메모리 분할
메모리 분할은 하나의 프로그램을 여러 개의 구역으로 나누어 메모리에 적재하는 방식입니다.
메모리 분할의 장점
-
메모리 공간의 효율적인 활용
프로그램의 일부분만 메모리에 적재하므로, 메모리의 낭비를 줄일 수 있습니다. -
프로그램의 보호
각 구역에 접근 권한을 설정하여, 다른 구역이나 운영체제에 의한 오류나 침범을 방지할 수 있습니다. -
프로그램의 공유
여러 프로세스가 같은 프로그램의 구역을 공유하여, 메모리 사용량을 줄일 수 있습니다.
메모리 분할의 종류
정적 분할
프로그램이 실행되기 전에 구역의 크기와 위치가 결정되는 방식입니다.
정적 분할은 구현이 간단하고 오버헤드가 적지만, 내부 단편화와 외부 단편화 문제가 발생할 수 있습니다.
동적 분할
프로그램이 실행되는 동안에 구역의 크기와 위치가 결정되는 방식입니다.
동적 분할은 내부 단편화 문제를 해결하고, 메모리 공간을 유연하게 할당할 수 있지만, 구현이 복잡하고 오버헤드가 크며, 외부 단편화 문제가 여전히 남아있습니다.
외부 단편화와 내부 단편화
단편화란?
외부 단편화와 내부 단편화는 메모리 관리에서 발생하는 문제입니다. 메모리는 프로세스에게 할당되고, 프로세스는 메모리를 사용합니다. 하지만 프로세스의 크기와 메모리의 크기가 정확히 일치하지 않을 수 있습니다. 이때, 메모리의 일부 공간이 낭비되는 현상이 발생합니다.
이를 단편화라고 합니다.
외부 단편화
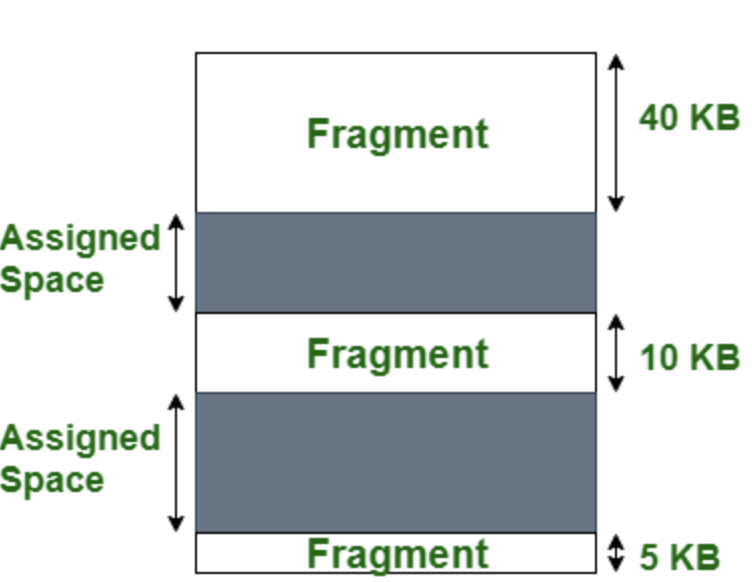
외부 단편화는 메모리의 가용 공간이 충분하지만, 연속적인 공간이 부족하여 프로세스가 메모리에 적재되지 못하는 현상입니다.
예를 들어, 10MB의 메모리가 있고, 2MB, 3MB, 4MB의 프로세스가 각각 메모리에 적재되었다고 가정해봅시다. 이때, 1MB의 가용 공간이 남아있지만, 5MB의 프로세스는 연속적인 5MB의 공간이 없으므로 메모리에 적재할 수 없습니다.
이러한 외부 단편화를 해결하기 위한 방법으로는 압축(compaction)과 페이징(paging)이 있습니다.
- 압축은 메모리에 적재된 프로세스들을 한쪽으로 몰아서 연속적인 가용 공간을 만드는 방법입니다.
- 페이징은 메모리를 일정한 크기의 블록으로 나누고, 프로세스도 같은 크기의 블록으로 나누어서 메모리에 적재하는 방법입니다.
내부 단편화
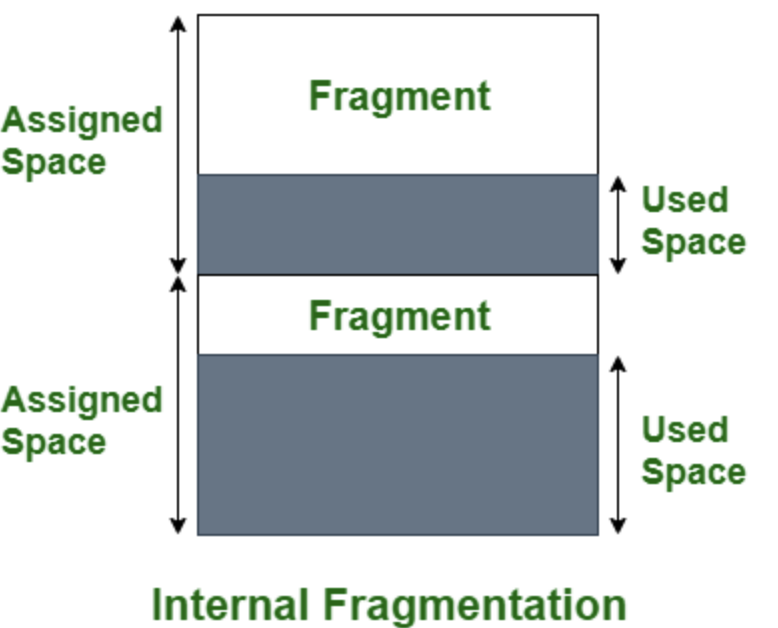
내부 단편화는 프로세스가 할당받은 메모리보다 작은 크기를 사용하여, 할당받은 메모리 내부에 낭비되는 공간이 생기는 현상입니다.
예를 들어, 페이징을 사용할 때, 4KB의 페이지 크기로 메모리를 나누었다고 가정해봅시다. 이때, 9KB의 프로세스는 3개의 페이지(12KB)를 할당받게 됩니다. 그러나 프로세스는 9KB만 사용하므로, 마지막 페이지에서 3KB가 낭비됩니다.
이러한 내부 단편화를 해결하기 위한 방법으로는 세그멘테이션(segmentation)이 있습니다.
- 세그멘테이션은 프로세스를 의미있는 단위인 세그먼트로 나누고, 세그먼트마다 다른 크기의 메모리를 할당하는 방법입니다.
외부 단편화와 내부 단편화의 차이
외부 단편화와 내부 단편화의 차이점을 요약하면 다음과 같습니다.
-
외부 단편화는 가용 공간은 충분하지만 연속적인 공간이 부족하여 발생하는 현상이고, 내부 단편화는 할당받은 공간보다 작은 공간을 사용하여 발생하는 현상입니다.
-
외부 단편화를 해결하기 위한 방법으로는 압축과 페이징이 있고, 내부 단편화를 해결하기 위한 방법으로는 세그멘테이션이 있습니다.
메모리 배치 기법
메모리 배치 기법이란, 프로그램이 실행되기 위해 메모리에 적재되는 방식을 말합니다.
메모리 배치 기법은 메모리의 효율성과 성능에 영향을 미치므로, 적절한 전략을 선택하는 것이 중요합니다.
연속 배치 기법
이 기법은 프로그램을 메모리의 연속된 공간에 적재하는 방식입니다.
연속 배치 기법은 구현이 간단하고 주소 변환도 쉽습니다.
하지만, 메모리의 공간 낭비가 심하고 외부 단편화 문제가 발생할 수 있습니다.
외부 단편화란, 메모리의 사용 가능한 공간이 작은 조각들로 나뉘어져서 프로그램을 적재할 수 없는 현상을 말합니다.
Colaescing(통합) 배치 기법
Colaescing(통합)은 메모리 배치 기법 중 하나로, 메모리 공간이 단편화되어 작은 조각들로 나뉘어져 있을 때, 인접한 빈 공간들을 합쳐서 큰 공간으로 만드는 방법입니다.
이렇게 하면 메모리 공간의 활용도를 높일 수 있습니다.
예를 들어, 다음과 같은 메모리 공간이 있다고 가정해봅시다.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| A | B | C | D |
여기서 2번, 4번, 5번, 7번 공간은 빈 공간입니다. 만약 새로운 데이터 E가 들어오려고 하는데, E의 크기가 3이라면 어느 공간에도 배치할 수 없습니다.
그러나 Colaescing(통합)을 사용하면 인접한 빈 공간들을 합쳐서 다음과 같이 바꿀 수 있습니다.
| 0 | 1 | 2-3 | 4-7 |
|---|---|---|---|
| A | B | C |
이제 E는 4-7번 공간에 배치할 수 있게 됩니다.
Colaescing(통합)은 메모리 단편화를 줄이고 메모리 활용도를 높이는 효과가 있지만, 인접한 빈 공간들을 찾아서 합치는 작업에 시간이 걸릴 수 있다는 단점도 있습니다. 따라서 Colaescing(통합)을 적절하게 사용하는 것이 중요합니다.
Compaction(압축)
Compaction(압축)은 연속 분할 할당에서 자주 사용하는 단편화(fragmentation) 문제를 해결하기 위한 방법입니다.
Compaction(압축)은 메모리의 사용 가능한 공간들을 한쪽 끝으로 몰아서 큰 하나의 빈 공간을 만드는 작업입니다.
이렇게 하면 프로세스가 들어갈 수 있는 충분한 공간이 확보되고, 메모리의 이용률이 향상됩니다.
하지만 Compaction(압축)은 프로세스들의 위치를 변경해야 하므로 많은 시간이 소요될 수 있습니다.
버디 시스템
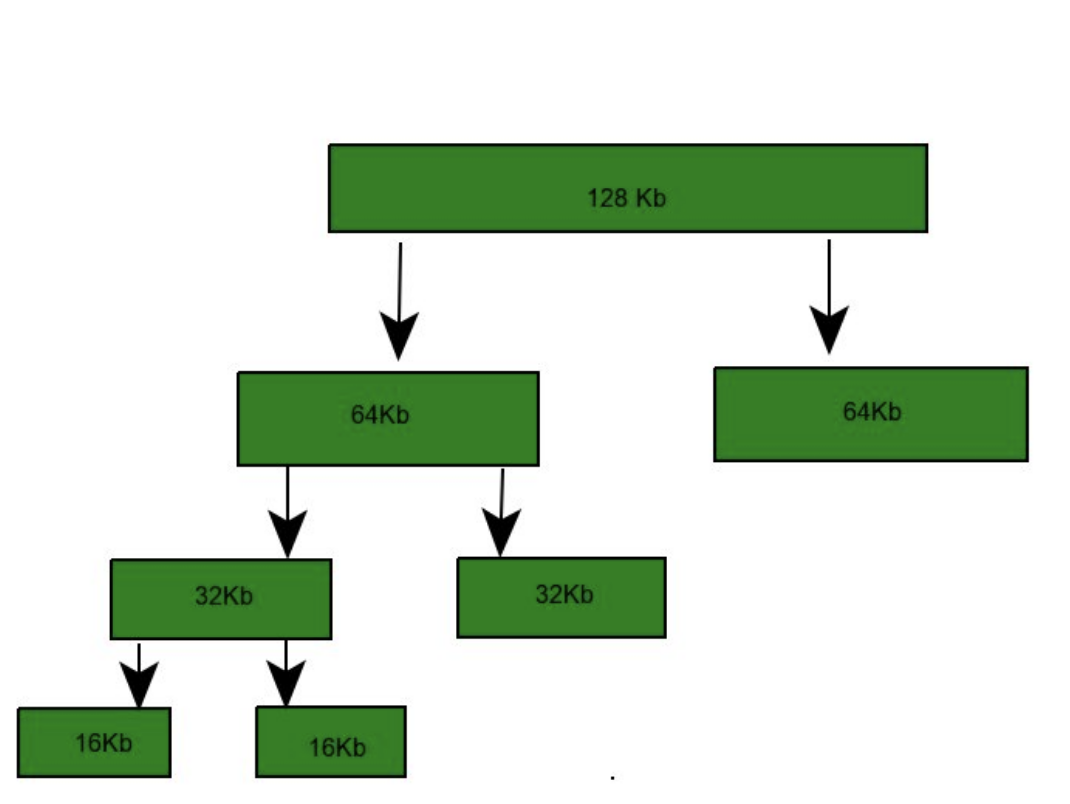
버디 시스템이란 메모리 배치 기법 중 하나로, 고정 분할과 동적 분할의 장점을 결합한 방법입니다.
버디 시스템에서는 메모리 블록의 크기가 2의 거듭제곱인 2^k로 제한되어 있으며, L ≤ k ≤ U의 범위에서만 할당이 가능합니다.
예를 들어, L = 2, U = 5라면, 할당 가능한 블록의 크기는 4, 8, 16, 32바이트입니다.
버디 시스템은 메모리 요구량에 따라 블록을 분할하거나 병합하는 과정을 반복합니다.
예를 들어, 프로세스 A가 12바이트를 요구하면, 가장 작은 크기인 4바이트 블록부터 시작하여 이웃한 블록과 합쳐서 8바이트 블록을 만들고, 다시 이웃한 블록과 합쳐서 16바이트 블록을 만듭니다. 그리고 이 중 12바이트만 A에게 할당하고 남은 4바이트는 재사용을 위해 남겨둡니다. 이때, 이웃한 블록과 합치거나 분할할 수 있는 블록을 버디(buddy)라고 부릅니다.
버디 시스템의 장점은 다음과 같습니다.
-
메모리 단편화를 줄일 수 있습니다.
동적 분할 방식에서는 메모리 공간이 작은 조각들로 나뉘어져서 사용하지 못하는 경우가 많았습니다. 하지만 버디 시스템에서는 사용하지 않는 블록들을 병합하여 큰 블록으로 만들 수 있으므로 공간 낭비를 줄일 수 있습니다. -
메모리 할당과 해제가 빠릅니다.
고정 분할 방식에서는 적절한 크기의 파티션을 찾기 위해 모든 파티션을 탐색해야 했습니다. 하지만 버디 시스템에서는 트리 구조를 이용하여 적절한 크기의 블록을 찾을 수 있으므로 탐색 시간을 줄일 수 있습니다. -
메모리 관리가 간단합니다.
동적 분할 방식에서는 메모리에 존재하는 모든 블록의 시작 주소와 크기를 기억해야 했습니다. 하지만 버디 시스템에서는 각 레벨별로 비어있는 블록의 목록만 유지하면 되므로 관리가 간단합니다.
세그멘테이션 배치 기법
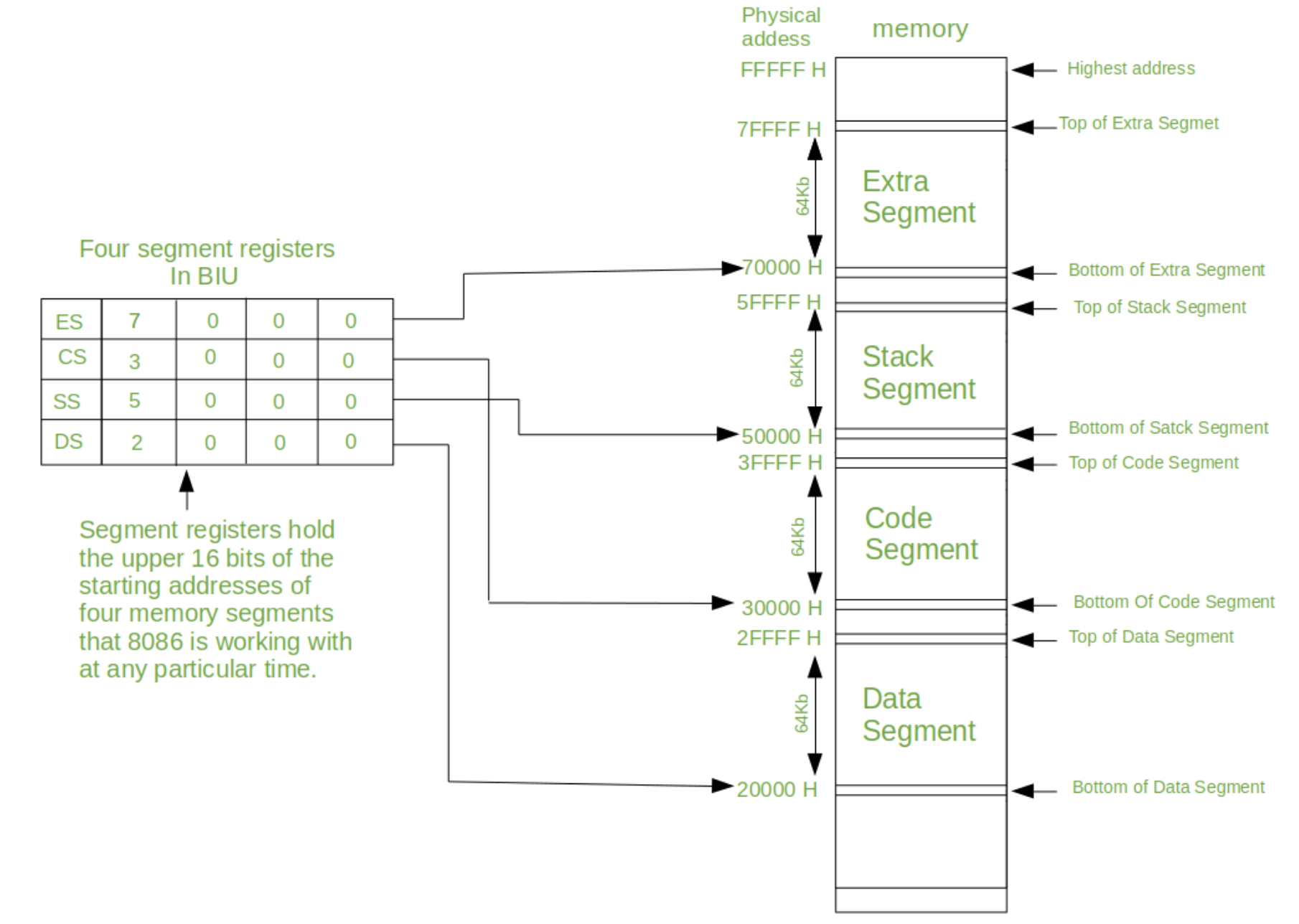
세그멘테이션 기법은 가상 메모리를 서로 크기가 다른 논리적 단위인 세그먼트(Segment)로 분할하고 메모리를 할당하는 기법입니다.
세그먼트는 프로그램의 배열, 함수, 객체 등과 같은 논리적인 구성 요소로 나누어지며, 각 세그먼트는 고유한 이름과 크기를 갖습니다.
세그멘테이션 기법을 사용하면 프로그램의 논리적인 구조와 메모리의 물리적인 구조를 일치시킬 수 있어서 메모리 공간의 활용도를 높일 수 있습니다. 또한, 세그먼트 단위로 보호와 공유가 가능하여 보안과 효율성을 향상시킬 수 있습니다.
세그멘테이션 기법에서 가상 주소는 세그먼트 번호와 오프셋으로 구성됩니다.
세그먼트 번호는 세그먼트 테이블에서 해당 세그먼트의 시작 주소와 길이를 찾는 데 사용되고, 오프셋은 시작 주소에 더해져서 실제 물리 주소를 계산하는 데 사용됩니다.
세그먼트 테이블은 메모리에 저장되며, 각 프로세스마다 하나씩 할당됩니다. 세그먼트 테이블에는 각 세그먼트의 베이스(base)와 한계(limit) 값이 저장됩니다. 베이스 값은 세그먼트의 시작 주소를 나타내고, 한계 값은 세그먼트의 길이를 나타냅니다.
이렇게 하면 오프셋 값이 한계 값보다 작으면 유효한 주소이고, 크면 잘못된 주소임을 판단할 수 있습니다.
세그멘테이션 기법의 장점은 다음과 같습니다.
- 프로그램의 논리적인 구조와 메모리의 물리적인 구조를 일치시켜서 프로그래밍과 디버깅을 용이하게 합니다.
- 세그먼트 단위로 보호와 공유가 가능하여 보안과 효율성을 향상시킵니다.
- 내부 단편화 문제가 없으며, 외부 단편화 문제도 컴팩션(compaction)을 통해 해결할 수 있습니다.
세그멘테이션 기법의 단점은 다음과 같습니다.
- 세그먼트 테이블의 크기가 커질 수 있으며, 이를 관리하기 위한 오버헤드가 발생할 수 있습니다.
- 외부 단편화 문제가 발생할 수 있으며, 이를 해결하기 위한 컴팩션 작업에 시간이 많이 소요될 수 있습니다.
- 가변 크기의 세그먼트를 할당하고 해제하는 과정에서 메모리 관리가 복잡해질 수 있습니다.
세그멘테이션 기법은 가상 메모리 관리 기법중 하나로, 프로그램을 논리적인 단위로 분할하고 메모리를 할당하는 기법입니다. 이 기법은 메모리 공간의 활용도와 보안성을 높일 수 있지만, 메모리 관리의 복잡도와 오버헤드를 증가시킬 수 있습니다.
페이징 배치 기법
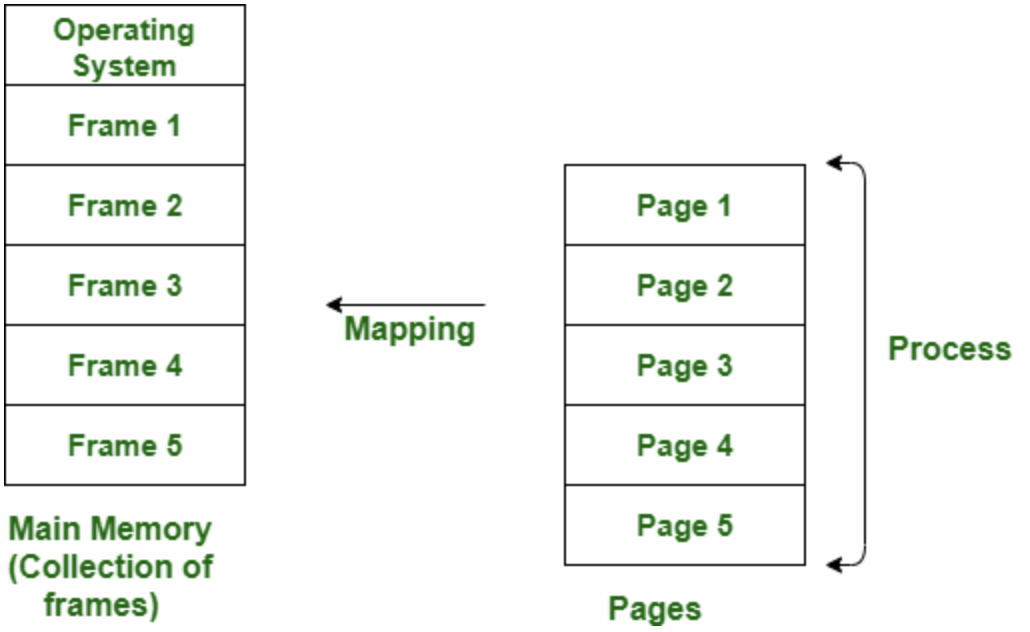
페이징이란 메모리 배치 기법 중 하나로, 가상 메모리를 일정한 크기의 페이지로 나누고, 물리 메모리를 같은 크기의 프레임으로 나누어서, 페이지와 프레임을 일대일로 매핑하는 방식입니다.
페이징을 사용하면 외부 단편화 문제를 해결할 수 있으며, 메모리 접근 속도도 빠릅니다.
페이징은 페이지 테이블이라는 자료구조를 이용하여 가상 주소와 물리 주소를 변환합니다.
페이지 테이블은 각 페이지의 시작 주소와 해당하는 프레임의 번호를 저장하고 있습니다.
또한, 가상 메모리와 잘 호환되어 메모리 관리를 효율적으로 할 수 있습니다.
하지만, 구현이 복잡하고 주소 변환도 어렵습니다. 또한, 페이지 테이블이라는 자료구조를 유지해야 하므로 오버헤드가 발생할 수 있습니다.