01 PANDAS란
넘파이의 한계: 가독성이 떨어짐, 정보에 대한 레이블 삽입 불가, 한가지 데이터 타입만 사용해야함
그래서 사용하는 것이 판다스
넘파이를 기반으로 만들어짐
판다스의 장점: 다양한 데이터 불러오기, 데이터 가공, 데이터 분석, 데이터 시각화
넘파이가 복잡한 수학연산, 특히 행렬연산에 특화되어있다면
판다스는 표 형태의 데이터를 간편하게 다루고 싶을때 사용한다
판다스의 기본단위는 데이터프레임과 시리즈다.
- 시리즈(Series): 1차원 데이터 구조로, 엑셀의 한 열(column)이나 파이썬의 리스트(list)와 비슷합니다. 인덱스(index)와 값(value)으로 이루어져 있습니다.
- 데이터프레임(DataFrame): 2차원 데이터 구조로, 엑셀의 스프레드시트(sheet)와 유사합니다. 여러 개의 시리즈가 모여서 형성된 구조로, 각각의 시리즈가 데이터프레임의 열(column)을 이룹니다. 행(row)과 열(column)로 이루어져 있으며, 각 행과 열은 인덱스로 구분됩니다. 즉, PANDAS가 표 모양으로 데이터를 다를 수 있는건 데이터프레임 기반이기 때문이다!
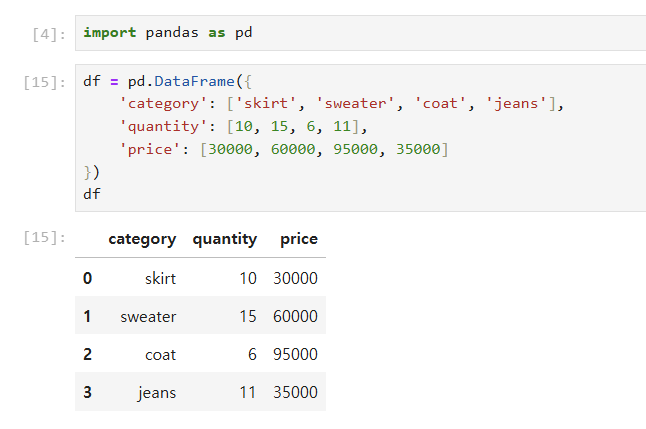
ROW - 행 - 가로줄 - 제일왼쪽 INDEX로 정렬
COLUMN - 열 - 세로줄 - COLUMN의 이름으로 정렬
기본적인 연산들은 NUMPY와 동일하게 사용가능
02 PANDAS 사용하기
01 DATAFRAME 만들기
(1) 리스트 사용하기
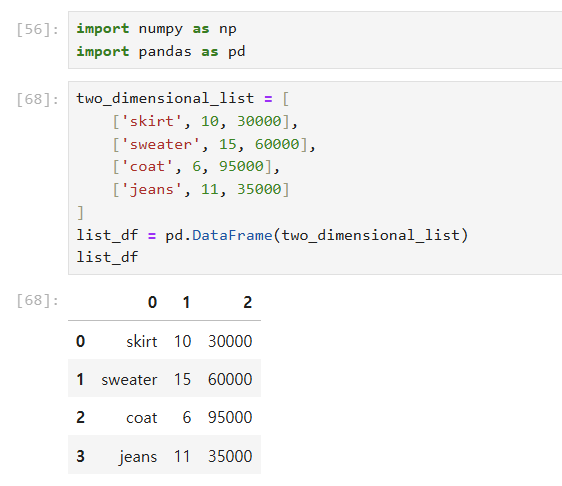
(2) NUMPY 사용하기
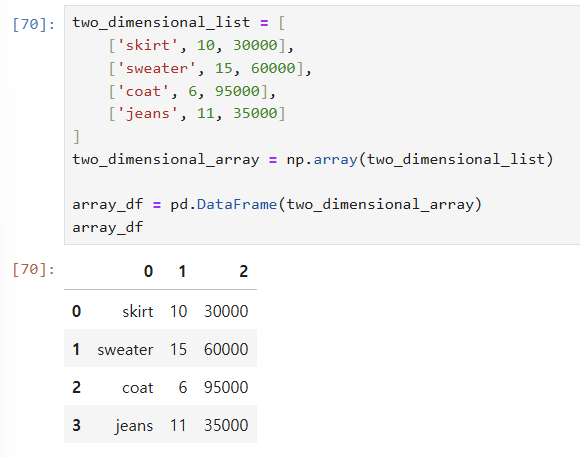
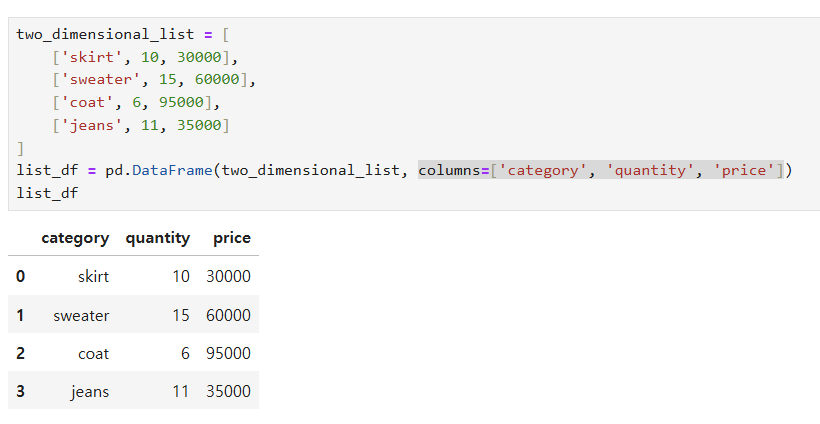
칼럼네임 삽입하기 : 옵션에 columns=[네임, 네임, 네임...] 삽입하기
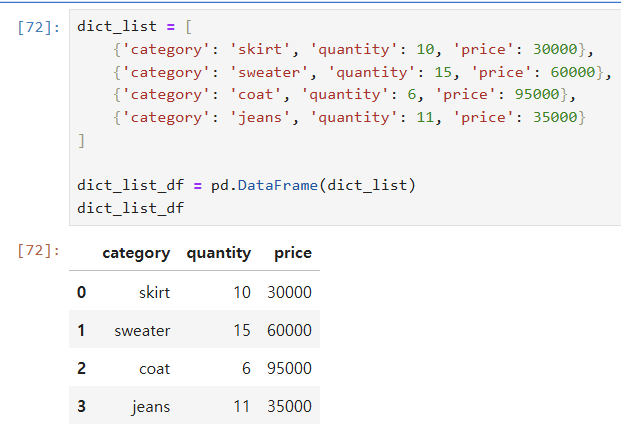
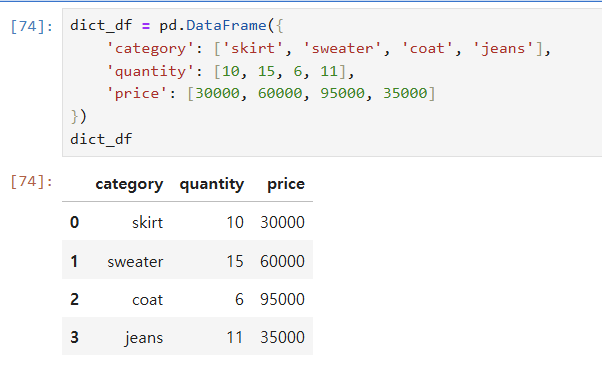
(3) 딕셔너리 사용하기
02 데이터 불러오기
(1) csv 파일
csv = comma - seperated - values, 콤마로 분류되어있다
- pd.read_csv(' / /csv파일 경로.csv')
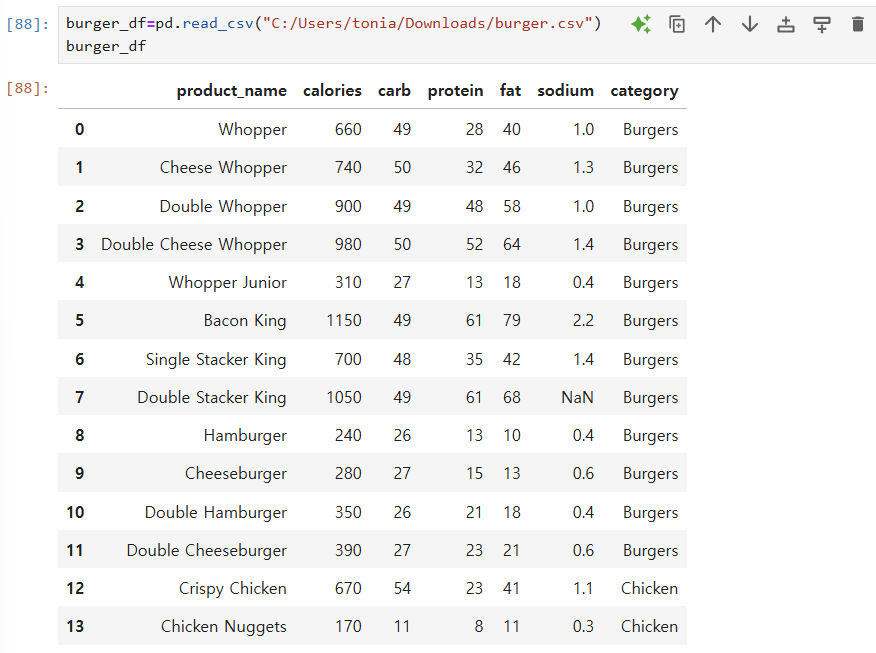
- header 없애기 : pd.read_csv(' / /csv파일 경로.csv', header=None)
- header 만들기 : pd.read_csv(' / /csv파일 경로.csv', header=None, names=[칼럼 이름, 이름, 이름...])
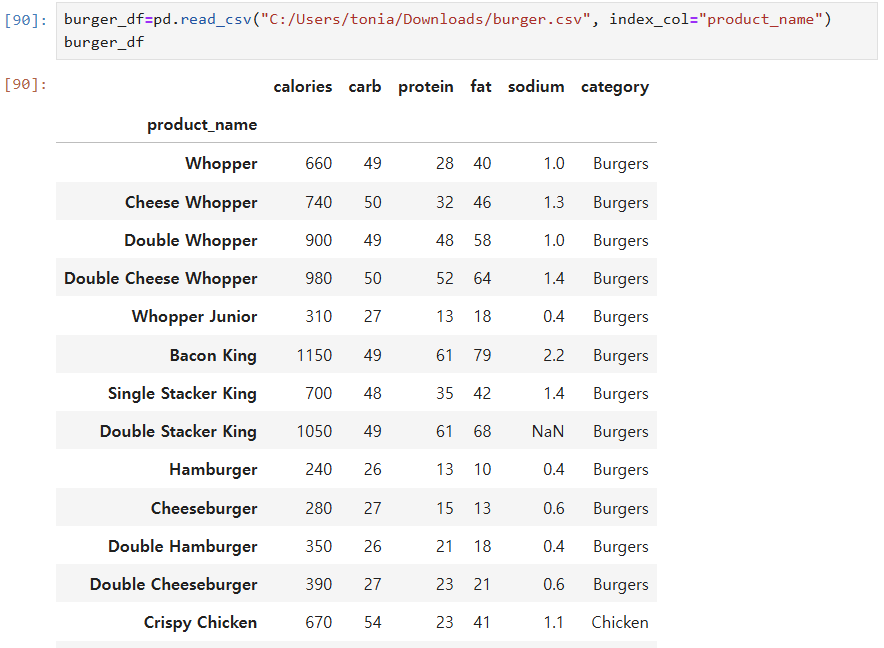
- 특정 칼럼 이름을 인덱스로 사용하기 : pd.read_csv(' / /csv파일 경로.csv, index_col="product_name")
03 일부 데이터만 가져오기
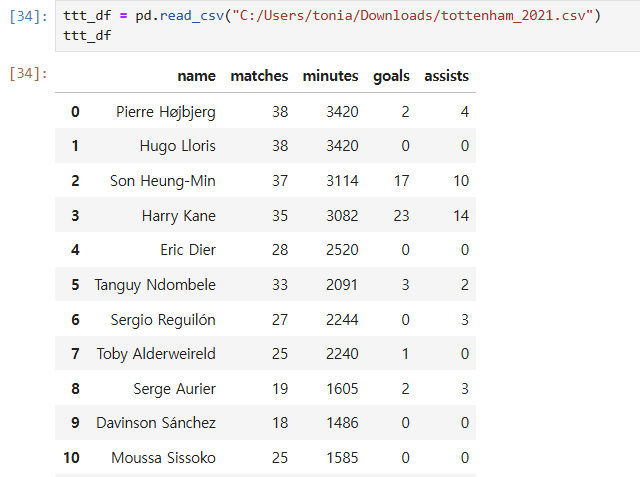
만약 이런 그래프에서....
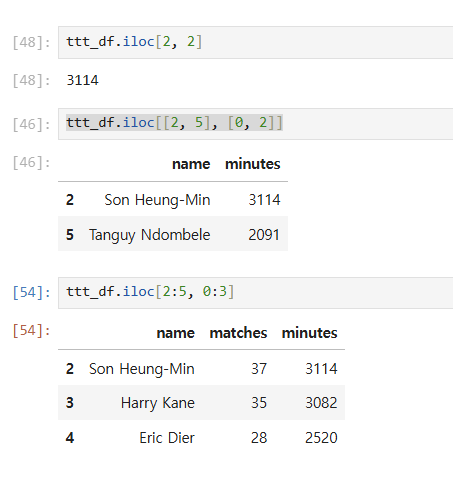
(1) iloc
loc = location, 즉 위치값으로 데이터를 불러오는데 그 중에서 정수(i)값으로 불러온다. 대괄호 안에 세로열을 먼저 쓰고, 가로행을 쓴다. 그 정수 값들은 여러개를 리스트처럼 넣거나, 시리즈로 넣을수 있으며 그러면 또다른 데이터프레임 모양으로 만들어진다.
(2) loc
이름을 통해서 원하는 값을 추출하는 법.
이름을 잘 지어놨다면 이것이 훨씬 편하다. 각 행열이 몇번째인지 세볼필요가 없으니까. 이름을 가지고 슬라이싱도 가능하다.
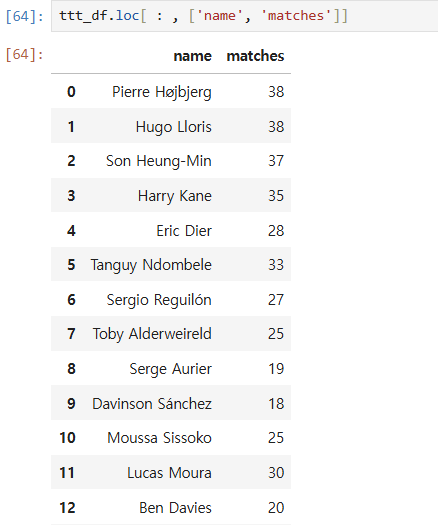
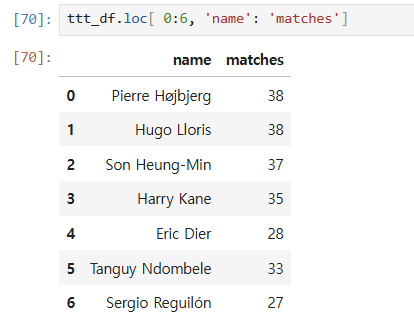
(3) 그냥 대괄호 사용하기
참고) 전체를 선택하고 싶을땐 loc, iloc 모두 : 사용하기
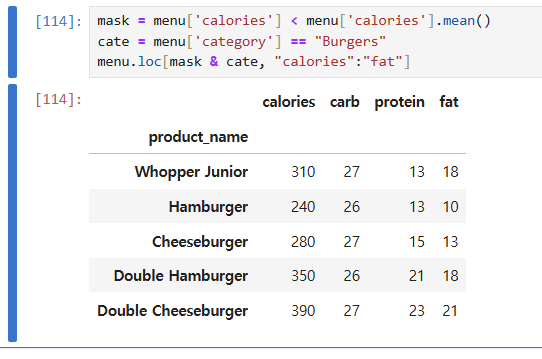
04 (중요) 불린 인덱싱
넘파이랑 비슷하다
- 데이터 프레임에 불린을 붙이면 t/f로 된 또다른 데이터프레임/시리즈가 만들진다.
- loc을 하고 []안에 불린을 넣으면 이에 true인 항목들만 인덱싱된다
- 그리고 그 불린은 주로 mask라는 개체로 만들어서 사용한다.