신기한 인공지능의 세계! 영화에서나 듣던 양자를 여기서 듣다니...
학습시간 09:00~03:00(당일18H/누적1426H)
◆ 학습내용
1. LoRA
(1) Fine-tuning의 한계
A. 기존 Full Fine-tuning의 문제점
- GPT-3 같은 거대 모델의 모든 파라미터를 재학습시키는 방식은 비용이 매우 많이 듦
- 특정 작업에 맞춰 미세조정할 때마다 원본 모델 크기의 독립적인 파일이 생성됨
- 이는 수많은 모델을 저장하고 배포하는 것을 거의 불가능하게 만듦
- 예를 들어 GPT-3 모델 하나를 미세조정하면 1750억 개의 파라미터를 가진 새 모델이 생김
B. 기존 경량화 기법들의 문제점
- 어댑터(Adapter) 방식은 모델에 새로운 레이어를 추가하여 추론할 때 처리 속도를 느리게 만듦
- 특히 한 번에 한 개씩 처리하는 온라인 환경에서 속도 저하 문제는 더 심각해짐
- 접두사 튜닝(Prefix-tuning) 같은 방식은 모델이 한 번에 읽을 수 있는 글자의 길이를 줄이는 단점이 있음
- 또한, 접두사 튜닝은 최적화가 어렵고 학습하는 파라미터가 많아질수록 오히려 성능이 떨어지기도 함
| 구분 | 전체 미세조정 (Full Fine-tuning) | 어댑터 (Adapter) | 접두사 튜닝 (Prefix-tuning) |
|---|---|---|---|
| 파라미터 | 전부 학습 (매우 많음) | 일부만 학습 (적음) | 일부만 학습 (적음) |
| 저장 용량 | 매우 큼 | 작음 | 작음 |
| 추론 속도 | 기준 | 추가 레이어로 인한 지연 발생 | 저하 없음 |
| 단점 | 높은 비용, 큰 저장 공간 필요 | 추론 지연, 순차적 계산 필요 | 사용 가능 시퀀스 길이 감소 |
(2) Low-Rank 가설
A. 핵심 가설
- 사전 학습된 거대 언어 모델은 사실 '저차원의 내재적 차원'에 존재함
- 이를 바탕으로, 모델을 특정 작업에 맞게 변화시키는 '가중치 업데이트' 정보 또한 '낮은 순위(low-rank)', 즉 단순하고 핵심적인 구조일 것이라고 가정함
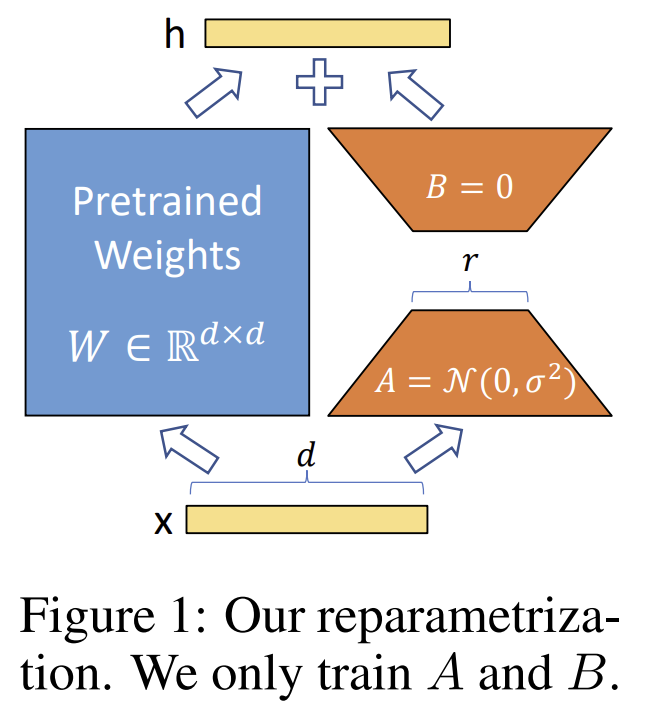
B. 재파라미터화(Reparameterization)
- 기존의 거대한 사전 학습 가중치는 변경되지 않도록 고정함(freeze)
- 모델을 변화시키는 '업데이트 정보'를, 훨씬 작은 두 개의 행렬(A와 B)의 곱으로 분해하여 표현함
- 여기서 두 행렬 A와 B는 원래 가중치 행렬의 크기보다 훨씬 작은 중간 다리 역할(rank)을 거쳐 정보를 압축함
- 학습 과정에서는 오직 이 작은 두 행렬 A와 B만 업데이트함
C. 작동 방식 및 초기화
- LoRA가 적용된 레이어의 최종 결과물은 (기존 가중치의 결과값) + (새로 학습하는 두 행렬 A, B를 거친 결과값)을 더해서 만들어짐
- 행렬 A는 무작위 값으로, 행렬 B는 0으로 초기화하여 학습 초기에는 모델에 아무런 변화를 주지 않도록 설정함
- 업데이트의 강도를 일정하게 유지하기 위해, 알파(alpha)라는 상수를 랭크(rank)로 나눈 값을 조절 장치로 사용함
(코드예시)
class LoRALinear(nn.Module):
def __init__(self, linear_layer, rank, alpha):
super().__init__()
self.r = rank
self.alpha = alpha
self.in_features = linear_layer.in_features
self.out_features = linear_layer.out_features
self.weight = linear_layer.weight
self.bias = linear_layer.bias
self.lora_A = nn.Parameter(torch.randn(self.r, self.in_features))
self.lora_B = nn.Parameter(torch.zeros(self.out_features, self.r))
self.scaling = self.alpha / self.r
self.weight.requires_grad = False
def forward(self, x):
original_output = nn.functional.linear(x, self.weight, self.bias)
lora_update = (x @ self.lora_A.T @ self.lora_B.T) * self.scaling
return original_output + lora_update(3) 효율성과 성능
A. 파라미터 및 하드웨어 효율성
- GPT-3 모델에서 학습 가능한 파라미터 수를 10,000배까지 줄일 수 있음
- 대부분의 파라미터를 고정시키므로, Adam 같은 optimizer의 상태를 저장할 필요가 없어 GPU 메모리 사용량을 최대 3배 줄임
- 모델 저장 파일 크기를 GPT-3 기준 350GB에서 35MB로 대폭 감소시킴
- 학습해야 할 정보량이 크게 줄어들어 GPT-3에서 전체 미세조정 대비 학습 속도가 25% 향상됨
B. 추론 성능
- 어댑터 방식과 달리 추가적인 처리 시간 지연을 발생시키지 않음
- 배포 시점에는 학습된 두 개의 작은 행렬(A와 B)을 미리 계산해서 기존 가중치에 더해 하나의 행렬로 만들 수 있기 때문
- 이로 인해 추론 과정은 무거운 전체 미세조정 모델과 완전히 동일하게 작동함
C. 태스크 전환 및 확장성
- 하나의 거대한 사전 학습 모델을 공유하면서 여러 작업들을 위한 작은 LoRA 모듈들을 만들 수 있음
- 실제 서비스에서 작업을 바꿀 때, 전체 모델 파일을 교체하는 대신 작은 LoRA 가중치만 바꾸면 되므로 매우 빠르고 효율적임
- 수많은 커스텀 모델을 즉시 교체하며 서비스하는 것이 가능해짐
| 장점 항목 | 상세 내용 |
|---|---|
| 저장 공간 효율성 | 저장 파일 크기를 10,000배까지 줄임 (GPT-3 기준) |
| 메모리 효율성 | 학습 시 GPU VRAM 사용량을 최대 3배까지 줄임 |
| 추론 속도 | 추가 지연 시간 없음 (No Inference Latency) |
| 학습 속도 | 전체 미세조정 대비 25% 향상 (GPT-3 기준) |
| 성능 | 전체 미세조정과 비슷하거나 더 나은 성능을 보임 |
| 운영 효율성 | 작은 모듈 교체만으로 빠른 태스크 전환 가능 |
(4) 주요 모델 성능 비교
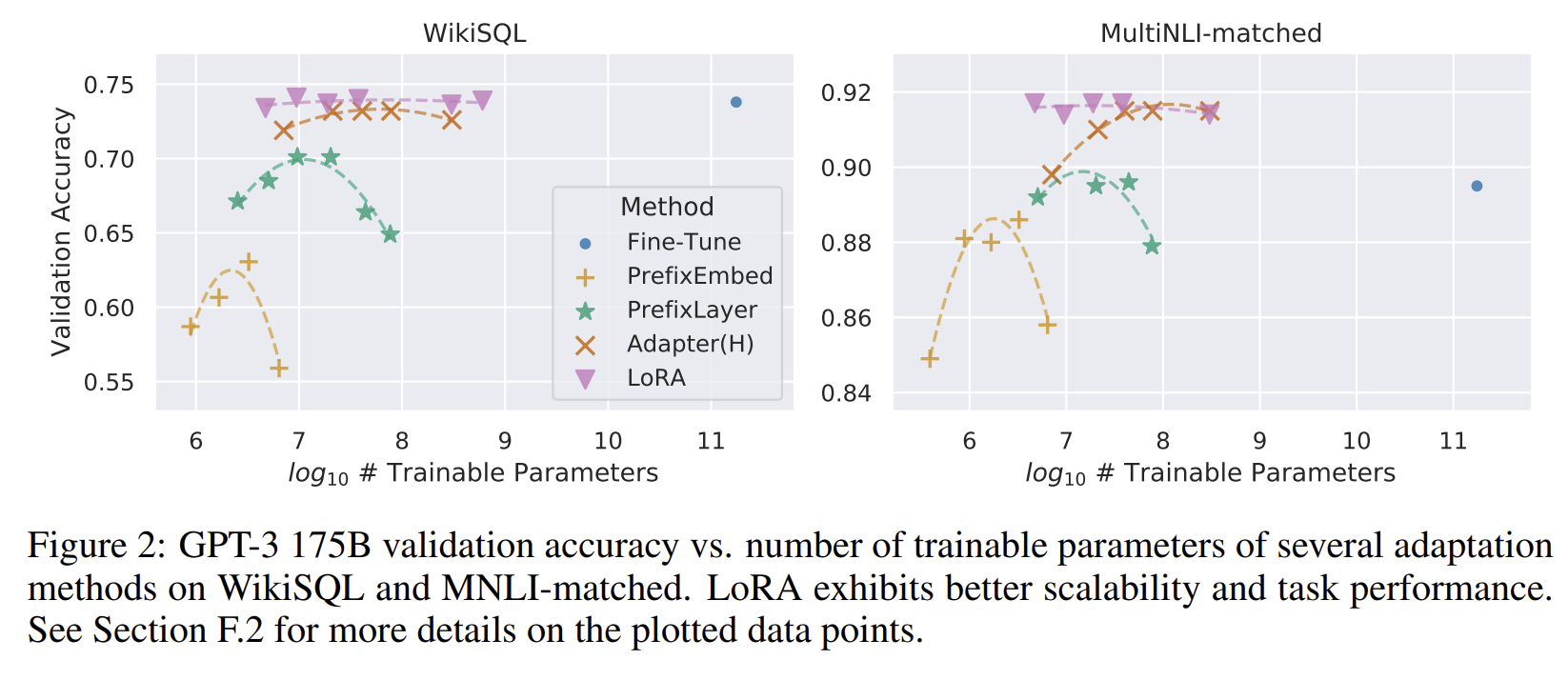
A. GPT-3 175B 성능
- LoRA는 WikiSQL, MultiNLI 같은 작업에서 전체 미세조정 성능과 비슷하거나 더 좋은 성능을 보임
- 특히 아주 적은 수의 파라미터를 가진 LoRA가 1750억 개를 모두 학습한 전체 미세조정보다 더 좋은 결과를 보이기도 함
- 다른 경량화 기법들과 달리, LoRA는 학습 파라미터가 늘어날수록 성능이 안정적으로 향상되는 좋은 확장성을 보임
B. RoBERTa, DeBERTa, GPT-2 성능
- RoBERTa와 DeBERTa 모델을 사용한 GLUE 벤치마크 평가에서 전체 미세조정과 대등한 성능을 달성함
- GPT-2를 이용한 자연어 생성(NLG) 작업에서도 기존 기법들보다 뛰어난 성능을 보임
(5) Low-Rank 업데이트 행렬 분석
A. 최적 적용 대상
- 트랜스포머 구조 안의 모든 가중치에 LoRA를 적용하는 것보다, 특정 부분에 집중하는 것이 더 효율적임
- 제한된 파라미터 예산 안에서, Self-Attention 모듈의 쿼리(Query)와 밸류(Value) 행렬에만 LoRA를 적용했을 때 가장 좋은 성능을 보임
- 이는 하나의 가중치에 높은 랭크(rank)를 할당하는 것보다, 여러 가중치에 더 낮은 랭크를 나누어 할당하는 것이 유리함을 의미함
B. 최적 랭크(rank)의 비밀
- 놀랍게도 1이나 2 같은 매우 낮은 랭크 값으로도 경쟁력 있는 성능을 달성함
- 이는 모델을 바꾸는 데 필요한 정보가 실제로 매우 단순하고 핵심적인 구조(low-rank)라는 가설을 강력하게 뒷받침함
- 서로 다른 랭크(예: 8과 64)로 학습된 행렬을 비교해보니, 가장 중요한 핵심 정보(최상위 방향)만 공유하고 나머지는 크게 겹치지 않았음
- 이는 랭크를 무작정 높이는 것이 반드시 더 좋은 성능으로 이어지지 않음을 보여줌
C. 업데이트 정보와 기존 정보의 관계
- LoRA가 학습한 '업데이트 정보'는 기존 모델이 가진 '원래 정보'에서 가장 중요한 부분을 단순히 복사하는 것이 아님
- 대신, '업데이트 정보'는 '원래 정보' 안에 이미 존재하지만 크게 주목받지 못했던 특징들을 찾아내 증폭시키는 역할을 함
- 이 증폭 효과는 상당히 커서, 랭크가 4일 때 약 21.5배에 달했음
- 이는 LoRA가 일반적인 지식 속에 숨어있던, 특정 작업에 필요한 전문 지식을 찾아내 강화하는 방식으로 작동함을 보여줌
| 분석 주제 | 결론 요약 |
|---|---|
| 최적 적용 가중치 | Self-Attention의 쿼리(Query)와 밸류(Value)에 동시에 적용하는 것이 가장 효율적 |
| 최적 랭크(rank) | 매우 작은 값(1, 2, 4, 8)으로도 충분하며, 이는 업데이트 정보의 차원이 낮다는 증거 |
| 업데이트의 역할 | 기존 정보의 특징을 복사하는 것이 아니라, 특정 작업에 필요한 방향을 찾아 증폭시키는 역할 |
2. 문제
LoRA가 해결하고자 했던 '전체 미세 조정(Full Fine-tuning)'의 가장 큰 문제점은 무엇인가요?
- 각 태스크마다 원본 모델만큼 큰 별도의 미세 조정 모델을 배포하는 것은 엄청나게 비쌈
- 미세 조정을 거친 새 모델은 원본과 동일한 수의 파라미터를 가져 저장 공간에 큰 부담을 줌
- 특히 GPT-3 175B 같은 거대 모델의 경우, 수많은 버전을 저장하고 배포하는 것이 현실적으로 어려움
LoRA 이전에 존재했던 PEFT 기법인 '어댑터(Adapter)'의 주된 단점은 무엇인가요?
- 모델의 깊이를 확장시켜 추론 시 지연 시간(inference latency)을 필연적으로 발생시킴
- 어댑터 레이어는 순차적으로 처리되어야 하므로 배치 크기가 작은 온라인 추론 환경에서 속도 저하가 눈에 띔
- 모델 병렬화 시 추가적인 GPU 동기화 작업이 필요해 복잡성을 증가시킴
LoRA의 핵심 가설은 사전 훈련된 가중치 행렬(W₀)의 변화량(ΔW)이 어떤 속성을 가진다는 것인가요?
- 모델을 특정 작업에 적응시킬 때 가중치의 변화량이 낮은 '내재적 순위(intrinsic rank)'를 가짐
- 이는 사전 훈련된 언어 모델 자체가 낮은 '내재적 차원(intrinsic dimension)'에 존재한다는 연구에 영감을 받음
- 즉, 모든 가중치를 바꿀 필요 없이 핵심적인 저차원(low-rank) 정보만으로도 충분한 업데이트가 가능함
LoRA는 ΔW를 어떻게 표현하나요?
- 훨씬 작은 두 개의 행렬 A와 B의 곱셈(BA)으로 분해하여 표현함
- 이때 랭크(r)는 원래 행렬의 차원보다 훨씬 작은 값으로 설정됨
- 이를 통해 방대한 업데이트 정보(ΔW)를 소수의 파라미터를 가진 A, B 행렬로 압축함
LoRA 훈련 시작 시, 행렬 A와 B는 어떻게 초기화되나요?
- 행렬 A는 무작위 가우시안 분포를 사용하여 초기화함
- 행렬 B는 0으로 초기화하여 학습 시작점에는 아무런 변화가 없도록 만듦
- 이 초기화 방식 덕분에 학습 시작 시점의 가중치 변화량(ΔW)은 0이 됨
LoRA의 결정적 이점인 추가 지연 없이 추론할 수 있는 이유는 무엇인가요?
- 배포 시점에 학습된 두 행렬(A, B)의 곱을 기존 가중치(W₀)에 미리 더해 하나의 행렬로 만들 수 있음
- 이 병합된 가중치(W = W₀ + BA)를 사용하면 추론 과정은 일반 미세 조정 모델과 완전히 동일해짐
- 설계상 추가적인 계산이나 레이어가 없어 추론 지연 시간이 전혀 발생하지 않음
실험에서 어떤 가중치 행렬에 LoRA를 적용했을 때 최적 성능을 보였나요?
- 트랜스포머의 Self-Attention 모듈 내 가중치 행렬들을 대상으로 실험함
- 쿼리(Wq)와 밸류(Wv) 두 종류의 가중치 행렬에 동시에 LoRA를 적용했을 때 가장 좋은 성능을 보임
- 하나의 행렬(예: Wq)에 더 높은 랭크를 할당하는 것보다 여러 종류의 행렬에 낮은 랭크를 할당하는 것이 더 효과적이었음
랭크 r 값이 작은 경우 성능은 어땠나요?
- 놀랍게도 매우 작은 랭크(r=1, 2)만으로도 경쟁력 있는 성능을 달성함
- 특히 Wq와 Wv를 함께 조정할 때, 랭크가 1인 경우에도 높은 성능을 기록함
- 이는 가중치 업데이트에 필요한 정보가 실제로 매우 낮은 순위(low-rank) 구조임을 시사함
GPU 메모리 사용량을 크게 줄인 주된 이유는 무엇인가요?
- 모델의 대부분을 차지하는 사전 훈련된 가중치를 '동결(freeze)'시키기 때문
- 동결된 파라미터에 대해서는 Adam과 같은 옵티마이저의 상태(예: 모멘텀)를 저장할 필요가 없음
- 훨씬 크기가 작은 LoRA 행렬(A, B)에 대한 옵티마이저 상태만 유지하면 되므로 메모리 부담이 크게 줄어듦
GPT-3 175B에 적용했을 때 파라미터 효율성 대비 성능이 가장 좋았던 기법은?
- LoRA가 전체 미세 조정을 포함한 다른 모든 기법들보다 좋은 성능을 보임
- 심지어 470만 개의 파라미터를 사용한 LoRA가 1750억 개를 사용한 전체 미세 조정보다 성능이 높게 나옴
- 다른 기법들은 파라미터 수를 늘렸을 때 오히려 성능이 하락했지만, LoRA는 안정적인 성능 향상을 보임
3. QLoRA
(1) 탄생배경
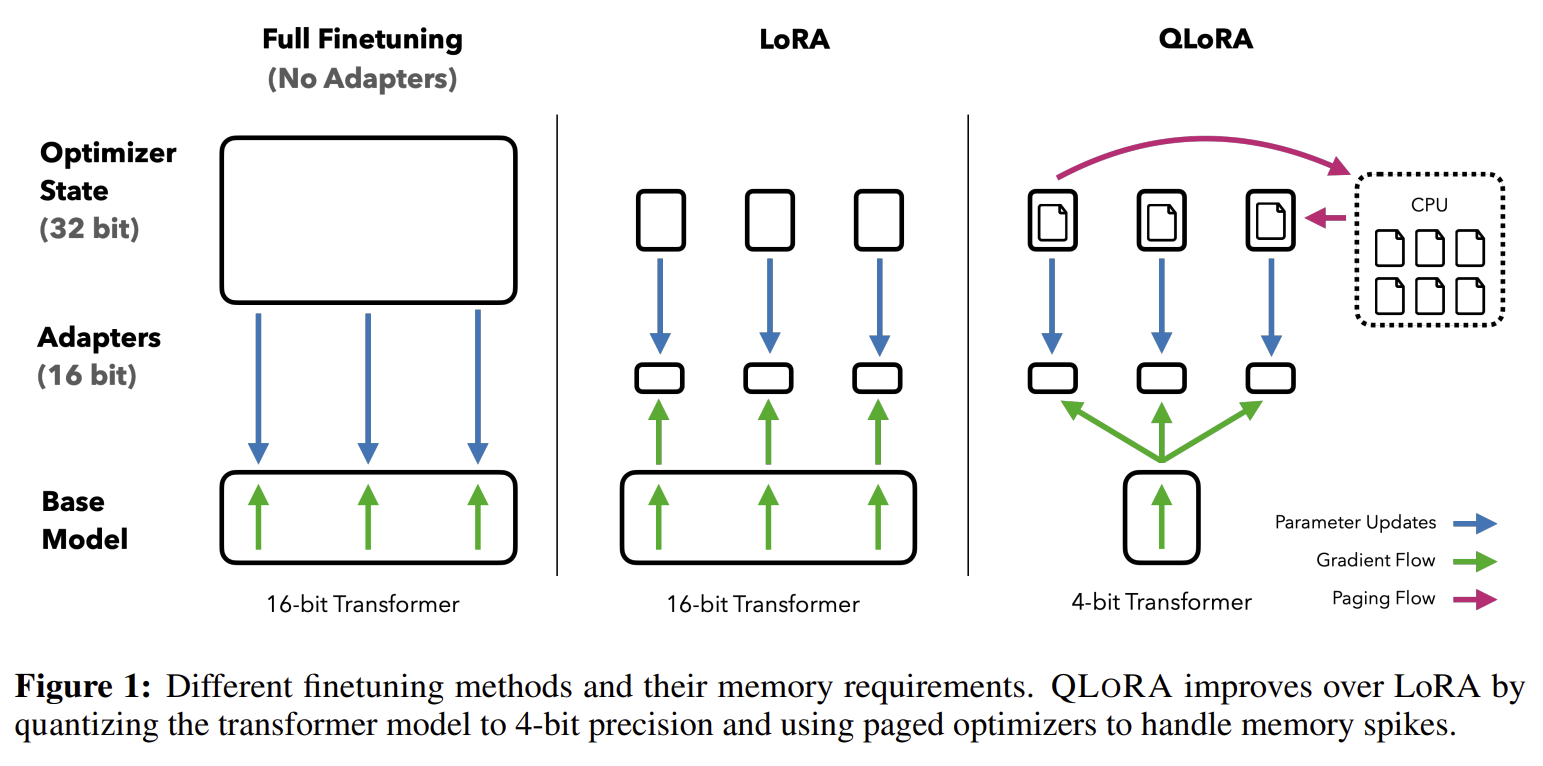
A. 메모리 요구량
- 기존의 16비트 정밀도로 LLM을 미세조정하는 것은 엄청난 양의 GPU 메모리를 필요로 함
- 예를 들어 LLaMA 65B 모델을 16비트로 미세조정하려면 780GB가 넘는 GPU 메모리가 필요함
- 이는 일반적인 연구자나 개발자가 감당하기 어려운 수준임
B. 기존 양자화 기술의 한계
- 추론(inference) 시에 모델의 메모리 사용량을 줄이는 양자화 기술은 존재했음
- 하지만 이런 기술들은 학습(training) 과정에서는 성능이 크게 저하되어 사용할 수 없었음
- 즉, 모델을 훈련시킬 때는 여전히 막대한 메모리가 필요하다는 문제가 해결되지 않음
(2) 핵심요소: NF4
- QLoRA는 NF4라는 새로운 4비트 데이터 타입을 도입함
- 이는 정보 이론 관점에서 정규 분포를 따르는 데이터에 가장 최적화된 데이터 타입임
- 기존의 4비트 정수(Integer)나 일반 부동소수점(Float) 방식보다 더 나은 성능을 보여줌
- LLM의 가중치가 대부분 평균이 0인 정규 분포를 따른다는 점에 착안함
- 정규 분포의 형태에 딱 맞는 '맞춤형 자'를 만든다고 생각하면 이해하기 쉬움
- 모든 데이터 구간에 동일한 개수의 값이 할당되도록 양자화를 수행하여 정보 손실을 최소화함
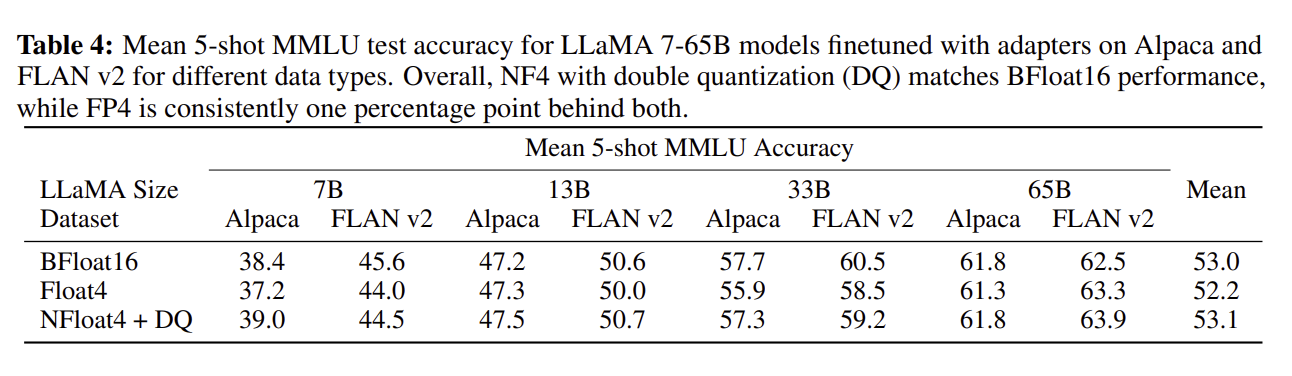
Overall, NF4 with double quantization (DQ) matches BFloat16 performance.
(3) 핵심요소: Double Quantization
- 양자화를 할 때는 '양자화 상수'라는 추가적인 정보가 필요한데, 이 정보도 메모리를 차지함
- 이중 양자화는 이 '양자화 상수' 자체를 다시 한번 양자화하는 기술임
- 비유하자면, 파일을 압축할 때 생기는 메타데이터를 다시 한번 압축해서 용량을 더 줄이는 것과 같음
- 이중 양자화를 통해 파라미터당 평균 0.37비트의 메모리를 추가로 절약함
- 65B 모델의 경우, 이 기술만으로 약 3GB의 메모리를 절약하는 효과를 가져옴
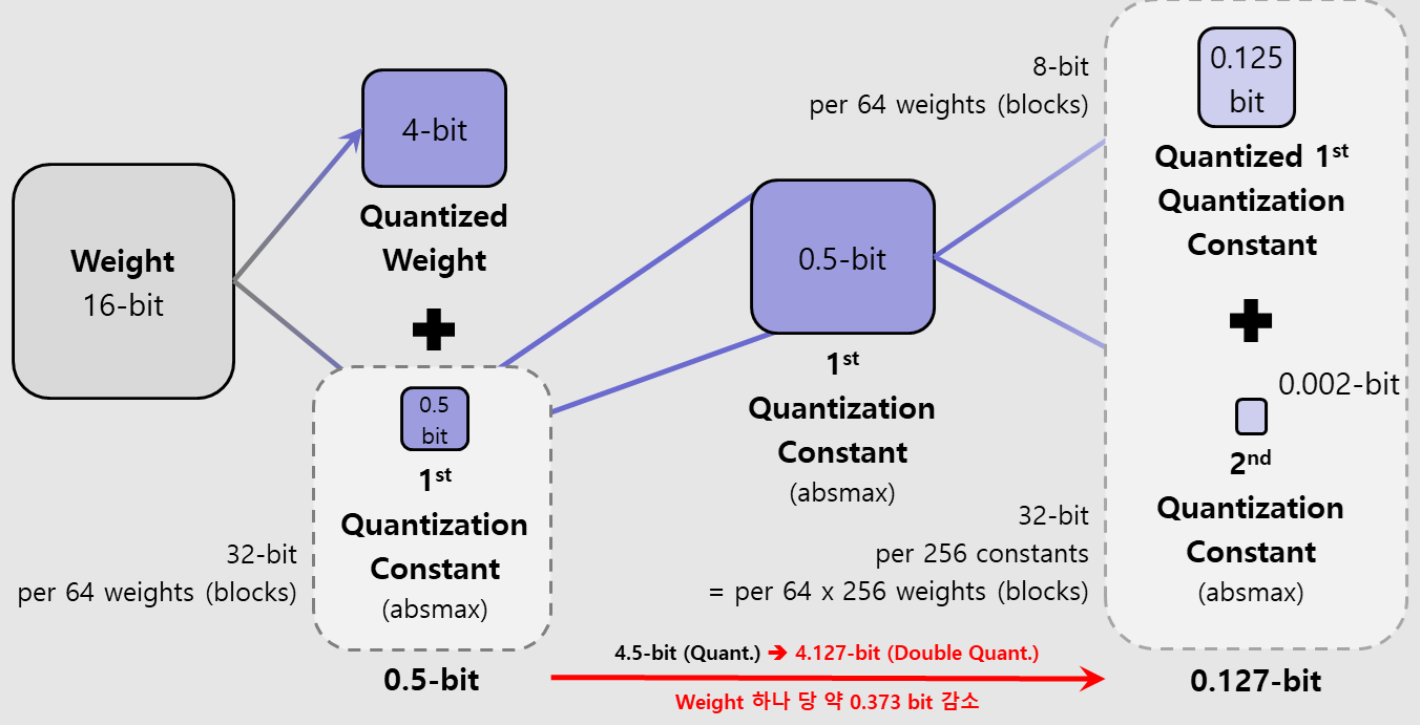
가중치 변화량: 16bit(양자화 전) -> 4.5bit(양자화 1차) -> 4.127bit(양자화 2차)
4비트를 역양자화하기 위해 0.5비트의 상수가 필요함
(4) 핵심요소: Paged Optimizers
- 학습 중 긴 시퀀스를 처리할 때 순간적으로 메모리 사용량이 급증하여 오류가 발생하는 경우가 많음
- 페이지드 옵티마이저는 NVIDIA의 통합 메모리(Unified Memory) 기능을 활용함
- GPU 메모리가 부족해지면, 옵티마이저 상태(optimizer states)를 CPU RAM으로 이동시키고, 필요할 때 다시 GPU로 불러와 메모리 부족 오류를 방지함
(코드예시)
import torch
import torch.nn as nn
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from peft import get_peft_model, LoraConfig
# 1. 4-bit 양자화 설정 (NF4, Double Quantization 포함)
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
# 2. 양자화된 베이스 모델 로드
base_model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
quantization_config=quantization_config,
device_map='auto'
)
# 3. LoRA 설정 (어댑터만 학습)
lora_config = LoraConfig(
r=8,
lora_alpha=8,
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"],
bias="none",
task_type="CAUSAL_LM",
)
# 4. QLoRA 모델 준비 완료
qlora_model = get_peft_model(base_model, lora_config)
qlora_model.print_trainable_parameters()
(5) QLoRA 작동방식
A. 양자화와 역양자화
- 베이스 모델의 가중치는 4비트(NF4)라는 매우 낮은 정밀도로 저장되어 메모리를 아낌
- 하지만 실제 계산(순전파 및 역전파)을 할 때는 이 4비트 가중치를 16비트(BFloat16)로 순간적으로 변환(역양자화)하여 사용함
- 이를 통해 정밀도 손실 없이 계산을 수행할 수 있음
B. 그래디언트 계산
- 역전파 과정에서 그래디언트(기울기)는 오직 LoRA 어댑터 파라미터에 대해서만 계산됨
- 4비트로 얼려진 베이스 모델의 가중치에 대해서는 그래디언트를 계산하지 않아 엄청난 계산량과 메모리를 절약함
- 즉, '계산은 16비트로 정확하게, 저장은 4비트로 가볍게, 학습은 LoRA만' 하는 방식임
C. 적용 범위
- 실험 결과, 4비트 QLoRA는 16비트 전체 미세조정 및 16비트 LoRA와 동일한 수준의 성능을 달성함
- 기존 LoRA처럼 일부 레이어(예: 쿼리, 밸류 행렬)에만 어댑터를 적용해서는 16비트 성능을 따라잡기 어려웠음
- 완전한 성능을 재현하기 위해서는 트랜스포머의 모든 선형(linear) 레이어에 LoRA 어댑터를 적용하는 것이 매우 중요했음
4. 문제
QLoRA가 달성하고자 한 핵심 목표는 무엇인가요?
- 65B 모델을 단일 48GB GPU에서 파인튜닝할 수 있을 정도로 메모리 사용량을 줄임
- 16비트 전체 파인튜닝과 동일한 태스크 성능을 보존함
- 양자화된 4비트 모델을 성능 저하 없이 파인튜닝하는 것을 최초로 증명함
QLoRA가 메모리 절약을 위해 도입한 세 가지 핵심 혁신 기술은 무엇인가요?
- 4비트 NormalFloat(NF4)라는 새로운 데이터 타입을 도입함
- 양자화 상수를 다시 양자화하는 이중 양자화(Double Quantization) 기법을 사용함
- 메모리 스파이크를 관리하기 위한 페이지드 옵티마이저(Paged Optimizers)를 활용함
4비트 NormalFloat(NF4) 데이터 타입이 효과적인 이유는 무엇인가요?
- 정규 분포를 따르는 가중치에 대해 정보 이론적으로 최적화된 새로운 4비트 데이터 타입임
- 각 양자화 구간(bin)에 동일한 수의 값이 할당되도록 설계되어 정보 손실을 최소화함
- 실험 결과, 기존의 4비트 정수(Int4)나 부동소수점(FP4)보다 뛰어난 성능을 보임
'이중 양자화(Double Quantization)' 기법은 무엇을 위한 기술인가요?
- 양자화 과정에서 사용되는 '양자화 상수' 자체를 다시 한번 양자화하는 기법임
- 양자화 상수가 차지하는 메모리 공간을 추가로 줄여줌
- 65B 모델 기준, 파라미터당 평균 0.37비트의 메모리를 추가로 절약함
'페이지드 옵티마이저(Paged Optimizers)'는 어떤 문제를 해결하나요?
- 긴 시퀀스를 처리할 때 그래디언트 체크포인팅 과정에서 발생하는 순간적인 메모리 급증 문제를 해결함
- GPU 메모리가 부족해질 때 발생하는 '메모리 부족(out-of-memory)' 오류를 방지함
- GPU 메모리가 부족하면 옵티마이저 상태를 자동으로 CPU RAM으로 옮겨 에러 없이 학습을 지속함
QLoRA의 학습 과정에서 가중치 '저장'과 '계산'은 각각 어떤 정밀도로 이루어지나요?
- 가중치 저장은 저정밀도인 4비트 NormalFloat(NF4)를 사용함
- 순전파 및 역전파 같은 실제 연산은 고정밀도인 16비트 BrainFloat(BF16)로 수행함
- 저장된 4비트 가중치를 계산 시점에 16비트로 역양자화하여 정밀도 손실 없이 연산함
QLoRA가 16비트 미세조정 성능을 완전히 재현하기 위해 실험에서 발견한 중요한 LoRA 적용 방식은 무엇인가요?
- 기존 LoRA처럼 일부 어텐션 레이어에만 어댑터를 적용하는 것만으로는 16비트 성능을 완전히 따라잡지 못함
- 16비트 파인튜닝 성능을 완전히 재현하기 위해서는 트랜스포머의 모든 선형(linear) 레이어에 LoRA를 적용해야 함
- LoRA 랭크(r) 값 자체는 성능에 큰 영향을 주지 않았음
QLoRA로 훈련된 모델 제품군의 이름은 무엇이며, 챗봇 성능은 어땠나요?
- QLoRA로 훈련된 모델 제품군은 'Guanaco(과나코)'라고 불림
- 가장 성능이 좋은 Guanaco 65B 모델은 Vicuna 벤치마크에서 ChatGPT 성능의 99.3%에 도달함
- 단일 GPU에서 24시간만 훈련하여 높은 성능을 달성함
데이터셋의 '크기'와 '품질' 중 무엇이 더 중요하다고 논문은 결론 내렸나요?
- 데이터셋의 품질이 크기보다 훨씬 더 중요함
- 9천 개의 고품질 데이터(OASST1)로 학습한 모델이 45만 개의 데이터(FLAN v2)로 학습한 모델보다 챗봇 성능이 더 좋았음
- 이는 잘 정제된 소량의 데이터가 무작정 많은 데이터보다 효과적일 수 있음을 보여줌
QLoRA가 LoRA보다 메모리를 훨씬 더 효율적으로 사용하는 핵심적인 이유는 무엇인가요?
- 거대한 베이스 모델을 4비트로 양자화하여 저장 공간을 대폭 줄임
- 학습이 필요한 부분은 작은 LoRA 어댑터로 한정하고, 그래디언트는 이 어댑터에 대해서만 계산함
- 이중 양자화와 페이지드 옵티마이저 같은 기술로 메모리 오버헤드를 추가로 절감함

AI Engineer