애플에서 드디어 숨겨뒀던 LM을 공개했다(아직은 모델 말고 논문만) 무려 데이터 및 실험정보가 담긴 논문을! 신나서 헐레벌떡 들어왔습니다
이 논문에 나오는 LM은 사실 시리를 위한 모델이라고 생각된다. 첫 인트로덕션부터 Human speech에서는 대명사를 사용하는데 이게 참 뭘 뜻하는지 알기가 어려워요~ 하고 시작한다. 그래서 모델 이름도 이러한 문제를 해결할 수 있는 reference resolution이 붙었다.
이게 인트로 상에서 주어진 예시이다.
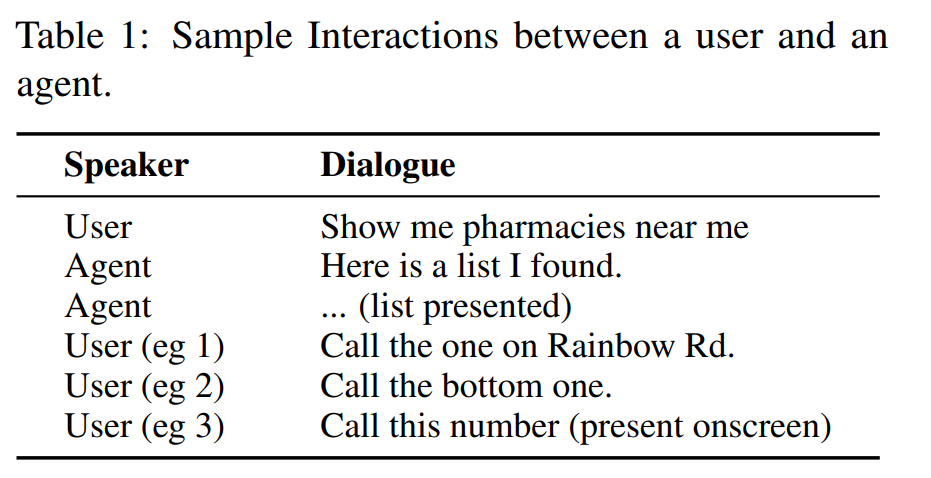
사람들 사이의 대화에서, 보통 친절하게 '다섯 번째 번호에 전화해' 라고 말하지 않는다. 만약에 내가 친구한테 몇 가지 음식점을 추천받았다면, 아마도 그 음식점 중 하나를 가리키면서 '이거 괜찮다' 라고 말할 가능성이 높다. 그리고 이런 발화는 lm이 해결하기 참 어려운 문제다. 왜냐? 이미지를 알아먹을 수가 없거든.
On-device SLM
특이하게도 다른 상용기업과는 다르게 (물론! 상용기업들도 추세는 slm(sllm?매번 바뀐다)으로 넘어오긴 했다) 타겟을 아예 on-device slm을 썼다. 애플 정도 되면 데이터도 많겠다 (대표적으로 시리) 그냥 llm을 학습시켜도 됐을텐데 왜 하필 on-device일까?
논문에서는 다음과 같은 문제가 있을 수 있기 때문에 slm을 데려왔다고 한다.
- 프라이버시 및 효율성을 지키기 위하여: API콜을 하게 되면 내 데이터가 넘어가니까!
- API 통합 이슈 때문에: 호출까지 가능한(아마 tool / agent느낌이라고 생각된다) 모델은 큰 모델이다. 사실 이부분 이해가 살짝 안 갔다. 애초에 시리도 인터넷 없으면 안되는걸보니 api콜이 아니었나요..?
- general 모델보다 특화 모델을 사용하면 기존 참조 모델을 간단하게 대체할 수 있다. 사실 이 이유보다는 특화 모델을 학습시키면 원래 일반화 모델보다는 잘 하는게 맞기는 하니까... 라는 생각이 든다.
Goal
위에서 설명했듯 이 모델의 목적은 'reference resolution'을 잘 해결하는 것이다. 그러기 위해서는 사실상 어쩔 수 없이 추가 정보가 들어가야 하는데, 이 추가 정보(엔티티)의 목록은 다음과 같다.
- 스크린에서의 엔티티. 현재 유저가 보고있는 스크린 상에서의 유효 정보들 (전화번호 / 이메일 주소 / 등등)
- 대화와 관련된 엔티티. 대화 중 언급되는 개체 및 정보를 뜻한다. '엄마'한테 이 전화번호 문자로 보내. 하면 '엄마' 가 대화 엔티티고 '이 전화번호'가 스크린 엔티티일 것
- background 엔티티. 현재 백그라운드 프로세스로 돌고 있는 것들에 대한 정보. 시리를 써 봐서 아는데 대충 이런 거 같다. '지금 울리는 알람 꺼줘'
모델은 어떠한 문장이 들어왔을 때, 어떤 엔티티인지 골라야 한다. 참고로 multiple choice task이기 때문에 답변이 엔티티 모두일수도, 하나일수도, 아무것도 아닐 수도 있다.
Method
Dataset
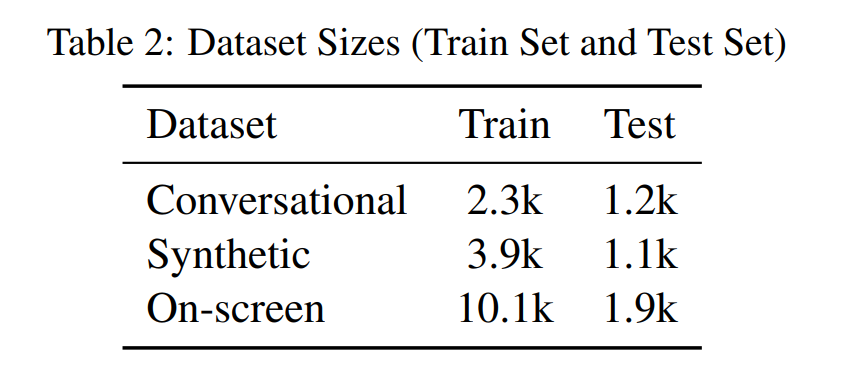
다른 논문에 비하면 정말 - 정말 작은 양의 데이터를 사용했다. 그만큼 퀄리티 있는 데이터를 사용했다는 뜻일 수도 있고... 왜나면 예전에 less is better같은 논문도 있었으니까?
대화 데이터
grader에게 가상의 대화를 하도록 해서 실 사용때와 비슷한 요청을 만들어내게 했다.
예를 들어 뭔가 작업 목록 같은 스샷이 주어졌을 때, grader가 이와 관련된 요청을 만들게 하는 식.
합성 데이터
생각보다 룰 템플릿으로 쉽게 만들 수 있는 데이터가 많다 (e.g. 실행해! -> 음악이나 동영상이나 뭐 재생할 수 있는 컨텐츠일 것) 이런 느낌으로 템플릿을 작성한 다음에 데이터로 활용하는 형태.
On-Screen 데이터
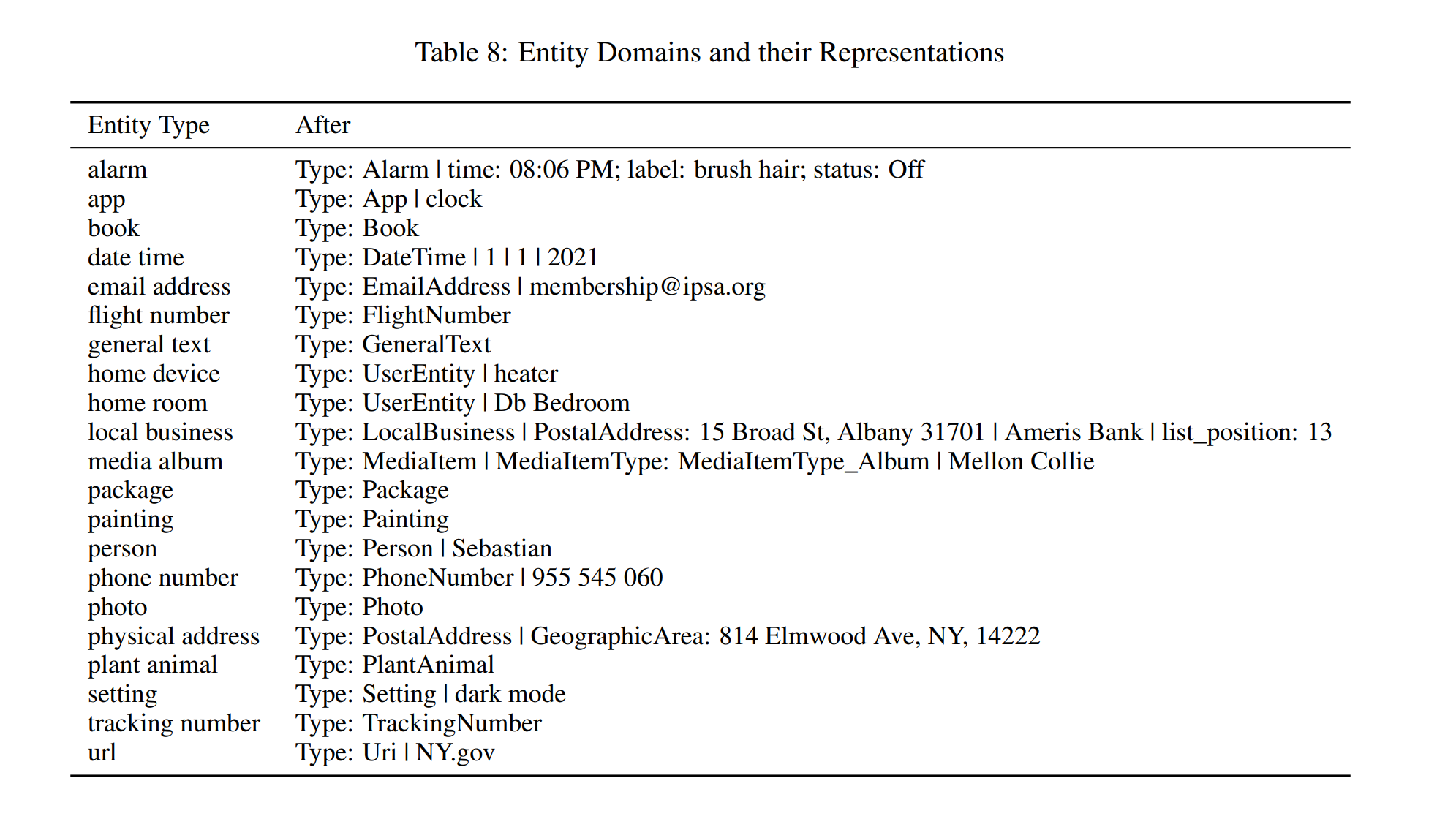
appendix에 따르면 상당히 많은 엔티티가 존재한다. 이런 정보들을 이미지에서 일단 뽑아내는 것이 우선.
투스텝으로 수집했다고 한다.
- 스크린샷 -> 사람이 표시된 정보(ocr box려나?)를 각 엔티티로 분류. 쿼리도 같이 3개쯤 생성하라고 시킴
- 1에서 나온 엔티티-쿼리를 검증함.
검증할 때는 대략 아, 쿼리가 실제로 이 엔티티를 참조하고 있나요? 뭔가 자연스러운 질문이 맞나요? 이런 느낌으로 검증
Discussion
실험을 통해서 해당 부분에서 꽤 좋은 성능을 보임을 입증
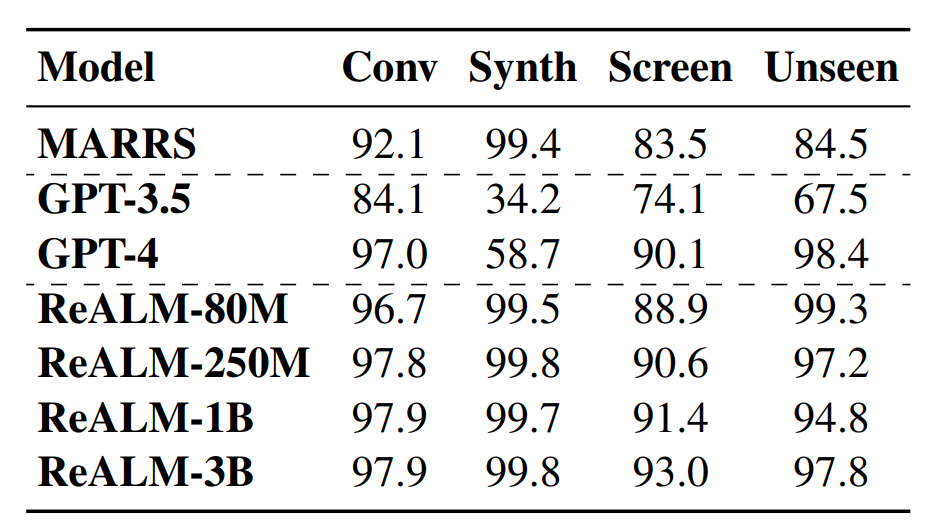
위에 데이터 섹션에서 나오는 표에 나오는 테스트 데이터를 사용. 그 외의 많은 실험은 진행하지 않은 것으로 보임.
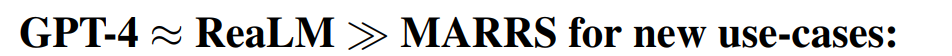
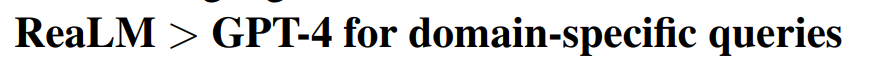
이렇게 두 개로 정리할 수 있음 딱 두개.
사실 중간에 재밌는 말이 있었다.
우리는 최선을 다해서 챗지피티에 먹일 프롬프트를 만들긴 했지만, 사실 이것보다 나은 프롬프트가 있을 수도 있다
프롬프트를 이쁘게 만지면 ReALM보다 나아질 수도 있나.?
두번째로 재밌는 점은 논문상에서는 계속 ReaLM이라고 부르면서 제목은 ReALM이라고 한다. 저 위의 사진에서도 ReaLM이라고 부르고 있다.
일단 특화데이터 - 특히 저런 tts붙일 작은 모델 정도는 저 정도의 작은 데이터로도 학습이 가능한 걸 봐서 정말 간단 태스크 정도는 SLM을 쓰게 될지도 모른다는 생각을 했다.
결론은 pi2를 써보자
(+) 다시 읽어 보니 입력을 엄청나게 예쁘게 준 쪽에 가깝다. 모델 성능이 이거보다 구려도 이 정도로 이력을 주면 잘 해야 하는 것이 맞다.
예시를 보면,

모든 정보가 다 입력으로 들어간다. 이 정도면 스샷에서 저 퀄리티의 정보를 어떻게 뽑지? 가 제일 궁금하다. 다행스럽게도 appendix에 내용이 있다.
Appendix - screen 2 text?
방식은 다음과 같다. 우선 screen parser(정보 없음)을 통해 초기 entity를 추출한다. 그리고 이전 대화에서의 entity역시 추출하여 (LM으로 식별된 경우) 식별한다음 화면 정보와 통합하여 제공한다.

