
Architecture란?
Architecture는 시스템 또는 소프트웨어의 기본 구조와 설계를 의미합니다. 이는 시스템의 구성 요소, 이들의 상호 작용, 그리고 데이터 흐름을 정의합니다. 머신러닝 아키텍처는 모델이 데이터를 처리하고 학습하는 방식을 결정하며, 이를 통해 최적의 성능과 효율성을 달성할 수 있도록 합니다.
고려사항
-
모듈화: 독립적으로 관리할 수 있는 여러 모듈로 나누어 설계합니다. 각 모듈을 독립적으로 테스트하고 유지보수할 수 있어 확장성과 유연성이 높아집니다.
-
확장성: 시스템이 증가하는 데이터와 사용 요구를 효율적으로 처리할 수 있도록 설계합니다.
-
유연성: 새로운 요구 사항과 기술 변화에 적응할 수 있도록 시스템을 설계합니다. 시스템을 쉽게 업데이트하고 기능을 추가할 수 있습니다.
-
효율성: 자원(예: CPU, 메모리)을 효율적으로 사용하도록 시스템을 설계합니다.
-
데이터 보안: 민감한 데이터를 보호하기 위해 적절한 보안 조치를 포함합니다.
-
재사용성: 코드와 구성 요소를 여러 프로젝트에서 재사용할 수 있도록 설계합니다.
-
테스트 가능성: 시스템의 각 부분을 독립적으로 테스트할 수 있도록 설계합니다.
...
Components
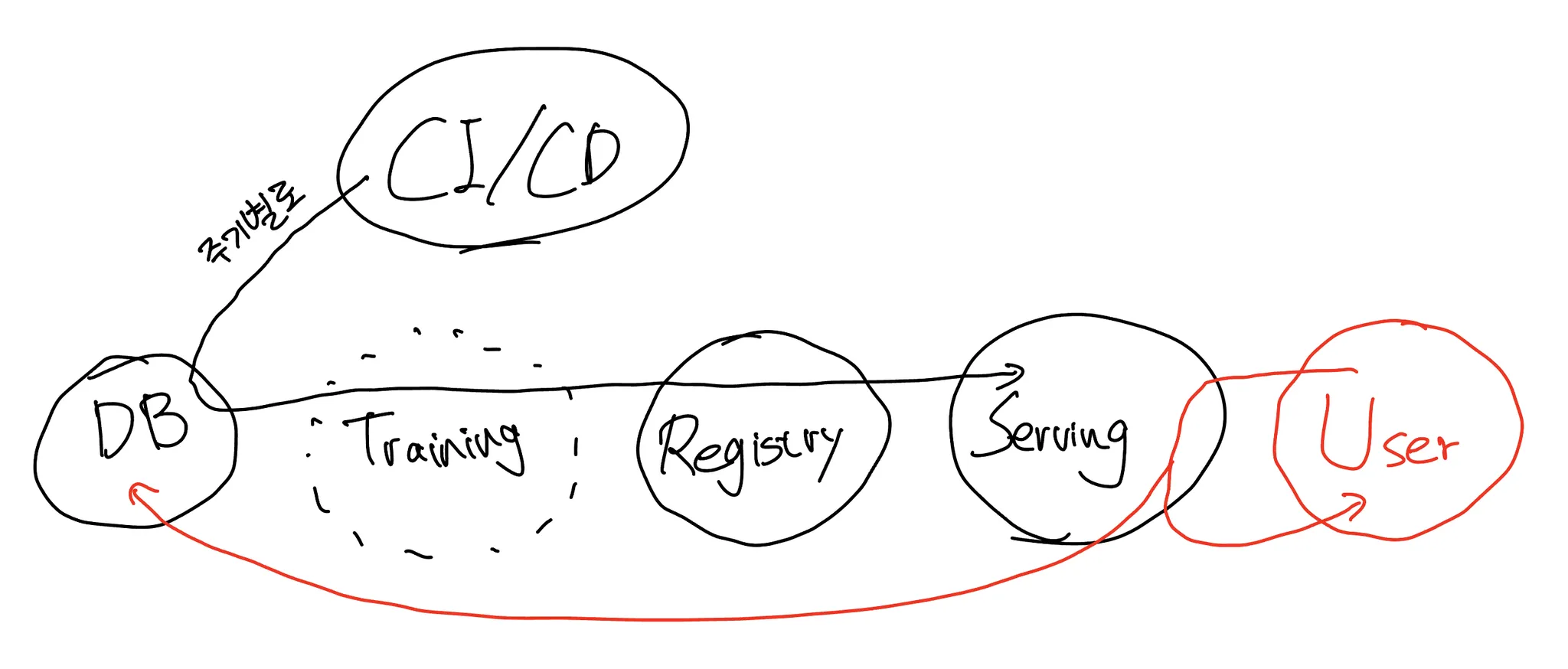
01 DATABASE
1) 고려요소
- 얼마나 큰 data인가?
- 어떤 종류의 data인가? Relational database, Document database, Vector database...
- 사용량이 어떤가? = 얼마나 자주 데이터가 추가/삭제되는가? = 컴퓨터의 성능 결정에 중요
2) 권장사항
1. api 서버 활용: 외부에서 database에 직접 접근하는 것은 위험하다. api를 통해서 접근하는 것이 필요하다
- 보안(db에 접근제한, 권한설정 등)에 용이
- 데이터 추상화에 용이(복잡한 db구조 가리는 역할) = 유연성 제고
- api로 집중관리 및 로깅 모니터링에 용이
2. 읽기 복제본(READ REPLICA) 만들기: 주기적으로 많은 양의 데이터를 트레이닝때 READ 읽어야하는데, 만약 단일 DB 서버만 사용하면 그때마다 과부화가 생김. 이를 방지하기 위해 데이터베이스 읽기 작업을 여러 서버에 분산시키기. 이 읽기 복제본도 API로 연결된다.
3) 추가 고려사항
1. Distributed Database(분산 DB) : 하나의 데이터베이스 관리 시스템(DBMS)이 여러 CPU에 연결된 저장장치들을 제어하는 형태의 데이터베이스.
- 주로 DB에 새로운 아이템을 WIRTE하는 행동이 가장 무거운 작업이다. 그럼으로 자주 데이터가 추가된다면, 그 일을 여러 컴퓨터가 나눠서하게 하는 것이 분산 DB. 이로써 처리성능이 향상된된다.
- 관련된 유료 서비스가 있지만 비쌈, 예산이 있다면 클라우드 서비스 이용가능.
- 분산 가능한 데이터
- 독립적인 데이터: 서로 강하게 연관되지 않은 데이터들 (예를 들어, 사용자 프로파일 정보나 주문 기록처럼 각 레코드가 독립적으로 처리될 수 있는 경우)
- 수평적 분할 가능 데이터: 테이블이나 데이터 세트를 특정 기준으로 쉽게 분할할 수 있는 경우 (예를 들어, 날짜나 지역별로 데이터가 분할될 수 있는 경우입니다. 이를 통해 데이터의 일부분만 특정 서버에서 관리할 수 있습니다.)
- 분산 불가능한 데이터
- 강한 연결 데이터: 데이터 간에 강한 관계나 의존성이 있는 경우, 분산이 어려울 수 있습니다. 예를 들어, 복잡한 트랜잭션 관리가 필요한 은행 시스템의 데이터나, 다수의 조인이 필요한 관계형 데이터베이스
- 실시간 일관성이 요구되는 데이터: 데이터의 실시간 일관성이 매우 중요한 경우, 분산이 어려울 수 있습니다. 예를 들어, 주식 거래 시스템처럼 매우 짧은 시간 내에 일관성이 보장되어야 하는 경우입니다.
- 당장 (훈련용으로) 사용하지 않는 데이터는 파일로 추출해서 다른 하드웨어에 보관하기
02 CI/CD
1) 의미
MLOPS에서 CI/CD란, 1. 주기마다 데이터를 읽어와 통계 모델을 생성하고 2. 이를 (자동으로) 배포까지 하는 컴포넌트이다.
1. Continuous Integration (CI):
<보통 개발환경에서의 CI>
의미: 개발자가 새로운 코드를 주기적으로 통합(Integration)하는 과정을 자동화합니다.
기능: 모든 개발자가 각자의 코드 변경 사항을 주기적으로 중앙 저장소에 통합합니다. 이를 통해 버그를 빠르게 발견하고, 코드 충돌을 줄이며, 품질을 높일 수 있습니다. CI 서버는 코드가 변경될 때마다 자동으로 빌드(build)하고 테스트(test)합니다.
<MLOPS에서의 CI>
의미: 데이터와 모델의 지속적 통합: MLOps에서 CI는 주기적으로 데이터를 수집하고 통합하며, 새로운 데이터를 반영하여 모델을 지속적으로 업데이트하고 개선하는 과정을 의미합니다. 이를 통해 모델이 항상 최신 데이터를 기반으로 작동할 수 있습니다.
기능 :
데이터 통합: 주기적으로 새로운 데이터를 수집하고, 이를 기존 데이터와 결합하여 통합합니다. 데이터의 품질을 검사하고 전처리 과정을 통해 데이터를 준비합니다.
모델 통합: 새로운 데이터에 기반하여 통계 모델을 생성하거나, 기존 모델을 주기적으로 업데이트합니다.모델의 성능을 평가하고, 필요 시 최적화합니다.
모델 검증 및 테스트: 모델의 최신 버전을 검증하고, 테스트를 통해 모델의 성능을 평가합니다.
모델의 정확성과 일관성을 유지하기 위해 다양한 테스트 케이스를 실행합니다.
2. Continuous Deployment (CD):
의미: 코드가 통합된 후 자동으로 배포(Deployment)하는 과정을 말합니다. Continuous Delivery(CD)라고도 하며, 약간의 차이가 있습니다.
기능: 코드가 통합되고 테스트를 통과하면, 자동으로 프로덕션(Production) 환경에 배포합니다. Continuous Delivery의 경우, 자동으로 배포 준비 상태까지 만들고, 실제 배포는 수동으로 할 수도 있습니다. 이를 통해 배포 과정을 단순화하고, 개발자와 운영 팀 간의 협력을 강화하며, 배포 주기를 단축할 수 있습니다.
2) 역할(하는 일 순서대로)
CI/CD가 접근할 수 있는 또다른 컴퓨터를 만들어서 걔가 작업을 하도록 만든다. 주로 젠킨스라는 툴을 쓴다.
1. DB(READ REPLICA)에 접근해서 데이터 불러와서 저장
-
모델 학습 코드가 포함된 git repository를 clone해오오기
-
모델 훈련 및 결과로 나온 모델 파일 저장
-
저장된 모델 파일을 REGISTRY로 전송 및 정상적으로 저장된 것 확인
-
SERVING 실행 (재생성)
3) 주의사항
(중요!!) CI/CD는 꼭 PRIMARY DB가 아닌 READ REPLICA를 바라보도록 해야한다!!
- 이유(1) 부하 분산: primary 데이터베이스는 읽기 및 쓰기 작업을 모두 처리해야 하기 때문에 부하가 집중됩니다. 많은 사용자가 동시에 접근하는 경우 성능이 저하될 수 있습니다. read replica를 사용하면 읽기 작업을 분산시켜 primary 데이터베이스의 부담을 줄일 수 있습니다.
- 이유(2) 안전한 읽기 작업: primary 데이터베이스는 중요한 쓰기 작업을 처리하기 때문에, 다른 용도의 읽기 작업이 primary 데이터베이스에 영향을 미치지 않도록 read replica를 사용하는 것이 좋습니다.
- 이유(3) 가용성 향상: 가용성 향상: read replica는 primary 데이터베이스의 복제본이기 때문에, primary 데이터베이스에 장애가 발생하더라도 read replica에서 데이터를 읽을 수 있습니다. 이를 통해 서비스의 가용성을 높일 수 있습니다.
- 이유(4) 확장성: 확장성: 여러 개의 read replica를 배포하면 읽기 요청을 효율적으로 분산시킬 수 있습니다. 이를 통해 시스템의 확장성을 확보할 수 있습니다.
03 TRAINING
- TRAINING이 점선인 이유; 항상 살이있을 필요가 없음!!!!
04 REGISTRY
1) 의미, 역할
모델을 저장해두는 역할.
즉, 그냥 파일 저장소에 가까움.
가장 기본적인 역할은: 네이밍 잘해서 저장 잘하고, 필요할때 다른 컴포넌트에 잘 전달할 수 있는, 그리고 백업 주기적으로 잘하는 정도.
2) 고려사항
필요하다면 모델의 버전 별로 설명을 잘 붙여서 관리하는 컴포넌트(api 형식)를 추가할 수 있다. MLflow, Kubeflow, TensorFlow Extended 등의 서비스가 있다.
05 SERVING
1) 의미, 역할
모델 서빙 담당으로 크게 두가지 기능을 갖는다.
1. user가 입력한 데이터로 prediction을 하는 기능
2. user가 입력한 데이터를 DB로 전송하는 기능
하는 일을 순서대로 나열하면 아래와 같다.
1. REGISTRY에서 모델을 불러와서 저장
2. 모델 서빙 코드가 포함된 git repository를 clone해오기
3. USER와 연결된 API 서버 실행
2) 권장사항
"일반적으로 stateless하게 설계하는 것을 권장"
즉, 김윤아와 한요한이 각각 우리 ML 서비스 API에서 PREDICTION을 요청한다면, 이 둘이 입력한 값들은 서로의 PREDICTION에 영향을 주지 않게 만든다.
= HTTP가 독립적으로 처리된다.
= 서버는 클라이언트의 이전 요청 정보를 기억하지 않고, 각 요청을 별도로 처리
단, 서버에는 저장되지 않을 뿐 위의 역할대로 DB에는 저장시킨다.
3) 추가 고려사항
1. CONTAINER ORCHESTRATION을 활용한 다중 SERVING 사용: 서비스 사용량이 과도하게 많은 경우 SERVING을 여러개 띄워 사용량을 분산대응해야한다. 이때도 각 SERVING 간의 STATELESS 필수!!! 클라우드 서비스를 사용하면 낮은 난이도의 CONTAINER ORCHESTRATION 기능이 있고, 아니라면 KUBERNATES를 사용해야한다.
- KUBERNATES를 사용하면 전체 인프라를 하나의 시스템으로 관리할 수 있다.
2. MESSAGE QUE 사용: 동시 서비스 요청개수가 과도하게 몰리는 경우가 예상된다면, DB에 쓰기 작업을 하는 컴퓨터에 트래픽이 과도하게 몰리게 되어 처리하지 못하는 데이터가 생길 수 있다. 이를 방지하기 위해 요청들을 줄로 나열시켜 하나하나 수행하게끔 만들어주는 MESSAGE QUE 컴포넌트를 추가할 수 있다.
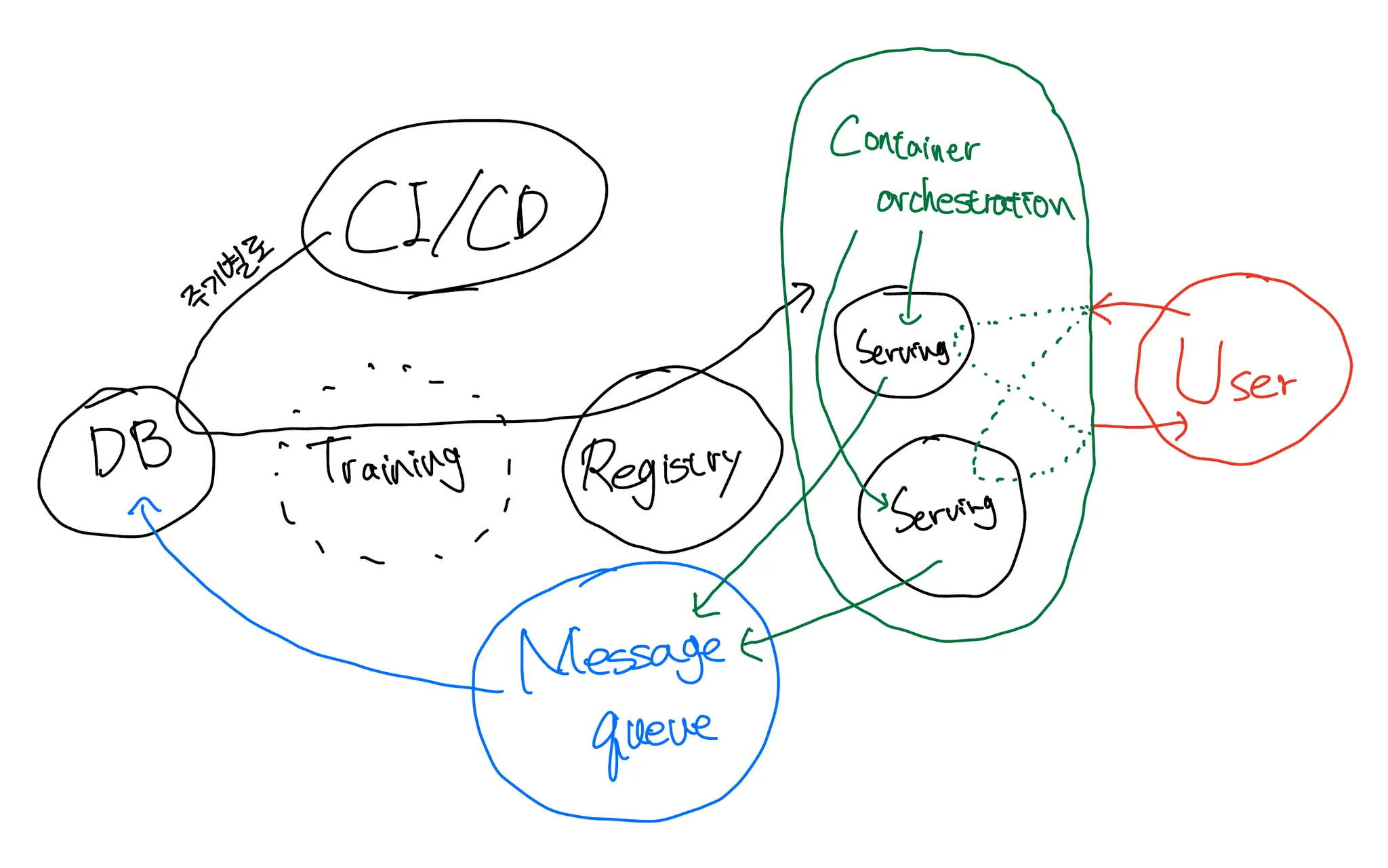
3. ETL 서비스 사용: 생산되는 데이터를 DB에 넣어 실제 사용하기 전에 가공(FEATURE ENGINEERING)하는 작업을 담당한다. 필요한 경우 USER 생산 데이터를 그대로 (임시) 보관하는 DB를 별도로 추가해야한다.
- ETL(Extract, Transform, Load): ETL 과정은 데이터 파이프라인의 일부로서, 데이터를 효과적으로 수집하고 준비하는 데 필수적입니다.
- Extract(추출): 다양한 데이터 소스(예: 데이터베이스, 파일, API 등)에서 데이터를 수집하는 단계입니다.
- Transform(변환): 추출한 데이터를 원하는 형식으로 변환하는 단계입니다. 여기에는 데이터 정제, 집계, 변환, 필터링 등이 포함됩니다. 데이터를 모델이 학습할 수 있는 형태로 준비하는 것이 목표입니다. = FEATURE ENGINEERING
- Load(적재): 변환된 데이터를 데이터베이스나 데이터 웨어하우스 등에 저장하는 단계입니다.
- Feature Engineering: 모델의 성능을 향상시키기 위해 원본 데이터를 변환하거나 새로운 특성(Feature)을 생성하는 과정입니다. 주요 활동은 다음과 같습니다:
- 특성 선택: 모델 학습에 필요한 중요한 특성을 선택합니다.
- 특성 생성: 새로운 유용한 특성을 생성합니다. 예를 들어, 날짜 데이터를 기반으로 요일이나 월을 생성할 수 있습니다.
- 데이터 정규화: 특성 간의 스케일 차이를 줄이기 위해 정규화나 스케일링을 합니다.
- 변환과 인코딩: 범주형 데이터를 수치형 데이터로 변환하거나, 로그 변환 등을 수행합니다.
(비교) 전처리라는 말은 STATIC한 데이터를 교정하는일이고, FEATURE ENGINEERING은 실시간 데이터를 주물러야하는 가장 통계적인 지식이 필요한 예술의 일.
06 ML WORKFLOW ORCHESTRATION
각각의 단계에서 일어나는 과정을 관리감독 하고 싶은 경우 ml workflow orchestration 도구가 필요함. 대표적으로 mlflow, airflow 등의 도구를 사용하게 될 것.
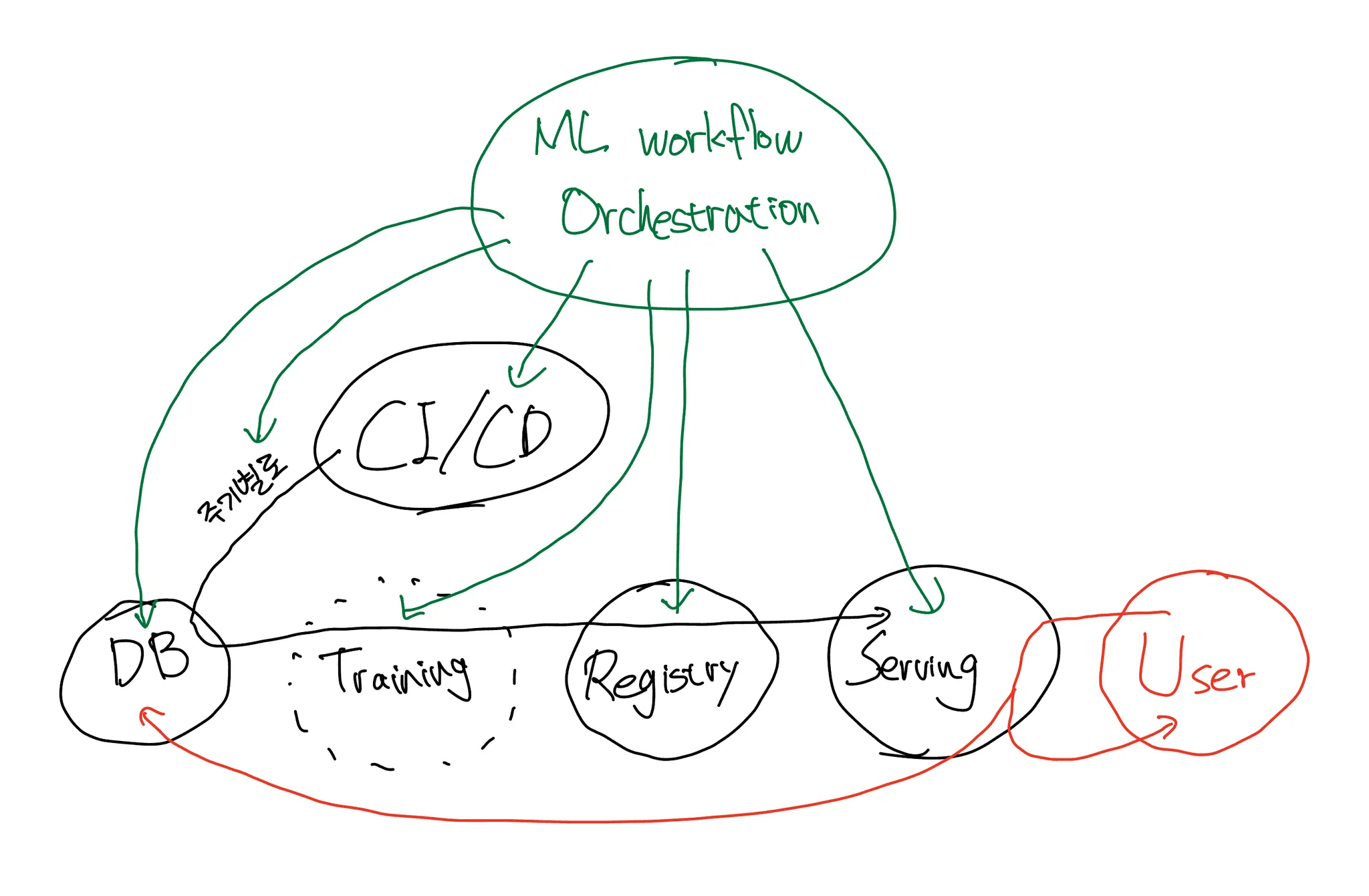
특히 상세한 로그를 보기 위해서는 필요!
만약 위의 모든 컴포넌트를 클라우드에서 진행하게 된다면, orchestration 도구 또한 클라우드 서비스를 사용하고 컴포넌트의 생성 및 관리도 해당 도구 위에서 진행하는 것이 유지보수 측면에서 유리
