[기초] CNN-LSTM, LSTM-AE
1. LSTM AutoEncoder
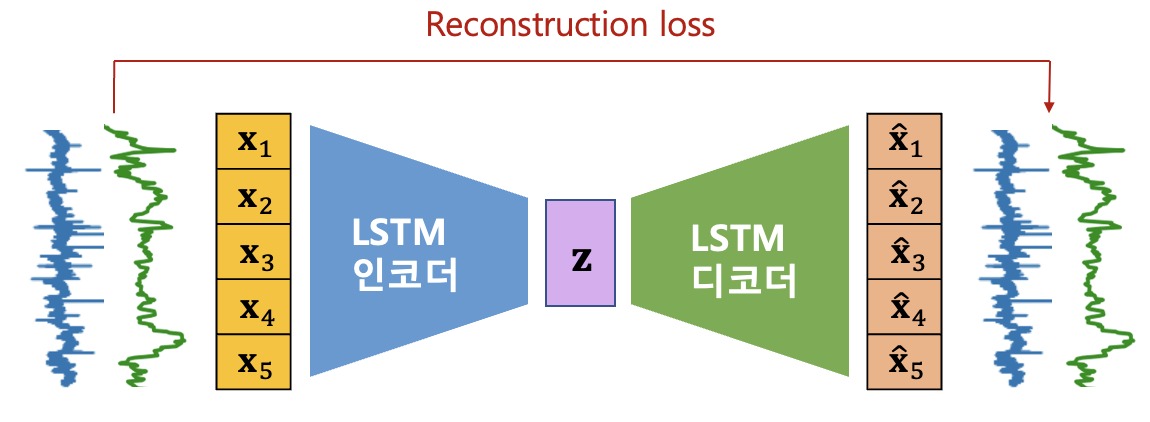
LSTM Autoencoder와 시퀀스 입력–출력 구조
1. 시퀀스 모델에서의 입력–출력 구조
순환 신경망(RNN) 및 LSTM 계열 모델은 입력과 출력이 시간 축을 따라 어떻게 대응되는가에 따라 여러 구조로 구분된다.
이러한 구분은 모델이 시계열 정보를 어떤 방식으로 요약하고, 언제 출력으로 전개하는지를 이해하는 데 중요한 기준이 된다.
아래 그림은 대표적인 다섯 가지 시퀀스 입력–출력 구조를 도식화한 것이다.
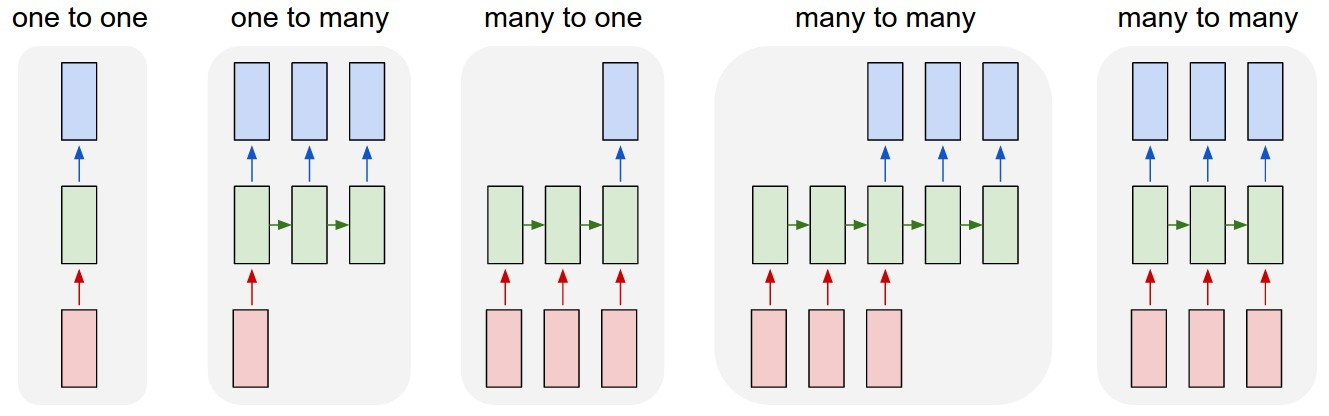
1.1 One-to-One 구조
하나의 입력이 하나의 출력으로 대응되는 구조이다.
시간적 의존성이 명시적으로 활용되지 않으며, 구조적으로는 feedforward 신경망과 동일하다.
시계열 문제에서는 제한적인 경우에만 사용된다.
대표적인 예시
- 특정 시점의 센서 벡터 → 해당 시점의 상태 값 예측
- 고정 길이 특징 벡터 → 하나의 회귀값 또는 클래스
- 시계열 데이터에서 시간 축을 제거하고, 통계 요약값만을 입력으로 사용하는 경우
1.2 One-to-Many 구조
하나의 입력으로부터 여러 시점의 출력을 생성하는 구조이다.
입력은 고정된 컨텍스트로 작용하며, 출력은 시간 축을 따라 순차적으로 생성된다.
대표적인 예시
- 이미지 하나 → 설명 문장 생성 (Image Captioning)
- 초기 상태 벡터 → 미래 시점의 시계열 시뮬레이션
- 단일 조건 벡터 → 제어 시퀀스 생성
1.3 Many-to-One 구조
여러 시점의 입력 시퀀스를 하나의 출력으로 요약하는 구조이다.
시계열 분류나 상태 판별과 같이, 시퀀스 전체에 대한 하나의 판단이 필요한 문제에 주로 사용된다.
대표적인 예시
- 일정 시간 구간의 센서 시계열 → 정상 / 이상 분류
- 문장 전체 → 감정 분류 결과
- 공정 로그 시퀀스 → 공정 상태 라벨
1.4 Many-to-Many 구조 (동기식)
입력 시퀀스와 출력 시퀀스가 동일한 길이를 가지며,
각 시점의 입력과 출력이 직접 대응되는 구조이다.
대표적인 예시
- 과거 시계열 → 같은 길이의 미래 시계열 예측
- 시계열 데이터 → 시점별 이상 점수 산출
- 문장 입력 → 각 단어에 대한 품사 태깅
1.5 Many-to-Many 구조 (비동기식, Encoder–Decoder)
입력 시퀀스를 모두 처리한 뒤, 별도의 출력 시퀀스를 생성하는 구조이다.
입력과 출력 시퀀스의 길이는 서로 다를 수 있으며,
일반적으로 Encoder–Decoder 구조 또는 sequence-to-sequence 구조라고 불린다.
대표적인 예시
- 문장 → 다른 언어의 문장 (기계 번역)
- 음성 신호 시퀀스 → 텍스트 시퀀스
- 시계열 전체 → 요약된 이벤트 시퀀스
- 시계열 → 동일한 시계열의 재구성 (LSTM Autoencoder)
LSTM Autoencoder는 이 구조를 사용하되,
출력 시퀀스를 새로운 목표 시퀀스가 아니라 입력 시퀀스 자체의 재구성으로 설정한다.
2. LSTM Autoencoder의 기본 개념
LSTM Autoencoder는 시계열 데이터를 입력으로 받아,
동일한 시계열을 다시 복원하도록 학습되는 비지도 학습 모델이다.
이 모델의 핵심 목적은 다음과 같이 정리할 수 있다.
시계열 전체를 고정 차원의 잠재 표현으로 압축한 뒤,
해당 표현만을 이용해 원래 시계열의 시간 구조를 재구성한다.
이를 위해 LSTM Autoencoder는 Encoder LSTM과 Decoder LSTM으로 구성된다.
3. Encoder–Decoder 구조
이 글에선 입력 시퀀스와 출력 시퀀스의 길이가 동일한 재구성(autoencoding) 설정을 가정한다.
3.1 Encoder LSTM
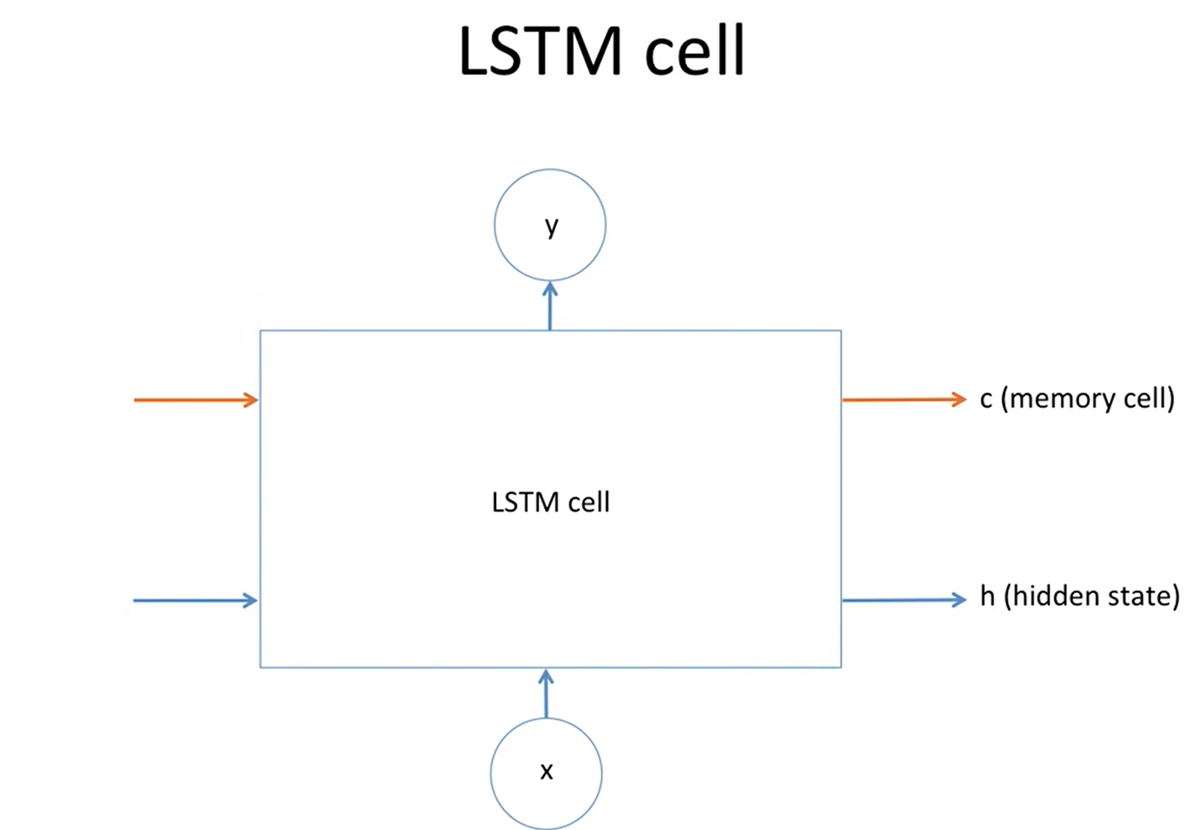
입력 시계열을 다음과 같이 정의한다.
Encoder LSTM은 입력 시퀀스를 시간 순서대로 처리하며 hidden state와 cell state를 갱신한다.
- Cell state : 시계열 전반에 걸쳐 유지되는 long-term memory를 담당
- 여러 시점을 관통하는 추세
- 장기간 유지되어야 할 상태 정보
- 급격한 변동에 쉽게 흔들리지 않는 정보
- Hidden state : 현재 lstm cell 시점에서의 output
- 현재 시점의 입력, 장기 기억(cell state), 직전 hidden state의 요약 정보
마지막 시점의 hidden state는 시계열 전체를 요약한 잠재 벡터로 사용된다.
Cell state (c_T)를 잠재 표현으로 사용하는 변형도 존재하지만,
일반적으로는 hidden state (h_T)가 더 널리 사용된다.
3.2 Decoder LSTM
Decoder LSTM은 Encoder가 생성한 잠재 벡터 (z)를 초기 상태로 받아,
시간 순서에 따라 입력 시퀀스를 재구성하는 역할을 한다.
일반적으로 잠재 벡터 (z)는 Decoder LSTM의 초기 hidden state와 cell state로 주어진다.
이후 시점 (t)에서 Decoder LSTM의 상태는 다음과 같이 갱신된다.
각 시점의 출력은 hidden state로부터 계산된다.
여기서 (f(\cdot))는 선형 변환 혹은 출력 차원에 맞춘 비선형 함수이다.
4. 학습 목표 함수
LSTM Autoencoder는 입력 시계열과 출력 시계열 간의 차이를 최소화하도록 학습된다.
대표적인 손실 함수는 평균 제곱 오차(MSE)이다.
이 손실 함수는 단순한 복사 문제처럼 보일 수 있으나,
다음과 같은 구조적 제약이 존재한다.
- Encoder는 전체 시계열을 하나의 고정 차원 벡터로 압축해야 한다.
- Decoder는 해당 벡터를 기반으로 시간적 구조를 복원해야 한다.
따라서 잠재 벡터 (z)에는 시계열의 전반적인 동역학 정보가 내재될 수밖에 없다.
5. Many-to-Many 구조와 LSTM Autoencoder의 해석
그림 X의 비동기식 many-to-many 구조는 LSTM Autoencoder를 이해하는 핵심 틀을 제공한다.
- 입력 시퀀스 전체 → Encoder
- 잠재 벡터 (z) → Decoder
- 출력 시퀀스 전체
LSTM Autoencoder는 이 구조를 그대로 사용하되,
출력 시퀀스를 새로운 목표 시퀀스가 아니라 입력 시퀀스 자체의 재구성으로 설정한다.
즉,
LSTM Autoencoder는
sequence-to-sequence 형태의 many-to-many 구조를 이용한
시계열 재구성 모델이다.
6. 이상 탐지 관점에서의 활용
이상 탐지 목적으로 사용되는 경우,
LSTM Autoencoder는 일반적으로 정상 시계열 데이터만을 사용해 학습된다.
정상 데이터에 대해 학습된 모델은 정상적인 시간 패턴에 대해서는 낮은 재구성 오차를 보이는 반면,
비정상적인 패턴에 대해서는 높은 재구성 오차를 보인다.
시점별 재구성 오차는 다음과 같이 정의할 수 있다.
또는 시퀀스 단위의 재구성 오차:
이 오차를 기준으로 시계열의 정상 여부를 판단할 수 있다.
7. 코드
import torch.nn as nn
# Encoder
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, dropout, seq_len):
super().__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.seq_len = seq_len
self.encoder_lstm = nn.LSTM(
input_size=input_dim,
hidden_size=hidden_dim,
dropout=dropout,
batch_first=True
)
def forward(self, input_seq):
encoder_outputs, (h_n, c_n) = self.encoder_lstm(input_seq)
# last hidden state -> latent representation
latent = h_n.squeeze(0) # (B, H)
latent_seq = latent.unsqueeze(1).repeat(1, input_seq.size(1), 1)
return latent_seq, encoder_outputs
# Decoder
class Decoder(nn.Module):
def __init__(self, output_dim, hidden_dim, dropout, seq_len, use_output_activation):
super().__init__()
self.output_dim = output_dim
self.hidden_dim = hidden_dim
self.seq_len = seq_len
self.use_output_activation = use_output_activation
self.decoder_lstm = nn.LSTM(
input_size=hidden_dim,
hidden_size=hidden_dim,
dropout=dropout,
batch_first=True
)
self.output_layer = nn.Linear(hidden_dim, output_dim)
self.activation = nn.Sigmoid()
def forward(self, latent_seq):
decoder_outputs, (h_n, c_n) = self.decoder_lstm(latent_seq)
reconstructed_seq = self.output_layer(decoder_outputs)
if self.use_output_activation:
reconstructed_seq = self.activation(reconstructed_seq)
return reconstructed_seq, h_n
# LSTM AutoEncoder
class LSTMAutoEncoder(nn.Module):
def __init__(self, input_dim, hidden_dim, dropout, seq_len, use_output_activation=True):
super().__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.seq_len = seq_len
self.encoder = Encoder(
input_dim=input_dim,
hidden_dim=hidden_dim,
dropout=dropout,
seq_len=seq_len
)
self.decoder = Decoder(
output_dim=input_dim,
hidden_dim=hidden_dim,
dropout=dropout,
seq_len=seq_len,
use_output_activation=use_output_activation
)
def forward(self, input_seq, return_latent=False, return_encoder_outputs=False):
latent_seq, encoder_outputs = self.encoder(input_seq)
reconstructed_seq, last_hidden = self.decoder(latent_seq)
if return_latent:
return reconstructed_seq, last_hidden
elif return_encoder_outputs:
return reconstructed_seq, encoder_outputs
return reconstructed_seq2. CNN–LSTM 모델
1. CNN–LSTM이 필요한 배경
시계열 데이터 는 다음 두 가지 구조를 동시에 가진다.
-
국소 패턴(Local pattern)
짧은 시간 구간에서 반복적으로 나타나는 파형, 주기, 급격한 변화
→ 필터 기반의 국소 특징 추출에 유리 -
장기 의존성(Temporal dependency)
과거의 상태가 현재의 해석에 영향을 미침
→ 상태(state)를 누적하는 순환 구조가 필요
CNN–LSTM은 이 두 구조를 분리된 역할로 처리한다.
| 구성 요소 | 역할 |
|---|---|
| CNN | 짧은 시간 구간의 형태적 패턴 추출 |
| LSTM | 패턴들의 시간적 연결 관계 모델링 |
즉,
CNN은 “무엇이 일어났는지”를 요약하고,
LSTM은 “그 일이 언제, 어떤 순서로 일어났는지”를 학습한다.
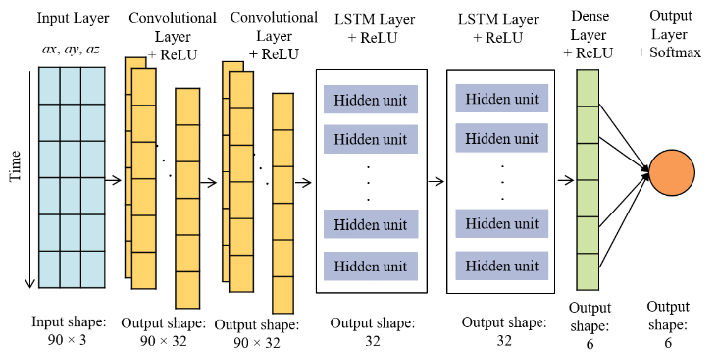
2. 전체 구조 개요
입력 시계열을 다음과 같이 표현한다.
- : 시계열 길이
- : 채널 수 (센서 수, 변수 수)
CNN–LSTM의 처리 흐름은 다음과 같다.
3. CNN 단계: 국소 패턴 추출
3.1 1D Convolution의 적용
시계열에서는 시간 축을 따라 1D Convolution을 적용한다.
- : 커널 크기 (time window)
- : 필터 인덱스
- : 번째 필터의 feature map
3.2 의미 해석
이 연산은 다음을 의미한다.
- 짧은 시간 구간에서의 패턴을 감지
- 위치가 달라도 동일한 패턴을 같은 특징으로 인식
- 노이즈에 비교적 강인
CNN의 출력은 다음과 같은 형태가 된다.
- : CNN 필터 개수
- : padding/stride에 따라 줄어든 시간 길이
3.3 Pooling의 역할 (선택적)
Pooling이 사용될 경우,
- 미세한 시간 정렬 오차에 둔감
- 계산량 감소
- 그러나 시간 해상도 손실
→ LSTM과 결합 시에는 과도한 pooling은 피하는 경우가 많다
4. LSTM 단계: 시간적 의존성 학습
CNN 출력 를 LSTM의 입력 시퀀스로 사용한다.
4.1 LSTM 내부 연산
각 시점 에서 LSTM은 다음을 계산한다.
4.2 CNN과 결합되었을 때의 의미
- LSTM은 원시 신호가 아니라
CNN이 요약한 고수준 특징 시퀀스를 처리 - 불필요한 단기 변동은 CNN에서 제거됨
- LSTM은 장기 흐름에 집중 가능
5. 출력 구조
문제 유형에 따라 출력 방식이 달라진다.
5.1 시계열 분류
- 마지막 hidden state 사용
5.2 시계열 회귀 / 예측
- 마지막 또는 모든 시점의 hidden state 사용
5.3 이상 탐지 (Autoencoder 계열)
- LSTM Decoder를 추가하여 재구성 오차 사용
6. CNN–LSTM의 설계 의도 정리
| 단계 | 설계 목적 |
|---|---|
| CNN | 국소 패턴 자동 추출, 노이즈 완화 |
| LSTM | 시간 순서 및 장기 의존성 모델링 |
| 결합 | 역할 분리로 학습 안정성 향상 |
CNN–LSTM은 다음 가정을 내포한다.
“의미 있는 단기 패턴이 먼저 존재하고,
그 패턴들의 시간적 조합이 전체 의미를 결정한다.”
7. 장점과 한계
7.1 장점
- 원시 시계열에서 수작업 feature engineering 감소
- LSTM 단독 사용 대비 학습 안정성 증가
- 다변량 센서 데이터에 적합
7.2 한계
- 구조가 비교적 무거움 (CNN + LSTM)
- 매우 긴 시계열에서는 여전히 비효율
- 전역 의존성 모델링에는 Transformer 대비 한계
8. 언제 CNN–LSTM을 사용하는가
다음 조건일 때 특히 효과적이다.
- 짧은 주기의 반복 패턴이 중요한 경우
- 센서 신호, 진동, 로그 시계열
- 이상 탐지, 상태 분류, 이벤트 인식
반대로,
- 장기 의존성이 매우 길거나
- 전역 패턴이 중요한 경우
→ TCN, Transformer 계열이 더 적합할 수 있다.
9. 코드
class CNNLSTM(nn.Module):
def __init__(
self,
input_dim, # D
cnn_channels, # C
kernel_size, # K
lstm_hidden_dim, # H
lstm_layers,
num_classes,
dropout=0.0
):
super().__init__()
# -------------------------
# 1. CNN (1D Convolution)
# -------------------------
self.conv1d = nn.Conv1d(
in_channels=input_dim,
out_channels=cnn_channels,
kernel_size=kernel_size,
padding=kernel_size // 2 # time length 유지
)
self.relu = nn.ReLU()
# -------------------------
# 2. LSTM
# -------------------------
self.lstm = nn.LSTM(
input_size=cnn_channels,
hidden_size=lstm_hidden_dim,
num_layers=lstm_layers,
batch_first=True,
dropout=dropout if lstm_layers > 1 else 0.0
)
# -------------------------
# 3. Output layer
# -------------------------
self.fc = nn.Linear(lstm_hidden_dim, num_classes)
def forward(self, x):
"""
x: (B, T, D)
"""
# -------------------------
# CNN expects (B, D, T)
# -------------------------
x = x.permute(0, 2, 1)
# (B, C, T)
x = self.conv1d(x)
x = self.relu(x)
# -------------------------
# LSTM expects (B, T, C)
# -------------------------
x = x.permute(0, 2, 1)
# x: (B, T, C)
lstm_out, (h_n, c_n) = self.lstm(x)
# -------------------------
# 마지막 시점 hidden state
# -------------------------
h_last = lstm_out[:, -1, :] # (B, H)
# -------------------------
# Output
# -------------------------
out = self.fc(h_last) # (B, num_classes)
return out- pytorch conv1d 입력 형식 : (batch, channels, length)
- 시계열 데이터 : (batch, time, features)
→ 시간 축을 length로 보기 위해 permute가 필수
