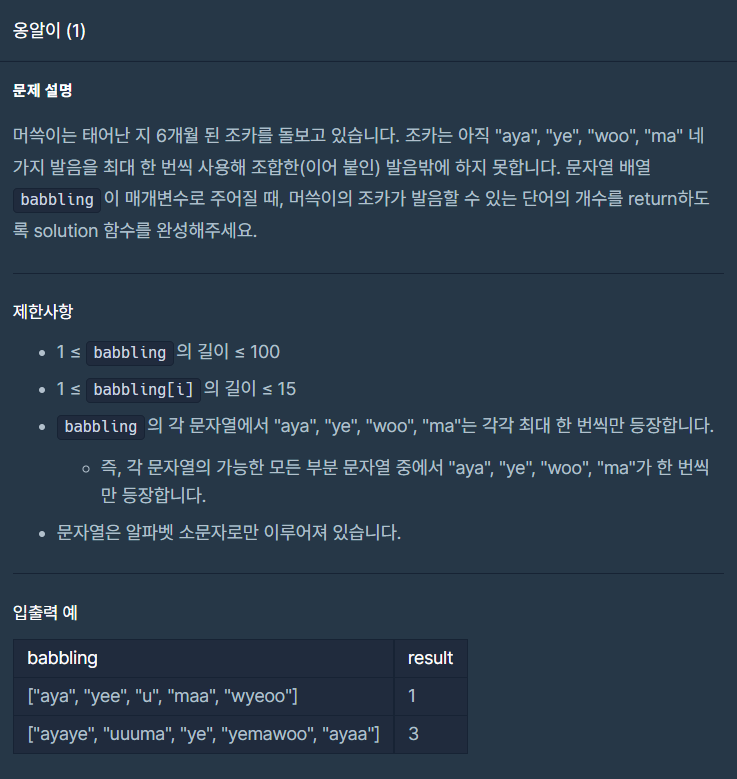
문제
풀이
레벨 0치고 제법 정답률이 낮은 문제다.
문제를 풀기 위해서는 매개변수 babbling의 요소들을 주어진 발음 "aya" "ye" "woo" "ma" 를 구분자로 split한 다음 남은 내용물이 없는 것들을 필터링 해주면 된다고 생각했다.
const solution = babbling => babbling
.filter(x=>x.split(/aya|ye|woo|ma/g)
.filter(y=>y!="")
.length==0).lengthbabbling의 요소를 정규식으로 split한 다음 빈 칸만 남은 것들을 필터링해 준 다음 babbling의 길이를 확인하여 조건에 맞는 발음의 개수를 찾아냈다.
이것도 다른 사람의 풀이를 보면서 더 괜찮다고 느낀게 있어 가져왔다.
const solution = babbling => babbling.filter(x=>/^(aya|ye|woo|ma)+$/.test(x)).length정규식을 좀 더 잘 쓰면 이렇게 주어진 발음으로만 이루어진 것들을 바로 찾을 수 있었다.
여기서 사용된 정규식을 이해하려고 검색을 통해 각 의미를 찾아보았다.
'^' is the begin of subject "anchor." It does not consume any data, just asserts a position. Similar to the metacharacter sequence \A if you encounter that, although the latter is not affected by line mode (research regex "mode modifiers").
'$' is the end of subject anchor. Again, a non consuming assertion. Similar to \Z metacharacter, although the latter is not affected by line mode. Close cousin of \z (although the latter has no regard for newlines and line modes). Anytime you see a regex framed with ^...$ it's asserting that the match condition is front to back.
'+' is the one-or-more quantifier. \1+ means whatever character was captured by capture group 1 repeats one-or-more times (i.e., occurs two or more times). "aa" would match, where the first 'a' is matched by the dot captured in group \1, and the second 'a' matches because it satisfies the one-or-more quantification.
요약하면 '^'는 앵커의 시작, '$'는 앵커의 끝을 의미하고 '+'는 하나 이상의 수량자 라는 것이다.
/^(aya|ye|woo|ma)+$/이 정규식을 해석하면 시작 부분(^)이 (aya|ye|woo|ma)중에서 하나이고 뒷부분($)도 (aya|ye|woo|ma)이면서 하나 이상의(+) (aya|ye|woo|ma)로 이루어진 것을 찾으라는 것으로, 이걸 사용하면 정규식 한번에 (aya|ye|woo|ma) 로만 이루어진 문장을 찾을 수 있다.
참고 :
https://ko.wikipedia.org/wiki/%EC%A0%95%EA%B7%9C_%ED%91%9C%ED%98%84%EC%8B%9D
https://stackoverflow.com/questions/34292024/regular-expression-vs-vs-none
https://stackoverflow.com/questions/31079959/what-is-the-meaning-of-the-regular-expression-1
