대망의 자연어 첫 미션. 그래도 트랜스포머 모델 전까지는 할만하지 않을까...
학습시간 09:00~02:00(당일17H/누적1182H)
◆ 학습내용
- 18,846개의 뉴스 문서를 20개의 카테고리로 분류
- 데이터를 훈련 세트와 테스트 세트로 적절히 분류
- Word2Vec, FastText, GloVe 임베딩 모델 사용
- RNN, LSTM, GRU 시계열 모델 사용
- Accuracy, Precision, Recall, F1-score 등을 활용해 평가
# 제공 데이터
from sklearn.datasets import fetch_20newsgroups
news_data = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))1. 계획
솔직히 NLP를 막 배워서 뭐가 뭔지 잘 모르겠다. 게다가 트랜스포머를 배운 다음에 다시 예전 모델을 보려니 또 헷갈린다.
지난 주에 모델 정리를 해놔서 참 다행이다. 간단하게 복습 한번 더 하고 시작해 보자!
[ 임베딩 모델 ]
- Word2Vec
- 단어 단위로 임베딩한다. CBOW(주변 단어로 예측), Skipgram(주변 단어를 예측) 기법을 사용한다. 학습 데이터에 없는 단어가 나오면 성능이 떨어진다.
- FastText
- 단어를 n-gram(subword) 단위로 임베딩한다. 더 많은 정보를 저장해야 하므로 계산 비용이 높지만 학습 데이터에 없는 단어, 오탈자, 신조어 등 OOV(Out Of Vocab)에 간겅하게 대응할 수 있다.
- GloVe
- 말뭉치 전체의 통계 정보를 초기에 한 번만 계산한다. 덕분에 학습이 빠르고 효율적이다. 하지만 Word2Vec과 마찬가지로 OOV에 취약하다.
[ 시계열 모델 ]
- Vanilla RNN
- 가장 기본 형태의 순환 신경망이다. 시원스 데이터 패턴을 학습하지만, 치명적인 장기 의존성 문제가 있다. 역전파 과정에서 기울기가 소실되거나 폭발하는 문제가 있다.
- LSTM
- 장기 의존성 문제를 해결하기 위해 고안된 구조다. 3개의 게이트(forget, input, ouput)로 기억 정보 및 출력을 조절할 수 있다. 기울기 문제를 많이 해결했지만 계산 비용이 높다. 아직도 주식 관련 모델에 종종 쓰인다.
- GRU
- LSTM의 게이트를 2개(reset, update)로 줄인 모델이다. update가 forget, input 역할을 한다. 계산 효율이 높아진 대신 LSTM만큼 정교한 제어가 어렵다. 현대에선 거의 안 쓰인다.
여러 번 복습하고 나니 확실히 모델의 특징은 대충 이해가 된다. 그런데 문제는 어떻게 저 6개를 동시에 사용하느냐다. 내 계산이 맞다면 총 9번의 학습이 필요할 것 같은데,,, 이거 가능한 건가??
일단 시작해 보자!
2. 라이브러리 로드
import sys
if 'google.colab' in sys.modules:
from google.colab import drive; drive.mount('/content/drive')
import drive.MyDrive.develop.config_my_path as cc
cc.dir('news-topic-classifier')개발환경 셋팅을 먼저 해준다.
프로젝트 때 간소화 하는 방법을 찾았다. config 파일을 따로 만들어서 임포트 하니 매번 코드를 넣을 필요 없어서 아주 간편하다.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from gensim.models import Word2Vec, FastText
from gensim.scripts.glove2word2vec import glove2word2vec
from gensim.models import KeyedVectors
import numpy as np
import re
from collections import Counter필요한 라이브러리를 호출한다.
지난 번 강의 실습할 때 호환성 지옥에 빠져서 한참 고생했는데,, 이번엔 과연 무사히 넘어갈 수 있을지!?
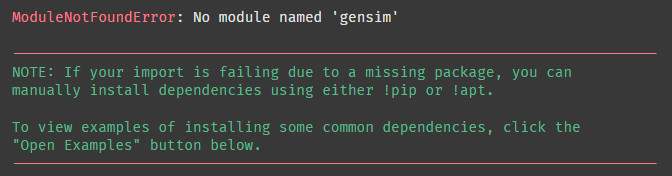
gensim이 없다고 한다.
!pip install gensim설치!
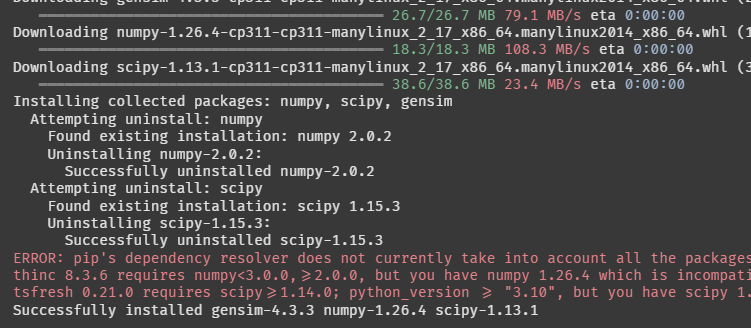
뭐가 쭉 설치되더니 에러가 떴다. 그 후 성공적으로 설치되었다는데,,, 이게 무슨 상황이지??
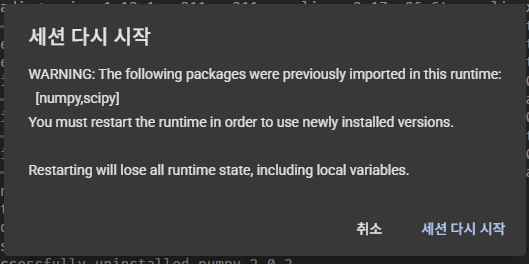
갑자기 런타임이 끊겼다. 또 지옥 시작인가? ㅠㅠㅠㅠ

다시 연결하고 셀을 재실행하니까 이번엔 정상 작동한다.
이상하군,,, 지난 번에는 scipy랑 numpy버전도 막 변경했던 것 같은데,,,
뭔가 찝찝하지만 일단 다음 단계로!
3. EDA
이 데이터가 어떻게 구성되어 있는지 먼저 살펴볼 필요가 있을 것 같다.
news_data = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))
documents = news_data.data
labels = news_data.target
categories = news_data.target_names지침받은 대로 fetch_20newsgroups() 모듈로 데이터를 가져왔다.
print(f"Documents: {len(documents)}")
print(f"Labels: {len(labels)}")
print(f"Categories: {len(categories)}")몇 개인지 부터 살펴보자.
지난 번 프로젝트 때 데이터에 누락이 많아서 주는 데이터를 고분고분 사용하면 안 되겠다는 깨달음을 얻었다.
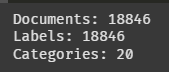
전달받은 내용과 수량이 동일하다. 다행이다.
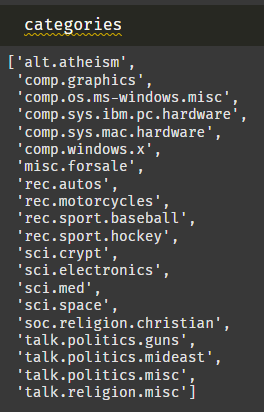
카테고리가 20개 밖에 없어서 직접 살펴봤다. 흠,,, 하위 카테고리가 몇 개씩 붙은 것 같은데 쉽게 유추할 수가 없다.
찾아보니 아래와 같다.
1차 분류
| 분류1 | 의미 |
|---|---|
| alt | 대안적/비주류 |
| comp | 컴퓨터 관련 |
| misc | 기타/잡다한 |
| rec | 레크리에이션/취미 |
| sci | 과학 |
| soc | 사회/문화 |
| talk | 토론/논쟁 |
2차 분류
| 분류2 | 의미 |
|---|---|
| atheism | 무신론 |
| graphics | 그래픽 |
| os | 운영체제 |
| sys | 시스템 |
| windows | 윈도우 |
| forsale | 판매 |
| autos | 자동차 |
| motorcycles | 오토바이 |
| sport | 스포츠 |
| crypt | 암호 |
| electronics | 전자공학 |
| med | 의학 |
| space | 우주 |
| religion | 종교 |
| politics | 정치 |
아하! 이제 알겠군.
documents본문 내용도 살펴 보자!
헉,,, 이거 딱 봐도 전처리가 힘들 것 같은 느낌이 든다.
특수 문자도 많고.. 보기만 해도 어지러운 데이터다.
일단 조금 더 자세히 확인해 보자!
category_counts_raw = Counter(labels)
category_name_counts_raw = {categories[label]: count for label, count in category_counts_raw.items()}
df_counts_raw = pd.DataFrame(list(category_name_counts_raw.items()), columns=['Category', 'Document Count'])
df_counts_raw = df_counts_raw.sort_values(by='Category').reset_index(drop=True)
total_documents = df_counts_raw['Document Count'].sum()
print(f"Total: {total_documents}")
plt.figure(figsize=(12, 6))
plt.bar(df_counts_raw['Category'], df_counts_raw['Document Count'], color=(1, 0.3, 0.3))
plt.xticks(rotation=90)
plt.title('Number of Documents')
plt.tight_layout()
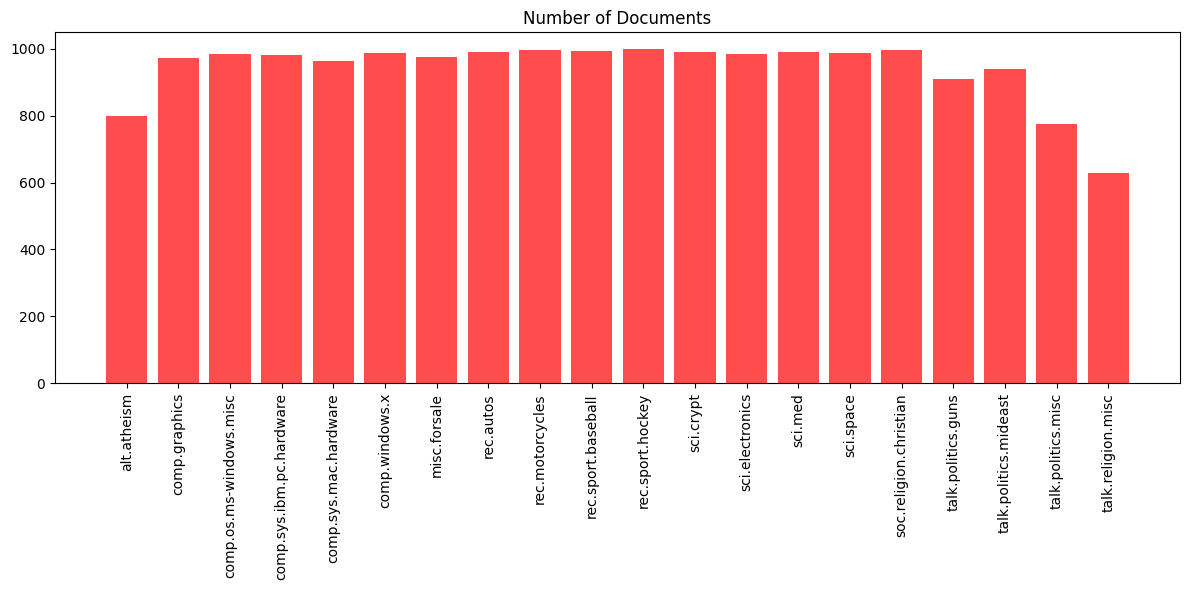
먼저 카테고리별 데이터 수다. 거의 비슷한 것 같은데 몇몇 카테고리는 데이터가 소폭 적다.
category_max_lengths = {name: 0 for name in categories}
for i, doc in enumerate(documents):
doc_length = len(doc.split())
category_name = categories[labels[i]]
if doc_length > category_max_lengths[category_name]:
category_max_lengths[category_name] = doc_length
df_max_lengths = pd.DataFrame(list(category_max_lengths.items()), columns=['Category', 'Max Document Length'])
df_max_lengths = df_max_lengths.sort_values(by='Category').reset_index(drop=True)
plt.figure(figsize=(12, 6))
plt.bar(df_max_lengths['Category'], df_max_lengths['Max Document Length'], color=(0.3, 1, 0.3))
plt.xticks(rotation=90)
plt.title('Document Length(Max)')
plt.tight_layout()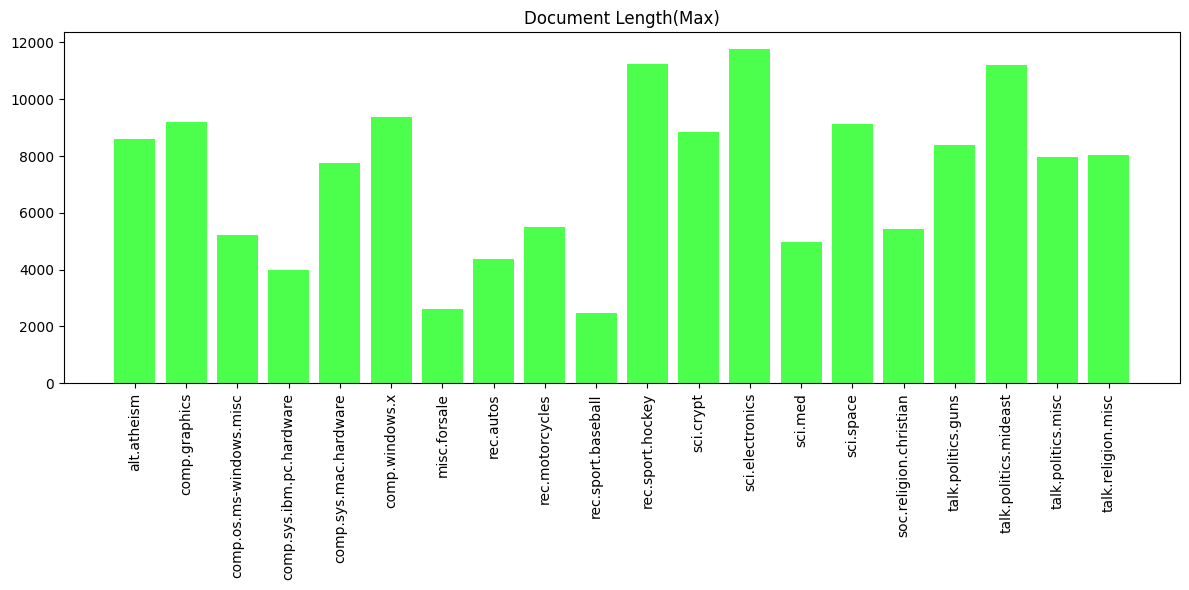
이번엔 카테고리별 텍스트 최대 길이다. 패딩을 어느 정도 염두에 두어야 하는지 고려하기 위함이다. 유독 긴 글도 있고 유독 짧은 글도 있다. 2000자~12000자면 폭이 생각보다 크다.
category_lengths = defaultdict(list)
for i, doc in enumerate(documents):
doc_length = len(doc.split())
category_name = categories[labels[i]]
category_lengths[category_name].append(doc_length)
category_avg_lengths = {name: np.mean(lengths) for name, lengths in category_lengths.items()}
df_avg_lengths = pd.DataFrame(list(category_avg_lengths.items()), columns=['Category', 'Average Document Length'])
df_avg_lengths = df_avg_lengths.sort_values(by='Category').reset_index(drop=True)
plt.figure(figsize=(12, 6))
plt.bar(df_avg_lengths['Category'], df_avg_lengths['Average Document Length'], color=(0.3, 0.3, 1))
plt.xticks(rotation=90)
plt.title('Document Length(Avg)')
plt.tight_layout()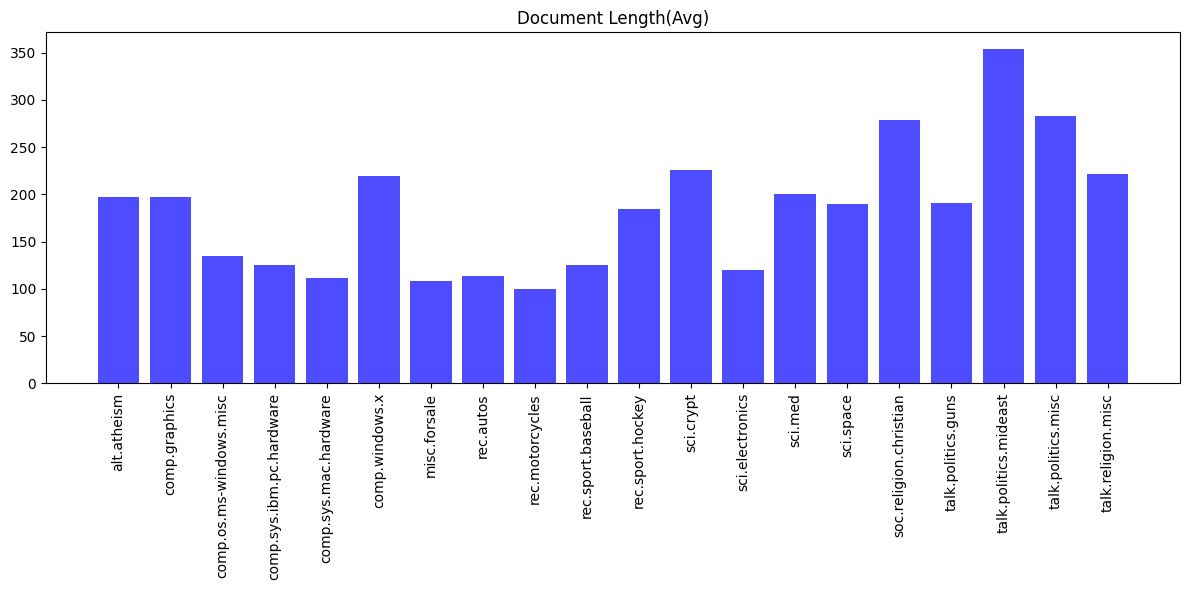
마지막으로 카테고리별 텍스트 평균 길이다. 사실 카테고리 수보다는 이게 더 중요하지 않나 싶다. 어찌됐든 텍스트가 길다는 건 그만큼 많은 데이터가 있다는 뜻이니까. 대체적으로 정치 토론 쪽이 텍스트가 긴 것으로 보인다.
일단 오늘은 여기까지 ㅠㅠ 해커톤 준비랑 같이 하다보니 미션을 오래 들여다 볼 수가 없다... 그래도 난 잘 해낼 것이다!!
