
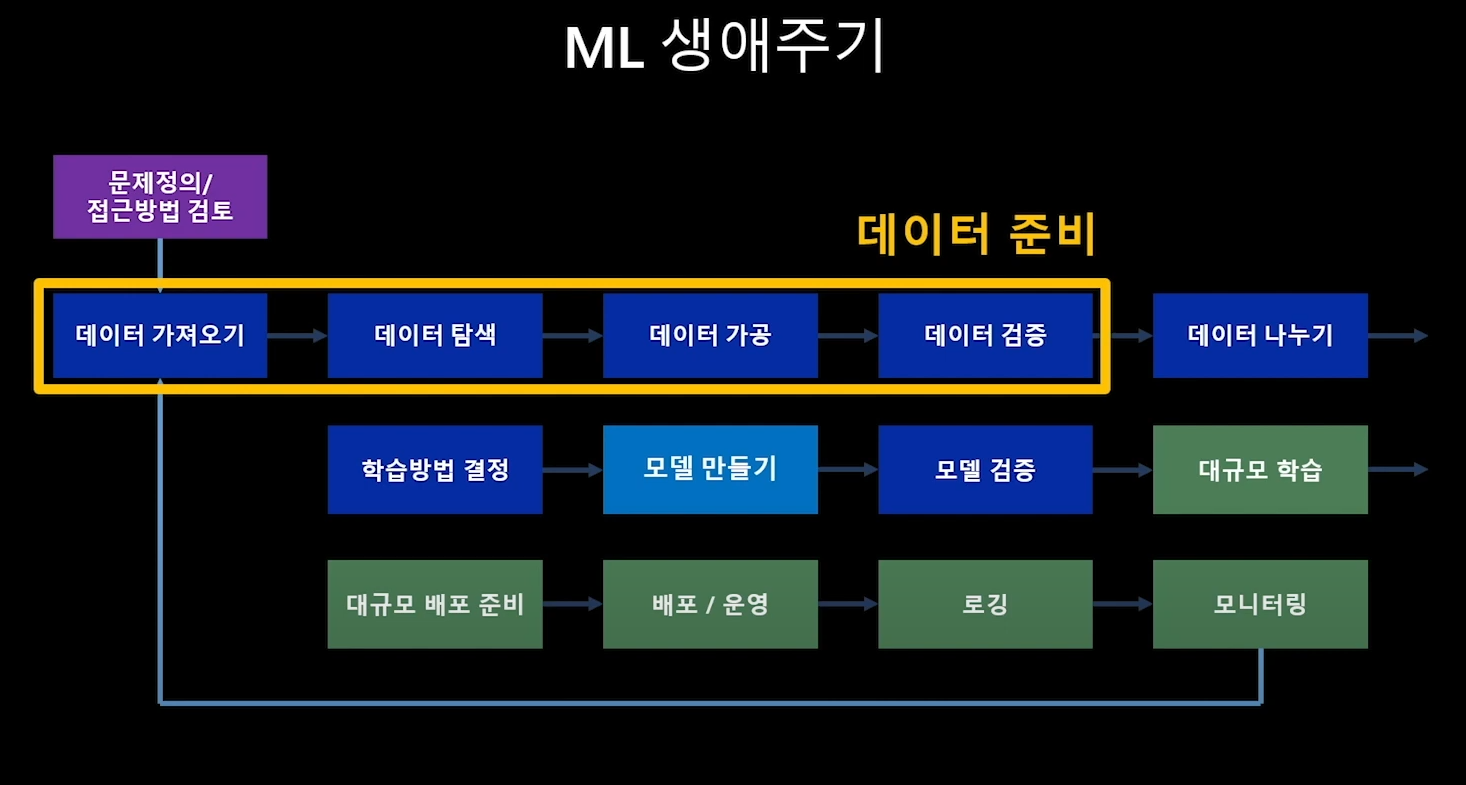
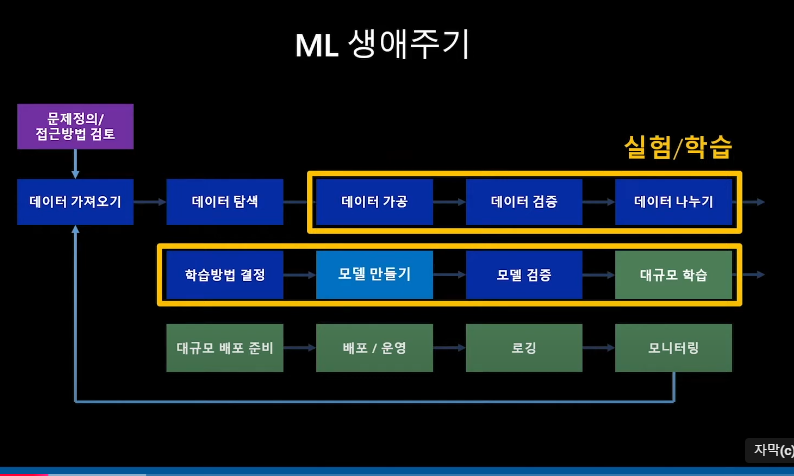
0. MLOPs란
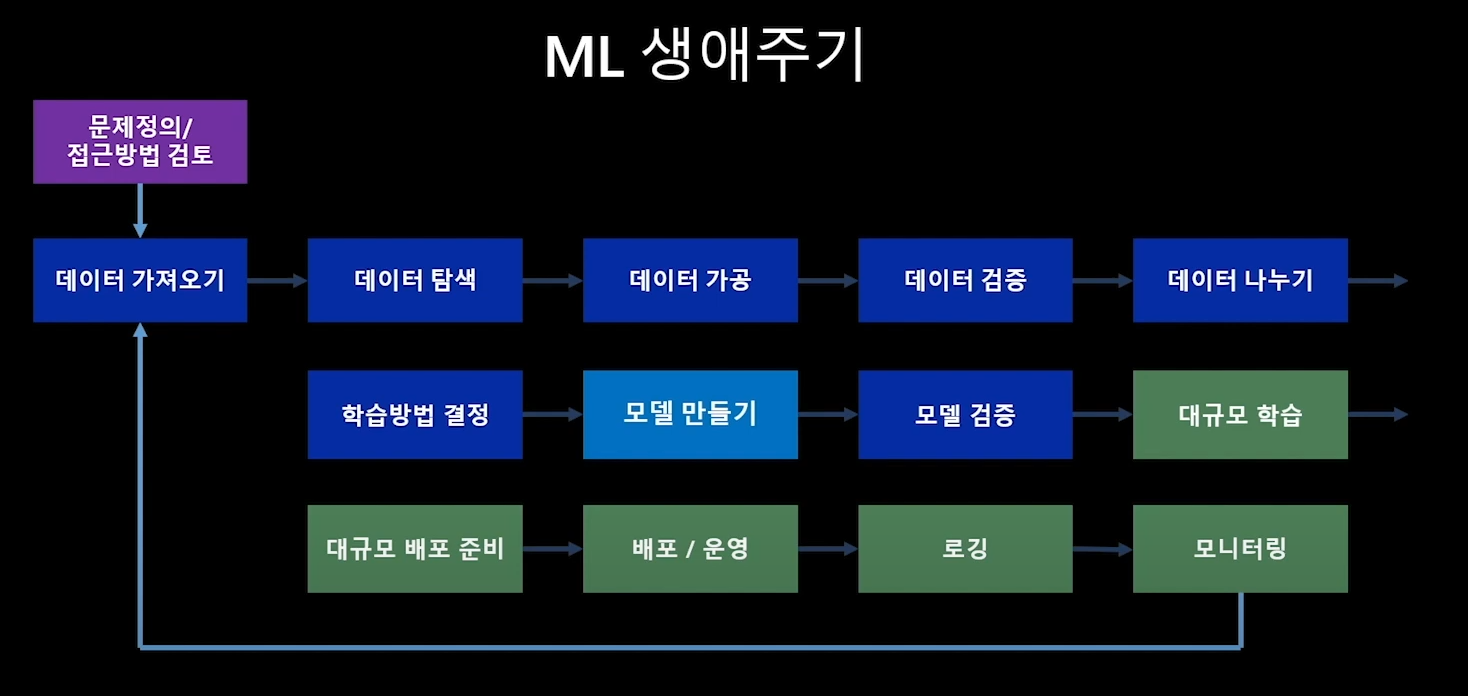
- 문제정의
- 데이터 가져오기
- 데이터 탐색
- 데이터 가공
- 데이터 검증
- 데이터 나누기
- 학습방법 결정
- 모델 만들기
- 모델 검증
- 대규모 학습
- 대규모 배포 준비
- 배포/운영
- 로깅
- 모니터링
<누가?>
파란색: 데이터 사이언티스트
- 빠르게 실험 반복하기
- 가장 좋은 툴 찾기
- 머리 아픈 관리는 최소화하기
- 대용량 데이터 가공 및 모델 학습
초록색: 데이터/소프트웨어 엔지니어
- 툴과 플랫폼의 재사용
- 컴플라이언스
- 모니터링 및 감사
- UPTIME 유지하기 (서비스 죽지않고 살아있게 만들기)
<DevOps와 MLOPs 비교>
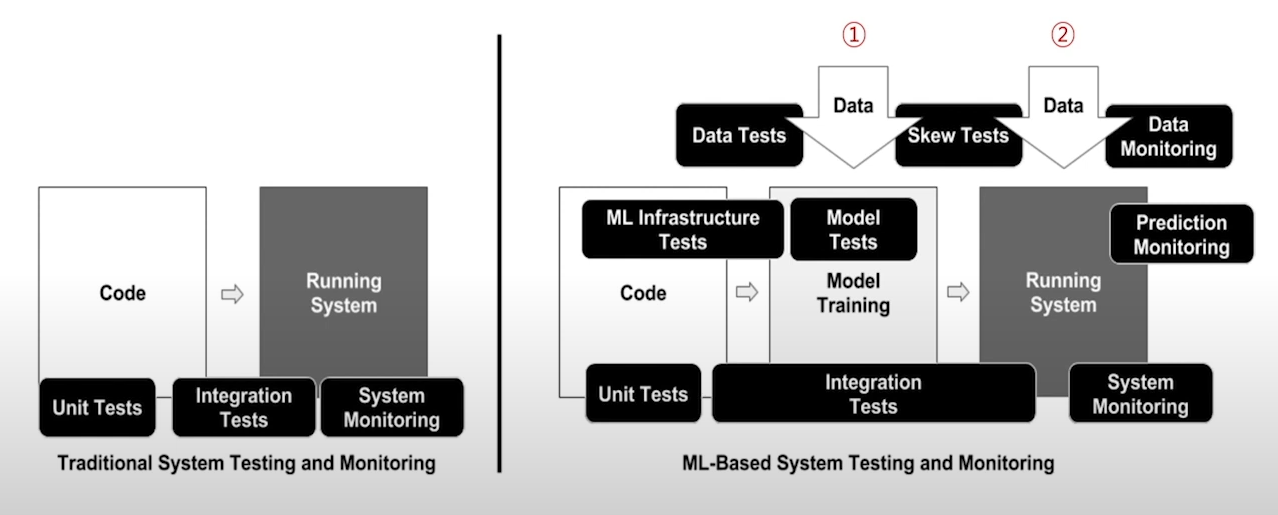
DevOps
데브옵스의 중요한 대부분의 영역은 '조직문화관리'
but 그외의 플로우는 크게 두 단계
코드를 만드는 단계 > 서비스 형태로 패키징해서 운영하는 단계
그리고 그 과정에서 테스트/모니터링 단계는 3개
부분적으로 만든 유닛코드 테스트 > 전체 코드를 종합적으로 테스트 > 배포후 모니터링
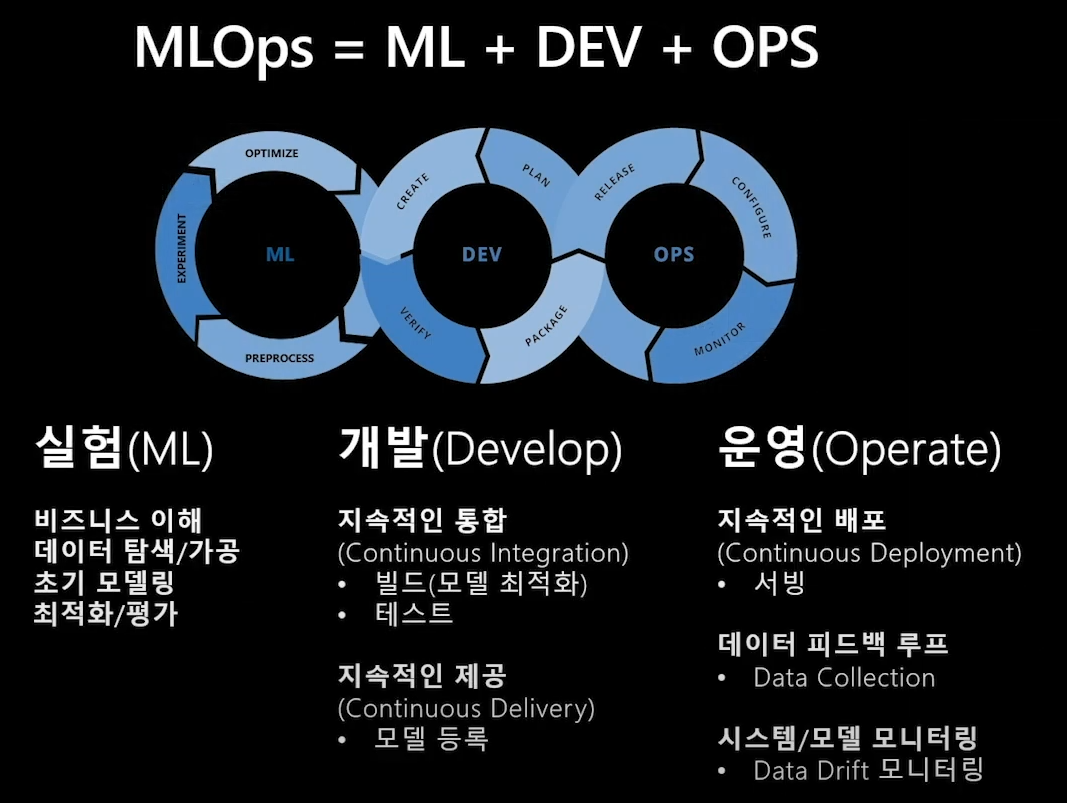
MLOPs
데브옵스와 비슷한 구조지만 두가지가 다르다!
1. 한 단계가 추가됨 = 모델 만들기 = Model Traiding
2. 내가 코드만 만들면 되는 데브옵스와 다르게 DATA를 가져와 사용해야해서 만들어지는 단계들이 있다.
- 데이터는 크게 두개: 1) 모델을 계속 테스트해보며 만드는 과정에서 가져오는 데이터와 2) 이를 배포해서 사용하는 중에 모이게 되는 현실/진짜/REALTIME 데이터들
공통점은 결국 배포 후 운영하며 모니터링을 통해 다시 원래의 실험단계로 돌아와야한다는 루프를 그려내는 것!
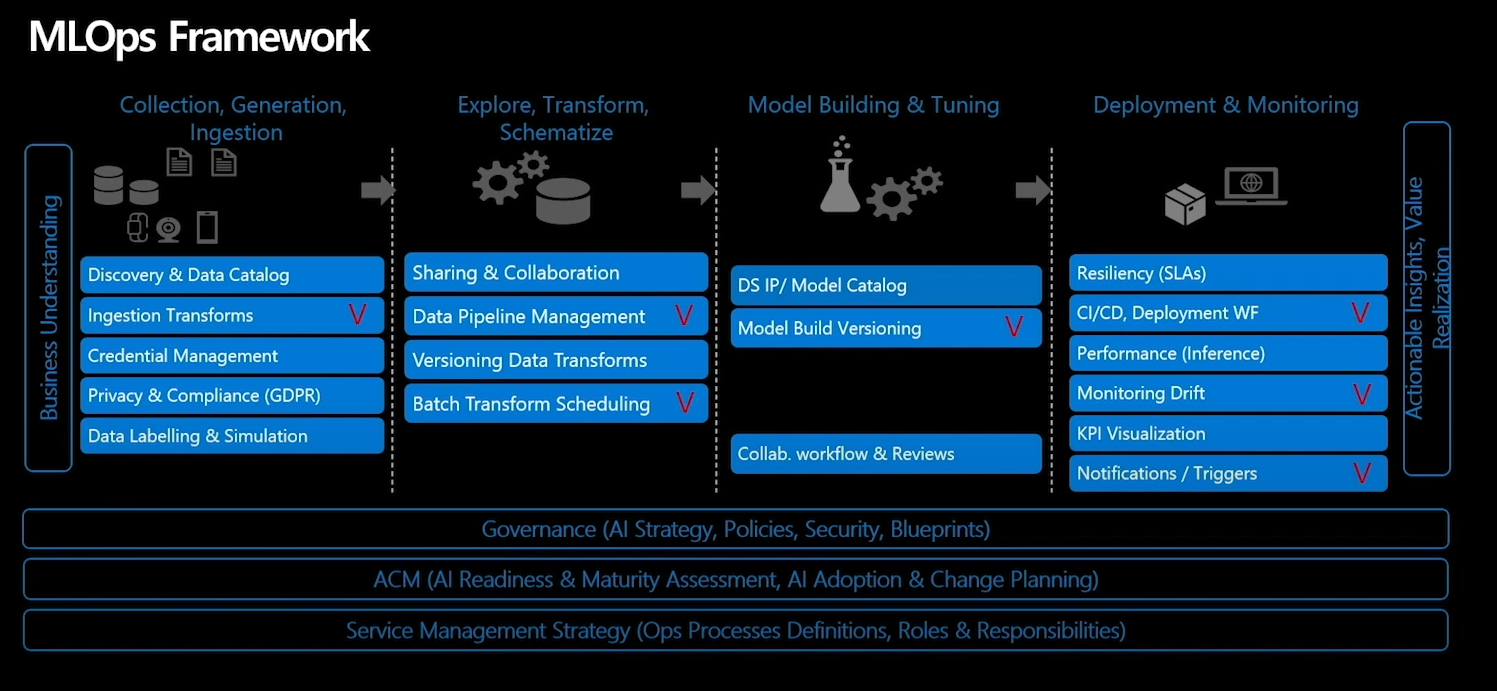
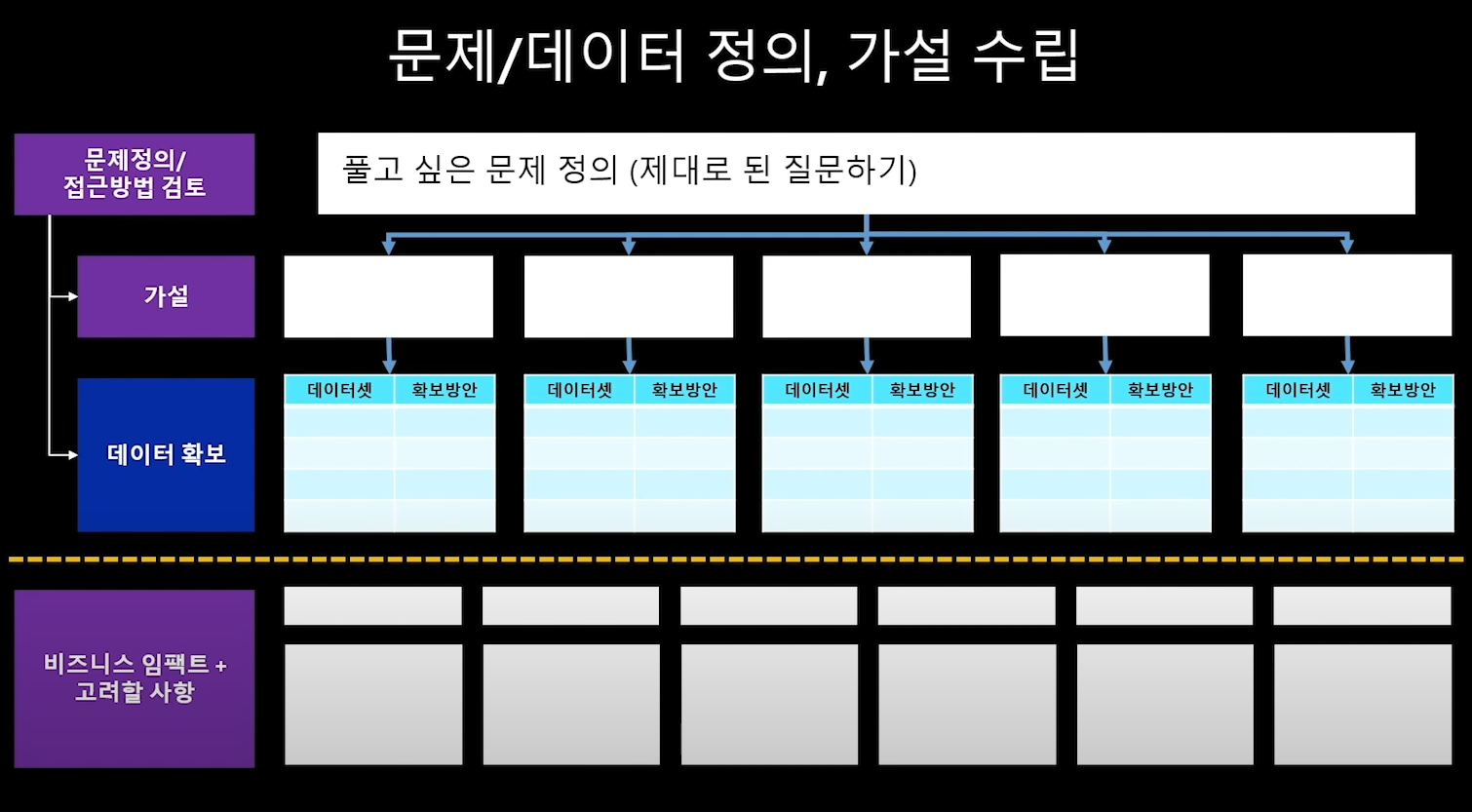
1.문제 정의
머신러닝 프로젝트의 출발점!
아래의 빈칸들을 채워보기
2.데이터 준비
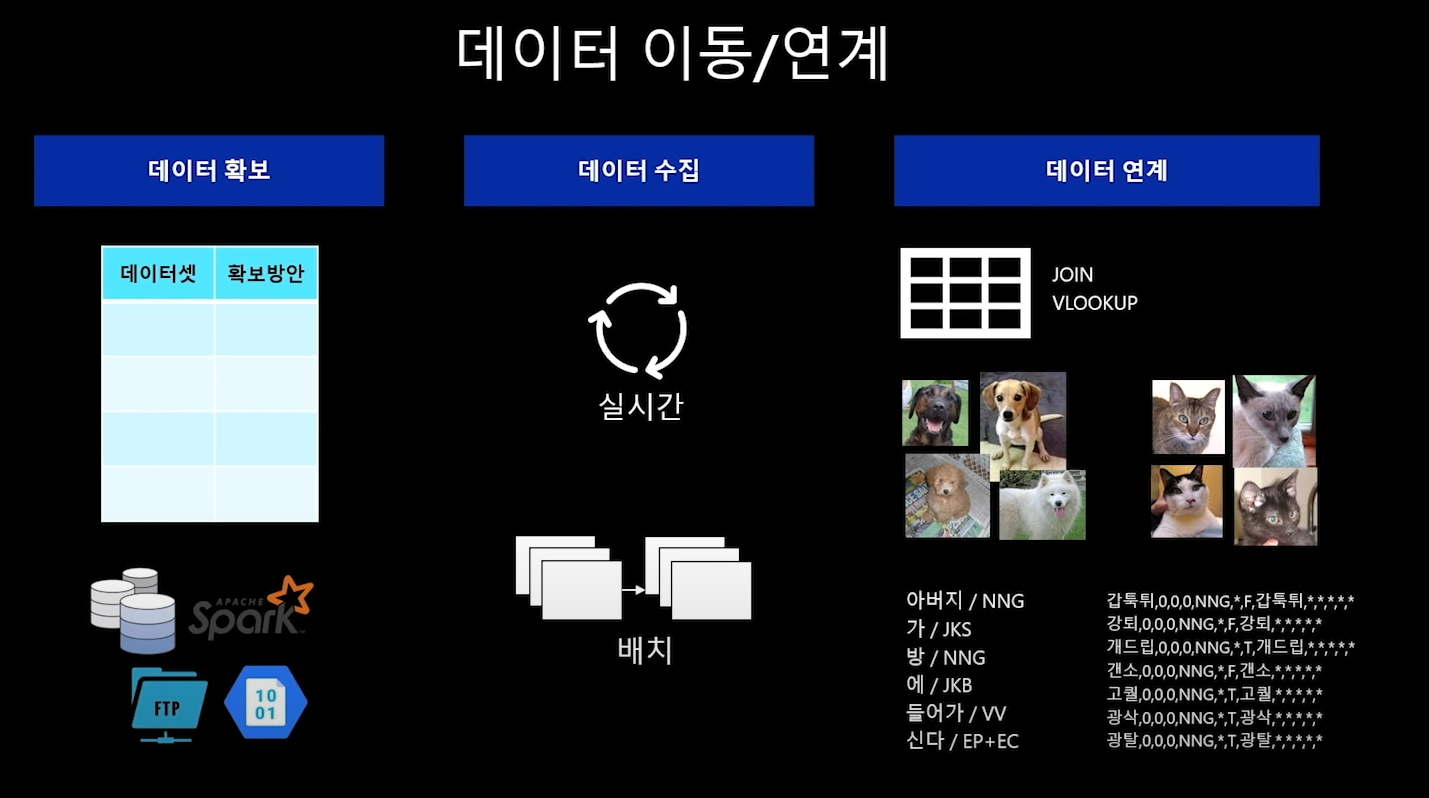
(1) 데이터 가져오기
① 데이터 확보
어떤 데이터를 어디에서?
② 데이터 수집
실시간 방식 / 배치 방식??
③ 데이터 연계
엑셀이면 VLOOKUP으로 연관된 것들을 묶어서 보거나,
그림데이터면 연관된 것들끼리 묶어놓거나
텍스트 형태면 모델이 필요료할 형태로 묶기
④ 데이터셋 공유 및 재사용
데이터를 어디서 가져왔고, 버전별로 어떻게 되어있고, 어떻게 과거에 사용했고, 또 팀원들과 공유할건지... 이에 대해 고민하고 효율화시키는 것이 중요해진다!
⑤ DATA DRIFT 감지 및 관리
데이터의 통계적 특성이 시간이 지나면서 변하는 현상인 DATA DRIFT를 관리해야함
(2) 데이터 탐색/가공
① 데이터 탐색
내가 확보한 데이터가 어떠한 형태인지 확인하기
빠진 값은 없는지, 내가 예상한 분포를 가지고 있는지?
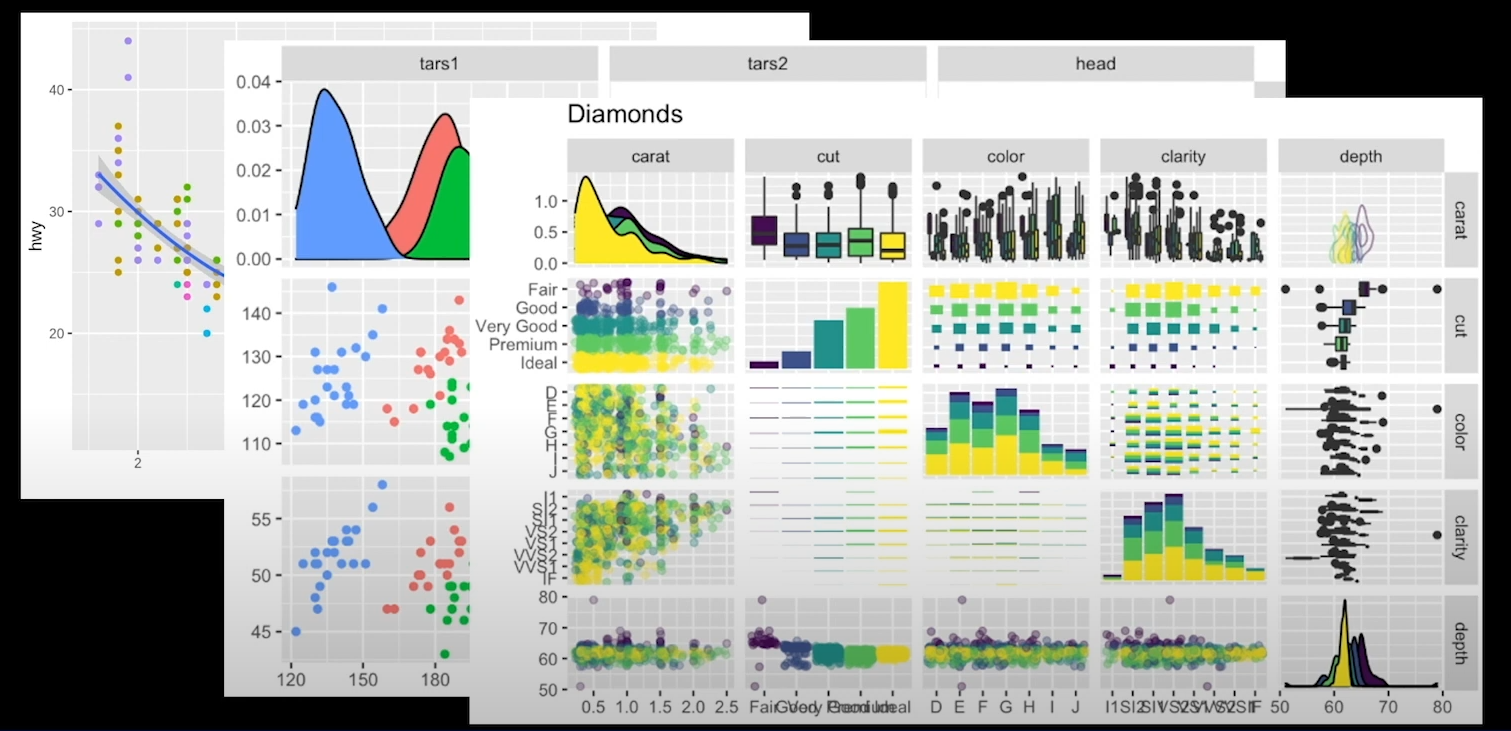
데이터들을 다양한 형태로 시각화해보며 탐색하기
②데이터 가공
①에서 발견된 미흡하거나 특이사항이 있는 부분들은 가공을 통해서 보완/조정하기
이부분에 자동화 기술이 들어가기고 합니다.
(빠진 값 채우기, CLASS 간 균형등 체크포인트들을 만들어서...)
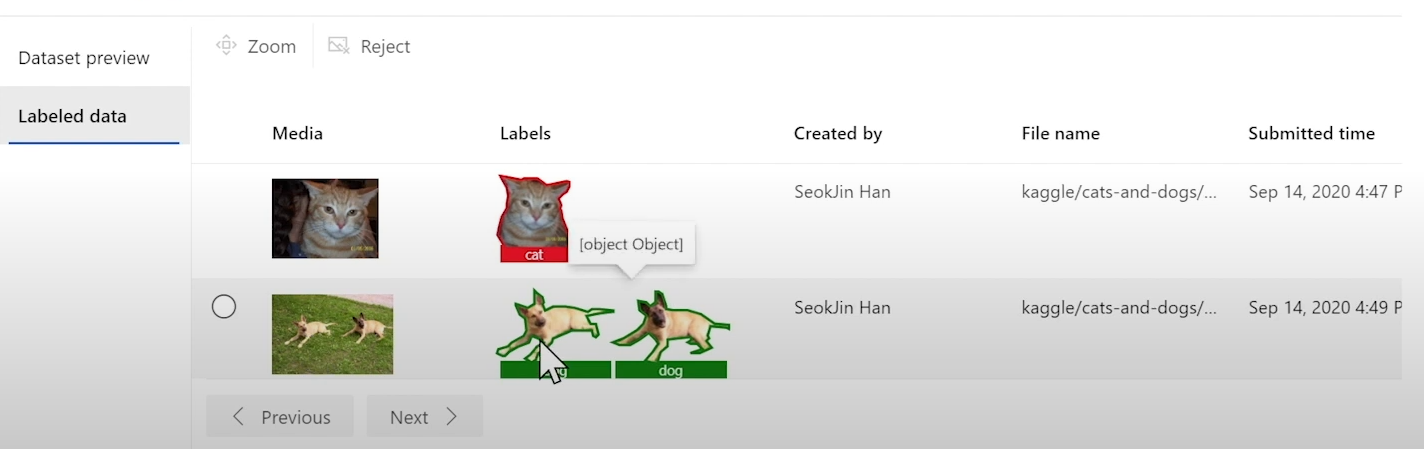
③ 데이터 레이블링
레이블 = 목표값
예를들어 이미지로 동물을 분류하기는 모델을 만든다면
기존 사자와 돌고래 사진에서 "이건 사자" "이부분은 돌고래"라고 레이블을 달아 주는 과정도 본격적인 모델링 전 데이터 가공과정의 일종이다.
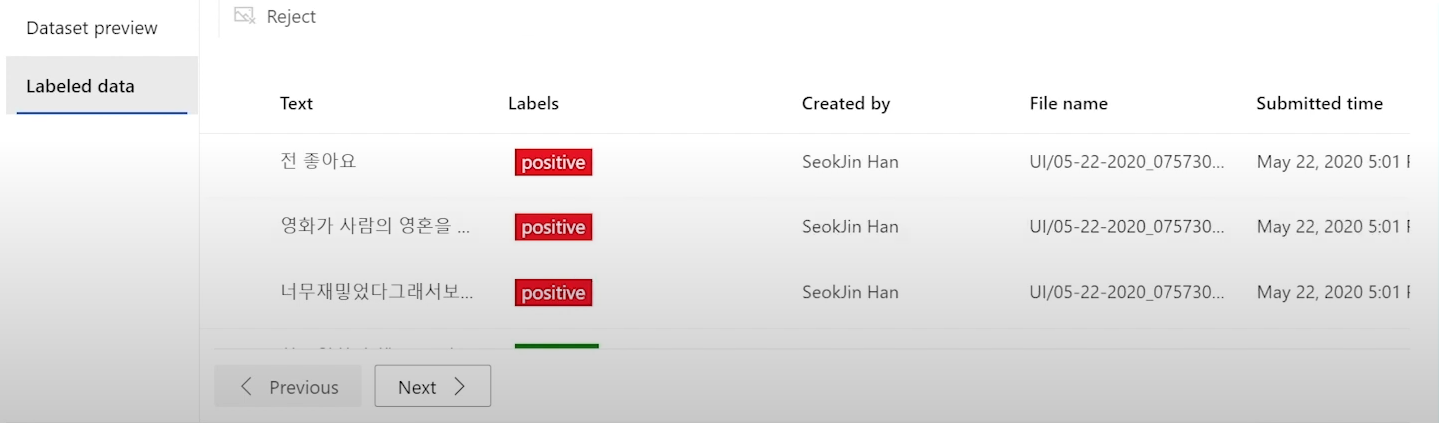
또다른 예: 텍스트로 모델링 할때 사용되는 단어들 중에서 이건 POSITIVE 표현, NEGATIVE 표현... 이렇게 나눠서 라벨링하는 것
④ feature importance 탐색
데이터의 컬럼 = feature
어떤 컬럼이 내 모델에 더 중요하고, 덜 중요한가?
이건 로컬 지식을 기반으로 한 이성적 판단으로도 갈음할 수 있지만
데이터의 관계성 자체만으로도 판단할 수 있다.
이렇게 어떤 데이터 feature가 더 중요한지 덜 중요한지 판단하는것도 탐색의 한 과정이다.
3. 실험/학습
데이터를 가공하는 과정과 밀접하다
데이터가 어떻게 가공되었는지가 모델의 성능을 좌우한다.
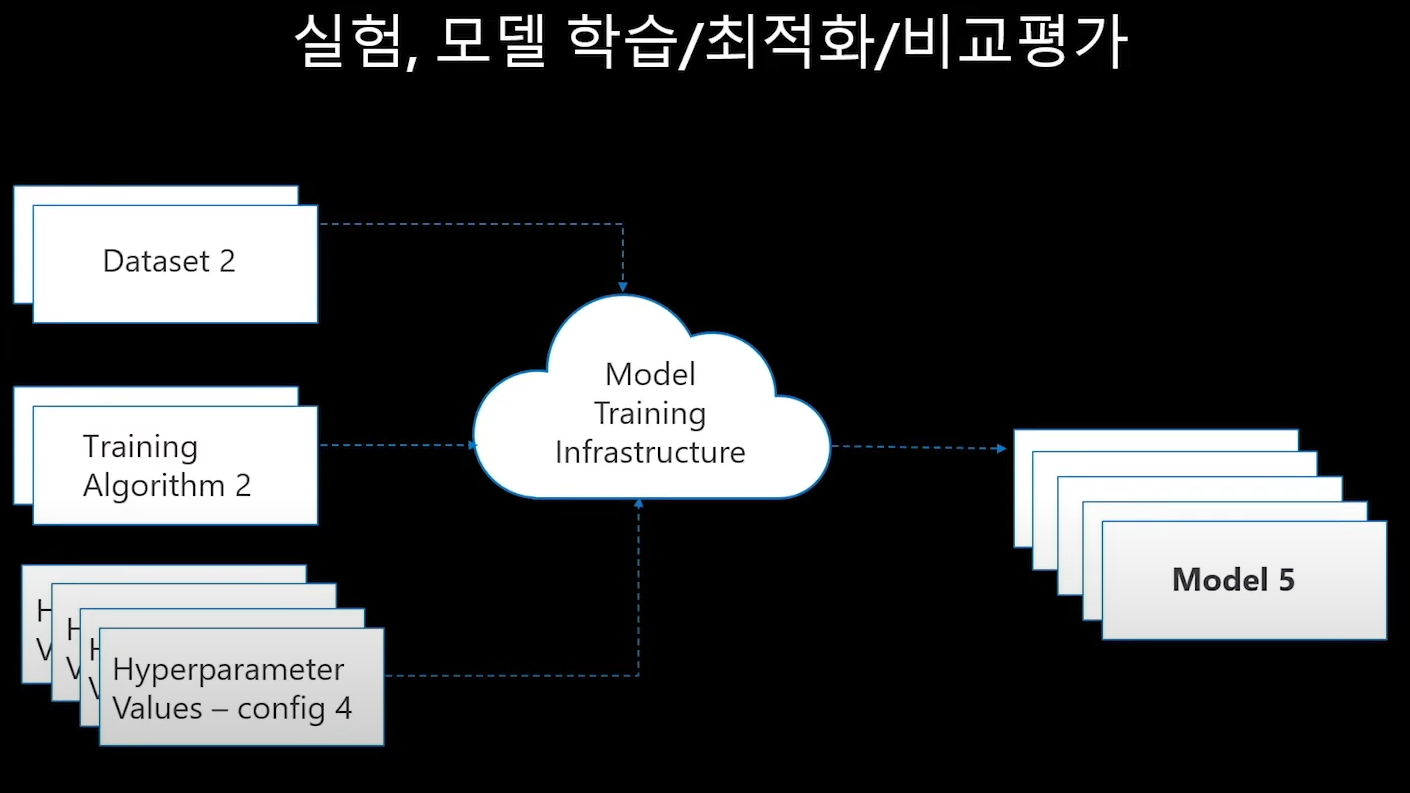
① 모델학습 / 최적화 / 비교평가
모델을 만든다는 건 결국 입력을 받아 출력물을 만드는 것.
어떤 입력조건 = input 환경이 필요한가?
1. data set
2. training algorithm
3. hyperparameter values
이 세가지 중 하나가 변하면 model의 출력값은 변한다.
참고: data set은 데이터 / 알고리즘과 하이퍼파라미터는 코드적 요소이다.
② 실험 추적관리
여러 모델은 비교해야하는 ①을 하다보면 이런것들이 궁금해진다.
최근 모델들에서 어떤 알고리즘과 파라미터를 썻더라?
데이터의 feature 변경은 어떤 영향이 있더라?
지난번에 썼던 스크립트는 어떤 버전이었지?
그래서 필요한게 실험 추적관리!
- 실험실행에 사용한 input 요소들(data set, code...)과 환경(파이썬 패키지 등)을 기록하고
- 실험 실행으로 출력된 출력물들, 모델의 버전들도 유기적으로 기록되어야한다!
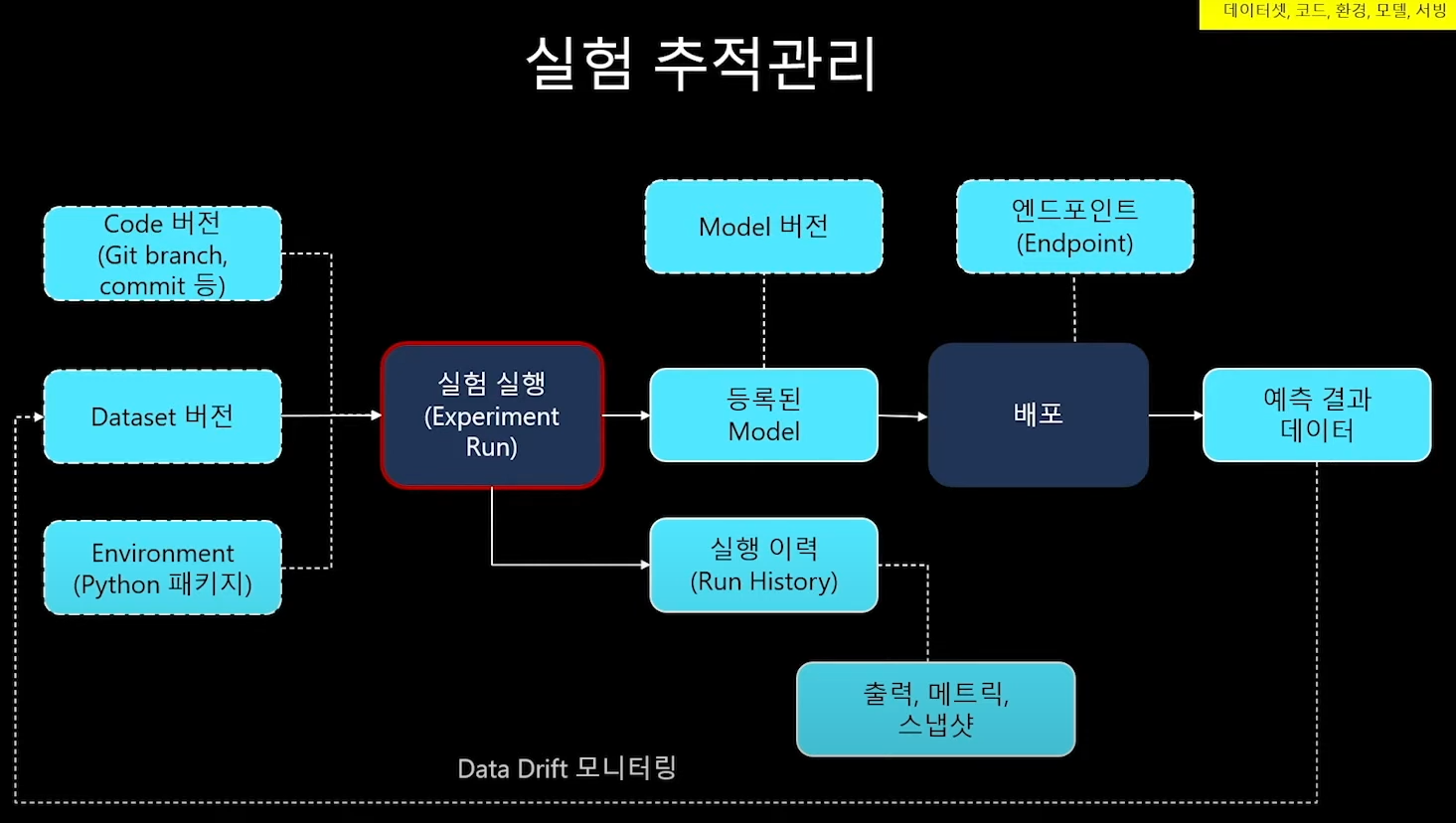
중요한건 input과 output이 잘 연계되어 기록관리되어야 한다!
어떤 input / 어떤 모델 / 어떤 output >> 유기적 관계!
③ 자동화된 ML (automated ML)
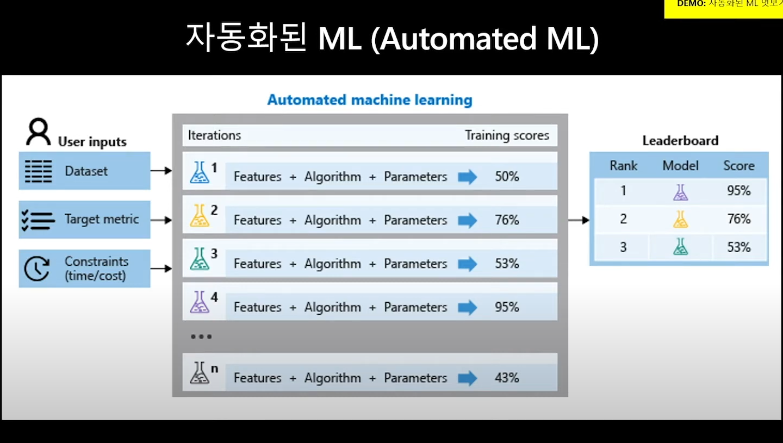
데이터 input을 넣어주면
자동으로 코드적 input(알고리즘과 데이터전처리 기법 등)에 variation을 주며
output의 성능을 예측해내 효율성을 올려주는 것
중요한 것은
마냥 랜덤하게 돌리는 것이 아니라
성능을 높이는 방향을 스스로 찾아서 돌려본다는 점이다!!
모델의 결과값만 보는게 아니라 이를 정량화해서 자동으로 성능지표가 뽑혀 비교분석할 수 있도록 해줘야함.
④ 모델의 검증: 예측성능/처리성능
-
예측성능: 이 모델이 얼마나 실제값을 잘 설명하나
* 개별 모델의 지표들에 따라...- 분류나 회귀냐에 따라 기준이 다름
-
처리성능: 실제 서비스로 넘어갔을때 안정적으로 확장에 용이하게 작동하나
* 어떤 이슈가 있었고 이것이 어떤 로그로 해결되어왔는가
⑤ 모델해석
모델 검증의 한 과정으로 내 모델이 예측을 잘하고 있는지, 왜 이 예측값이 나왔는지, 어디를 보고 중요하게 생각했기에 그 값이 나왔는지를 해석해보는 것. 설사 맞는 예측을 했다 하더라도 그 이유가 나의 상식과 다르다면, 또는 사실과 전혀 다른 이유로 그 결론을 추론했다면 그 모델은 틀린 모델이다.
예)
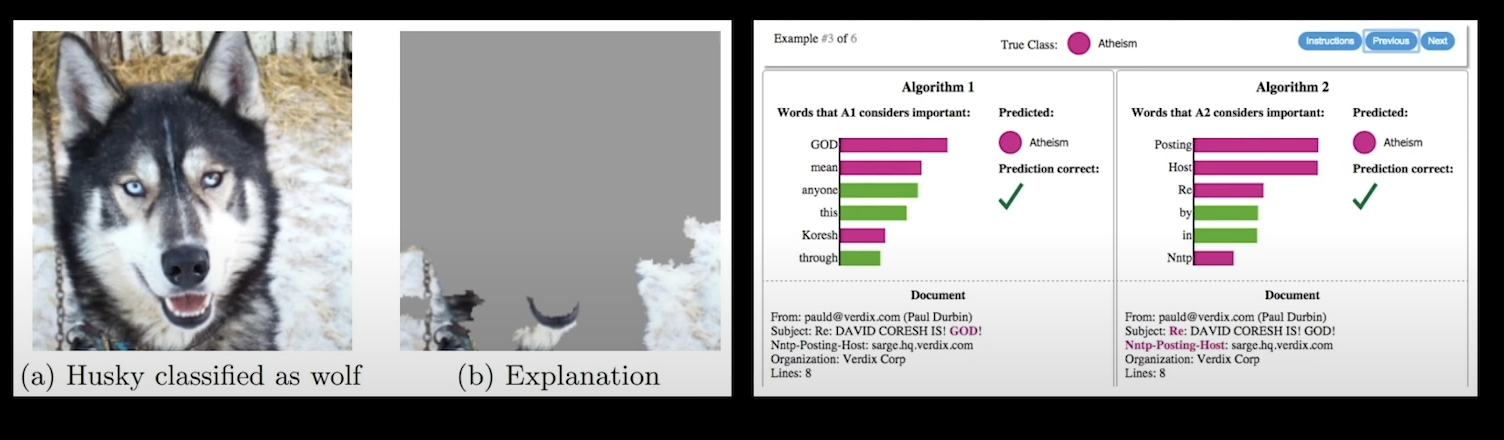
모델 해석을 해야하는 이유는 다양하다.
"accuracy 지표가 높으면 추론체택!"이라는 자동 로직에 기반한 것이 아니라 그 내용을 들여다보고 사람이 판단할 수 있게 하는것 = 이를 human in the loop라고 한다.
내 모델이 체택되기 위해서는 모델의 합리성을 증명하기 위해서 모델 해석이 필요하고,
심지어 비즈니스별로 모델 해석이 의무화되기도 한다: 의료 등

모델해석 방법
글로벌: 내 모델의 전체적인 해석
로컬: 내 모델의 특정 영역 별 해석
model specific: 특정 모델에만
model agnostic: 모든 모델에 범용적으로

오른쪽의 리스트들은 다양한 모델 해석 로직, 툴들이다
azure에는 다양한 모델 해석 및 시각화 모델이 탑재되어 있다.
SHAP: 트리모델에 적합한/딥러닝/커널모델에 적합한 해석 테크닉
MIMIC: 원래 모델이 엄청 복잡한 경우 그것과 비슷하게 행동하는 대체 모델을 만들어 돌려본 후 해석하는 간접적인 방법

특히 로컬과 글로벌 간의 FEATURE IMPORTANCE의 차이 중요함
PERTURBATION탐색 & ICE는 같은 데이터셋에 하나의 FEATURE만 바뀌었을때 어떤 변화가 나오는지 알아보는 해석툴
(예: 당뇨병 환자A의 모든 요소는 동일한데 나이만 30대에서 60대로 바꾸었을때의 결과값의 변화 등)
4. 배포 서빙
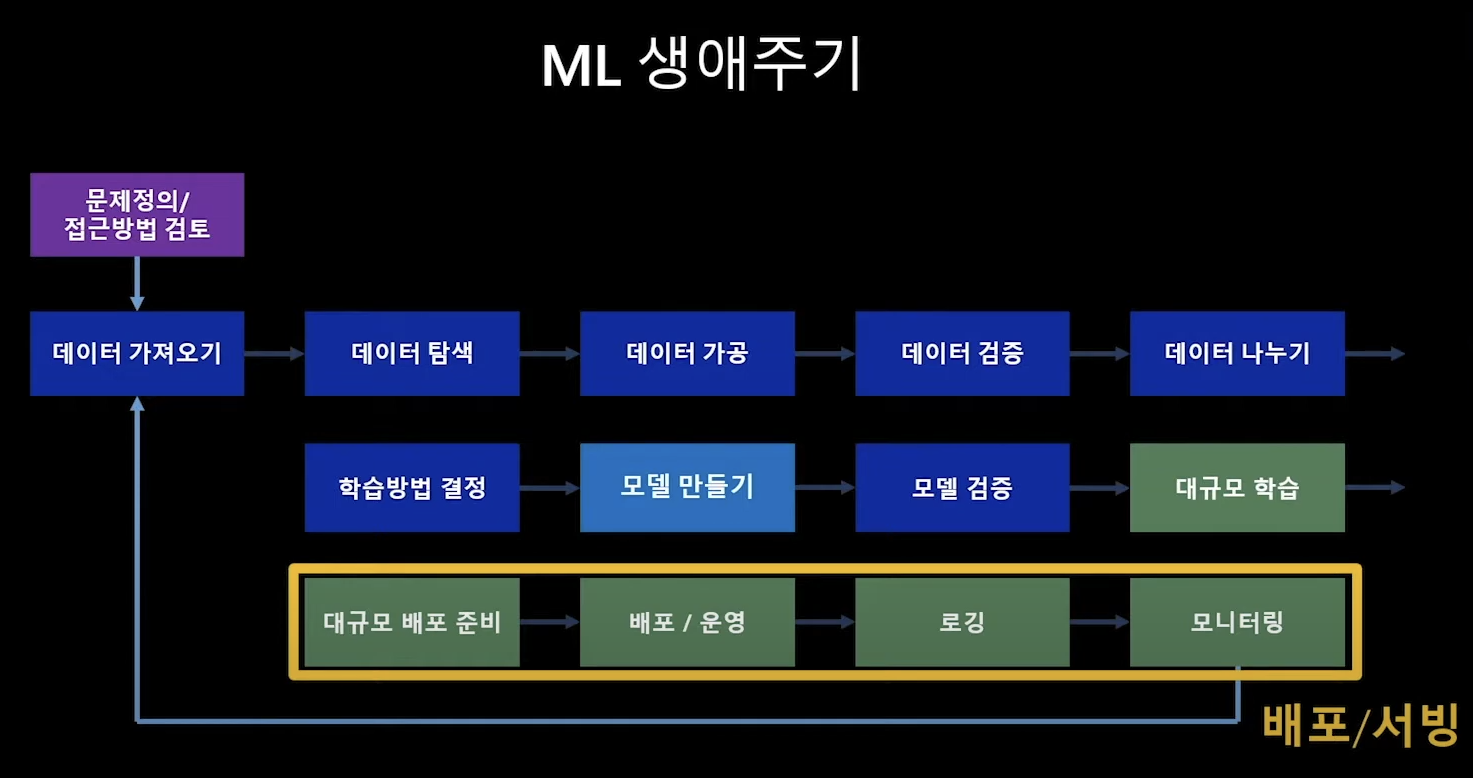
전반부는 데이터 사이언티스트가 데이터와 모델을 만들고
후반부는, 즉 모델을 서비스화 하는 것은 데이터/소프트웨어 엔지니어에게로 이관
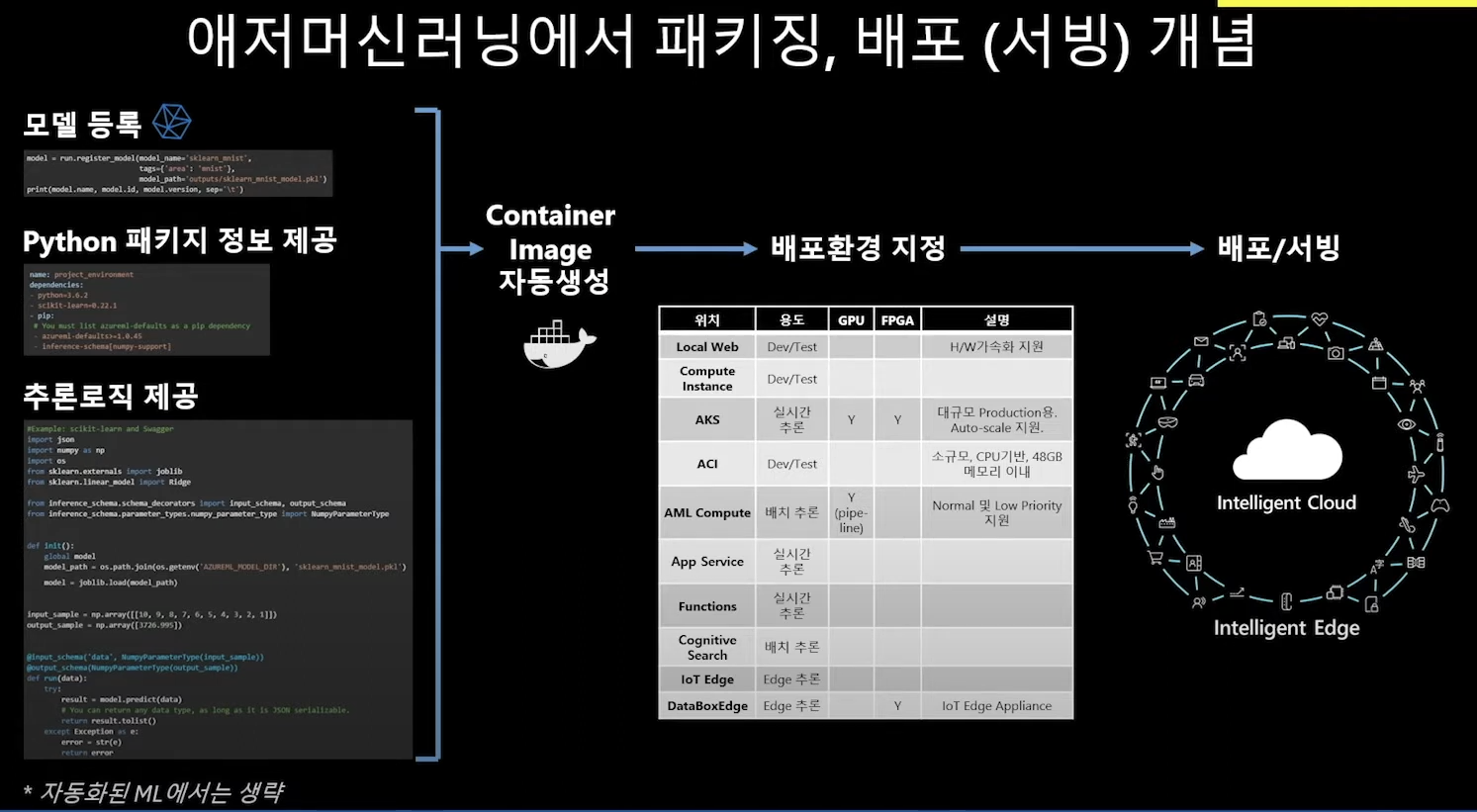
가장 중요한 건 컨테이너, 즉 도커를 통해 이미지를 배포한다!
ML에서 컨테이너를 선택한 이유 = 재현의 안전성!!
컨테이너에 들어가는 내용
1. 모델 등록 : 다양한 모델이 실험되었고 그중 최적의 모델이 체택되면 이걸 서비스화하기 위해 모델을 등록한다
2. 파이썬 패키지 정보 제공: 어떤 파이썬 패키지를 이용해서 예측을 수행할 것인지
3. 추론로직 제공: 어떻게 데이터를 받아오고, 어떻게 가공하고, 어떻게 모델을 활용해서 예측값을 계산해내고, 필요하다면 그 값을 또 어떻게 가공(시각화 등)해서 최종 리턴할 것인지?
데이터 드리피트
모델 성능 파악을 위한 모니터링 방법 중 하나
모델 성능 파악은 결국
모델이 만들어낸 예측값과 실체값이 같은지 확인하는 것.
근데 문제는 실체값은 나~중에 나오니까 예측값을 만드는거라
모델 성능을 바로바로 측정하기 하기 어렵다.
그래서 사용하는 것이 데이터 트리프트
= 내가 학습할때 썼던 데이터 셋의 패턴과 지금 운영상태에서 들어오고 있는 데이터 셋의 비교! 이 둘의 패턴이 처음엔 같았지만 점점 패턴이 뭉그러진다면... 모델의 성능이 떨어지고 있는 것이라고 간접적으로/미리미리 측정한다.
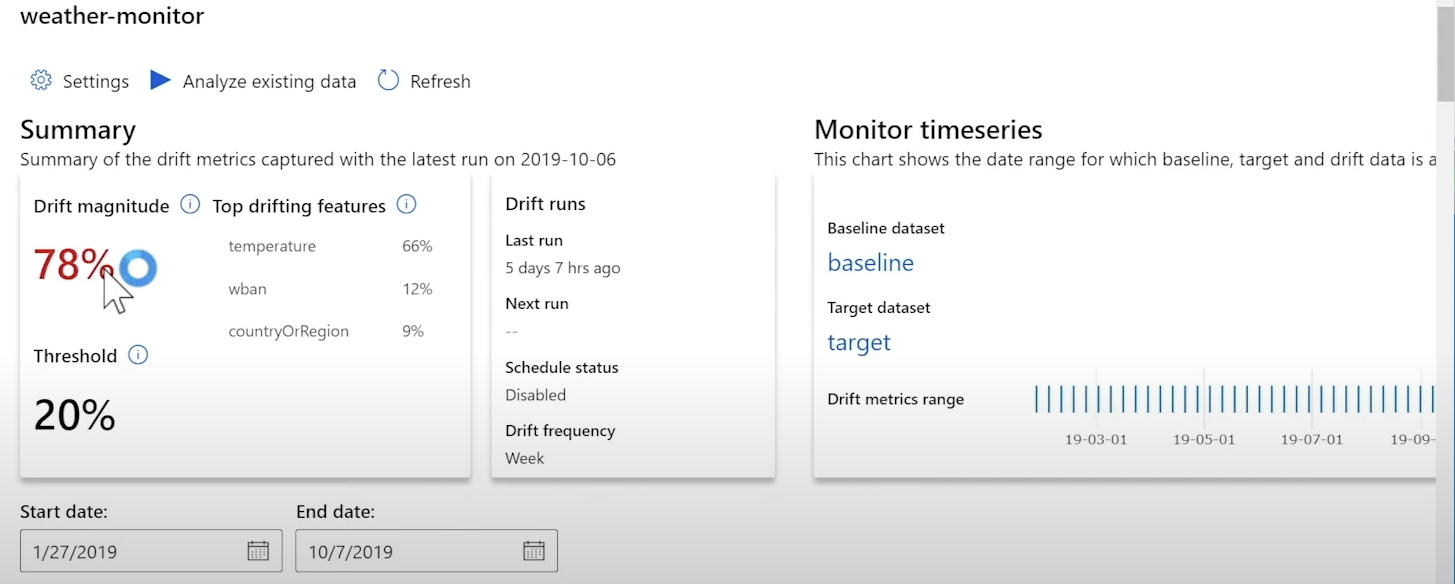
예시) AZURE의 드리프트
나의 모델개발 시절의 데이터 셋과 지금 운영중에 수집되는 데이터들의 드리프트 정도가 78%이고 그 가장 큰 피처는 "온도"다. 그리고 만약 이 드리프트가 20%이하로 떨어지면 나에게 알람을 주고, 자동 재학습/재배포 루프를 돌려라 라고 명령을 줄 있음.
