Description
Summary
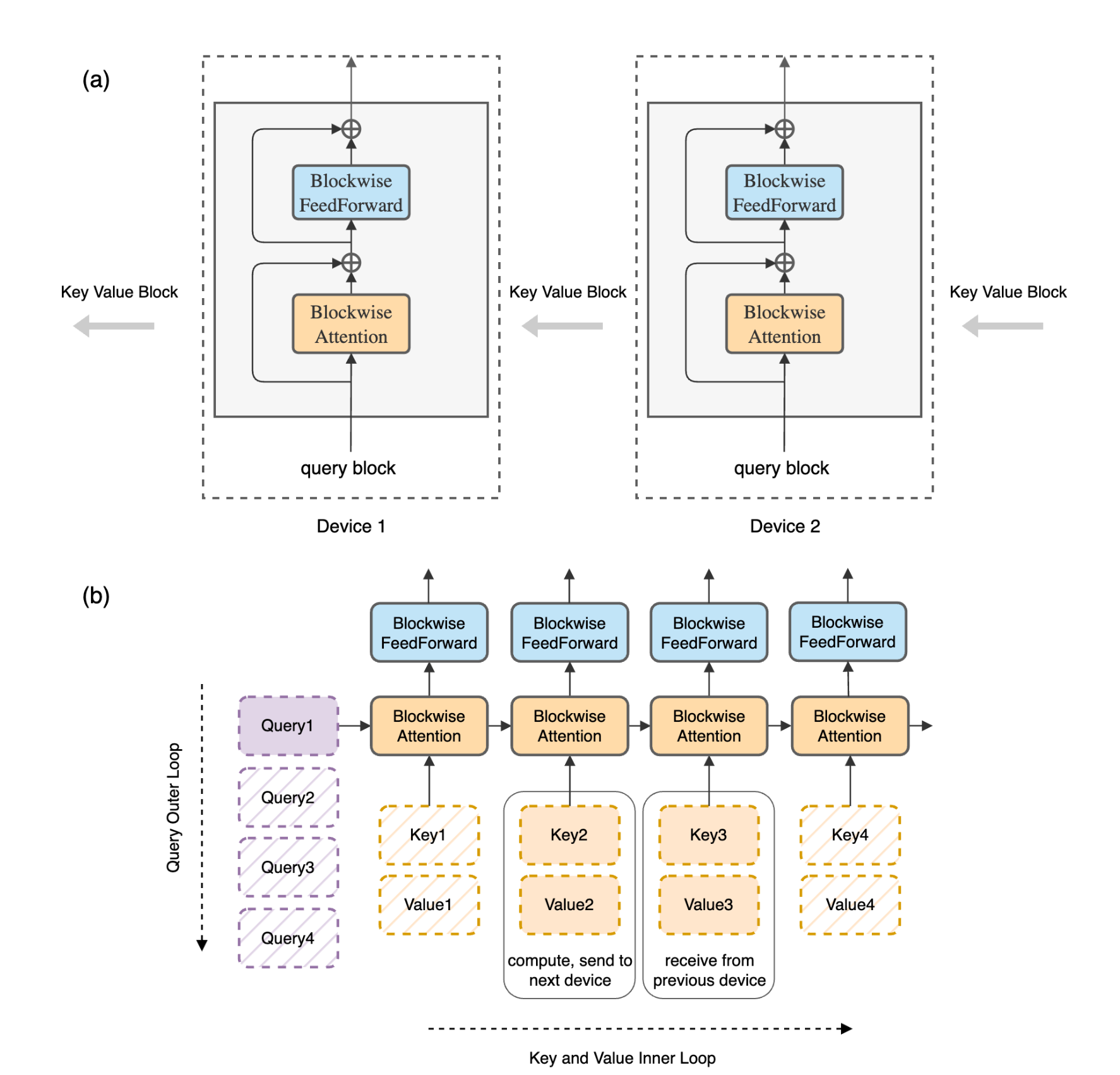
- block merge 시 병합을 위한 전송 속도 딜레이를 없애기 위해 ring형태의 아키텍쳐 사용
- 자기가 가지고 있던 local block의 key value값을 자기 다음 device에게로 넘긴다.
- name: Ring Attention with Blockwise Transformers for Near-Infinite Context
- link: https://arxiv.org/abs/2310.01889
- github: https://github.com/lhao499/RingAttention
Introduction
긴 입력을 처리하기 위한 attention 변형 방식.
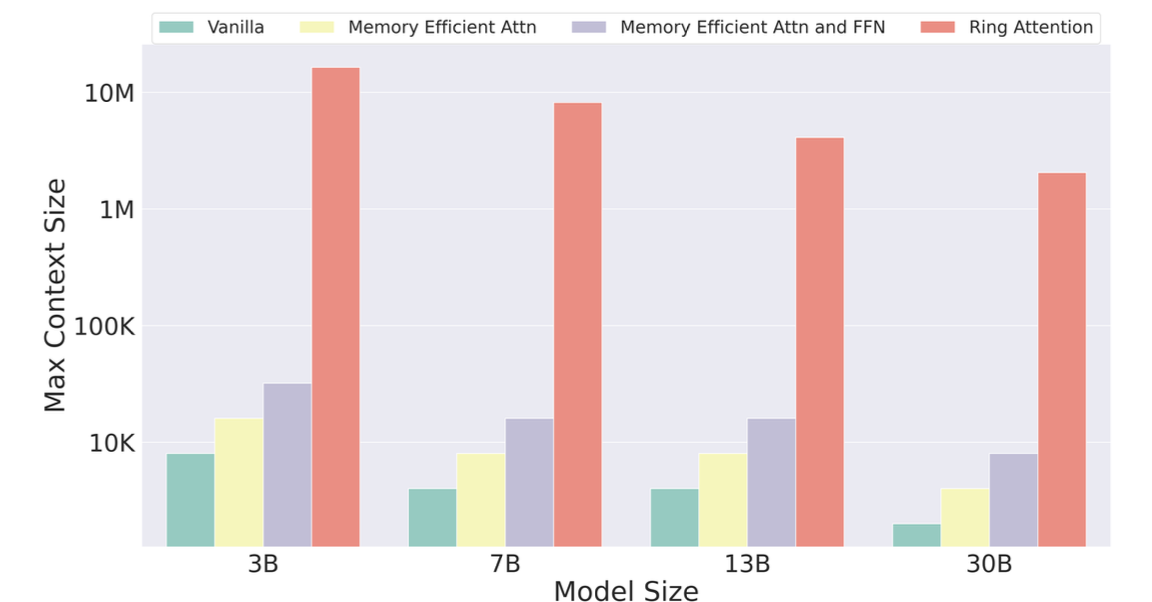
이미지에서 확인할 수 있듯이 메모리에 가장 크게 관여하는 것은 모델 사이즈가 아닌 입력 길이이다. (고로 입/출력 모두에 영향을 준다) 길이가 짧으면 여러 가지 문제가 있을 수 있는데, 예를 들어 few-shot이 안 된다. context-based QA에 제약이 크게 따른다 등등.
긴 입력이 처리가 되지 않는 이유는, 모든 길이에 대한 attention을 한 번에 계산하려고 하기 때문이다. 이 논문에서는 ringattention이라는 새로운 attention기법을 제안하는데, 블록 단위로 병렬적으로 attention을 계산하도록 하는 것이다.
Ring이라는 이름이 붙은 이유는 이전 키벨류를 전으로부터 계속 넘겨받는, 마치 하나의 고리 같은 모양새이기 떄문.
Methods
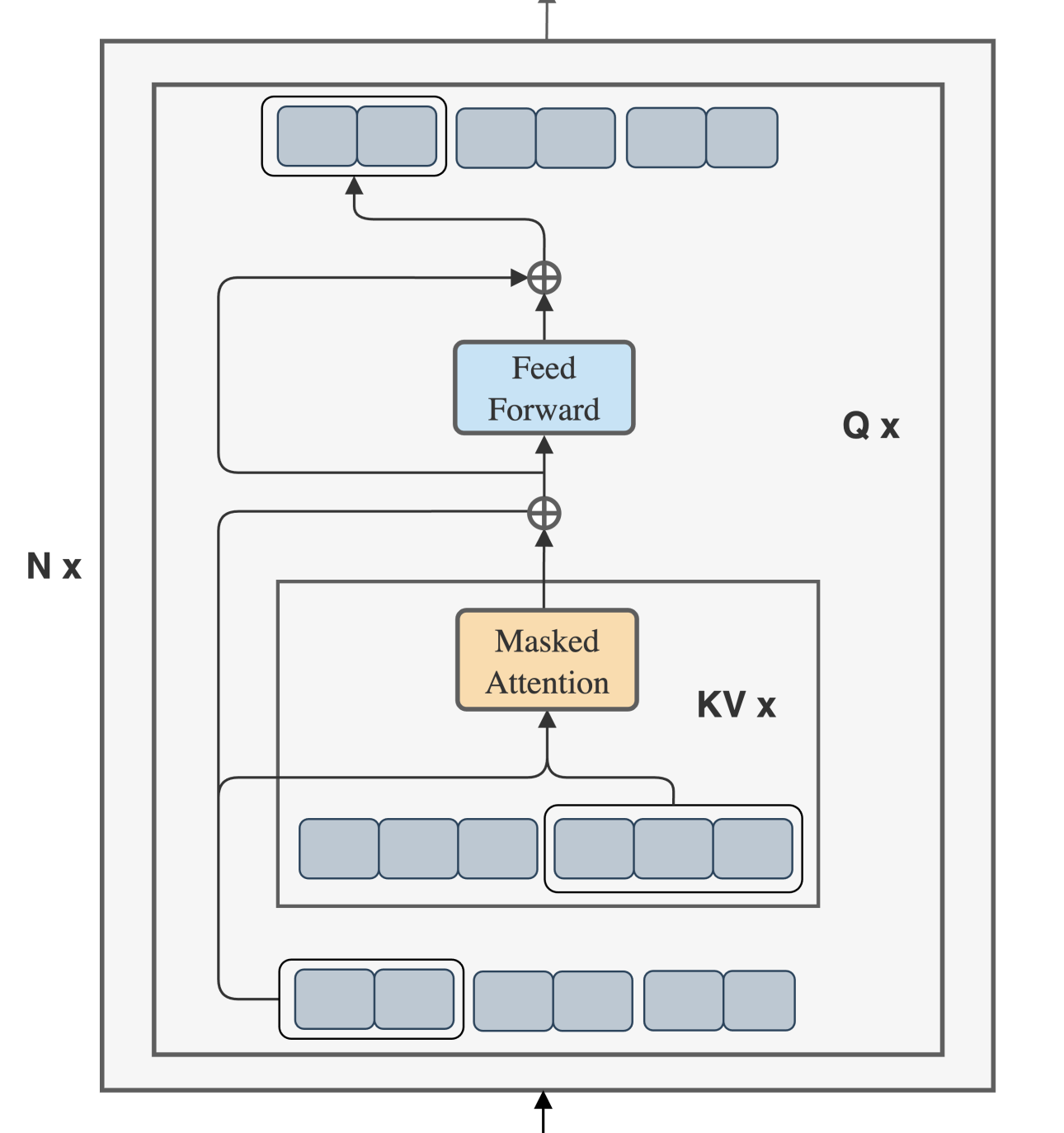
Blockwise Parallel Transformers
기존의 전체 attention에서 block단위로 나눠서 연산을 진행하게 하여 연산량을 줄인다. 원래는 sequence에 quadratic하게 증가할 수 밖에 없는 구조로 되어 있다.
당시 SOTA 기법에서 연산 정도는 대략 로, batch size가 s보다 많이 작다는 것을 고려하면 기존의 보다 많이 줄어들었다는 것을 알 수 있다.
그러나 이 기법으로도 해결할 수 없는 문제가 있는데, 바로 출력 길이 문제이다.
계속해서 긴 답변을 생성하려면 이전 답변에 대한 정보를 저장해두어야만 하는데, 예를 들어 100M개의 토큰을 생성하는데 대략 1000GB의 메모리가 든다고 한다(...) 참고로 현재 '일반적으로' 사용되는 GPU는 80GB(H100 / A100)
Ring Attention
BPT의 가장 큰 문제점인 통신 속도로부터 시작한다.
이와 같이 연산 자체는 적은 수로 할 수 있지만, 다른 단위의 device에 들어간 block을 다 취합해 연산하기 때문에 통신 관련 문제가 발생하게 된다.
이 논문에서는 간단한 해결법을 제시한다.
- 연산할 때 전송을 동시에 한다.
- 모두가 자기 옆의 device로 자신이 들고있던 kv를 넘긴다.
이러면 연산속도 > 전송 속도일 경우 무조건 연산 속도만큼의 생성 속도를 가지게 되므로 통신 관련 문제가 발생하지 않는다.