

1. 기초 통계기법 분류
(1) 회귀 (Regression)
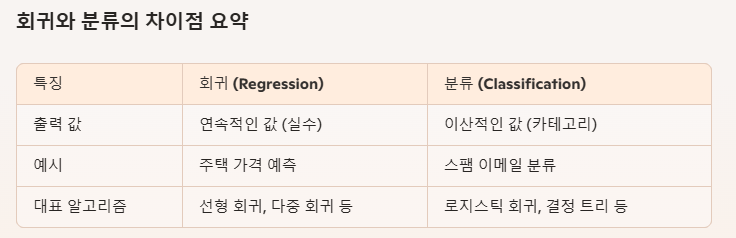
회귀는 연속적인 값을 예측하는 데 사용되는 통계 기법입니다. 예를 들어, 집의 크기와 가격 데이터를 가지고, 새로운 집의 크기를 입력받아 그 집의 가격을 예측하는 문제에 사용됩니다.
주요 특징:
- 연속적인 출력 값: 예측 결과가 실수 또는 연속적인 값으로 나타납니다.
대표적인 알고리즘:
- 선형 회귀(Linear Regression)
- 다중 회귀(Multiple Regression)
- 리지 회귀(Ridge Regression)
예시:
- 주택 가격 예측
- 주식 가격 예측
- 날씨 예측
(2) 분류 (Classification)
분류는 주어진 입력 데이터를 특정한 카테고리나 클래스에 할당하는 문제입니다. 예를 들어, 이메일 데이터를 가지고 그 이메일이 스팸인지 아닌지를 분류하는 문제에 사용됩니다.
주요 특징:
이산적인 출력 값: 예측 결과가 특정 카테고리 또는 클래스(예: 스팸 또는 비스팸)로 나타납니다.
대표적인 알고리즘:
- 로지스틱 회귀(Logistic Regression)
- 결정 트리(Decision Tree)
- 서포트 벡터 머신(SVM)
- k-최근접 이웃(k-Nearest Neighbors, k-NN)
예시:
- 스팸 이메일 분류
- 이미지 속 객체 인식 (예: 고양이, 개, 자동차 등)
- 질병 진단 (예: 특정 질병의 유무)
(3) 랭킹
랭킹은 항목을 중요도, 관련성, 또는 특정 기준에 따라 순서대로 정렬하는 문제입니다. 예를 들어, 검색 엔진에서 사용자가 입력한 검색어에 가장 관련성이 높은 문서를 상위에 노출시키는 것이 랭킹 문제입니다.
주요 특징:
- 순서 결정: 항목들 사이의 상대적인 순서를 결정합니다.
- 점수화: 각 항목에 점수를 부여하여 순위를 매깁니다.
대표적인 알고리즘:
- PageRank:구글의 검색 엔진 알고리즘으로, 웹페이지의 중요도를 평가하여 순위를 매기는 방법
- Learning to Rank: 머신러닝 기법을 사용하여 항목들의 순서를 학습
Pointwise Approach: 각 항목의 점수를 독립적으로 예측하여 순위를 매기는 방법.
Pairwise Approach: 두 항목을 비교하여 어느 쪽이 더 높은 순위인지 학습하는 방법.
* Listwise Approach: 전체 목록을 학습하여 순서를 예측하는 방법.
예시:
- 검색 엔진 결과: 검색어에 대해 가장 관련성이 높은 문서를 상위에 표시.
- 추천 시스템: 사용자가 선호할 만한 아이템을 순서대로 추천.
- 순위 결정: 스포츠 팀의 순위를 매기거나, 영화의 순위를 결정.
2. Predict Modeling Techniques
(1) Decision Tree
Decision Tree(결정 트리)는 데이터의 특징을 기준으로 의사 결정을 내려 결과를 예측하는 모델입니다. 트리의 각 노드는 질문(또는 조건)을 나타내며, 각 가지(branch)는 해당 질문에 따른 답변(또는 조건의 결과)로 이어집니다. 최종적으로 잎 노드(leaf node)에서 예측 결과를 얻을 수 있습니다.
장점: 텍스트
- 해석 용이성: 직관적으로 이해하기 쉬운 구조를 가집니다.
- 특징 선택 자동화: 가장 중요한 특징을 자동으로 선택해줍니다.
(2) Ensemble Learning
Ensemble Learning(앙상블 학습)은 여러 개의 모델을 결합하여 하나의 예측 결과를 도출하는 방법입니다. 앙상블 학습은 개별 모델의 약점을 보완하고 예측 성능을 향상시킬 수 있습니다.
주요 방법:
-
Bagging: 같은 알고리즘을 여러 번 사용하여 학습 데이터를 무작위로 추출해 다수의 모델을 학습시키고, 결과를 평균 내는 방법입니다. 대표적인 예로 랜덤 포레스트(Random Forest)가 있습니다.
-
Boosting: 직전 모델의 오류를 보완하는 방식으로, 순차적으로 모델을 학습시켜 예측 성능을 향상시키는 방법입니다. 대표적인 예로 AdaBoost, Gradient Boosting, XGBoost가 있습니다.
(3) Boosting이란?
Boosting(부스팅)은 앙상블 학습의 일종으로, 약한 학습기(weak learner)를 순차적으로 학습시켜 강한 학습기(strong learner)를 만드는 방법입니다. 각 단계에서 이전 모델의 오류를 보완하는 방식으로 학습합니다.
(4) Gradient Boosting이란?
Gradient Boosting(그래디언트 부스팅)은 Boosting 기법의 하나로, 손실 함수(Loss Function)를 최소화하기 위해 각 단계에서 그레디언트(gradient, 기울기)를 이용해 모델을 학습시킵니다. 각 모델은 이전 모델의 오류를 줄이기 위해 학습하며, 최종 모델은 모든 모델의 결과를 결합하여 예측을 수행합니다.
주요 단계:
1) 초기 모델을 학습시킵니다.
2) 이전 모델의 오류를 분석하여 새로운 모델을 학습시킵니다.
3) 이 과정을 반복하여 최종 모델을 만듭니다.
3. ML 핵심 개념 1) 데이터 전처리와 관리
(1) 데이터 분할 (Data Splitting)
데이터를 학습 세트, 검증 세트, 테스트 세트로 나누는 것은 머신러닝에서 매우 중요한 단계입니다.
주로 60-80 / 10-20 / 10-20 으로 분할함
학습 세트 (Training Set):
모델을 학습시키는 데 사용되는 데이터입니다. 모델의 가중치나 파라미터를 조정하여 최적의 성능을 내도록 학습시킵니다. 충분히 많은 데이터를 포함하여 모델이 다양한 패턴을 학습할 수 있도록 해야 합니다.
검증 세트 (Validation Set):
학습 과정 중 모델의 성능을 평가하고, 하이퍼파라미터를 튜닝하는 데 사용되는 데이터입니다. 학습 세트와는 별도로, 모델이 새로운 데이터에 대해 얼마나 잘 일반화할 수 있는지 평가합니다.
테스트 세트 (Test Set):
최종적으로 모델의 성능을 검증하기 위해 사용되는 데이터입니다. 학습과 검증 과정에서 전혀 사용되지 않은 데이터여야 하며, 최종 모델의 일반화 성능을 평가합니다
(2) 결측값 관리 (Handling Missing Values)
데이터셋에서 누락된 값들을 적절히 처리.
(3) 희소 행렬과 희소성 인식
희소 행렬(Sparse Matrix): 대부분의 요소가 0인 행렬.
예: 인기없는 우리 동네 도서관. 베스트셀러 도서를 제외하고는 빌려가는 사람이 한명도 없었다. 이 경우 베스트셀러르르 제외하고 대부분 채들의 대출기록 데이터는 0이다.
Sparsity Awareness(희소성 인식)
모델이 희소한 데이터 구조를 효과적으로 처리할 수 있도록 설계된 기능으로 이를 통해 메모리와 연산시간을 절약할 수 있다.
Sparsity Awareness의 주요 특징
-
효율적인 메모리 사용: 대부분의 값이 0인 희소 행렬을 저장할 때, 0이 아닌 값만 저장함으로써 메모리 사용을 최적화합니다. 이는 큰 데이터셋을 다룰 때 매우 유용합니다.
-
빠른 연산 속도: 0이 아닌 값만을 이용하여 연산을 수행하므로, 불필요한 연산을 줄여 계산 속도를 향상시킵니다. 이는 모델이 더욱 빠르게 학습하고 예측할 수 있게 합니다.
-
희소 데이터 구조 지원: 다양한 희소 데이터 구조(Coordinate List, Compressed Sparse Row, Compressed Sparse Column 등)를 지원하여, 데이터 접근과 처리가 용이합니다.
3. ML 핵심 개념 2) 모델의 성능 평가와 최적화
(1) 손실 함수
손실 함수(Loss Function)는 모델이 예측한 값과 실제 값 사이의 차이를 측정하는 데 사용되는 함수입니다. 이를 "오류값" 또는 "로스"라고도 합니다. 손실 함수는 모델이 얼마나 잘 예측하고 있는지를 평가하는 중요한 척도입니다. 최적화의 목표로 사용되는 함수입니다.
손실 함수의 역할
-
오류 측정: 손실 함수는 모델의 예측 값과 실제 값 사이의 차이를 수량화합니다. 이 차이는 예측이 얼마나 잘못되었는지를 나타내는 지표입니다.
-
모델 최적화: 손실 함수를 최소화하는 방향으로 모델의 매개변수를 조정 합니다. 즉, 손실 함수 값이 작을수록 모델의 예측이 실제 값에 가깝다는 것을 의미합니다.
-
Gradient Boosting: Gradient Boosting에서는 각 단계에서 손실 함수의 그라디언트(기울기)를 계산하여 모델의 매개변수를 업데이트합니다. 이렇게 함으로써 모델의 예측 성능을 점진적으로 향상시킵니다.
손실 함수의 종류
-
Mean Squared Error (MSE): 회귀 문제에서 자주 사용되며, 예측 값과 실제 값의 차이의 제곱을 평균한 값입니다.
-
Cross-Entropy Loss: 분류 문제에서 자주 사용되며, 예측 확률과 실제 클래스 간의 차이를 측정합니다.
로스의 반대말: 정답지, ground truth
(2) 과적합과 정규화
과적합:
과적합은 모델이 학습 데이터에 너무 잘 맞춰져서 새로운 데이터에 대해 일반화하지 못하는 현상을 말합니다. 이는 모델이 학습 데이터의 잡음(noise)까지 학습하게 되어 발생합니다.
과적합의 특징:
- 학습 데이터에 대한 높은 성능: 학습 데이터에 대해서는 매우 높은 정확도를 보입니다.
- 새로운 데이터에 대한 낮은 성능: 새로운 데이터나 테스트 데이터에 대해서는 예측 성능이 낮아집니다.
과적합을 방지하는 방법:
-
정규화 (Regularization): 모델의 복잡도를 줄이기 위해 패널티 항(term)을 추가합니다.
-
교차 검증 (Cross-Validation): 데이터를 여러 부분으로 나누어 모델을 검증합니다.
-
더 많은 데이터 수집: 더 많은 데이터를 수집하여 모델이 일반적인 패턴을 학습할 수 있도록 합니다.
-
드롭아웃 (Dropout): 신경망에서 일부 뉴런을 임의로 제외하여 과적합을 방지합니다.
정규화(보통화, 일반화):
정규화는 모델의 복잡도를 줄여 과적합을 방지하는 기법입니다. 정규화는 모델의 가중치에 패널티 항을 추가하여 과도한 학습을 방지합니다.
주요 정규화 기법:
-
L1 정규화: 모델의 가중치의 절대값 합에 패널티를 부과하여(제한을 두어) 가중치가 너무 커지지 않도록 제한을 두는 방법.
- 비유 : 음식점 가게 주인이 재료값의 제한을 걸어두는 것. 제한이 없으면 너무 재료를 비싸게 사게 되거나, 사실 꼭 필요하지는 않은 재료들까지 다 사게 될 수 있다.- 효과 1: 불필요한 변수 제거: 가중치 절대값 합에 제한을 두면 불필요한 변수들의 가중치가 점점 더 작아져 결국 0이 되거나 무시할 수 있는 수준으로 낮아집니다. 이는 모델에서 중요하지 않은 변수를 자동으로 제거하는 효과를 줍니다.
- 효과 2: 과도한 가중치 감소: 너무 큰 가중치를 가지는 요소들의 가중치도 낮아져 모델이 과적합되는 것을 방지할 수 있습니다. 이는 모델의 복잡도를 줄이고, 일반화 성능을 향상시키는 데 도움을 줍니다.
- Lasso Regression: L1 정규화를 사용하는 회귀 방법입니다.
-
L2 정규화: 모델의 가중치의 제곱 합에 패널티를 부과합니다.(제한을 줍니다) 이는 L1보다 더 부드럽게 가중치들을 작게/단순하게 만들어 모델의 복잡도를 줄입니다.
- L2는 가중치가 미미한 요소들의 가중치를 완전히 0이 되기보다는 작은 값을 만드는 부드러운 규제 / L1은 많은 가중치들을 아예 0으로 만들어 불필요한 변수를 완전히 제거하여 희소성 촉진에 효과적
- L2는 제곱합의 기반하기에 큰 가중치는 더 많이 줄이고, 작은 가중치는 상대적으로 덜 줄이는 효과 / L1은 절대값의 합을 줄이기에 불필요한 변수들이 아예 삭제되어 변수를 선택하는 기능을 합니다.
- Ridge Regression: L2 정규화를 사용하는 회귀 방법입니다.
- Elastic Net: L1과 L2 정규화를 결합하여 사용하는 방법입니다. 이는 두 기법의 장점을 모두 활용할 수 있습니다.
3. ML 핵심 개념 3) 모델의 하이퍼파라미터 조정과 검증
(1) 하이퍼파라미터 (Hyperparameter)
하이퍼파라미터는 모델 학습 과정에서 (특히 본격적인 학습 전에) 사용자가 직접 설정해야 하는 매개변수입니다. 이는 모델이 학습하는 동안 최적화되는 매개변수와는 다릅니다.
비교
하이퍼파라미터: 학습 전에 설정되는 값들로, 요리사가 처음 계획으로 세우는 레시피의 각 요소들(재료를 몇가지 얼마큼씩 쓸까, 소금을 얼마나 넣을까, 어떤 세기의 불에서 몇분을 끓일까, 등)과 비슷합니다.
최적화되는 매개변수: 학습 중에 데이터에 따라 조정되는 값들로, 요리사가 맛을 보며 재료를 조정하는 것과 비슷합니다. 가장 대표적인 것으로 모델이 학습을 하며 찾아가게되는 가중치가 있습니다.
주요 하이퍼파라미터
-
학습률 (Learning Rate): 학습 과정에서 모델의 가중치를 업데이트하는 크기를 결정합니다. 너무 크면 모델이 최적점을 지나칠 수 있고, 너무 작으면 학습이 매우 느려집니다.
-
최대 깊이 (Max Depth): 트리 모델에서 트리의 최대 깊이를 결정합니다. 깊이가 깊을수록 모델이 복잡해져 과적합될 수 있습니다.
-
정규화 계수 (Lambda): 모델의 복잡도를 제어하여 과적합을 방지하는 정규화 항의 강도를 설정합니다.
-
트리 수 (Number of Trees): 앙상블 방법에서 생성할 트리의 개수를 결정합니다. 너무 많으면 과적합될 수 있습니다.
-
샘플링 비율 (Subsample): 학습 데이터를 샘플링하여 사용합니다. 전체 데이터를 사용하면 과적합될 수 있으므로 일부 데이터를 사용하여 학습합니다.
하이퍼파라미터 튜닝 방법
-
그리드 탐색 (Grid Search): 가능한 하이퍼파라미터 값들의 모든 조합을 시도하여 최적의 조합을 찾습니다. 매우 계산 비용이 높지만, 최적의 결과를 얻을 수 있습니다.
-
랜덤 탐색 (Random Search): 하이퍼파라미터 공간에서 무작위로 값을 선택하여 최적의 조합을 찾습니다. 그리드 탐색보다 계산 비용이 적습니다.
-
베이지안 최적화 (Bayesian Optimization): 이전 시도 결과를 바탕으로 다음 시도할 하이퍼파라미터를 선택하여 더 효율적으로 최적의 조합을 찾습니다.
(2) 교차검증 (Cross-Validation)
교차 검증은 데이터를 여러 부분으로 나누어 모델을 검증하는 방법으로, 모델의 일반화 성능을 평가하는 데 사용됩니다.
주요 방법
-
K-폴드 교차 검증 (K-Fold Cross-Validation):
데이터를 K개의 폴드(fold)로 나누고, 각 폴드에 대해 모델을 학습한 후 나머지 폴드로 검증합니다. K번 반복하여 모든 폴드가 한 번씩 검증 세트가 되도록 합니다. 최종 결과는 K번의 검증 결과의 평균으로 나타냅니다. -
스트래티파이드 K-폴드 (Stratified K-Fold):
K-폴드 교차 검증과 비슷하지만, 각 폴드가 클래스 비율을 유지하도록 데이터셋을 나눕니다. 불균형한 데이터셋에서 유용합니다. -
LOO (Leave-One-Out Cross-Validation):
데이터셋의 각 샘플을 한 번씩 검증 세트로 사용하고, 나머지 샘플들로 모델을 학습합니다. 데이터셋이 작을 때 사용하지만, 계산 비용이 매우 높습니다.
교차 검증의 장점
-
모델 평가: 모델이 새로운 데이터에 대해 얼마나 잘 일반화될 수 있는지 평가할 수 있습니다.
-
과적합 방지: 데이터를 여러 번 나누어 사용하므로 과적합을 방지할 수 있습니다.
-
하이퍼파라미터 튜닝: 교차 검증을 통해 하이퍼파라미터를 최적화하는 데 사용됩니다.
데이터 분할과 교차검증?
데이터 분할은 내가 가진 데이터 전체를 3가지 용도(학습, 검증, 테스트)로 잘 나눠야한다는 개념
3가지로 나눠진 각각의 데이터 셋 내에서
또 여러부분으로 나눠서 이를 교차검증하는 것이
하이퍼파라미터를 튜닝하거나 일반성 성능 평가하는데 필요하다!
4. XGBoost란?
정의
XGBoost(Extreme Gradient Boosting)는 고성능의 머신러닝 알고리즘 라이브러리로, 특히 예측 성능이 뛰어나고 학습 속도가 빠릅니다. XGBoost는 다양한 데이터 과학 경진대회에서 많이 사용되는 알고리즘이기도 합니다.
XGBoost는 Decision Tree를 기반으로 하고, Gradient Boosting 방법을 사용하여 모델을 학습합니다.
주요 장점
(1) 빠른 학습 속도
- 병렬처리: 여러 CPU 코어를 사용하여 트리 분할 작업을 병렬로 수행함으로써 학습시간을 단축한다. 즉, CPU를 보다 효율적으로 사용하는 것!
- 하드웨어 최적화: XGBoost는 하드웨어 최적화를 통해 데이터 접근을 빠르게 처리합니다. 이는 주로 CPU 캐시와 메모리 사용을 최적화하여 이루어집니다.
- 분산학습 : 분산 학습은 대규모 데이터셋을 다루기 위해 여러 대의 컴퓨터에서 데이터를 분산 처리하여 학습하는 방법입니다. 이를 위해 대표적으로 Apache Spark와 Hadoop 같은 플랫폼을 사용합니다.
(2) 모델 최적화
-
과적합 방지: 정규화(Regularization)를 통해 과적합을 효과적으로 방지합니다.
-
Sparsity Awareness: XGBoost는 희소 행렬(즉, 대부분의 값이 0인 행렬)을 효과적으로 처리할 수 있습니다. 이는 데이터 전처리와 모델 학습을 더욱 효율적으로 만듭니다.
-
Tree Pruning (트리 가지치기)
최대 깊이의 제한: XGBoost는 최대 트리 깊이를 제한하고, 가지치기(pruning) 기법을 통해 불필요한 분기를 제거합니다. 이는 모델의 복잡도를 줄이고, 학습 및 예측 속도를 향상시킵니다. -
Learning Rate (학습률) 조정
학습률 최적화: XGBoost는 학습률을 조정하여 모델의 예측 성능을 더욱 향상시킵니다. 이는 모델이 과도하게 학습되지 않도록 조절하는 데 도움이 됩니다. -
Handling Missing Values (결측값 처리)
결측값 처리: XGBoost는 데이터셋에서 결측값(값이 기록되지 않은 부분)을 효과적으로 처리할 수 있습니다. 이는 데이터 전처리 단계를 단순화하고, 더 많은 데이터를 활용할 수 있게 합니다. 삭제 / 대체 / 특수값 처리 등...
(3) 유연성
회귀, 분류, 랭킹 등 다양한 문제에 적용할 수 있습니다.
주요 개념/기능
(1) Tree Booster:
Tree Booster는 XGBoost의 핵심 구성 요소로, Decision Tree를 기반으로 하는 모델을 생성합니다.
이를 통해 데이터를 분할하고 예측하는 데 사용됩니다.
(2) Objective Function:
Objective Function은 모델이 최적화하려는 목표를 정의합니다.
일반적으로 손실 함수(Loss Function)와 정규화 항(Regularization Term)으로 구성됩니다.
예를 들어, 회귀 문제에서는 평균 제곱 오차(MSE)가 손실 함수로 사용될 수 있습니다.
(3) Evaluation Metrics:
Evaluation Metrics는 모델의 성능을 평가하는 데 사용됩니다.
대표적인 예로 정확도(Accuracy), F1 점수(F1 Score), 평균 제곱 오차(MSE) 등이 있습니다.
(4) Hyperparameter Tuning:
Hyperparameter Tuning은 모델의 성능을 최적화하기 위해 하이퍼파라미터를 조정하는 과정입니다.
XGBoost에서 중요한 하이퍼파라미터로는 학습률(Learning Rate), 최대 깊이(Max Depth), 정규화 계수(Lambda) 등이 있습니다.
(5) 기타기능
-
Early Stopping: 조기 종료 기법을 사용하여 더 이상 성능이 향상되지 않으면 학습을 중단합니다.
-
Feature Importance: 모델에서 중요한 특징을 식별하여, 어떤 특징이 예측에 가장 큰 영향을 미치는지 알 수 있습니다.
-
Cross-validation: 데이터를 여러 부분으로 나누어 모델을 검증하고, 최적의 모델을 선택하는 데 사용됩니다.
5. XGBoost 사용방법
(1) DXMatrix 생성
DMatrix는 XGBoost에서 사용되는 데이터 구조로, 효율적인 모델 훈련과 예측을 위해 설계되었습니다. DMatrix는 주로 다음과 같은 역할을 합니다:
-
효율적인 메모리 사용: DMatrix는 메모리를 효율적으로 사용하여 큰 데이터셋을 다룰 때도 성능을 유지합니다. 이는 내부적으로 압축된 데이터 구조를 사용하기 때문입니다.
-
빠른 데이터 로드 및 처리: DMatrix는 다양한 데이터 형식을 빠르게 로드하고 처리할 수 있습니다. 예를 들어, CSV 파일이나 Pandas DataFrame을 직접 로드할 수 있습니다.
-
성능 최적화: DMatrix는 XGBoost의 핵심 연산을 최적화하여 모델 훈련과 예측 속도를 높입니다. 이는 스파스 매트릭스(sparse matrix)와 같은 고급 데이터 구조를 사용함으로써 가능해집니다.
DXMatrix 예제
Pandas DataFrame을 사용하여 데이터셋을 DMatrix로 변환/생성하는 예제입니다:
# 판다스
import xgboost as xgb
import pandas as pd
# 데이터 로드
data = pd.read_csv('your_data.csv')
X = data.iloc[:, :-1] # 입력 변수
y = data.iloc[:, -1] # 타겟 변수
# DMatrix 생성
dtrain = xgb.DMatrix(data=X, label=y)
-
입력 변수 (Input Variables): 모델이 학습할 때 사용하는 데이터의 독립 변수입니다. 이 변수들은 예측하려는 결과에 영향을 미치는 요소들입니다. 예를 들어, 주택 가격 예측 모델에서는 방 개수, 면적, 위치 등이 입력 변수가 될 수 있습니다.
-
타겟 변수 (Target Variable): 모델이 예측하려는 결과 값입니다. 이는 종속 변수로도 불리며, 입력 변수를 기반으로 예측해야 하는 값입니다. 주택 가격 예측 모델에서는 실제 주택 가격이 타겟 변수가 됩니다.
-
dtrain: XGBoost에서 학습에 사용될 데이터 객체로, dtrain은 훈련 데이터셋을 의미합니다.
-xgb.DMatrix: XGBoost에서 제공하는 데이터 구조로, 메모리 효율성을 높이고 빠른 처리를 가능하게 합니다.- data=X: 입력 변수를 지정합니다. X는 독립 변수들의 데이터프레임입니다.
- label=y: 타겟 변수를 지정합니다. y는 종속 변수(예측하려는 값)입니다
(2) 모델 파라미터 설정
params = {
'objective': 'reg:squarederror',
'max_depth': 6,
'learning_rate': 0.1,
'n_estimators': 100
}
- params: XGBoost 모델의 하이퍼파라미터를 설정하는 딕셔너리입니다.
- 'objective': 모델의 학습 목표를 설정합니다.
ㅇ 'reg:squarederror'는 회귀 문제를 의미하며, 제곱 오차 손실 함수를 최소화하려는 목표를 갖습니다.
ㅇ 그 외:

-
'max_depth': 각 결정 트리의 최대 깊이를 설정합니다. 깊이가 클수록 모델이 복잡해질 수 있지만, 과적합(overfitting) 위험이 증가할 수 있습니다. 여기서는 6으로 설정했습니다.
-
'learning_rate': 학습률을 의미합니다. 각 트리가 모델에 기여하는 비율을 조정합니다. 값이 작을수록 학습이 천천히 진행되지만, 일반화 성능이 높아질 수 있습니다. 여기서는 0.1로 설정했습니다.
-
'n_estimators': XGBoost 모델에서 생성할 결정 트리의 개수를 나타냅니다. 각 트리는 데이터를 분석하여 예측 모델을 개선하는 역할을 합니다. 일반적으로, 더 많은 트리를 생성할수록 모델의 성능이 좋아질 수 있지만, 학습 시간이 길어지고 과적합의 위험이 증가할 수 있습니다.여기서는 100으로 설정했습니다.
(3) 모델 훈련
model = xgb.train(params, dtrain, num_boost_round=100)
-
model: 훈련된 XGBoost 모델 객체를 저장합니다.
-
xgb.train: XGBoost 라이브러리의 함수로, 모델을 훈련시키는 역할을 합니다.
-
params: 모델 훈련에 사용할 파라미터들을 포함한 딕셔너리입니다. 예를 들어, objective, max_depth, learning_rate 등이 포함됩니다.
-
dtrain: 훈련 데이터가 담긴 DMatrix 객체입니다.
-
num_boost_round=100: 부스팅 라운드(트리)의 수를 설정합니다. 총 100개의 트리가 생성되어 모델을 훈련하게 됩니다. (파라미터의 n_estimators와 유사한 개념. 둘을 동시에 지정하는 것 지양)
(4) 모델 저장
model.save_model("xgboost_model.json")
-
model.save_model: 훈련된 모델을 파일로 저장하는 메서드입니다.
-
"xgboost_model.json": 모델이 저장될 파일의 이름입니다. JSON 형식으로 저장됩니다. 나중에 이 파일을 불러와서 모델을 재사용할 수 있습니다.
(5) 응답 반환
return {"info": "model trained and saved"}
- return {"info": "model trained and saved"}: 훈련이 완료된 후, 클라이언트에게 모델이 성공적으로 훈련되고 저장되었다는 정보를 JSON 형태로 반환합니다.
6. FastAPI와 함께 사용하기
from fastapi import FastAPI, File, UploadFile, HTTPException
import pandas as pd
import xgboost as xgb
import os
app = FastAPI()
# 상수 정의
UPLOAD_DIR = 'dataset_uploaded'
MODEL_FILE = 'xgboost_model.json'
uploaded_files = []
# 디렉토리가 존재하지 않으면 생성
if not os.path.exists(UPLOAD_DIR):
os.makedirs(UPLOAD_DIR)
# 1. 학습용 데이터 셋 업로드
@app.post("/train-data-upload")
async def train_data_upload(file: UploadFile = File(...)):
try:
file_location = os.path.join(UPLOAD_DIR, file.filename)
with open(file_location, "wb") as f:
f.write(await file.read())
uploaded_files.append(file.filename)
return {"info": f"file '{file.filename}' saved at '{file_location}'"}
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error uploading file: {e}")
# 1.1 업로드 된 학습용 데이터 셋 확인하기
@app.get("/uploaded-files")
async def get_uploaded_files():
return {"uploaded_files": uploaded_files}
# 2. XGBoost 모델 훈련시켜서 탑재하기
@app.post("/train-model")
async def train_model(file: UploadFile = File(...)):
try:
file_location = os.path.join(UPLOAD_DIR, file.filename)
with open(file_location, "wb") as f:
f.write(await file.read())
data = pd.read_csv(file_location, delimiter=';') # 데이터 로드 (tip! 세미콜론 구분)
X = data.iloc[:, :-1] # 입력 변수
y = data.iloc[:, -1] # 타겟 변수
dtrain = xgb.DMatrix(data=X, label=y) # DMatrix 설정
params = { # 파라미터 설정
'objective': 'reg:squarederror',
'max_depth': 6,
'learning_rate': 0.1,
}
model = xgb.train(params, dtrain, num_boost_round=100) # 모델 훈련
model.save_model(MODEL_FILE) # 모델 저장
return {"info": "model trained and saved"} # 응답 반환
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error training model: {e}")
# 3. 예측 엔드포인트 설정
@app.post("/predict")
async def predict(file: UploadFile = File(...)):
try:
file_location = os.path.join(UPLOAD_DIR, file.filename)
with open(file_location, "wb") as f:
f.write(await file.read()) # 새로운 입력값 읽고 저장
data = pd.read_csv(file_location, delimiter=';') # tip! 세미콜론 구분자 사용
dtest = xgb.DMatrix(data=data) # 새로운 입력값을 훈련데이터 삼아서
model = xgb.Booster() # xgbooster로 이번 예측에 사용할 (위에서 만든) 모델 불러오기
model.load_model(MODEL_FILE)
predictions = model.predict(dtest) # 예측값 반환
return {"predictions": predictions.tolist()}
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error making prediction: {e}")
DataFrame & CSV & JSON
데이터를 다루는 서로다른 방식!
1) DataFrame
DataFrame은 판다스에서 사용하는 데이터 구조로, 테이블 형태로 데이터를 다룹니다. 행(Row)과 열(Column)로 구성되어 있으며, 다양한 데이터 타입을 지원합니다.
import pandas as pd
# 데이터 생성
data = {
"Name": ["Alice", "Bob", "Charlie"],
"Age": [25, 30, 35],
"City": ["Seoul", "Busan", "Incheon"]
}
# DataFrame 생성
df = pd.DataFrame(data)
# DataFrame 출력
print(df)출력
Name Age City
0 Alice 25 Seoul
1 Bob 30 Busan
2 Charlie 35 Incheon
2) CSV (Comma-Separated Values)
CSV 파일은 쉼표로 구분된 값을 사용하여 데이터를 저장하는 형식입니다. 데이터는 행과 열로 구성된 텍스트 파일로 저장됩니다.
Name,Age,City
Alice,25,Seoul
Bob,30,Busan
Charlie,35,Incheon
3) JSON (JavaScript Object Notation)
JSON 파일은 키-값 쌍으로 구성된 데이터를 저장하는 형식입니다. 계층적 구조를 가지며, 데이터는 중첩될 수 있습니다.
[
{
"Name": "Alice",
"Age": 25,
"City": "Seoul"
},
{
"Name": "Bob",
"Age": 30,
"City": "Busan"
},
{
"Name": "Charlie",
"Age": 35,
"City": "Incheon"
}
]
4) CSC, JSON을 DATAFRAME로 바꾸기
CSV를 DATAFRAME으로 바꾸기
CSV 파일을 읽어들일 때는 pandas 라이브러리의 read_csv 함수를 사용하여 쉽게 DataFrame으로 변환할 수 있습니다. 이 명령어는 CSV 파일의 내용을 자동으로 판다스 DataFrame으로 변환합니다.:
data = pd.read_csv(file_location, delimiter=',')
delimiter 변수를 ; 등으로 바꾸면 구분자를 바꿀 수 있다.
JSON을 DATAFRAME으로 바꾸기
JSON 파일을 처리할 때는 json 라이브러리의 loads 함수를 사용하여 JSON 문자열을 파이썬 딕셔너리(중괄호 {}로 관리되는 파이썬의 키-값쌍 자료구조)로 변환한 후, 이를 DataFrame으로 변환해야 합니다. JSON 파일을 읽을 때는 다음과 같은 절차를 따릅니다:
(1) 파일의 내용을 읽어 JSON 문자열로 가져옵니다:
file_contents = file.read()(2) JSON 문자열을 파이썬 딕셔너리로 변환합니다:
data = json.loads(file_contents)(3) 파이썬 딕셔너리를 판다스 DataFrame으로 변환합니다:
df = pd.DataFrame(data)5) enable_categorical=True
6) 비동기식 프로그래밍 전환
이와 같은 오류가 발생하는 이유: JSON 파싱을 수행하려 할 때 file.read()의 결과가 비동기식 코루틴 객체이기 때문에 발생한 것입니다.
"detail": "Error making prediction: the JSON object must be str, bytes or bytearray, not coroutine"- 동기식(Synchronous): 작업이 순차적으로 수행되며, 한 작업이 완료될 때까지 다음 작업을 시작하지 않습니다.
- 비동기식(Asynchronous): 작업이 동시에 수행될 수 있으며, 다른 작업의 완료를 기다리지 않습니다.
- 비동기식 프로그래밍과 코루틴: 비동기식 프로그래밍에서는 특정 작업을 수행하기 위해 await 키워드를 사용하여 작업이 완료될 때까지 기다립니다. 코루틴(coroutine)은 이러한 비동기 작업을 지원하는 함수나 객체입니다.
# 예시: 비동기식 파일 읽기
file_contents = await file.read()
7) 스칼라와 벡터, 인덱스를 명시적으로 지정하기
CURL 명령어
