흠... FastAPI로 LLM 모델 하나만 연결할 땐 할만하다 싶었는데 본격적으로 들어가니까 또 어렵다. Pydantic을 이용하면 파이썬도 타입스크립트처럼 타입을 지정할 수 있다고 한다. 아직도 배울게 태산이구나...
학습시간 09:00~02:00(당일17H/누적1977H)
◆ 학습내용
1. 웹 개발과 백엔드
(1) 클라이언트-서버 모델
A. 기본 개념
- 웹 서비스는 사용자가 보는 화면(프론트엔드, 클라이언트)과 실제 데이터 처리 및 저장을 담당하는 뒷단(백엔드, 서버)으로 나뉨
- 클라이언트는 서버에 필요한 것을 요청(Request)하고, 서버는 그 요청을 처리한 후 결과를 응답(Response)하는 구조
- 네이버 웹툰을 본다면, 클라이언트는 "A 웹툰 1화 보여줘"라고 요청하고 서버는 해당 이미지 데이터를 응답으로 보내주는 식
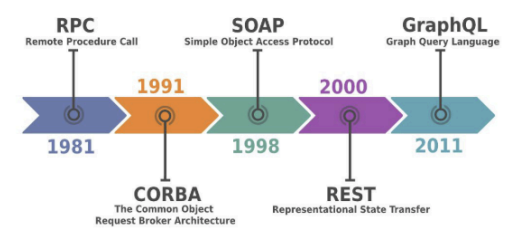
B. 통신 방식의 역사
- 초기의 RPC(1981년)부터 CORBA(1991년), SOAP(1998년)을 거쳐 현대적인 REST(2000년), GraphQL(2011년) 등으로 발전해옴
- 각 방식은 데이터를 주고받는 규칙과 구조에 차이가 있으며, 현재는 REST 방식이 가장 널리 사용됨
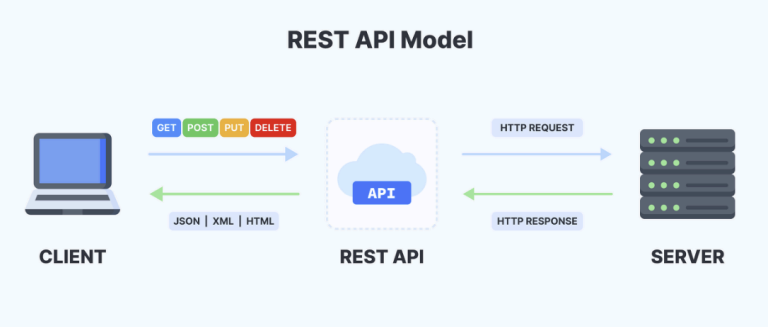
C. REST API
- 분산 시스템을 위한 아키텍처 스타일로, 자원을 이름으로 구분하여 상태를 주고받는 것을 의미
- 6가지 설계 원칙을 따름
- 균일한 인터페이스(Uniform Interface)
- 클라이언트-서버 분리(Client-Server Decoupling)
- 무상태성(Statelessness)
- 캐시 가능성(Cacheability)
- 계층화된 시스템(Layered System)
- 코드 온 디맨드(Code on Demand)
| 구분 | REST (Representational State Transfer) | GraphQL (Graph Query Language) |
|---|---|---|
| 발표 | 2000년 | 2011년 |
| 특징 | 각 자원에 대한 고유 URL(엔드포인트) 존재, 정해진 데이터 구조로만 응답 | 단일 URL(엔드포인트) 사용, 클라이언트가 필요한 데이터 구조를 직접 정의하여 요청 |
| 장점 | 직관적이고 이해하기 쉬움, 넓은 생태계와 높은 호환성 | Over-fetching, Under-fetching 문제 해결, 유연하고 효율적인 데이터 로딩 |
| 단점 | Over-fetching, Under-fetching 발생 가능, API 변경 시 버전 관리 필요 | 상대적으로 복잡한 쿼리, 캐싱 및 파일 업로드 구현이 복잡함 |
(2) HTTP 프로토콜
A. 요청과 응답
- Hypertext Transfer Protocol의 약자로, 웹 브라우저와 서버가 통신하는 규칙
- 대표적인 요청 메서드
- GET: 서버에 자료 조회를 요청
- POST: 서버에 자료 생성을 요청
- PUT: 서버의 자료 수정을 요청
- DELETE: 서버의 자료 삭제를 요청
- 대표적인 응답 상태 코드
- 1XX: 정보 전달 중
- 2XX: 요청 성공
- 4XX: 클라이언트 측 오류
- 5XX: 서버 측 오류
B. 메시지 구조
- Header: 요청과 응답의 메타데이터를 담는 부분(key-value 형태)
- Accept: 수용 데이터 형식
- Authorization: 인증 정보
- Content-Type: 요청 바디의 데이터 형식
- User-Agent: 클라이언트 정보 (앱 등)
- Body: 실제 전송하려는 데이터를 담는 부분, POST나 PUT 요청 시 주로 사용됨
- 데이터 형식은 JSON, XML, 텍스트, 바이너리(파일) 등 다양함
(3) 동기 vs 비동기
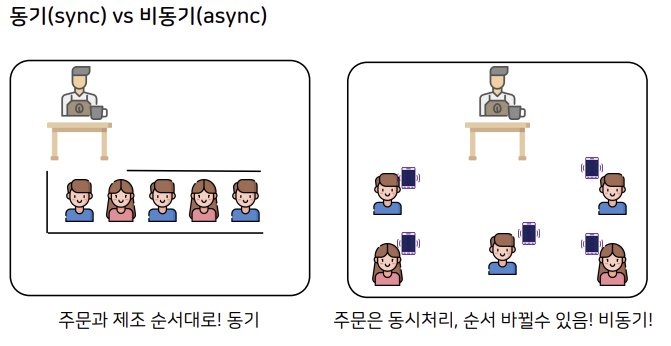
A. 개념 비교
- 동기(Synchronous): 요청을 보낸 후 응답이 올 때까지 기다리는 방식, 작업이 순서대로 처리됨
- 비동기(Asynchronous): 요청을 보낸 후 응답을 기다리지 않고 바로 다음 작업을 수행하는 방식, 처리 순서가 보장되지 않음
- FastAPI는 비동기 처리를 지원하여 I/O 작업이 많은 웹 환경에서 높은 성능을 보임
| 구분 | 동기 (Synchronous) | 비동기 (Asynchronous) |
|---|---|---|
| 처리 방식 | 요청 순서대로 하나씩 처리 | 여러 요청을 동시에 처리 시작 |
| 대기 여부 | 응답이 올 때까지 대기 | 대기 없이 다음 작업 진행 |
| 장점 | 설계가 간단하고 직관적 | 시스템 전체의 처리 효율 향상 |
| 단점 | I/O 작업에서 대기 시간으로 인한 성능 저하 | 동기 방식에 비해 설계가 복잡 |
| 예시 | 카페에서 주문하고 음료가 나올 때까지 카운터 앞에서 기다리기 | 카페에서 주문 후 진동벨을 받고 자리에서 기다리기 |
(4) 백엔드 개발자의 역할
A. 주요 업무
- 서비스 API 개발: 클라이언트 요청에 적절히 응답하는 API를 설계하고 구현
- 데이터 처리 및 관리: 데이터베이스 설계, 데이터의 생성/조회/수정/삭제 로직 구현
- 서버 관리: 서버(인프라)가 안정적으로 운영되도록 관리 (특히 AI 엔지니어는 GPU 서버 관리 능력도 중요)
- 고가용성 시스템 구축: 서비스가 중단 없이 항상 정상적으로 운영되도록 시스템을 설계하고 관리
2. FastAPI
(1) 개요
A. 핵심 특징
- 현대적이고 빠른 파이썬 기반 웹 프레임워크
- REST API를 쉽게 개발할 수 있도록 다양한 기능 제공
- Starlette(비동기 웹 프레임워크)과 Pydantic(데이터 유효성 검사 라이브러리)을 기반으로 제작
- 넷플릭스, 우버 등 글로벌 기업에서 사용 중
B. 주요 장점
- Fast to code: 직관적인 구조로 생산성이 매우 높음
- Fast to run: 비동기 지원으로 Node.js, Go에 버금가는 높은 실행 속도
- Automatic docs: OpenAPI, Swagger UI, ReDoc 등 대화형 API 문서를 자동으로 생성
- Type hints & Validation: Pydantic을 활용한 타입 힌트로 코드 안정성을 높이고, 강력한 데이터 유효성 검사 기능 제공
# main.py
from fastapi import FastAPI
# FastAPI 인스턴스 생성
app = FastAPI()
# 루트 경로('/')에 대한 GET 요청 처리
@app.get("/")
def read_root():
return {"message": "Hello, World!"}3. FastAPI 기초
(1) 환경 설정
A. 가상 환경
venv보다 약 9배 빠른uv를 사용한 가상 환경 구성을 권장pip install uv로 설치uv venv또는uv init -p 3.11명령어로 가상 환경 생성 및 파이썬 버전 지정 (3.10 이상 권장)
B. FastAPI 설치
uv add "fastapi[standard]"또는uv add fastapi --extra standard명령어로 FastAPI와 표준 의존성(uvicorn 등)을 함께 설치- 작업 완료 후
uv export -o requirements.txt로 의존성 목록을 파일로 저장 가능
(2) FastAPI 실행 및 API 문서
A. 서버 실행
uvicorn main:app --reload명령어로 개발 서버 실행main: 파이썬 파일 이름 (main.py)app: 파일 내의 FastAPI 인스턴스 변수 이름-reload: 코드가 변경될 때마다 서버를 자동으로 재시작하는 개발용 옵션
B. 자동 생성 문서
- 서버 실행 후 특정 URL로 접속하면 API 문서를 바로 확인할 수 있음
http://127.0.0.1:8000/docs: 대화형 API 테스트가 가능한 Swagger UI 문서http://127.0.0.1:8000/redoc: 가독성이 좋은 ReDoc 문서http://127.0.0.1:8000/openapi.json: OpenAPI 규격에 따른 스키마 정보
(3) 경로 매개변수와 쿼리 매개변수
A. 개념 정의
- 경로 매개변수(Path Parameter): URL 경로의 일부로 특정 자원을 식별할 때 사용 (예:
/users/{user_id}) - 쿼리 매개변수(Query Parameter): URL 경로 뒤에
?로 시작하며, 필터링, 정렬 등 부가적인 옵션을 전달할 때 사용 (예:/items?skip=0&limit=10)
from fastapi import FastAPI
app = FastAPI()
# 경로 매개변수: /items/{item_id}
@app.get("/items/{item_id}")
def read_item(item_id: int): # 타입 힌트로 자동 유효성 검사
return {"item_id": item_id}
# 쿼리 매개변수: /search?keyword=fastapi
# Optional[str] = None 또는 str | None = None 으로 선택적 파라미터 지정
@app.get("/search")
def search_items(keyword: str | None = None):
if keyword:
return {"message": f"'{keyword}' 검색 결과"}
return {"message": "검색어 없음"}(4) 기본 CRUD 구현
A. HTTP 메서드 활용
@app데코레이터를 사용하여 각 HTTP 메서드(GET, POST, PUT, DELETE)에 해당하는 API 함수(경로 작동 함수)를 정의- 함수의 매개변수로 클라이언트가 보낸 데이터를 받을 수 있으며, 함수의 반환값이 클라이언트에게 응답으로 전송됨
HTTPException을 발생시켜 특정 HTTP 상태 코드와 에러 메시지를 클라이언트에 전달 가능
(5) 데이터 유효성 검사
A. Pydantic 활용
- Pydantic의
BaseModel을 상속받아 데이터 모델 클래스를 정의하면, FastAPI가 자동으로 요청 본문(request body)의 유효성을 검사
Field를 사용하여 필드별로 더 상세한 유효성 검사 규칙(최소/최대 길이, 기본값, 설명 등)을 설정할 수 있음- 유효성 검사에 실패하면 FastAPI가 자동으로 422 Unprocessable Entity 에러를 클라이언트에 반환
from fastapi import FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
# Pydantic 모델 정의
class Movie(BaseModel):
id: int | None = Field(default=None, description="영화 ID")
title: str = Field(min_length=1, description="영화 제목")
director: str = Field(min_length=1, description="감독 이름")
rating: float | None = Field(default=None, ge=0, le=10, description="평점 (0~10)")
# Pydantic 모델을 타입 힌트로 사용
@app.post("/movies/")
def create_movie(movie: Movie):
# movie 객체는 이미 유효성 검사가 완료된 상태
return movie4. 모델 서빙
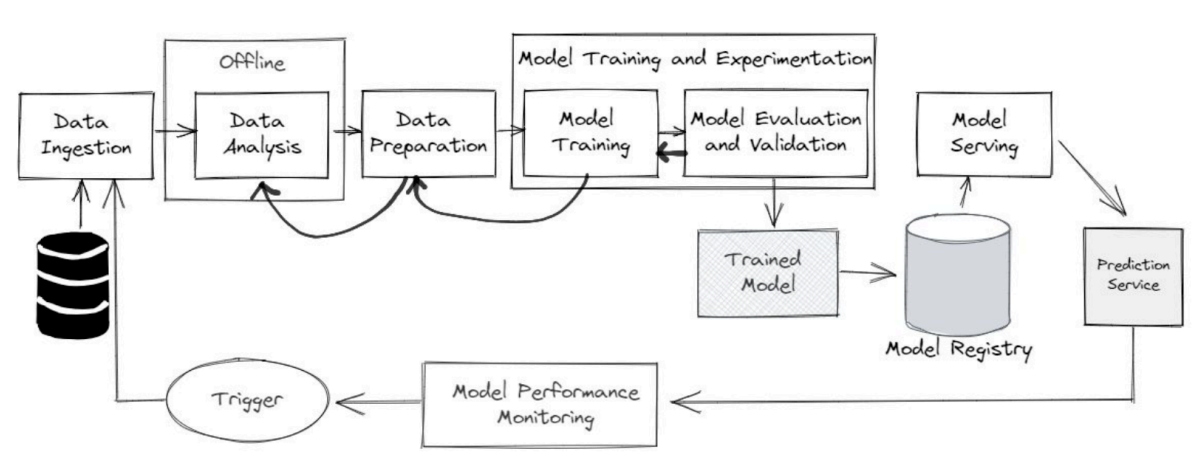
(1) 머신러닝 라이프사이클
A. 전체 흐름
- 데이터 수집(Ingestion)부터 모델 배포 및 모니터링까지 이어지는 전체 과정
- 일반적인 단계
- 데이터 수집 (Data Ingestion)
- 데이터 분석 (Data Analysis)
- 데이터 준비 (Data Preparation)
- 모델 학습 (Model Training)
- 모델 평가 및 검증 (Model Evaluation and Validation)
- 학습된 모델 저장 (Trained Model)
- 모델 레지스트리 (Model Registry)
- 모델 서빙 (Model Serving)
- 예측 서비스 (Prediction Service)
- 모델 성능 모니터링 (Model Performance Monitoring)
- 재학습 트리거 (Trigger)
(2) 모델 서빙의 종류
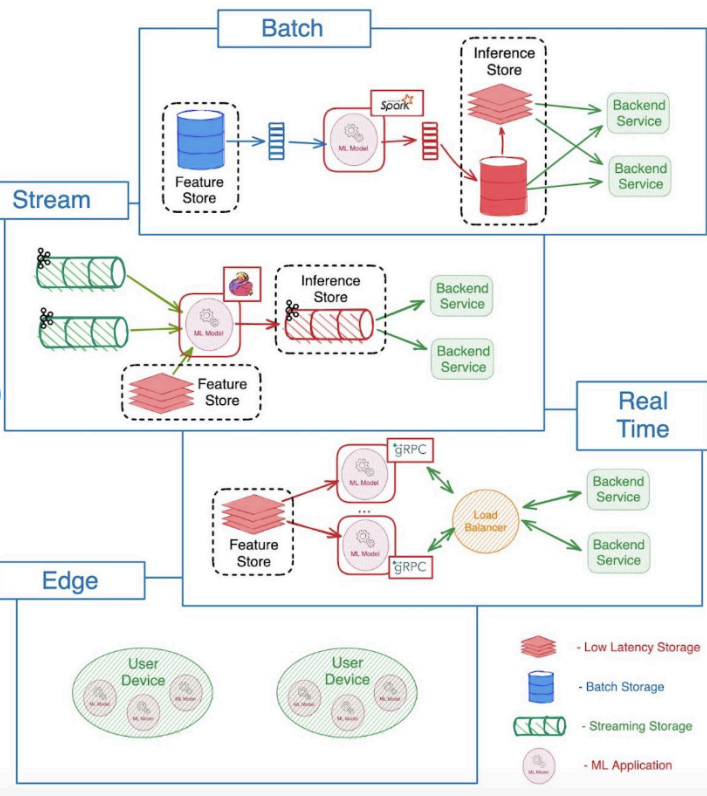
A. 서빙 방식 비교
- 배치 서빙(Batch Serving): 대량의 데이터를 주기적으로 한 번에 처리하는 방식
- (예: 일일 보고서나 월간 분석)
- 스트림 서빙(Stream Serving): 데이터가 들어오는 대로 실시간으로 처리 및 분석하는 방식
- (예: 소셜 분석)
- 실시간 서빙(Real-time Serving): 사용자 요청에 즉각적으로 예측 결과를 반환하는 방식
- (예: 추천 시스템)
- 엣지 서빙(Edge Serving): 사용자의 로컬 장치에서 모델을 직접 실행하여 지연 시간을 최소화하는 방식
- (예: IoT)
| 서빙 종류 | 처리 단위 | 응답 시간 | 주요 사용처 |
|---|---|---|---|
| 배치 (Batch) | 대용량 데이터 묶음 | 수 분 ~ 수 시간 | 일일 보고서, 월간 분석 |
| 스트림 (Stream) | 데이터 스트림 | 수 초 ~ 수 분 | 실시간 대시보드, 이상 탐지 |
| 실시간 (Real-time) | 단일 요청 | 수 밀리초 | 추천 시스템, 자율 주행 |
| 엣지 (Edge) | 단일 요청 (기기 내) | 매우 빠름 | IoT 기기, 모바일 AI 기능 |
5. 클라우드 배포
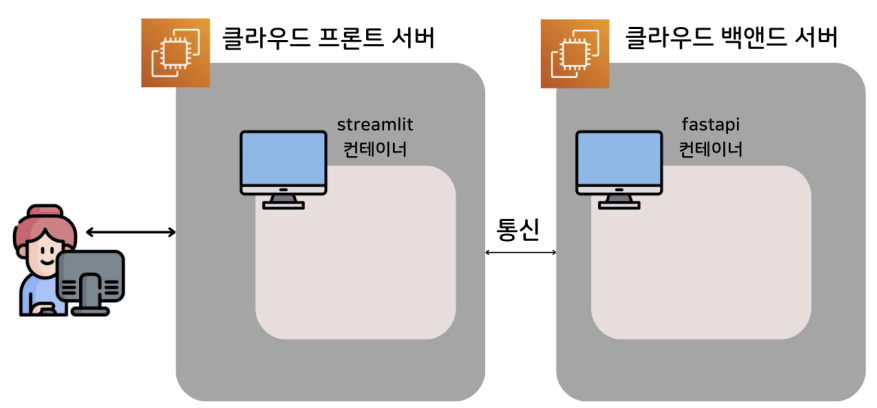
(1) 배포 아키텍처
A. 로컬 환경
- Docker를 사용하여 프론트엔드(Streamlit 등)와 백엔드(FastAPI)를 각각의 컨테이너로 빌드
- Docker Compose를 사용하여 두 컨테이너를 한 번에 실행하고 관리
- 컨테이너 간 통신은 Docker 네트워크를 통해 이루어짐
- (예:
http://fastapi-backend:8000)
- (예:
B. 클라우드 환경
- 일반적으로 프론트엔드 서버와 백엔드 서버를 물리적으로 분리하여 관리
- 사용자는 프론트엔드 서버와 통신하고, 프론트엔드 서버가 필요에 따라 백엔드 서버에 API를 요청하는 구조
- 학습된 AI 모델이나 대용량 데이터는 별도의 스토리지(GCS, S3 등)에 저장하고, 백엔드 서버가 이를 불러와 사용
- 이런 구조는 각 서버의 독립적인 확장(scale-out)을 용이하게 하고 안정성을 높임

AI Engineer