읽은거 간단하게 정리중 (너무 추워서 손시려워서 타자가 안쳐짐)
- deepseek R1
- deepseekmath (grpo만)
- deepseek v3 (학습만 간단히)
DeepSeek R1
- 여기선 학습 파이프라인을 소개하면서 자기네들이 reasoning 학습시킬때 적용한 여러 가지에 대해 설명함
Reasoning Model
- o1, o1-mini의 모델이 상용으로는 시초일 것 같은데(연구에서는 몇 개 있었음), 기존 연구에서는 Reasoning 기법이라고 해서 어떤 문제에 대해서 여러 스텝을 거친 후 최종 답안을 만드는 방식을 많이 썼었음
- Chain of Thoughts(CoT)로 널리 알려져 있는데, 이도 한 종류로 보면 될 듯. Thoughts부분을 어떻게 처리하니, 몇 개의 추론을 거치니, 데이터를 어떻게 만드니 기타 등등 좀 많은 기법들이 있어 왔음. 비학습기법으로 시작했다가, o1으로 대표되는 학습모델들까지 등장했다고 생각됨
- 예전에는 cot를 하면 그만큼 추론 시간도 길고 비용도 많이 소모되기 때문에 되도록 하지 않도록 학습시키거나, 토큰을 극단적으로 줄여버리는 연구들도 꽤 있었던 것으로 기억난다. codebook마냥 encode-decode하는 느낌으로 가는 논문도 있었던 것 같음
- 아무튼 본문에 나오는 reasoning model은 프롬프트 방식이 아니라 reasoning을 하도록 이미 학습된 모델 을 뜻함.
RLHF and DPO
- ChatGPT(gpt-3.5 이런 모델들)가 등장하면서 RLHF라는 기법이 빵 뜸. 이건 InstructGPT라는 논문에서 처음 소개됐는데, preference라는 애매한 개념을 loss로 표현하기 몹시 어려우니 강화학습을 차용해서 사람의 선호방식으로 학습을 하게 만들자 - 임.
- RLHF는 기본적으로 PPO라는 강화학습의 기법 중 하나를 사용하는데, 학습은 되는데 리소스가 너무 많은 게 문제임.
- DPO는 RLHF의 수식을 비틀어 짰더니, RLHF에 들어가는 수많은 요소들 (model, ref_model, reward_model, 중간 value model) 중 두 개(model, ref_model)만 가지고 지도학습형식으로 아주 유사하게 따라할수 있음! 을 알아냄. 생각해 보면 리소스가 반은 줄게 되므로(그리고 학습도 단일 단계만 해도 됨) 많이들 차용함
GRPO
분명 더 좋은 그림을 봤는데 집에 왔더니 못찾겠음
- 그럼 강화학습으로는 이 리소스 문제를 해결할 수 없나? 하면 해결할 수 있다! 가 GRPO
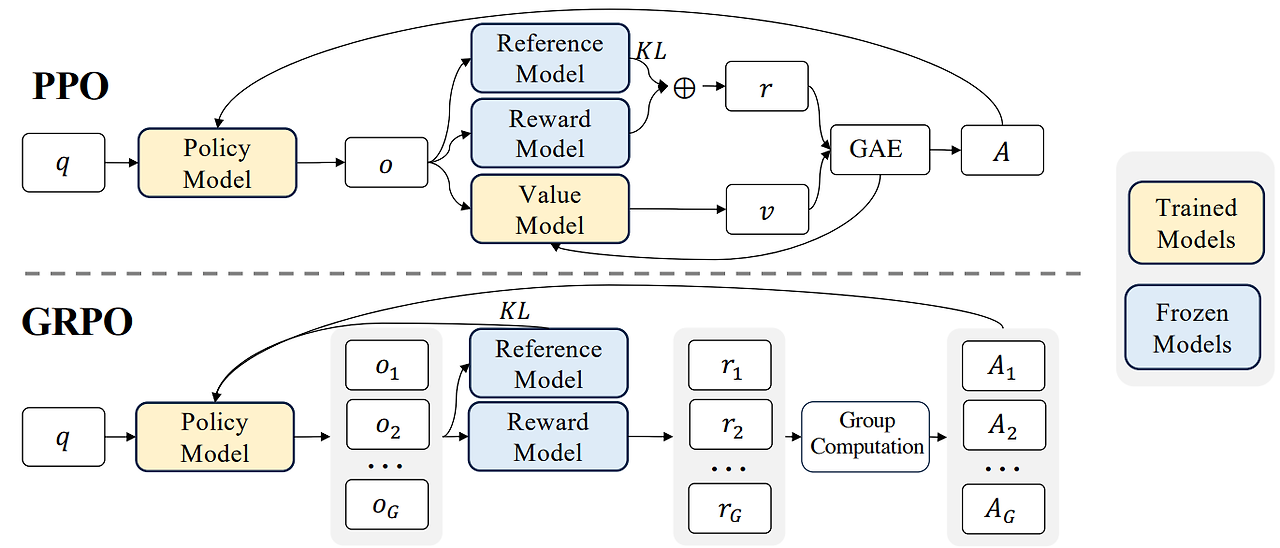
- ppo방식은 value model의 value가 baseline(모델기준 이거보단 잘해야 이 값을 올려줌)을 뽑아내는 방식으로, 시간차(TD lambda)방식으로 작동한다. 무슨 말이냐면, 언어모델을 강화학습으로 학습할 때, 보통 episode == 한 문장 생성(row)로 하는데, 문장이 끝났을 때 그 문장을 바탕으로 보상을 매김(Monte Carlo) / 문장이 완성은 안됐지만 중간값을 기반으로 보상을 해서 누적함 (TD) / 중간 스텝들을 weighted sum마냥 누적해서 보상을 매김 (TD lambda).
- 이를 위해서는 'value model' 이 필요하다. 이 모델은 중간결과까지의 유사 평가점수를 측정하는 역할인데, 그림 보면 노란색으로 '학습'을 동일하게 진행한다. 이 때문에 리소스가 아주 냠냠.
- 원래는 그래서 이 value model이 만든 값과, reward(+ref) 모델이 만든 값을 바탕으로 업데이트값을 정한다.
- grpo는 value model이 리소스 먹는게 싫다. 그래서 아예 던져버리는데, 그럼 baseline이 되어줄 v값은 어떻게 정하지? 여기서 학습모델로 하여금 G개의 샘플을 만들게 해서(deepseekmath 기준 G=64라고 읽었는데 HF디폴트는 또 8이라고 되어있다 :/) 샘플들의 리워드의 평균 을 baseline으로 둔다. baseline을 중간에 정하지 않고, 끝났을 때 바탕으로 보상을 매기기 때문에 MC방식이 될 수밖에 없다.
- 논문에서는 이 '중간에 점수매기게 하기'(어쩄든 이것도 학습이므로)가 언어생성에는 큰 가치가 없기 때문에 grpo가 더 도움이 된다! 라고 말하는중
DeepSeek R1 Zero
- 위의 grpo에서 더 단순한 아이디어를 집어넣었다. reward model이 굳이 모델이어야 하나?
- 그럼 reward를 뭐로 주지?
- cot할건데, reasoning형식이 맞니? (뭐 dictionary면 eval등으로 평가하면 되니까)
- 답은 맞니?
이런 식으로 명확히 점수를 매길 수 있는 task에 대해서는 간단하게 리워드 함수를 짤 수 있다. 이것만으로도 모델이 어느 정도 학습이 될까? 하는 게 r1 zero.
따라서 RL을 제외하고 그 어떤 학습도 하지 않았다...... 베이스는(여긴없지만) deepseek v3 base
결론은
- 생각보다 학습이 실제로 됨
- 물론 언어가 섞이는 등의 미묘한 문제는 있음
- 수학문제 / reasoning에는 의외로 효과가 있음
생각보다 해볼만하다고 느낀건지, 이 방식을 실 학습에도 쓰기로 함
DeepSeek R1
총 네 단계를 거침. 이중 앞의 두 단계는 뒤의 두 단계를 위한 준비 단계로 보면 될 듯.
1. Cold Starting
- SFT다. 아예 깡으로 RL했더니 위의 문제들이 있으니까, 아주 적은 데이터를 가지고 deepseek v3 base 학습을 진행한다.
2. Reasoning-oriented RL
- 위의 모델에 대고 RL 학습을 진행함.
- zero와 똑같이 rule based reward를 했는지는....모르겠는데 우선 코딩 / 수학 / 등의 'clear solution'이 있는 것만 대상으로 했다고 하니까 rule base가 맞을수도 있다.
- language consistency reward도 추가했따고 한다 (위의 언어 섞임 해결을 위해)
3. SFT
- 위의 모델로 학습을 안 한다. 이거로 데이터 만들기 진행.
- 위의 두 단계는 데이터 셔틀을 만들기 위한 노력이었던 것...
- reasoning data / non reasoning data 둘을 써서(약 3:1) 800K의 샘플을 만들어 deepseek v3 base를 학습시켰다
4. RL
- 여기선 자세히 다루지 않고, deepseek v3 논문에 더 자세히 나오는데, 그 논문에 나오는 학습 pipeline을 따랐다고 한다.
- machine based model과 rule based model을 둘 다 사용했다 (v3논문 참고). machine은 deepseek v3 base를 학습시켜서 만들었고.
- 둘 다 써야 하는게, 일부러 데이터 만들 때 룰로 할 수 있는 것과 아닌 것을 둘 다 넣었다. 그래야 룰이 아닌 시나리오에 대해서도 학습을 할 수 있으니까
- 그래도 grpo를 쓰긴 함

NLP / LLM