작년 말쯤에 영어권 llm leaderboard에서 인기를 엄청 끌었던 방법이 있었는데, 바로 model merge이다. 앙상블이랑 다른 점은, 앙상블은 큰 패러미터를 가지면서 실제 실행하는 패러미터를 기존 모델만큼 유지하지만 merge는 애초에 패러미터를 하나로 합쳐버리는 것이다.
정말 간단하게 설명하면 다음과 같다.
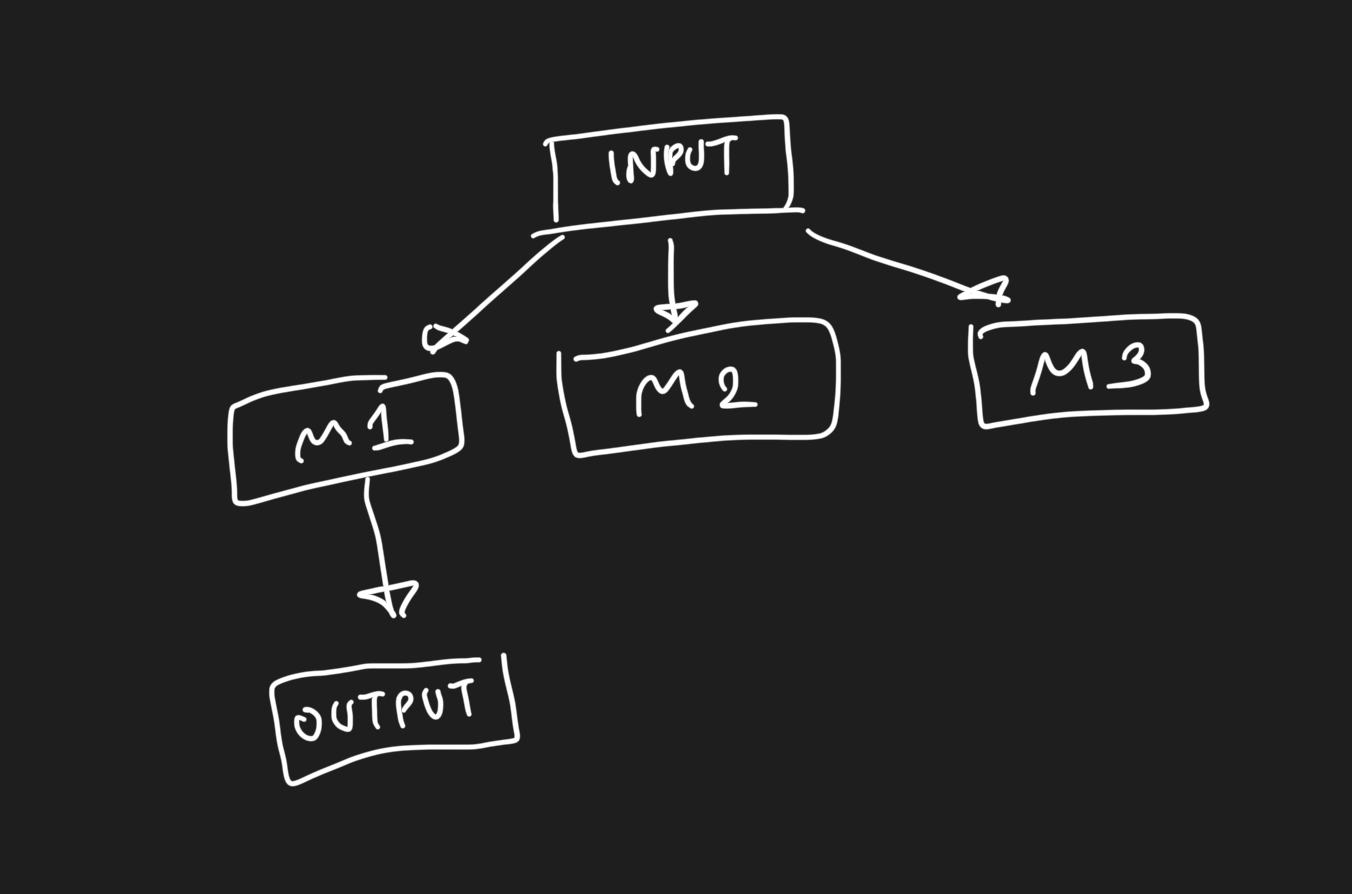
모델 사이즈는 만큼 나겠지만, 실제로는 만큼만 실행이 된다.
이에 반해 model merge는 다음과 같이 표시된다.
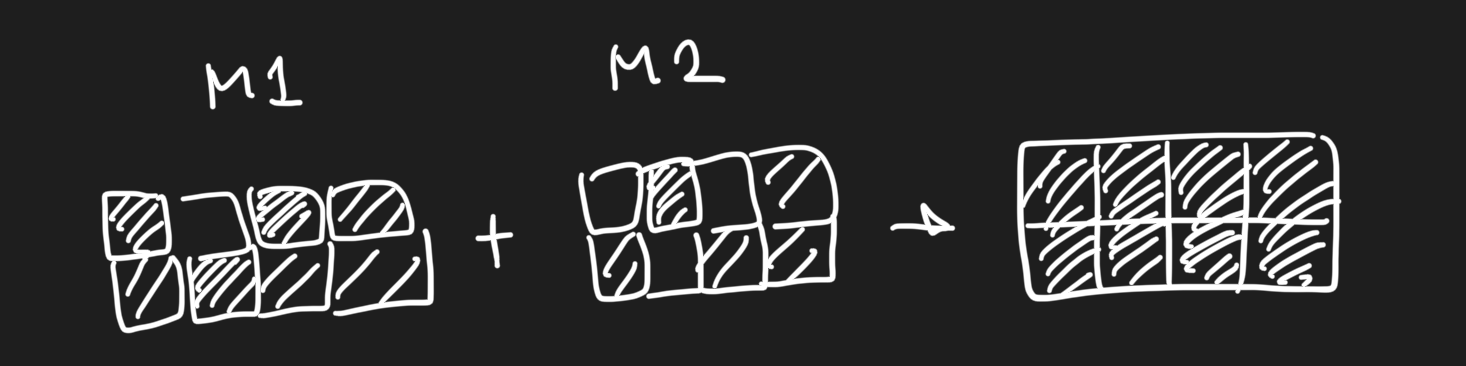
merge방식 중 하나인 ties-merge 저자의 말을 빌리자면, 어차피 특정 태스크에 특화되어 일하는 중요한 weight는 극소수이다. 따라서 task a에 대해서 가 더 잘하고, task b에 대해 가 더 잘할 때, 두 모델의 weight를 적절히 merge하는 경우 둘 다 잘하게 된다는 말이다.
weight merge는 사실 이미지 합성 분야 쪽에서는 이미 꽤나 많이 연구된 분야 중 하나이다. 어떻게 얼마나 섞어야 하는지도 많이 연구되어 있는 상태. LLM에서는 아직까지는 slerp를 통한 merge를 주로 하고 있는 추세이다. 이러한 상황에서 새로운 merge논문이 나와서 한 번 읽어보았다.
Method
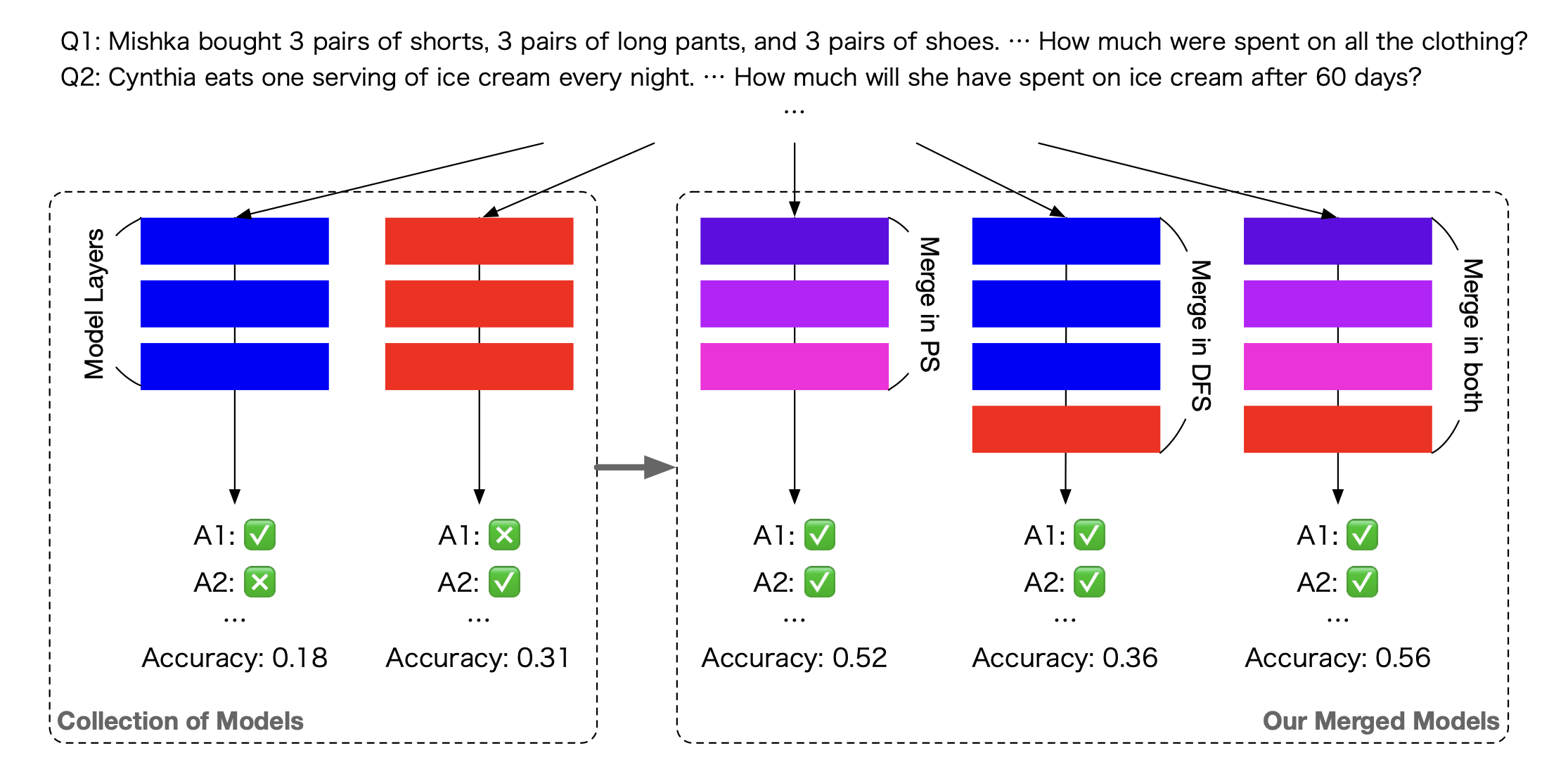
이 논문에서는 병합 기법을 두 가지로 분류한다.
- PS: ties-merging이나 DARE와 같은 방법(실제로 저자들도 이 방식을 개선해서 썼다)이다. 두 모델의 weight를 가중치에 따라 섞어서 쓴다.
즉, 특정 weight에 대해서
라는 뜻이다. 위의 이미지를 보면 이를 나타내듯 색이 중간에 보라색으로 섞여 있다.
- DFS: 앙상블과 비슷하다고 보면 된다. 데이터를 사용하되, 데이터가 어떤 weight를 선택해서 갈지 고른다. 여기서 데이터의 흐름에 따라 적절한 weight를 선택한다.
사실 양쪽 모두 장단점이 있기 때문에, 이 논문에서는 요 두 가지 방식을 섞은 새로운 절충안을 만들고자 했다. (가장 오른쪽)
그렇다면 어떻게 합쳤을까?
Merging PS and DFS
둘을 동시에 하는 것이 아니라 순차적으로 진행한다.
- PS를 통해 기본적인 병합의 틀을 맞춘다.
- 이제 샘플 데이터를 기반으로 DFS를 수행한다.
참고로 위의 두 스텝을 수행할 때 RL기반의 알고리즘이 쓰였는데, CMA-ES(Covariance Matrix Adaptation Evolution Strategy)라고 한다. 무려 2006년에 나온 알고리즘이다!
Discussion
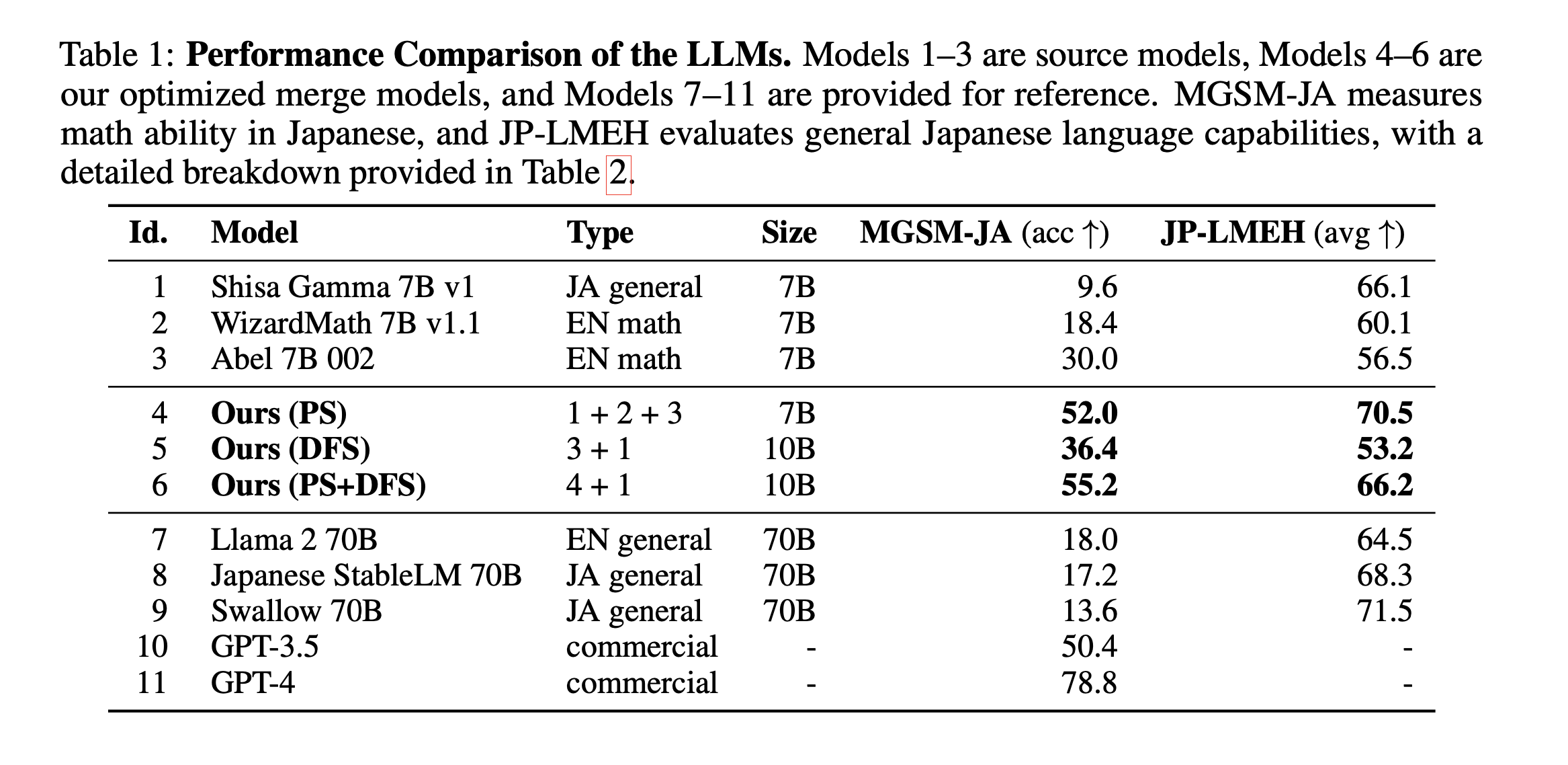
일단 오랜만에 보는 merge논문이라 바로 읽어버렸지만, 사실 이 논문은 일본쪽 검증 결과로 많이 치우쳐져 있다(실제로 저자도 일본인) 왠지 일본어 지식을 가진 일본어 모델과 범용지식이 많은 영어 모델(그냥 데이터 차이부터가 어마무시해서 따라갈 수가 없다)을 잘 병합해 보았다는 느낌이다.
그래도 일본어에서 나름 좋은 adaptation이 되었다면 한국어에서도 나름 잘 해주지 않을까? 라는 기대를 안게 한다.
단점은 PS쪽 기법 모체가 ties를 비롯한 기법들이라 다른 사이즈의 모델에도 되냐는 건데...

일단 실험 자체가 처음에는 7B로 되어 있다. 이유는 PS에 들어간 ties와 같은 기법들이 임베딩 사이즈와 같은 모델 weight shape가 정확히 같아야 하기 때문. 하지만 첫 번째 이미지에서 볼 수 있듯이 DFS에서는 사이즈 변화가 가능한 것으로 보인다.
