뭔가 시원하게 끝내지 못한 느낌이다. 언젠가 다시 돌아와서 혼쭐을 내주마!
학습시간 18:00~00:00(당일6H/누적1375H)
◆ 학습내용
어제에 이어 8번 부터 시작
8. 모델 개선
어제 학습한 모델의 성능이 썩 마음에 들지 않았다.
에폭을 조금 더 돌리면 괜찮은 성능이 나올까?
def train_model(model, tokenizer, train_dataset, eval_dataset, model_output_path):
training_args = TrainingArguments(
output_dir=model_output_path,
num_train_epochs=10,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
warmup_steps=500,
weight_decay=0.01,
logging_dir=f"{model_output_path}/logs",
logging_steps=1000,
eval_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=1000,
load_best_model_at_end=True,
save_total_limit=2,
report_to="none",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model(model_output_path)배치를 4에서 32로, 에폭을 2에서 10으로 늘렸다.
시간이 얼마나 걸릴까...?
train_model(
model=model,
tokenizer=tokenizer,
train_dataset=tokenized_train_dataset,
eval_dataset=tokenized_valid_dataset,
model_output_path="./kobart_best_model"
)돌려보자!!
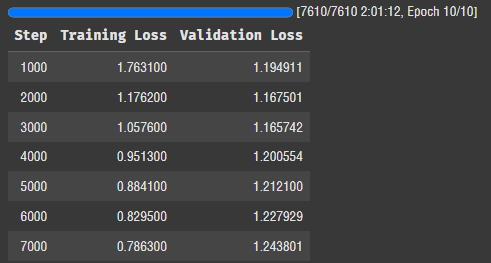
배치를 높여서 그런지 2시간만에 학습이 끝났다. 만약 배치 4로 10에폭 했으면 8시간은 걸렸을 것 같다.
로스가 0.78로 떨어졌는데 Valid set은 갈수록 로스가 높아진다. 이상하네... 뭔가 문제가 있는 것 같다.
evaluate_model(
model=loaded_model,
tokenizer=loaded_tokenizer,
df=valid_df,
device=device,
num_samples=1000
)어제 만든 평가함수를 사용해서 Valid set의 1000개 데이터를 평가해보자.

흠,,, 뭔가 괜찮은 것 같기도 하면서 또 어떤 샘플은 0점이 나오기도 한다.
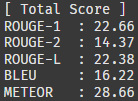
1000개 샘플의 점수 평균이다. 약 20점대라고 보면 될 것 같다.
어느 부분 때문에 성능이 안 좋은 건지 확인할 수가 없다 ㅠㅠ...
text_to_summarize = """
보험사기방지특별법 개정안이 국회 법제사법위원회 문턱을 통과했고 본회의에 상정되면서 법 제정 이후 8년 만에 손질할 수 있게 됐다.
다만 보험사기에 연루된 보험업 종사자의 가중처벌 조항이 삭제된 채 처리됨에 따라 개정안의 실효성 논란도 제기되고 있다.
25일 금융당국과 보험업계 등에 따르면 지난 24일 국회 법제사법위원회를 통과한 보험사기방지특별법 개정안이 이날 오후 본회의에 올라가 표결에 부쳐진다.
본회의에 상정돼 최종 통과가 되면 8년 만에 첫 개정으로 여야 간 이견이 없는 만큼, 무난하게 처리될 것으로 보인다.
"""
inputs = loaded_tokenizer(
text_to_summarize,
return_tensors="pt",
max_length=1024,
truncation=True
).to(device)
summary_ids = loaded_model.generate(
inputs['input_ids'],
max_length=150,
num_beams=5,
early_stopping=True
)
generated_summary = loaded_tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print("───────────────────────────────────")
print("[ Original ]")
print(text_to_summarize)
print("───────────────────────────────────")
print("[ Summarize ]")
print(generated_summary)새로운 데이터를 잘 요약하는지 확인해 보자.
위 텍스트는 네이버 기사에서 일부 가져왔다.

이렇게 보면 또 괜찮은 것 같은데,,,? 원래 자연어 모델이 점수가 안 좋은 건가
누가 문제좀 시원하게 해결해 줬으면 좋겠다....
일단 어찌어찌해서 이번 미션도 끝...!

AI Engineer