이제야 그동안 배운 것들을 써먹을 수 있는 퍼즐이 맞추어지는 느낌이다...!
학습시간 09:00~01:00(당일16H/누적1943H)
◆ 학습내용
웹앱 모델 배포 실습!!
목표
- 손으로 숫자를 그려 입력하면 해당 숫자를 예측하는 Streamlit 기반 웹 서비스를 개발
- Github ONNX 모델 저장소에서 제공하는 MNIST ONNX 모델 활용
- https://github.com/onnx/models/tree/main/validated/vision/classification/mnist/model
사용자 인터페이스
- 입력 캔버스: 숫자를 그릴 수 있는 캔버스(streamlit-drawable-canvas 라이브러리 활용)
- 전처리 이미지 표시: 숫자 이미지를 모델 추론에 적합하게 전처리한 결과를 시각적으로 표시
- 모델 추론 결과: 0부터 9까지의 각 레이블에 대한 예측 확률을 막대 차트로 시각화
- 이미지 저장소: 사용자가 그린 이미지를 저장하고 예측 레이블 및 확률을 함께 표시
필수 기능
- 모델 관리: 모델을 다운로드하고 세션 간 효율적인 모델 관리를 위해 캐싱 기능 구현
- 이미지 처리 및 추론: 입력 이미지를 모델 입력 사양에 맞게 전처리하고 추론하는 함수 개발
배포
- 도커 컨테이너화: Dockerfile을 작성하여 서비스를 도커 이미지로 빌드
- 도커 허브 배포: 완성된 도커 이미지를 Docker Hub에 업로드하여 배포
1. 모델 다운로드
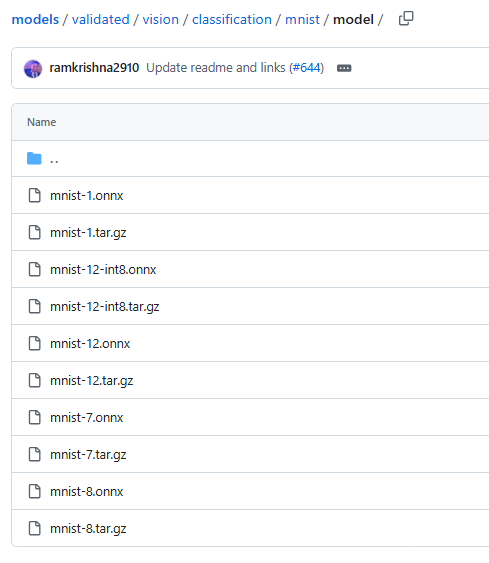
제공된 링크로 들어가니 이미 만들어진 onnx 파일들이 있다. 숫자가 1, 7, 8, 12 이렇게 있는데 찾아보니 모델 버전이라고 한다. YOLO 뒤에 붙는 숫자 느낌인듯.
일단 12 버전을 사용하는 것으로 하고, qint8로 내가 직접 양자화해서 다시 onnx 파일로 변환 후 사용해 봐야겠다.
model_url = "https://github.com/onnx/models/raw/main/validated/vision/classification/mnist/model/mnist-12.onnx"
fp32_model_path = "mnist-12.onnx"
qint8_model_path = "mnist-12-qint8.onnx"
urllib.request.urlretrieve(model_url, fp32_model_path)
quantize_dynamic(
model_input=fp32_model_path,
model_output=qint8_model_path,
weight_type=QuantType.QInt8,
)링크에서 onnx 파일을 다운로드 받고 qint8 타입으로 변환 후 다시 저장했다.
저장 완료! 이제 이걸 로드하면 될 것 같다.
2. 모델 로드
MODEL_PATH = "mnist-12-qint8.onnx"
@st.cache_resource
def load_model(model_path):
return ort.InferenceSession(model_path)
session = load_model(MODEL_PATH)모델을 로드하는 코드다.
streamlit run app.py로드가 잘 되는지 보자!
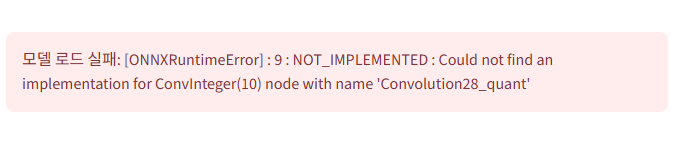
에러가 떴다.
Could not find an implementation for ConvInteger(10) node with name 'Convolution28_quant'
Convolution28_quant 라는 노드를 찾을 수 없다고 한다. conv 레이어에 무슨 문제가 있는 것 같은데 뭐지...?
quantize_dynamic(
model_input=fp32_model_path,
model_output=qint8_model_path,
weight_type=QuantType.QInt8,
op_types_to_quantize=['MatMul']
)qint8 양자화 시에는 데이터를 같이 주입해 보정해주는 작업이 필요하다고 한다.
일단 이건 해본 적이 없어서 다른 방법을 찾아봤는데, 보정이 필요한 레이어는 양자화를 안 하고 진행하면 된다고 한다.
MatMul로 시작하는 레이어만 양자화하고 ConvInteger 레이어는 무시하는 코드를 추가해서 다시 저장했다.
streamlit run app.py다시 실행해보자!

아무것도 안 나온 걸 보니 모델이 잘 로드된 것 같다.
3. 웹앱
if session:
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name로드한 모델로 인풋 아웃풋 분기를 만들어 준다.
입력한 이미지를 전처리해서 인풋에 넣고, 출력된 아웃풋을 웹에 보내야 한다.
# 이미지 전처리 함수
def preprocess_image(image_data):
# RGBA -> Grayscale
img = Image.fromarray(image_data.astype('uint8'), 'RGBA').convert('L')
# 28x28로 리사이즈
img_resized = img.resize((28, 28), Image.Resampling.LANCZOS)
# Numpy 배열로 변환하고 0~1 사이로 정규화
img_array = np.array(img_resized, dtype=np.float32) / 255.0
# 모델 입력 형식에 맞게 차원 확장 (1, 1, 28, 28)
processed = np.expand_dims(img_array, axis=(0, 1))
return processed캔버스에 숫자를 그리고 예측 버튼을 누르면 이 함수가 발동되어 전처리 후 모델로 보낸다.
흑백, 사이즈, 정규화, 차원 맞춤 4개만 한다.
# 세션 초기화
if 'stored_images' not in st.session_state:
st.session_state.stored_images = []빈 리스트의 세션을 만들어 준다. 예측한 이미지를 여기에 다 넣어서 이미지 저장소로 따로 출력할 예정이다.
with st.sidebar:
st.header("Options")
stroke_width = st.slider("Stroke width", 1, 50, 20)
stroke_color = st.color_picker("Stroke color", "#000000")
bg_color = st.color_picker("Background color", "#FFFFFF")
st.subheader("🎨 Canvas")
canvas_result = st_canvas(
fill_color="rgba(255, 165, 0, 0.3)",
stroke_width=stroke_width,
stroke_color=stroke_color,
background_color=bg_color,
height=400,
drawing_mode="freedraw",
key="canvas",
)
predict_button = st.button("Predict", use_container_width=False, type="primary")먼저 그림을 그릴 캔버스를 만든다. 사이드바로 펜 굵기, 색상, 배경 색상을 선택할 수 있도록 했다.
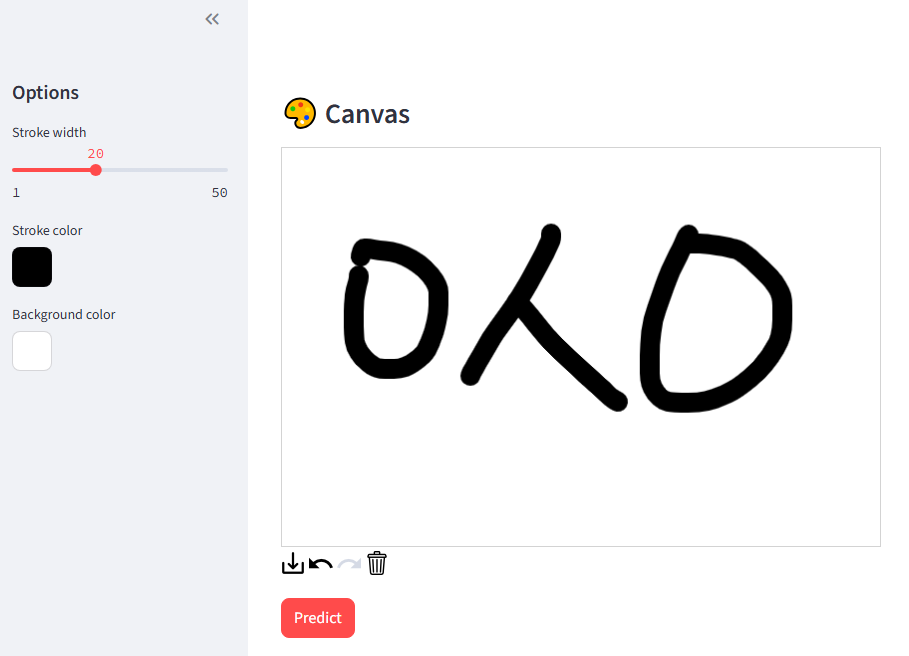
잘 나온다!
if predict_button:
# 예측값 및 확률 표시
preprocessed = preprocess_image(canvas_result.image_data)
results = session.run([output_name], {input_name: preprocessed})[0]
probabilities = scipy.special.softmax(results).flatten()
prediction = np.argmax(probabilities)
confidence = probabilities[prediction]
st.markdown(f"#### Prediction: {prediction} ({confidence:.0%})")
# 이미지 저장소에 추가
st.session_state.stored_images.append({
"image": Image.fromarray(canvas_result.image_data.astype('uint8'), 'RGBA'),
"prediction": prediction,
"confidence": confidence
})캔버스에 그려진 숫자를 예측하는 로직이다. 버튼을 누르면 데이터를 28x28 흑백 이미지로 전처리한다. 이후 ONNX 모델 세션에 넣어 숫자별 예측 점수를 도출하고, softmax 함수를 통과시켜 가장 높은 값을 argmax로 찾아낸다.
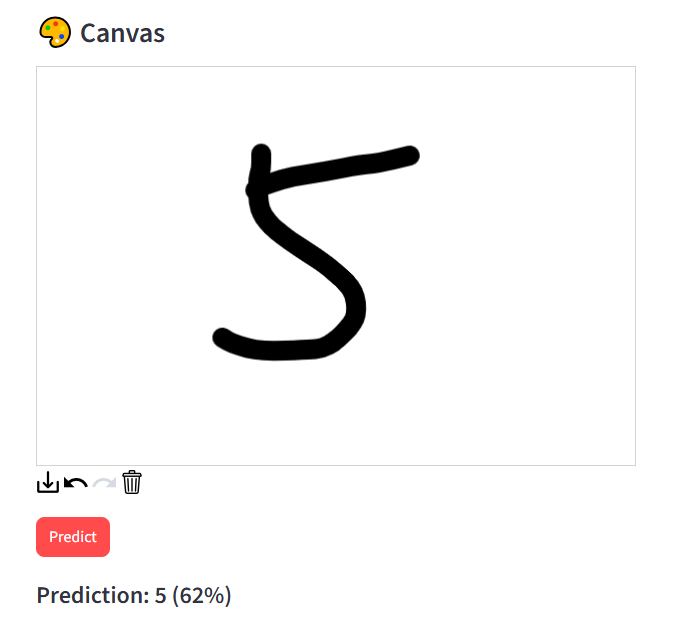
잘 작동한다! 완전 깔끔한 5인데 왜 예측 확률이 62% 밖에 안 되지..?
st.session_state.stored_images.append({
"image": Image.fromarray(canvas_result.image_data.astype('uint8'), 'RGBA'),
"prediction": prediction,
"confidence": confidence
})어쨌든 저장소에 계속 담아서 출력하기 위해 세션에 어펜드해준다.
st.subheader("🗂️ Storage")
if not st.session_state.stored_images:
st.info("EMPTY")
else:
reversed_images = st.session_state.stored_images[::-1]
cols = st.columns(5)
for i, record in enumerate(reversed_images):
with cols[i % 5]:
buffered = BytesIO()
display_img = record["image"].resize((50, 50))
display_img.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode()
# 테두리 안에 이미지와 텍스트 표시
st.markdown(f"""
<div style="border: 2px solid #ccc;
border-radius: 10px;
padding: 10px;
text-align: center;
margin: 5px;
height: 100px;">
<img src="data:image/png;base64,{img_str}" style="width: 50px;
height: 50px;">
<small><br>예측: {record['prediction']} ({record['confidence']:.0%})</small>
</div>
""", unsafe_allow_html=True)저장소 로직이다. 가로축은 최대 5개까지 올 수 있도록 했다.
인풋 이미지, 예측한 숫자, 확률 3개를 하나의 테두리 박스 안에 담을 수 있도록 간단한 HTML CSS 코드를 추가했다.

이것도 잘 나온다!
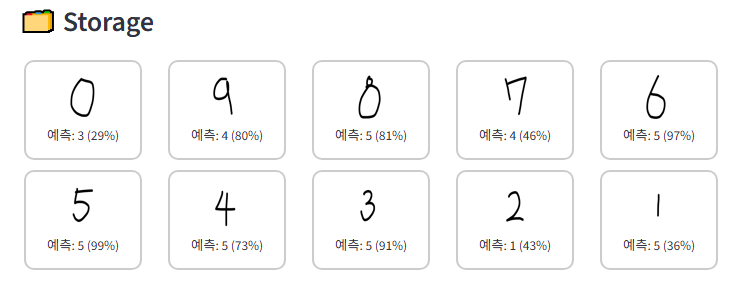
0~9까지 숫자를 다 그려봤는데,,, 결과가 이상하다??????
모델이 예측을 못한다. 높은 확률로 예측값을 그냥 5라고 하는 것처럼 느껴진다.
아무래도 어디선가 문제가 생긴 듯하다. qint8 양자화하면서 뭔가 꼬였나??
일단 오늘은 여기까지 해보자...
