군대에서 책 위주로 코딩 공부를 하며 작성한 글입니다.
개인 컴퓨터를 사용할 수 없어 컴파일은 in-browser IDE인 repl.it를 사용하였습니다.
C와 Java 비교 : 리터럴을 넣을 때
리터럴(literal) : 값 그 자체
ex)1,3.0e8,"ABC"
cf) 상수(constant) : 값을 한 번 저장하면 변경할 수 없는 저장공간
리터럴의 타입은 저장될 변수의 타입과 일치하는 것이 보통이지만, 타입이 달라도 저장범위가 넓은 타입에 좁은 타입의 값을 저장하는 것은 허용된다.
// JAVA
int i = 'A'; // OK. int(4bytes) > char(2bytes)
long l = 123; // OK. long(8bytes) > int(4bytes)
double d = 3.14f; // OK. double(8bytes) > float(4bytes)리터럴이 더 좁은 타입인 경우에는 C도 똑같이 작동한다. (char가 C에서는 1바이트인 것을 제외하면)
그렇다면 리터럴이 더 넓은 타입인 경우 C에서는 어떻게 컴파일되는가?
// C
int i = 2147483648; // Warning is issued, but it can be compiled.
float f = 3.14; // OK.
하지만 위의 코드를 똑같이 Java에서 작성한 경우 컴파일 에러가 발생한다.


그래서 그런지, Java를 공부하면서 C보다 자료형에 있어서만큼은 더 엄격하다는 생각이 들었다.
비유하자면 C는 int든 long이든 바이트 수만 다른 저장공간에 불과하는 것처럼 보지만, JAVA는 각 기본형들을 무려 별개의 객체로 인식해주는(당연히 객체는 아니지만) 느낌을 받았다.
묵시적 형변환과 명시적 형변환
사실 C든 Java든 대입 시 lvalue와 rvalue의 타입을 일치시키는 것이 원칙이다.
그렇게 생각한다면 위의 코드는 지양해야겠지만, 사실 불일치한다고 해서 형변환이 이루어지지 않는 것이 아니기에 안심해도 된다.
lvalue와 rvalue의 타입이 일치하지 않아도 컴파일러는 경우에 따라 생략된 형변환을 자동으로 추가하는데, 이를 묵시적 형변환(implicit type conversion)이라고 한다.
float f = 3.14;라는 같은 코드에 대해 C는 작동하고 Java는 에러를 띄우는 이유가 바로 C는 double -> float의 묵시적 형변환을 지원하지만, JAVA는 지원하지 않기 때문이다.
Java의 묵시적 형변환이 상대적으로 빡빡하게 이루어지는 이유는, 다음 규칙에서 찾아볼 수 있다.
컴파일러는 기존의 값을 최대한 보존할 수 있는 타입으로 자동 형변환한다.
즉, 좁은 타입에서 넓은 타입으로 형변환하는 경우에는 값 손실의 위험이 더 적으므로 넓은 타입으로 묵시적 형변환이 가능하지만, 반대의 경우에는 값 손실이 발생하기 때문에 JAVA에서는 자동으로 형변환이 되지 않도록 막아놓고 있다.
하지만 묵시적 형변환이 안 된다고 해서 형변환 자체가 불가능한 것은 아니다.
float f = 3.14; // Error.
float f = (float)3.14; // OK.아주 당연하게도 (float)를 이용하여 강제로 타입을 일치시켜주면 정상적으로 컴파일이 이루어지며, 이를 명시적 형변환(explicit type conversion)이라고 한다.
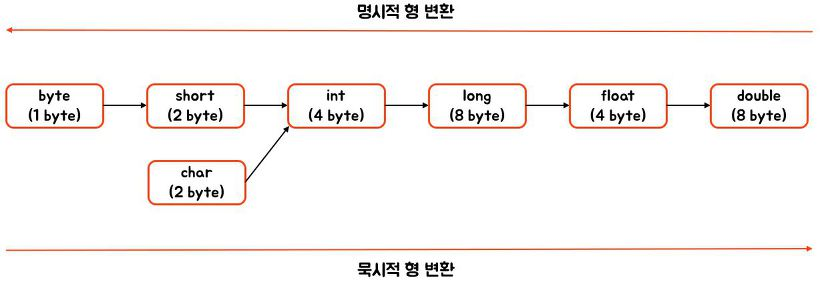
기본형의 자동 형변환이 가능한 방향은 위 그림과 같고, 반대 방향으로 형변환을 하고 싶다면 명시적 형변환을 직접 해줘야 한다.
char와 short는 둘 다 2바이트지만, char의 범위는 0~65535이고 short의 범위는 -32768~32767이므로 둘 중 어느 쪽으로의 형변환도 값 손실이 발생할 수 있으며, 따라서 자동 형변환이 수행되지 않는다. char가 unsigned short 아니냐고? 놀랍게도 Java에는 unsigned 개념이 없다!

위 그림을 보면 묵시적 형변환의 경우 데이터 손실의 우려가 없다 라고 나와 있는데, 굳이굳이 말하자면 long -> float에서는 정수에서 부동 소수점으로 저장방식이 변화하기 때문에 미미하게 수가 바뀌긴 한다. 물론 3에서 3.0000000001이 되는 것 뿐이다.
- boolean을 제외한 나머지 7개의 기본형은 서로 형변환이 가능하다.
- 기본형과 참조형은 서로 형변환할 수 없다.
2.5. 참조형은 서로 상속 관계(부모-자식)인 경우 가능.- 서로 다른 타입의 변수간의 연산은 형변환을 하는 것이 원칙이지만, 값의 범위가 작은 타입에서 큰 타입으로의 형변환은 생략할 수 있다.
일반 산술 변환
위에서는 lvalue와 rvalue의 묵시적/명시적 형변환에 대해 알아보았다면, 이번에는 이항 연산자의 두 피연산자 사이의 형변환에 대해 알아보자.
이항 연산자는 두 피연산자의 타입이 일치해야 연산이 가능하므로, 피연산자의 타입이 서로 다르다면 연산 전에 형변환 연산자로 타입을 일치시켜야 한다.
int i = 10;
float f = 20.0f;
float result = f + (float)i;대부분의 경우, 두 피연산자의 타입 중에서 더 큰 타입으로 일치시키는데, 그 이유는 작은 타입으로 형변환하면 원래의 값이 손실될 가능성이 있기 때문이다. 하지만 앞에서도 살펴보았듯이 작은 타입에서 큰 타입으로 형변환하는 경우에는 자동적으로 형변환되며, 따라서 형변환 연산자를 생략할 수 있다.
float result = f + i; // implicit conversion
int result = (int)f + i; // explicit conversion이 묵시적 형변환을 산술 변환 또는 일반 산술 변환(usual arithmetic conversion)이라고 하며, 이 변환은 이항 연산에서만 아니라 단항 연산에서도 일어난다. 하지만 쉬프트 연산자(<<, >>), 증감 연산자(++, --)는 예외다. 그러면 단항 연산이 뭐가 남는데?
일반 산술 변환의 규칙은 다음과 같다.
- 두 피연산자의 타입을 보다 큰 타입으로 일치시킨다.
ex) long + float -> float + float -> float- 피연산자의 타입이 int보다 작다면 int로 변환된다.
: int보다 작으면 오버플로우가 빈번히 발생하고 오히려 비효율적으로 처리되기 때문.
ex) char + short -> int + int -> int
쓸모없는 응용 하나, 5 / 2
Python에서는 5 / 2 = 2.5이지만, C나 JAVA에서는 5 / 2 = 2인 이유도 일반 산술 변환에서 찾아볼 수 있다.
나눗셈 연산자 / 또한 일반 산술 변환의 규칙에 해당되므로 5 / 2 -> int / int이므로 결과 역시 int로 나와야 하기 때문에 소수점은 버리고 몫만 도출하는 것이다.
쓸모없는 응용 둘, i = i + 1과 i += 1의 차이
char c = 'a';
c = c + 1; // Error.
c += 1; // OK. c = 'b'
c++; // OK. c = 'b'이제까지 같은 코드인줄 알았던 c += 1과 c = c + 1가 다른 컴파일 결과를 내놓는다는 사실이 정말 놀랍다.
원래 Java의 논리대로라면 c + 1 -> char + int -> int이고 char형 저장공간에 int를 집어넣으려 하고 있기 때문에 묵시적 형변환이 이루어지지 않아 Error를 띄우는 것이 정상적이다.
하지만 c += 1이나 c++의 경우 형변환 없이 c에 저장되어 있는 값을 1 증가시킨다! 따라서 에러가 발생하지 않는다.
c = 'a' + 1; // OK. c = 'b'하지만 위의 코드는 아주 놀랍게도 정상적으로 작동한다.
그 이유는 'a' + 1이 리터럴 간의 연산이기 때문이다. 상수 또는 리터럴 간의 연산은 실행 과정동안 변하는 값이 아니기 때문에, 컴파일 시에 컴파일러가 계산해서 그 결과를 미리 대체하여 코드를 더 효율적으로 만든다.
다시 말해, char c = 'a' + 1;은 실행 전 컴파일 상태에서 이미 char c = 'b';인 것이다!
그러나 수식에 변수가 들어가 있는 경우에는 컴파일러가 미리 계산할 수 없기 때문에 위의 예처럼 에러가 나는 것이다.
char c = 'a';
c = c + 1; // 컴파일 후에도 c = c + 1;
c = 'a' + 1; // 컴파일 후에는 c = 'b';바로 윗 줄에서 대입했는데 왜 이렇게 컴파일러가 멍청한 것 같냐고 말한다면...
다음의 익숙한 C 코드를 보자.
#include <stdio.h>
#include <string.h>
void lower1(char *s)
{
long i;
for (i = 0 ; i < strlen(s) ; i++)
if ('A' <= s[i] && s[i] <= 'Z')
s[i] -= 'A' - 'a';
}
void lower2(char *s)
{
long i;
long len = strlen(s);
for (i = 0 ; i < len ; i++)
if ('A' <= s[i] && s[i] <= 'Z')
s[i] -= 'A' - 'a';
}우리가 보면 strlen(s)는 매번 똑같은 걸 단번에 아는데, 왜 컴파일러는 for문을 돌 때마다 strlen(s) 함수를 실행하고 같은 결과를 도출한 다음에야 그 값을 이용하는가?
왜 컴파일러는 O(n^2)인lower1을 O(n)인 lower2로 변환하지 못하는가?
이상적인 세상에서 컴파일러는 루프 테스트에서
strlen호출은 같은 결과를 리턴할 것이고, 그래서 이 호출은 루프로부터 제거될 수 있을 것이다. 이를 위해서는 매우 복잡한 해석이 필요한데, 그 이유는strlen이 스트링의 원소들을 체크하고 이 값들이lower1이 실행됨에 따라 변하기 때문이다.컴파일러는 스트링 내의 문자들이 변하고 0으로 설정되는 상황 모두를 감지할 필요가 있다. 이러한 분석은 비록 이들이 인라이닝을 채택한다 하더라도 가장 복잡한 컴파일러의 능력 범위를 훨씬 벗어나며, 프로그래머들이 직접 해야 하는 영역이다(CS:APP, 490-491).
컴파일러는 변수를 상수화할 능력이 없다!
출처
- Java의 정석 3판(남궁성 저, 2016)
- 33쪽(리터럴과 변수 타입의 불일치)
- 83쪽(기본형의 자동 형변환이 가능한 방향)
- 92쪽(일반 산술 변환)
- 103~104쪽(
i += 1과i = i + 1의 차이)
- 컴퓨터 시스템 제3판(김형신 역, 2016, 원저 CS:APP)
- 490~491쪽(루프 비효율성 제거하기)
