혼자서 프론트엔드, 백엔드, 데이터베이스, 모델까지 전부 다 하려니 머리가 핑핑 돈다. 정말 산 넘어 산이구나 ㅠㅠ
학습시간 09:00~03:00(당일18H/누적2060H)
◆ 학습내용
영화 리뷰 AI 분석 웹앱 구현하기!!
어제에 이어 3번 부터 진행
3. 백엔드(메인화면)
일단 데이터베이스 셋팅부터 해줘야 한다.
강의 때는 pydantic basemodel을 통해 타입을 설정해 줬는데, 요즘 fastapi에서는 SQLModel을 더 많이 사용한다고 한다. 중복 작업을 간소화 해준다는데!
from typing import Optional
from sqlmodel import Field, SQLModel
from datetime import datetime, date
# 영화 데이터를 생성할 때 사용하는 모델
class MovieCreate(SQLModel):
title: str
release_date: date
director: str
genre: str
poster_url: str
# 데이터베이스 테이블과 연결하는 모델
# MovieCreate를 상속, id처럼 DB에서 관리되는 필드를 추가함
class Movie(MovieCreate, table=True):
id: Optional[int] = Field(default=None, primary_key=True)메인 화면에 필요한 DB 코드다.
# 리뷰 데이터를 생성할 때 사용하는 모델
class ReviewCreate(SQLModel):
author: str
review_text: str
# 데이터베이스 테이블과 직접 연결되는 리뷰 모델
# ReviewCreate를 상속, 서버에서 생성/관리하는 필드들을 추가함
class Review(ReviewCreate, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
# 어떤 영화에 달린 리뷰인지 알려주는 외부 키(foreign key)
movie_id: int = Field(foreign_key="movie.id")
# 감성 분석 모델이 계산한 점수
sentiment_score: float리뷰 화면에 필요한 DB 코드다.
from models import Movie, MovieCreate, Review, ReviewCreate
# 사용할 데이터베이스 파일 주소 설정
DATABASE_URL = "sqlite:///database.db"
# 데이터베이스와 연결하는 엔진 생성
engine = create_engine(DATABASE_URL, echo=True)
# 데이터베이스와 테이블을 생성하는 함수
def create_db_and_tables():
# models.py에 정의된 모든 테이블을 데이터베이스에 생성
SQLModel.metadata.create_all(engine)
# 감성 분석 파이프라인
sentiment_pipeline = pipeline(
"sentiment-analysis",
model="tabularisai/multilingual-sentiment-analysis",
)이제 FastAPI로 백엔드를 만들어 보자!
sqlite 포맷으로 하고 database.db 파일을 사용한다.
아까 만들었던 검증용 DB 코드를 models.py에 저장 후 import 했다.
리뷰를 분석할 AI 모델도 transformers pipeline을 이용해 만들었다.
# FastAPI 앱이 시작될 때와 종료될 때 실행할 로직
@asynccontextmanager
async def lifespan(app: FastAPI):
# 앱이 시작될 때 데이터베이스와 테이블을 생성
create_db_and_tables()
yield
# 앱이 종료될 때 실행할 코드가 있다면 여기에 추가
# lifespan을 사용하는 FastAPI 앱 인스턴스 생성
app = FastAPI(lifespan=lifespan)
# API가 호출될 때마다 데이터베이스 세션을 생성하고 끝나면 닫아주는 함수
def get_session():
with Session(engine) as session:
yield session서버를 실행하면 데이터베이스를 가져와 동기화 한다. 비동기 lifespan에 contextmanger 데코레이터를 달아주는 게 핵심이다.
# 새 영화를 생성하는 API
@app.post("/movies/", response_model=Movie)
def create_movie(movie: MovieCreate, session: Session = Depends(get_session)):
# 입력받은 MovieCreate 모델을 DB에 저장할 Movie 모델로 변환
db_movie = Movie.model_validate(movie)
# 세션에 영화 객체 추가
session.add(db_movie)
# 변경사항을 데이터베이스에 커밋(저장)
session.commit()
# 저장된 객체의 최신 상태를 세션에 반영 (예: 자동 생성된 id)
session.refresh(db_movie)
return db_movieCRUD 방식으로 API를 설계해 준다. 먼저 C 코드다.
# 모든 영화 목록을 조회하는 API
@app.get("/movies/", response_model=List[Movie])
def read_movies(session: Session = Depends(get_session)):
# Movie 테이블의 모든 데이터를 조회
movies = session.exec(select(Movie)).all()
return movies다음은 R 코드다. 이게 있어야 메인 화면에 저장된 DB를 보여줄 수 있다.
# 특정 영화 정보를 수정하는 API
@app.patch("/movies/{movie_id}", response_model=Movie)
def update_movie(movie_id: int, movie_update: MovieUpdate, session: Session = Depends(get_session)):
# DB에서 수정할 영화 데이터를 가져옴
db_movie = session.get(Movie, movie_id)
if not db_movie:
raise HTTPException(status_code=404, detail="Movie not found")
# MovieUpdate 모델에서 사용자가 보낸 데이터만 사전(dict) 형태로 가져옴
# (보내지 않은 필드는 None이라서 제외됨)
update_data = movie_update.model_dump(exclude_unset=True)
# 사용자가 보낸 필드들만 값을 업데이트함
for key, value in update_data.items():
setattr(db_movie, key, value)
# 변경사항을 DB에 저장
session.add(db_movie)
session.commit()
session.refresh(db_movie)
return db_movie다음은 U 코드다. put 대신 patch 사용했다.
근데 생각해 보니까 웹이랑 DB 쪽에서 U를 연결받을 수 있는 접점이 없다. 이것부터 만들어야 겠군 ㅠㅠ
class MovieUpdate(SQLModel):
title: Optional[str] = None
release_date: Optional[date] = None
director: Optional[str] = None
genre: Optional[str] = None
poster_url: Optional[HttpUrl] = NoneDB models 파일에 U를 받을 코드를 추가했다. 모든 부분을 옵셔널로 해서 하나만 수정해도 통신이 되도록 했다.
# 특정 영화를 삭제하는 API
@app.delete("/movies/{movie_id}")
def delete_movie(movie_id: int, session: Session = Depends(get_session)):
# id로 삭제할 영화를 찾음
movie = session.get(Movie, movie_id)
if not movie:
# 영화가 없으면 404 에러 발생
raise HTTPException(status_code=404, detail="Movie not found")
# 해당 영화에 달린 모든 리뷰를 찾아서 삭제
reviews_to_delete = session.exec(select(Review).where(Review.movie_id == movie_id)).all()
for review in reviews_to_delete:
session.delete(review)
# 영화를 삭제
session.delete(movie)
session.commit()
return {"ok": True}다음은 D 코드다. 이건 삭제 시에 달렸던 모든 리뷰까지 삭제되어야 하기에 조금 까다롭다.
def get_movies():
try:
res = requests.get(f"{BACKEND_URL}/movies/")
if res.status_code == 200:
return res.json()
else:
st.error(f"영화 목록 로딩 실패: {res.status_code}")
return []
except requests.ConnectionError:
st.error("서버에 연결할 수 없습니다.")
return []
def add_movie(title, release_date, director, genre, poster_url):
movie_data = {
"title": title,
"release_date": str(release_date),
"director": director,
"genre": genre,
"poster_url": poster_url
}
try:
res = requests.post(f"{BACKEND_URL}/movies/", json=movie_data)
return res
except requests.ConnectionError:
return None지금까지 만든 API를 프론트엔드에서 받을 수 있도록 API 받는 함수를 추가했다.
그리고 streamlit session에서 데이터를 가져오던 부분을 DB에서 가져올 수 있도록 코드를 전반적으로 수정했다.
4. 테스트(메인화면)
여기까지 한번 테스트해보자!
streamlit run frontend.py
uvicorn backend:app --reload실행!
이런 창이 나왔다. 서버에 연결할 수 없다는 문구가 안 뜬 것을 보면 잘 연결되었다는 뜻이겠지...?
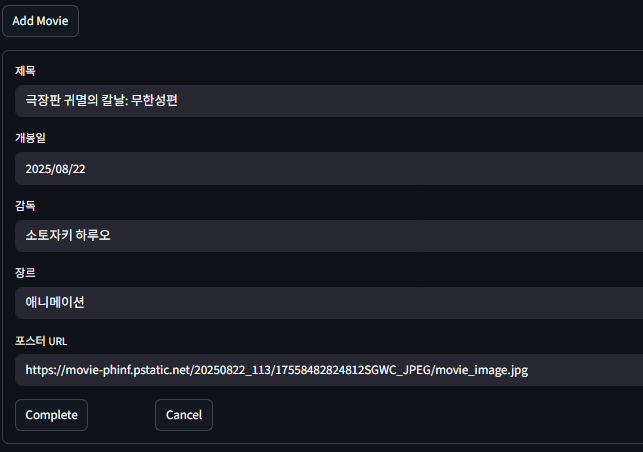
DB에 넣을 영화를 하나 만들어 보자.
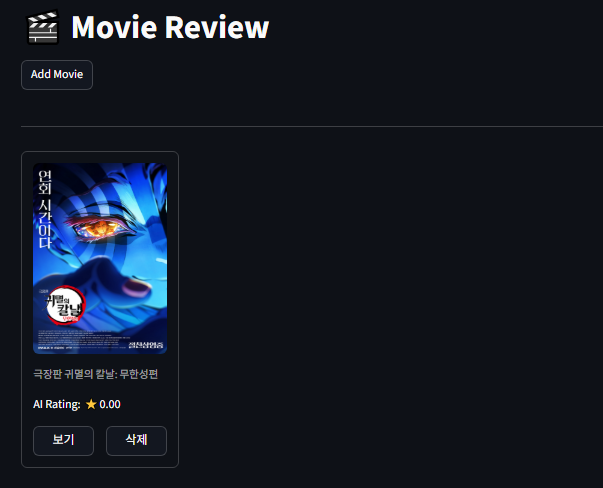
오 잘 들어간다.
이렇게 막 적으면 어떻게 될까? SQLModel 문법에 걸려서 문제가 생기려나?
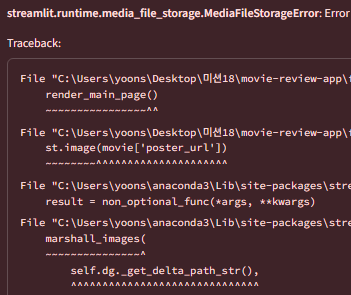
역시나 에러가 떴다. 읽어보니 poster url 쪽에 문제가 있는 것 같다.
어라 근데 새로고침을 해도 에러창이 그대로 떠있다.
아무리 봐도 에러를 끄는 법이 없네. 어쩌면 좋지..?
from pydantic import HttpUrl
# 영화 데이터 생성 모델
class MovieCreate(SQLModel):
title: str
release_date: date
director: str
genre: str
poster_url: HttpUrl
결국 서버를 종료했다. 코드를 고쳐야할 것 같다.
pydantic에서 지원하는 HttpUrl을 임포트해서 형식을 맞춰 보자.
서버를 다시 켰는데 아까 만들었던 귀멸의 칼날 영화가 안 보인다. 뭐지..!?
일단 테스트부터 다시 만들어 보자.
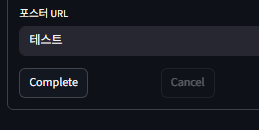
엥??? 갑자기 Cancel 버튼이 막히면서 아무것도 바뀌지 않는다.
아마도 DB로 데이터가 들어가는 건 막혔지만 프론트엔드 쪽에서 인터랙션을 해주지 못해서인 것 같다.
영화 등록 형식을 재확인 하라는 에러가 뜨도록 해야할 것 같다.
error_placeholder = st.empty()
col1, col2 = st.columns([1, 5])
with col1:
if st.form_submit_button("Complete"):
res = add_movie(title, release_date, director, genre, poster_url)
# 응답 코드에 따라 다르게 처리
if res and res.status_code == 200:
st.toast("추가 성공")
st.session_state.show_add_movie_form = False
st.rerun() # 성공했을 때만 폼을 닫고 새로고침
elif res and res.status_code == 422:
# 422 에러는 백엔드에서 데이터 유효성 검사에 실패했다는 뜻
error_placeholder.error("입력 양식을 다시 확인해 주세요.")
else:
error_placeholder.error("추가 실패")프론트엔드 코드를 일부 수정했다. 영화를 생성할 때 응답 코드에 따라 메시지를 분기하도록 했다.
헉 근데,,,,,,
ValueError: <class 'pydantic.networks.HttpUrl'> has no matching SQLAlchemy type
터미널 창에서 에러가 떴다.
SQLAlchemy 타입이 아니라고 한다.
???????? 무슨 소리지
class Movie(MovieCreate, table=True):
id: Optional[int] = Field(default=None, primary_key=True)한참 찾아보니 이 코드가 문제였다고 한다.
왜 문제가 됐는지 정리를 좀 해보자.
-
models.py에서 Movie 모델이 MovieCreate를 상속받았기 때문에, poster_url: HttpUrl이라는 속성도 그대로 물려받았다.
-
backend.py의 table=True 옵션은 SQLModel에게 Movie 모델을 보고 데이터베이스에 테이블을 만들라는 명령을 내린다.
-
명령을 받은 SQLModel은 poster_url: HttpUrl 속성을 보고, HttpUrl 타입으로 열 생성을 시도한다.
-
하지만 데이터베이스(SQLAlchemy)는 HttpUrl이라는 타입을 모른다. -> 그래서 ValueError에러가 뜨는 것이다.
흠 ㅇㅅㅇ;;;;;
아무래도 models.py 코드를 싹 갈아엎어야할 것 같은 느낌이다.
class MovieBase(SQLModel):
title: str
release_date: date
director: str
genre: str
poster_url: str
class MovieCreate(MovieBase):
poster_url: HttpUrl
class MovieUpdate(SQLModel):
title: Optional[str] = None
release_date: Optional[date] = None
director: Optional[str] = None
genre: Optional[str] = None
poster_url: Optional[HttpUrl] = NoneMovieBase 라는 클래스를 새로 만들었다.
기존 HttpUrl 타입을 받던 poster_url 인자는 MovieCreate 클래스를 새로 만들어서 넣었다.
다시 서버를 열고 테스트 해보자.
제발..!
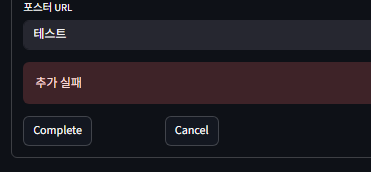
오! 의도한대로 실패했다는 에러가 떴다.
이제 데이터를 다시 넣어보자.
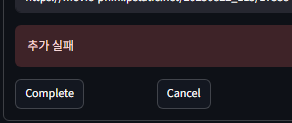
?????????????????????
이제 제대로 넣어도 데이터가 안 들어가진다.
미치겠군.....
으아아ㅏㅏㅏㅏ
ㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏ
두 시간 동안 붙잡고 있다가 멘탈이 터졌는데,,,
....결국 원인을 찾아냈다!!
문제는 이거였다.
- MovieCreate는 HttpUrl 타입을 받음
- MovieBase는 str 타입을 받음
- HttpUrl에서 str 타입으로 똑바로 변환되지 않음
- MovieBase가 들어오는 입력값을 이해할 수 없음
- MovieBase: 응 터질게~~ 펑~!!!
@app.post("/movies/", response_model=Movie)
def create_movie(movie: MovieCreate, session: Session = Depends(get_session)):
# 입력받은 MovieCreate 모델을 DB에 저장할 Movie 모델로 변환
movie_data = movie.model_dump(mode='json')
# DB 모델 Movie가 이해할 수 있는 딕셔너리로 변환
db_movie = Movie.model_validate(movie_data)
# 세션에 영화 객체 추가
session.add(db_movie)
# 변경사항을 데이터베이스에 커밋(저장)
session.commit()
# 저장된 객체의 최신 상태를 세션에 반영 (예: 자동 생성된 id)
session.refresh(db_movie)
return db_moviemodel_dump 함수를 이용해서 입력을 json 타입으로 변경했다.
이렇게 하면 str 타입으로 강제 변환되어서 들어간다고 한다.
다시 해보자!
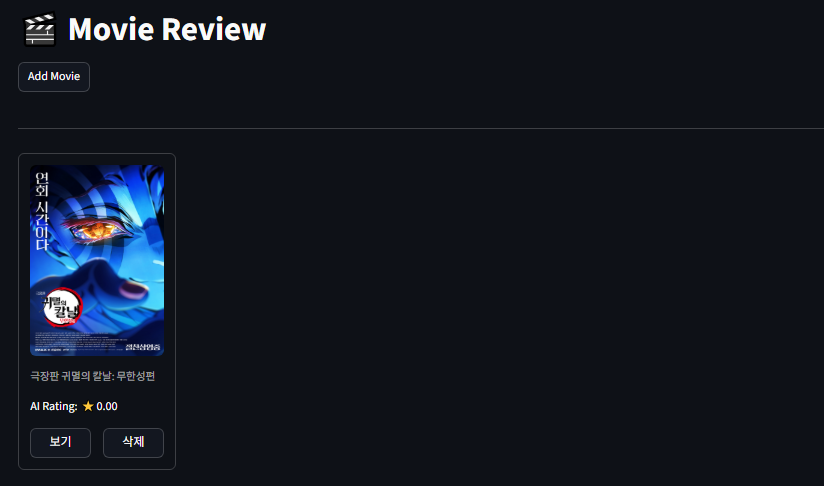
짜잔!
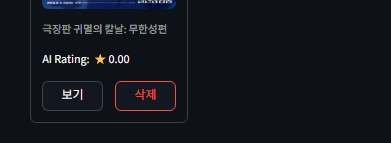
삭제도 잘 될까?
잘 된다!
다시 데이터 생성 후 서버를 재부팅 해도 추가한 데이터가 그대로 남아 있을까?
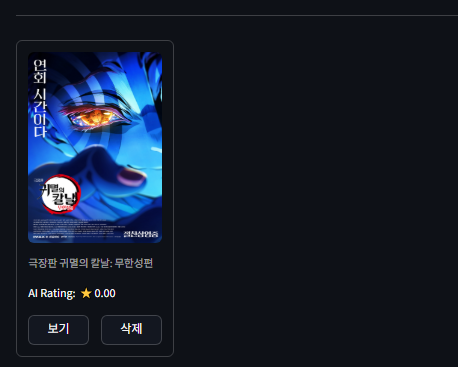
서버를 재부팅해도 남아있다! DB에서 데이터를 잘 가져온다는 뜻이다!!
다른 영화도 몇 개 더 추가해 볼까?
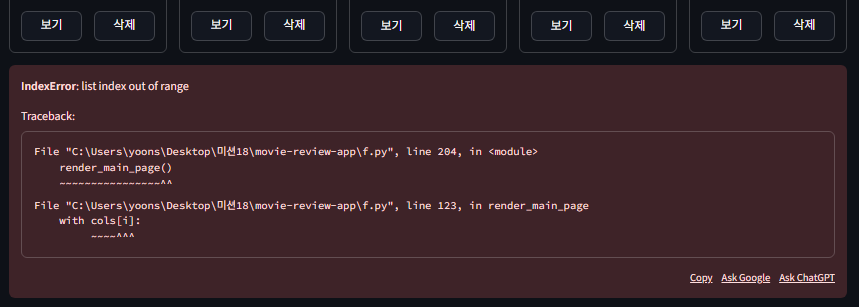
헉 6번 째 영화를 등록하려 했더니 에러가 떴다.
아무래도 행열을 나누는 코드를 잘못 짠 것 같은데,,,
오늘 에러를 너무 많이 봐서 머리가 아프다.
st.divider()
movies = get_movies()
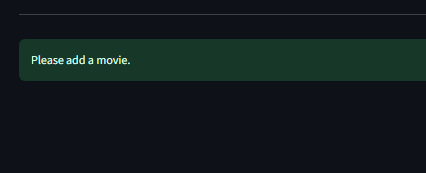
if not movies:
st.success("Please add a movie.")
else:
num_movies = len(movies)
num_cols = 5
cols = st.columns(num_cols)
for i in range(num_movies):
movie = movies[i]
col_index = i % num_cols
with cols[col_index]: # i 대신 col_index 사용기존 with cols[i] 였던 부분을 수정했다.
i를 num_cols의 값만큼 나눈 후에 이걸 기준으로 하도록 했다.
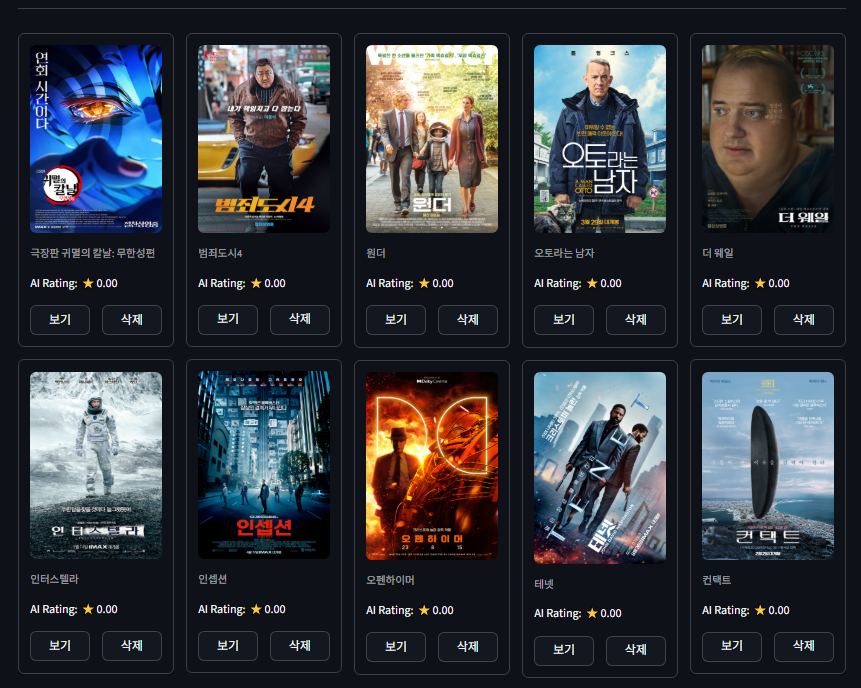
그 다음 행도 제대로 나온다.
생각나는 영화를 쭉 찾아봤는데,, 내 영화 취향이 이랬었구만 ㅋㅋㅋㅋ
후 일단 오늘은 여기까지 하자 ㅠㅠ 내일은 리뷰 페이지를 살펴봐야지... 피곤쓰...
