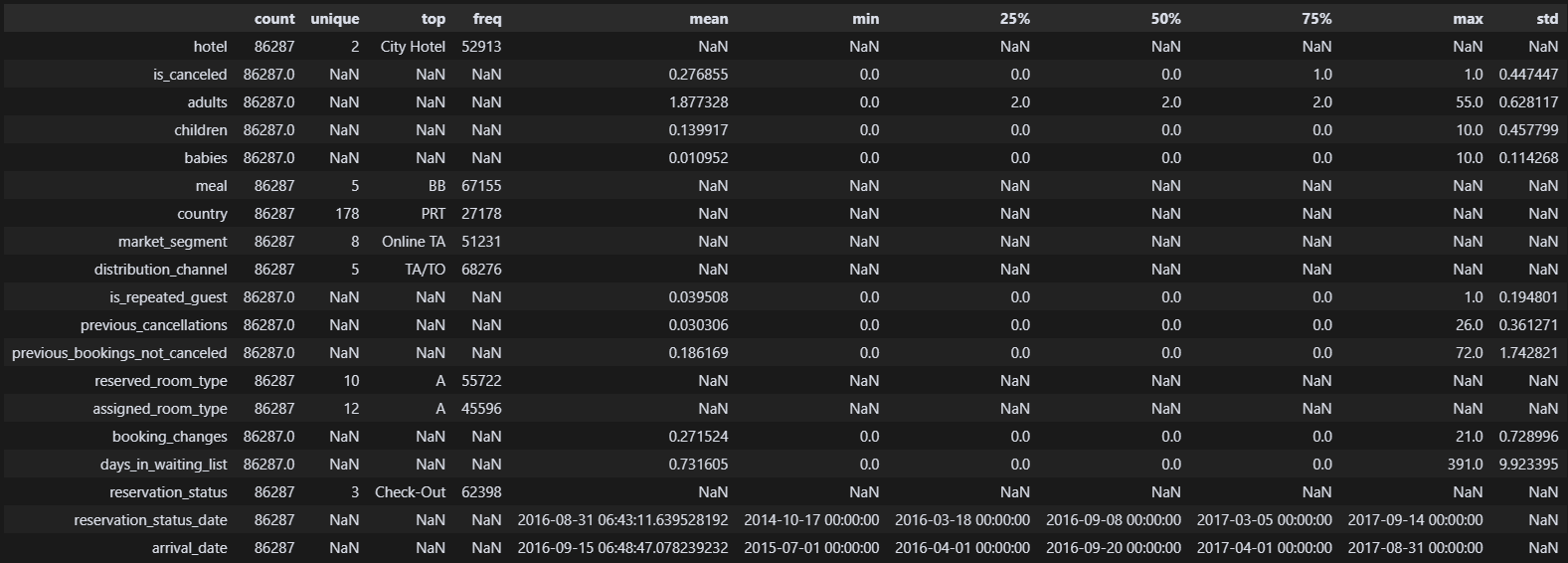 대충 필요한 열만 남긴 것 같다. 이제 수상한 놈들을 살펴보자.
대충 필요한 열만 남긴 것 같다. 이제 수상한 놈들을 살펴보자.
max가 굉장히 수상한 것들
-
adults: 투숙객 55명 ㅋㅋ / 10명 이상이면 mode값으로 적용!
-
children: 어린이 10명 ㅋㅋ / 5명 이상이면 mode값으로 적용!
-
babies: 아기 10명 ㅋㅋ / 5명 이상이면 mode값으로 적용!
-
previous_cancellations: 취소 26회 진짜냐...? 근데 값을 보니 진짜인 것 같음. 이 열은 건너뛰자!
-
booking_change: 변경 21회라 놀랐는데, 은근히 10~20 사이에 분포된 값이 많다. 이 열도 건너뛰자!
-
days_in_waiting_list: 웨이팅 391일? / 100일 이상이면 mode값으로 적용!
''' 이상치 값 분포 확인 '''
df['adults'].value_counts()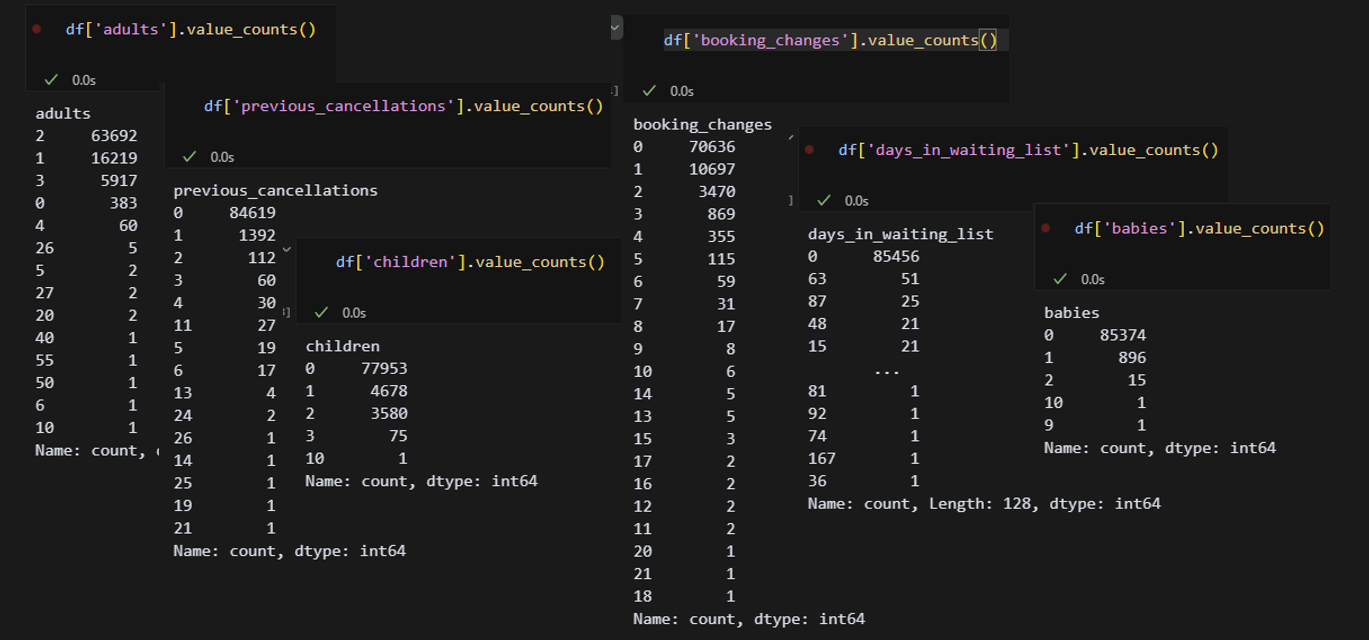 높은 값에 숫자가 몰려 있는 열은 없으니 이상치는 다 mode값으로 하면 될 것 같다. 이제 노가다 시작!
높은 값에 숫자가 몰려 있는 열은 없으니 이상치는 다 mode값으로 하면 될 것 같다. 이제 노가다 시작!
''' 이상치 처리 '''
df['adults'] = df['adults'].where(df['adults'] < 10, df['adults'].mode())
df['children'] = df['children'].where(df['children'] < 5, df['children'].mode())
df['babies'] = df['babies'].where(df['babies'] < 5, df['babies'].mode())
df['previous_cancellations'] = df['previous_cancellations'].where(df['previous_cancellations'] < 15, df['previous_cancellations'].mode())
df['days_in_waiting_list'] = df['days_in_waiting_list'].where(df['days_in_waiting_list'] < 100, df['days_in_waiting_list'].mode())
df['adults'].value_counts()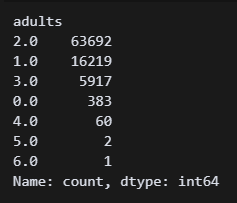 5개 열(사진은 adults)의 이상치가 mode값으로 들어간 것이 확인되었다!
5개 열(사진은 adults)의 이상치가 mode값으로 들어간 것이 확인되었다!
이번엔 수동으로 이상치를 설정했는데, 사실 quantile를 설정해서 정상범위를 벗어난 모든 이상치를 mode값으로 한 번에 처리하고 싶었다. 이것보다 더 효율적인 방법은 없으려나 ㅠㅠ...
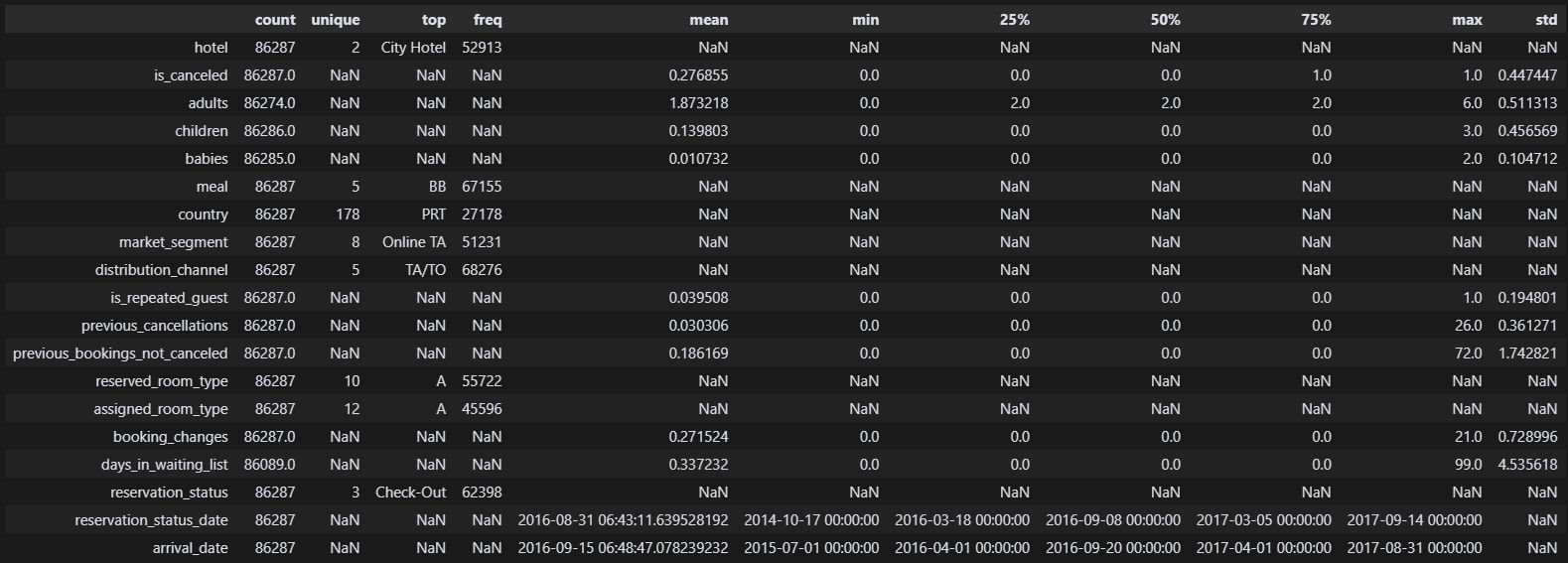 이정도면 이상치는 다 처리한 것 같다.
이정도면 이상치는 다 처리한 것 같다.
(5) 데이터 시각화
드디어 왔다! 내가 좋아하는 seaborn으로 해볼까!
''' seaborn 테마 설정 '''
sns.set_theme(rc={'figure.figsize':(15, 8)}, style='whitegrid', font='Malgun Gothic', font_scale=1, palette='Set2')
맑은고딕 폰트를 추가하고, 내가 좋아하는 깔쌈한 whitegrid 배경을 넣는다!
df.columns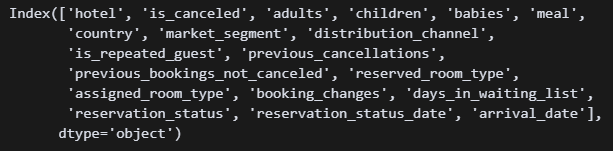 칼럼 이름 기억이 안 나서 불러와줌
칼럼 이름 기억이 안 나서 불러와줌
''' 그래프 보기 '''
sns.barplot(data=df, x='hotel', y='is_canceled')어느 축이든 is_canceled 열이 들어가야 상관관계를 볼 수 있다. 일단 바플롯으로 하나씩 들여다 보자.
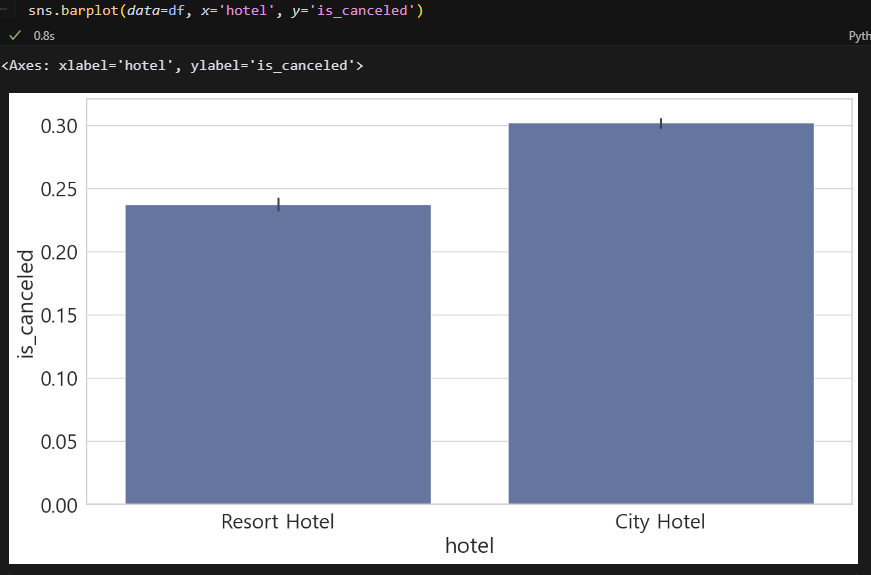 City Hotel의 취소율이 더 높다.
City Hotel의 취소율이 더 높다.
sns.heatmap(df.corr(numeric_only=True), annot=True, fmt=".2f")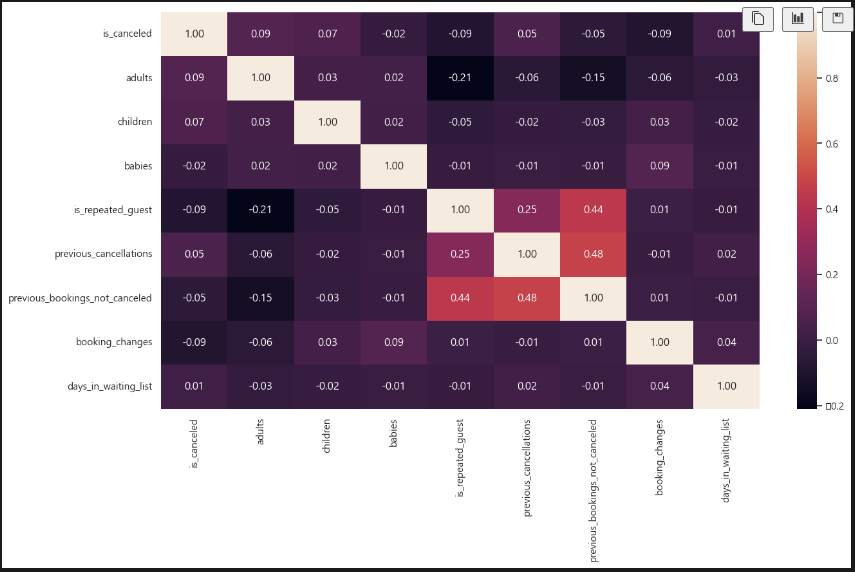 히트맵을 보자. 수치 상으로는 크게 연관있는 게 없어 보인다.
히트맵을 보자. 수치 상으로는 크게 연관있는 게 없어 보인다.
더 하고 싶은데 어느 새 하루가 끝나버렸다ㅠ... 일단 현재까지의 결과를 굳이 도출하자면,
- City Hotel 취소율이 더 높다.
- 투숙객 인원이 많을수록 취소율이 높다.
- 재방문 고객보다 첫방문 고객 취소율이 높다.
- 예약 변경이 잦은 고객일수록 취소율이 낮다.
근데 생각해 보니 호텔이 2개니까 나눠서 봐야하는 거 아닌가...?
일단 오늘은 여기까지! 월요일에 하나씩 뜯어서 봐야겠다!
