[기초] DataBase

1.1 Database는 무엇인가
데이터베이스(Database, DB)는 여러 사람이 공유할 목적으로 체계화하여 통합, 관리하는 데이터의 집합입니다. 단순히 데이터를 저장하는 것을 넘어, 효율적으로 관리하고 필요할 때 신속하게 접근할 수 있도록 지원하는 정보 저장소입니다.
데이터베이스의 정의와 역할
핵심 기능
- 체계적 저장: 데이터를 구조화하여 중복 없이 저장
- 효율적 검색: 필요한 데이터를 빠르게 찾아 제공
- 데이터 수정: 삽입(Insert), 삭제(Delete), 갱신(Update) 지원
- 동시 접근: 여러 사용자가 동시에 데이터 이용 가능
실생활 예시
- 은행 시스템: 고객 정보, 거래 내역, 계좌 정보 관리
- 전자상거래: 상품 정보, 주문 내역, 재고 관리
- 소셜 미디어: 사용자 프로필, 게시물, 댓글 저장
- 병원 시스템: 환자 기록, 진료 내역, 처방전 관리
데이터베이스의 특징
1. 실시간 접근성 (Real-Time Accessibility)
- 사용자의 요구에 실시간으로 응답
- 즉각적인 데이터 조회 및 처리 가능
2. 계속적인 변화 (Continuous Evolution)
- 새로운 데이터의 삽입(Insert)
- 불필요한 데이터의 삭제(Delete)
- 기존 데이터의 갱신(Update)
- 항상 최신 상태의 데이터 유지
3. 동시 공용 (Concurrent Sharing)
- 다수의 사용자가 동시에 같은 데이터 이용
- 동시성 제어를 통한 데이터 일관성 유지
4. 내용에 의한 참조 (Content Reference)
- 데이터의 물리적 위치가 아닌 내용으로 검색
- 사용자 요구에 따른 데이터 내용으로 접근
데이터베이스 관리 시스템 (DBMS)
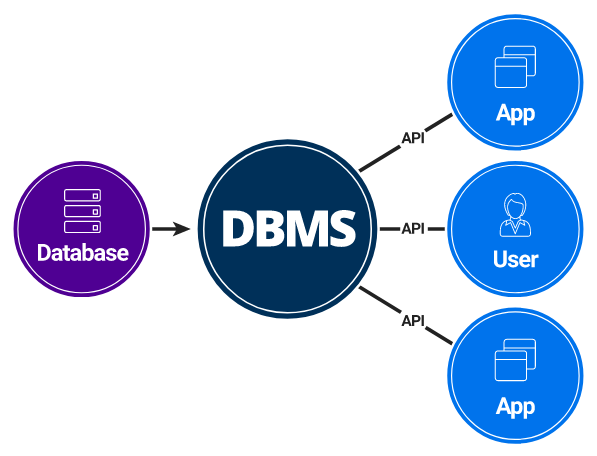
DBMS의 정의
- Database Management System의 약자
- 데이터베이스를 관리하고 운영하는 소프트웨어
- 사용자와 데이터베이스 사이의 인터페이스 역할
DBMS의 주요 기능
- 데이터 정의: 데이터 구조 정의 및 스키마 관리
- 데이터 조작: 검색, 삽입, 수정, 삭제 기능 제공
- 데이터 제어: 접근 권한 관리 및 보안 유지
- 데이터 공유: 여러 사용자의 동시 접근 지원
- 데이터 무결성: 데이터의 정확성과 일관성 보장
DBMS의 장점
- 데이터 중복 최소화
- 데이터 일관성 유지
- 데이터 보안 강화
- 데이터 표준화
- 프로그램과 데이터의 독립성
데이터베이스의 발전 역사
1세대: 계층형 데이터베이스 (Hierarchical DB)
- 1960년대 등장
- 트리(Tree) 구조로 데이터 구성
- 부모-자식 관계로 데이터 연결
- 단점: 구조 변경 어려움, 데이터 검색 비효율적
- 현재는 거의 사용되지 않음
2세대: 망형 데이터베이스 (Network DB)
- 계층형 DB의 문제점 개선
- 네트워크처럼 데이터 간 자유로운 연결
- 단점: 복잡한 구조로 프로그래밍 어려움
- 현재는 거의 사용되지 않음
3세대: 관계형 데이터베이스 (Relational DB)
- 1970년대 에드가 F. 커드(Edgar F. Codd)가 제안
- 테이블(Table) 형태로 데이터 저장
- SQL을 통한 데이터 관리
- 현재 가장 널리 사용되는 형태
4세대: NoSQL 데이터베이스
- 2000년대 이후 빅데이터 시대에 등장
- 비정형 데이터 처리에 적합
- 수평적 확장성 우수
- 다양한 데이터 모델 지원
1.2 Database 구성 요소
데이터베이스는 여러 구성 요소가 유기적으로 결합하여 데이터를 효과적으로 저장하고 관리합니다. 각 구성 요소의 역할과 관계를 이해하는 것이 중요합니다.
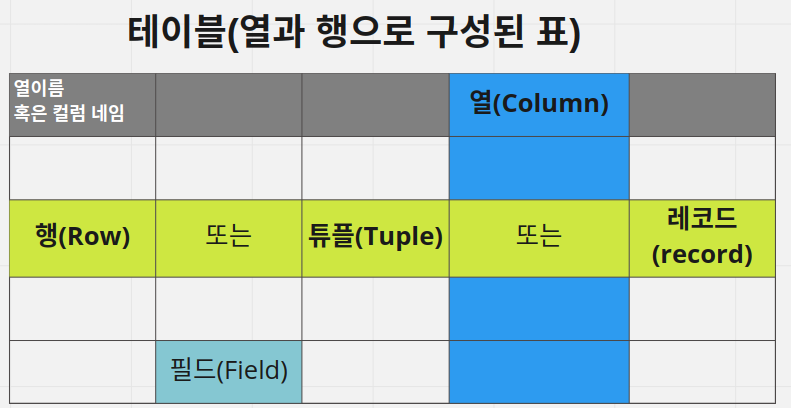
테이블 (Table)
정의: 데이터베이스에서 데이터를 저장하는 기본 단위
구조
- 행(Row): 개별 데이터 레코드를 나타냄 (튜플, Tuple)
- 열(Column): 데이터의 속성을 정의 (필드, Field)
- 행과 열이 교차하는 지점에 실제 데이터 값 저장
예시: 고객 정보 테이블
고객ID | 이름 | 전화번호 | 주소
-------|---------|--------------|------------------
001 | 홍길동 | 010-1234-5678| 서울시 강남구
002 | 김철수 | 010-9876-5432| 부산시 해운대구
003 | 이영희 | 010-5555-1234| 대구시 수성구레코드 (Record)
정의: 테이블의 각 행(Row)을 의미하며, 하나의 완전한 데이터 단위
특징
- 각 열에 해당하는 데이터 값을 포함
- 테이블의 스키마에 정의된 구조를 따름
- 고유 식별자(Primary Key)로 구분 가능
예시
- 고객 테이블의 한 레코드: (001, 홍길동, 010-1234-5678, 서울시 강남구)
- 각 필드가 모여 하나의 완전한 고객 정보 구성
필드 (Field) / 속성 (Attribute)
정의: 테이블의 열(Column)을 의미하며, 데이터의 특정 속성을 나타냄
필드의 구성 요소
- 필드명: 속성의 이름 (예: 이름, 전화번호)
- 데이터 타입: 저장할 데이터의 형식 (문자열, 숫자, 날짜 등)
- 제약 조건: 데이터 입력 규칙 (NOT NULL, UNIQUE 등)
주요 데이터 타입
- 문자형: VARCHAR, CHAR, TEXT
- 숫자형: INT, BIGINT, DECIMAL, FLOAT
- 날짜/시간: DATE, TIME, DATETIME, TIMESTAMP
- 논리형: BOOLEAN
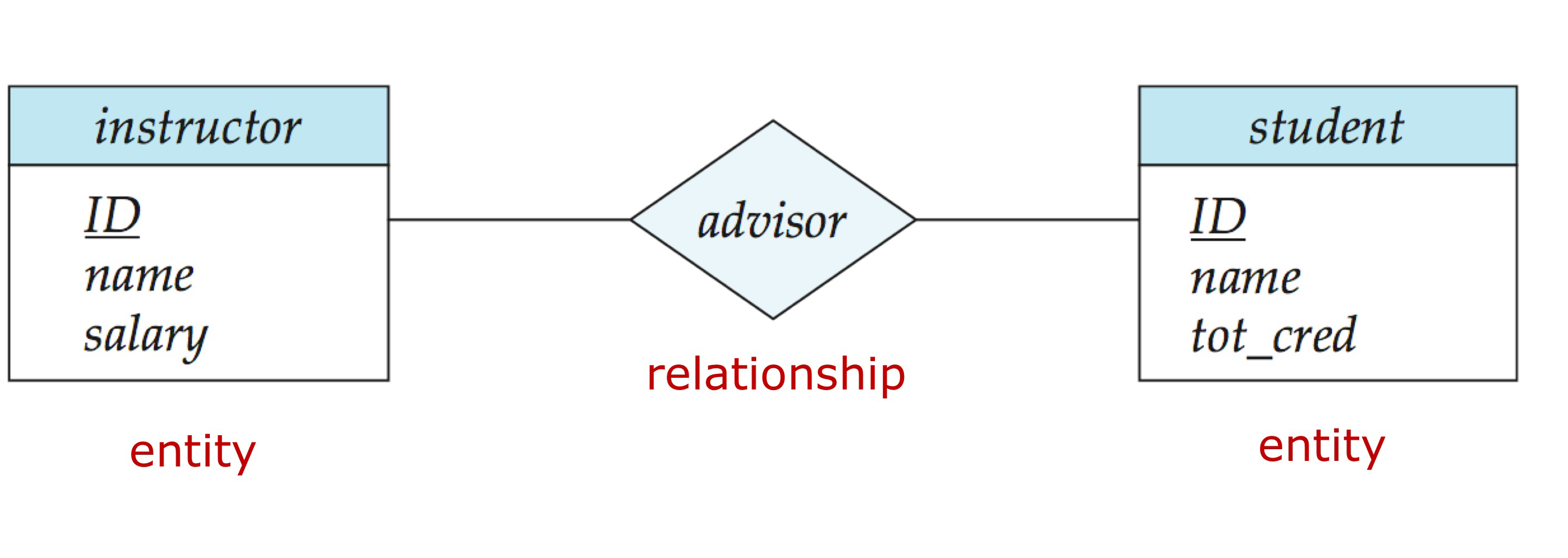
엔티티 (Entity)
정의: 독립적으로 존재하면서 고유하게 식별 가능한 실세계의 객체나 개념
엔티티의 특징
- 사람, 장소, 사물, 사건 등을 나타냄
- 여러 속성(Attribute)으로 구성
- 데이터베이스에서 테이블로 구현됨
엔티티 예시
- 고객 엔티티: 고객ID, 이름, 전화번호, 주소
- 상품 엔티티: 상품ID, 상품명, 가격, 재고량
- 주문 엔티티: 주문ID, 주문일자, 고객ID, 총액
스키마 (Schema)
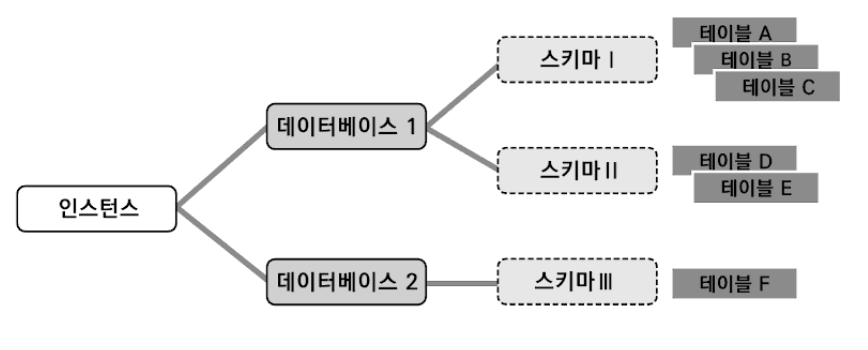
정의: 데이터베이스의 구조와 제약 조건을 정의한 설계도
스키마의 종류
1. 외부 스키마 (External Schema)
- 사용자 관점의 데이터베이스 구조
- 개별 사용자나 응용 프로그램이 보는 뷰(View)
- 여러 개 존재 가능
2. 개념 스키마 (Conceptual Schema)
- 조직 전체의 데이터베이스 구조
- 모든 사용자가 공유하는 논리적 구조
- 일반적으로 '스키마'라고 하면 개념 스키마를 의미
3. 내부 스키마 (Internal Schema)
- 물리적 저장 구조
- 실제 데이터가 저장되는 방식 정의
- 하나만 존재
키 (Key)
정의: 테이블에서 레코드를 고유하게 식별하거나 관계를 정의하는 속성
주요 키의 종류
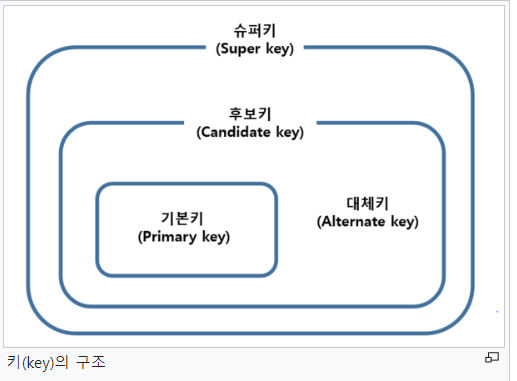
1. 기본 키 (Primary Key, PK)
- 각 레코드를 고유하게 식별하는 속성
- NULL 값 불가, 중복 불가
- 테이블당 하나만 존재
- 예: 고객ID, 주문번호
2. 외래 키 (Foreign Key, FK)
- 다른 테이블의 기본 키를 참조하는 속성
- 테이블 간 관계를 정의
- 참조 무결성 유지
- 예: 주문 테이블의 고객ID (고객 테이블 참조)
3. 후보 키 (Candidate Key)
- 기본 키가 될 수 있는 속성들
- 유일성과 최소성을 만족
4. 대체 키 (Alternate Key)
- 후보 키 중 기본 키로 선택되지 않은 키
5. 복합 키 (Composite Key)
- 두 개 이상의 속성을 조합한 키
관계 (Relationship)
정의: 엔티티(테이블) 간의 연관성을 나타내는 개념
관계의 유형
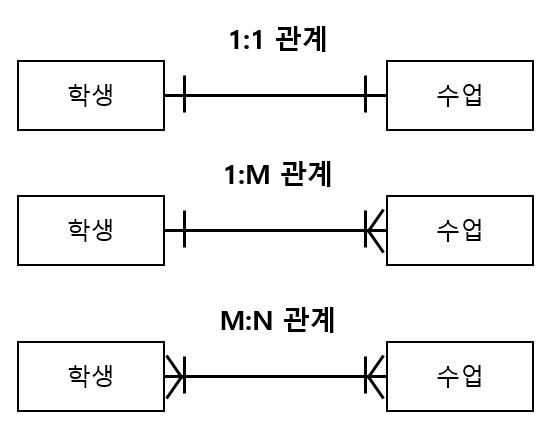
1. 일대일 (1:1) 관계
- 한 엔티티의 레코드가 다른 엔티티의 정확히 하나의 레코드와 연결
- 예: 사원 - 사원증 (한 사원은 하나의 사원증만 보유)
2. 일대다 (1:N) 관계
- 한 엔티티의 레코드가 다른 엔티티의 여러 레코드와 연결
- 가장 흔한 관계 유형
- 예: 고객 - 주문 (한 고객이 여러 주문 가능)
3. 다대다 (N:M) 관계
- 양쪽 엔티티의 레코드가 서로 여러 개와 연결
- 중간 테이블(연결 테이블)로 구현
- 예: 학생 - 과목 (한 학생이 여러 과목 수강, 한 과목을 여러 학생이 수강)
인덱스 (Index)
정의: 데이터 검색 속도를 향상시키기 위한 데이터 구조
인덱스의 원리
- 책의 색인과 유사한 개념
- 특정 열의 값과 해당 레코드의 위치 정보 저장
- B-Tree, Hash 등의 자료구조 사용
인덱스의 장점
- 검색 속도 대폭 향상 (특히 대용량 데이터)
- WHERE, ORDER BY, JOIN 연산 최적화
- 데이터 정렬 비용 감소
인덱스의 단점
- 추가 저장 공간 필요
- INSERT, UPDATE, DELETE 시 성능 저하
- 인덱스 유지 관리 비용
인덱스 사용 전략
- 자주 검색되는 열에 생성
- WHERE 절에 자주 사용되는 열
- JOIN 조건으로 사용되는 열
- 카디널리티(고유값 비율)가 높은 열
1.3 DB 생성 원칙
효과적인 데이터베이스를 설계하기 위해서는 체계적인 원칙과 방법론을 따라야 합니다. 데이터 무결성, 정규화, 성능 최적화 등을 고려한 설계가 필요합니다.
데이터 무결성 (Data Integrity)
정의: 데이터의 정확성, 일관성, 유효성이 유지되는 것
무결성의 종류
1. 개체 무결성 (Entity Integrity)
- 기본 키는 NULL 값을 가질 수 없음
- 기본 키는 중복될 수 없음
- 각 레코드를 고유하게 식별 보장
2. 참조 무결성 (Referential Integrity)
- 외래 키 값은 참조 테이블의 기본 키 값이어야 함
- 또는 NULL 값 허용 (선택적 관계인 경우)
- 존재하지 않는 데이터 참조 방지
3. 도메인 무결성 (Domain Integrity)
- 각 속성 값은 정의된 도메인(범위) 내에 있어야 함
- 데이터 타입, 길이, 형식 제약 준수
- CHECK 제약 조건으로 구현
4. 사용자 정의 무결성 (User-Defined Integrity)
- 비즈니스 규칙에 따른 제약 조건
- 예: 주문 수량은 0보다 커야 함
정규화 (Normalization)
정의: 데이터 중복을 최소화하고 무결성을 향상시키기 위해 테이블을 분해하는 과정
정규화의 목적
- 데이터 중복 제거
- 삽입/수정/삭제 이상(Anomaly) 방지
- 데이터 일관성 유지
- 저장 공간 효율화
제1정규형 (1NF)
- 모든 속성 값은 원자값(Atomic Value)이어야 함
- 반복 그룹 제거
- 각 열은 하나의 값만 포함
예시
비정규형:
학생ID | 이름 | 수강과목
001 | 홍길동 | 수학, 영어, 과학
1NF:
학생ID | 이름 | 수강과목
001 | 홍길동 | 수학
001 | 홍길동 | 영어
001 | 홍길동 | 과학제2정규형 (2NF)
- 1NF를 만족
- 부분 함수 종속 제거
- 기본 키가 아닌 모든 속성이 기본 키에 완전 함수 종속
제3정규형 (3NF)
- 2NF를 만족
- 이행적 함수 종속 제거
- 기본 키가 아닌 속성 간의 종속 관계 제거
역정규화 (Denormalization)
정의: 성능 향상을 위해 의도적으로 중복을 허용하는 과정
역정규화가 필요한 경우
- 조인 연산이 너무 많아 성능 저하
- 복잡한 쿼리로 인한 응답 시간 증가
- 읽기 작업이 압도적으로 많은 경우
역정규화 기법
- 테이블 통합: 자주 조인되는 테이블 병합
- 중복 열 추가: 계산 결과나 집계 값 저장
- 파생 열 추가: 자주 계산되는 값 미리 저장
- 요약 테이블: 집계 데이터를 별도 테이블로 관리
주의사항
- 데이터 일관성 유지 메커니즘 필요
- 업데이트 비용 증가 고려
- 저장 공간 증가 감수
명명 규칙 (Naming Convention)
테이블 명명 규칙
- 명확하고 의미 있는 이름 사용
- 복수형 사용 권장 (예: users, orders)
- 소문자와 언더스코어 사용 (snake_case)
- 예약어 사용 금지
열 명명 규칙
- 설명적이고 간결한 이름
- 테이블명 접두사 불필요 (테이블 컨텍스트에서 명확)
- 일관된 명명 패턴 유지
- 예: user_id, created_at, email_address
제약 조건 명명
- PK: pk_테이블명
- FK: fk테이블명참조테이블명
- INDEX: idx테이블명열명
- UNIQUE: uq테이블명열명
데이터베이스 설계 프로세스
1단계: 요구사항 분석
- 비즈니스 요구사항 파악
- 데이터 항목 식별
- 사용자 요구사항 수집
2단계: 개념적 설계
- ER(Entity-Relationship) 다이어그램 작성
- 엔티티와 관계 정의
- 속성 식별
3단계: 논리적 설계
- ER 다이어그램을 관계형 스키마로 변환
- 정규화 수행
- 키 정의 (기본 키, 외래 키)
4단계: 물리적 설계
- DBMS 선택
- 인덱스 설계
- 파티셔닝 전략
- 저장 공간 할당
5단계: 구현 및 테스트
- DDL(Data Definition Language)로 스키마 생성
- 샘플 데이터로 테스트
- 성능 튜닝
성능 최적화 원칙
쿼리 최적화
- SELECT 시 필요한 열만 조회 (SELECT * 지양)
- WHERE 절에 인덱스 활용
- 서브쿼리보다 JOIN 사용 권장
- LIMIT 절로 결과 제한
인덱스 전략
- 자주 검색되는 열에 인덱스 생성
- 복합 인덱스 활용 (여러 열 조합)
- 인덱스 개수 적정 유지 (과도한 인덱스는 역효과)
테이블 파티셔닝
- 대용량 테이블을 작은 단위로 분할
- 범위, 리스트, 해시 파티셔닝
- 쿼리 성능 향상 및 관리 용이성
캐싱 전략
- 자주 조회되는 데이터 캐싱
- Redis, Memcached 등 활용
- 데이터베이스 부하 감소
1.4 RDBMS와 NoSQL 비교
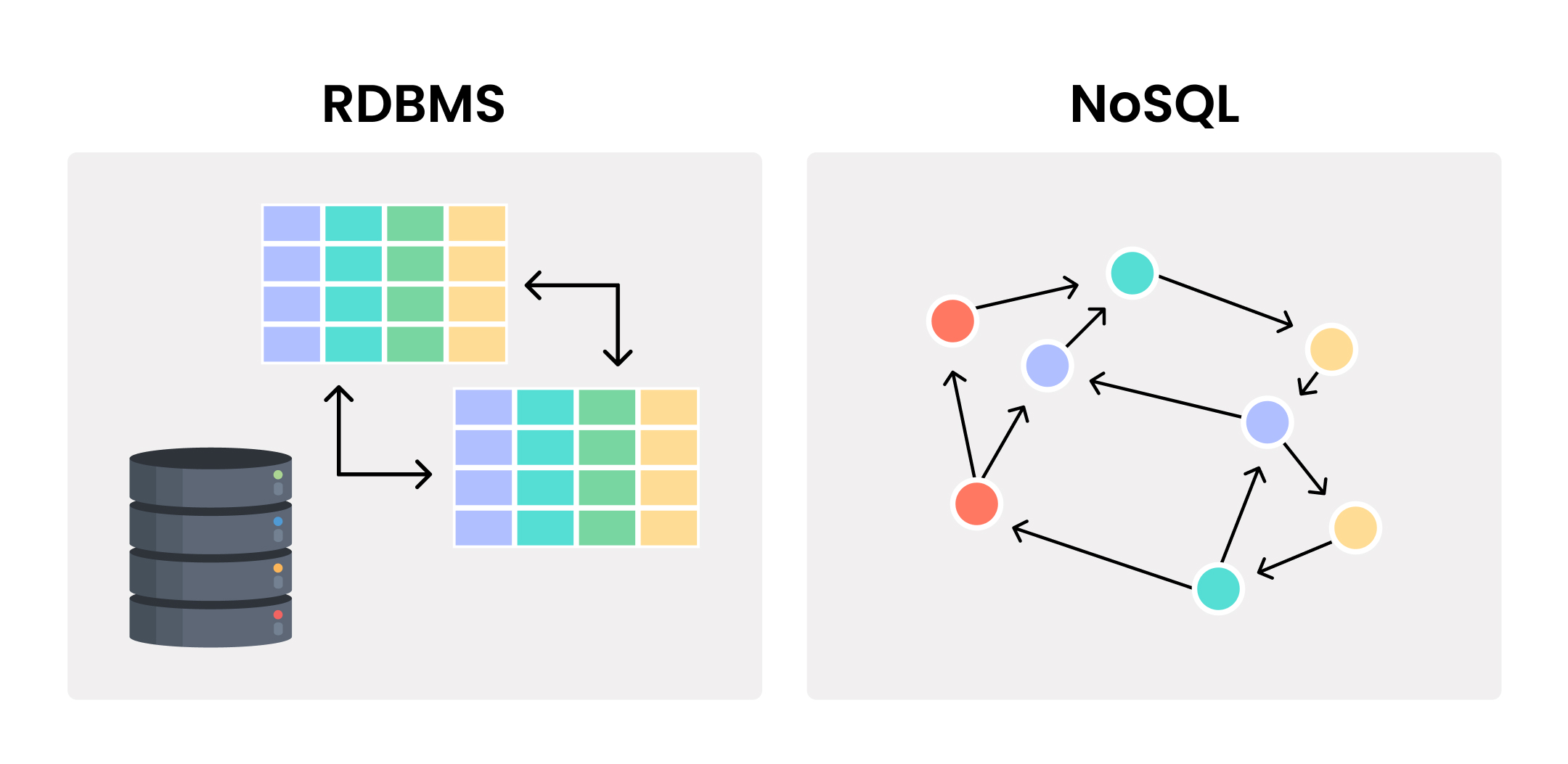
데이터베이스는 크게 관계형 데이터베이스(RDBMS)와 NoSQL 데이터베이스로 구분됩니다. 각각의 철학, 구조, 강점이 완전히 다르며, 프로젝트의 특성에 따라 적절한 선택이 필요합니다.
RDBMS (관계형 데이터베이스)
정의: 테이블 간의 관계를 기반으로 데이터를 구조화하여 관리하는 데이터베이스 시스템
핵심 철학
- 정확성과 일관성 중심: 한 글자, 한 숫자라도 틀리면 안 되는 데이터 관리
- ACID 트랜잭션: 데이터 무결성을 최우선으로 보장
- 구조화된 데이터: 명확한 스키마로 데이터 구조 정의
데이터 모델
- 테이블(Table) 형식의 관계형 데이터 모델
- 행(Row)과 열(Column)로 구성
- 테이블 간 관계(Relationship)로 연결
- 정형화된 데이터 저장
스키마
- 정적 스키마 (Static Schema)
- 데이터 구조를 미리 정의 필수
- 데이터 타입과 제약 조건 명시
- 스키마 변경이 어렵고 신중해야 함
RDBMS의 장점
1. 데이터 무결성 보장
- ACID 속성으로 트랜잭션 안정성 확보
- 참조 무결성으로 데이터 일관성 유지
- 제약 조건으로 잘못된 데이터 입력 방지
2. 표준화된 쿼리 언어
- SQL이라는 강력하고 표준화된 언어 제공
- 복잡한 쿼리와 조인 연산 지원
- 학습 곡선이 완만하고 자료 풍부
3. 데이터 중복 최소화
- 정규화를 통한 중복 제거
- 저장 공간 효율적 사용
- 데이터 일관성 유지 용이
4. 성숙한 생태계
- 수십 년간 검증된 기술
- 풍부한 도구와 라이브러리
- 전문 인력 확보 용이
RDBMS의 단점
1. 확장성 제한
- 수직 확장(Scale-up)에 의존
- 서버 성능 향상에 한계 존재
- 수평 확장(Scale-out) 어려움
2. 스키마 유연성 부족
- 스키마 변경이 복잡하고 비용 높음
- 애자일 개발 환경에 부적합할 수 있음
- 비정형 데이터 처리 어려움
3. 성능 이슈
- 대용량 데이터 처리 시 성능 저하
- 복잡한 조인 연산의 비용
- 특수 하드웨어 필요 가능성
4. 고정된 구조
- 다양한 형태의 데이터 저장 제약
- 반정형/비정형 데이터 처리 한계
주요 RDBMS 제품
MySQL
- 가장 널리 사용되는 오픈소스 RDBMS
- LAMP 스택의 핵심 구성 요소
- 웹 애플리케이션에 최적화
- 커뮤니티 에디션 무료 제공
PostgreSQL
- 고급 기능을 갖춘 오픈소스 RDBMS
- ACID 준수 및 확장성 우수
- 복잡한 쿼리와 대용량 데이터 처리
- JSON 지원으로 NoSQL 기능 일부 제공
Oracle Database
- 대기업용 상용 데이터베이스
- 최고 수준의 성능과 안정성
- 엔터프라이즈 기능 풍부
- 높은 라이선스 비용
Microsoft SQL Server
- 마이크로소프트의 상용 RDBMS
- Windows 환경과 긴밀한 통합
- .NET 개발과 호환성 우수
- Azure 클라우드 지원
MariaDB
- MySQL의 포크 프로젝트
- MySQL과 높은 호환성
- 오픈소스 정책 유지
- 성능 개선 및 추가 기능
SQLite
- 경량 임베디드 데이터베이스
- 서버 없이 파일 기반 동작
- 모바일 앱, 소규모 프로젝트에 적합
RDBMS 적합한 사용 사례
금융 시스템
- 은행 거래, 결제 시스템
- 정확성과 일관성이 최우선
- ACID 트랜잭션 필수
- 감사 추적(Audit Trail) 필요
전자상거래
- 주문 관리, 재고 관리
- 복잡한 비즈니스 로직
- 데이터 무결성 중요
- 트랜잭션 처리 빈번
ERP/CRM 시스템
- 기업 자원 관리
- 고객 관계 관리
- 정형화된 데이터 구조
- 복잡한 관계와 제약 조건
회계 시스템
- 재무 데이터 관리
- 정확한 계산과 기록
- 법적 요구사항 준수
NoSQL (비관계형 데이터베이스)
정의: "Not Only SQL"의 약자로, 관계형 모델을 따르지 않는 다양한 형태의 데이터베이스
핵심 철학
- 유연성과 확장성 중심: 빠르게 변화하는 데이터 구조 대응
- 수평적 확장: 서버 추가로 성능 향상
- 비정형 데이터 처리: 다양한 형태의 데이터 저장
데이터 모델
- 다양한 데이터 모델 지원
- 키-값(Key-Value), 문서(Document), 열 지향(Column-family), 그래프(Graph)
- 비정형 또는 반정형 데이터 저장
- 스키마리스(Schema-less) 또는 동적 스키마
스키마
- 동적 스키마 (Dynamic Schema)
- 데이터 구조를 미리 정의할 필요 없음
- 필드 추가/삭제가 자유로움
- 애자일 개발에 적합
NoSQL의 장점
1. 수평적 확장성
- 서버 추가로 성능 향상 (Scale-out)
- 클러스터링을 통한 분산 처리
- 대용량 데이터 처리에 유리
- 비용 효율적인 확장
2. 유연한 스키마
- 스키마 변경이 자유로움
- 다양한 형태의 데이터 저장 가능
- 빠른 개발 및 반복 가능
- 비정형 데이터 처리 우수
3. 높은 성능
- 특정 작업에 최적화된 구조
- 빠른 읽기/쓰기 속도
- 상용 하드웨어 사용 가능
- 캐싱 메커니즘 내장
4. 대용량 데이터 처리
- 빅데이터 환경에 적합
- 실시간 분석 지원
- 로그 데이터, 센서 데이터 처리
NoSQL의 단점
1. 데이터 일관성 약화
- ACID 대신 BASE 모델 (Basically Available, Soft state, Eventually consistent)
- 최종 일관성(Eventually Consistent) 보장
- 즉각적인 일관성 보장 어려움
2. 표준화 부족
- 각 NoSQL 데이터베이스마다 고유한 쿼리 언어
- SQL처럼 표준화된 언어 없음
- 학습 곡선이 가파를 수 있음
3. 복잡한 쿼리 제한
- 조인 연산 미지원 또는 제한적
- 복잡한 트랜잭션 처리 어려움
- 애플리케이션 레벨에서 처리 필요
4. 성숙도
- RDBMS에 비해 역사가 짧음
- 도구와 생태계가 상대적으로 부족
- 전문 인력 확보 어려울 수 있음
NoSQL 데이터베이스 유형
1. 문서 데이터베이스 (Document Database)
- JSON, BSON, XML 형식으로 데이터 저장
- 계층적 데이터 구조 지원
- 예: MongoDB, CouchDB, Elasticsearch
- 사용 사례: 콘텐츠 관리, 사용자 프로필
2. 키-값 데이터베이스 (Key-Value Store)
- 단순한 키-값 쌍으로 데이터 저장
- 매우 빠른 읽기/쓰기 성능
- 예: Redis, Memcached, DynamoDB
- 사용 사례: 캐싱, 세션 관리, 실시간 분석
3. 열 지향 데이터베이스 (Column-family Store)
- 열 단위로 데이터 저장 및 압축
- 대용량 데이터 분석에 최적화
- 예: Cassandra, HBase, Google Bigtable
- 사용 사례: 시계열 데이터, 로그 분석
4. 그래프 데이터베이스 (Graph Database)
- 노드와 엣지로 관계 표현
- 복잡한 관계 쿼리에 최적화
- 예: Neo4j, ArangoDB, Amazon Neptune
- 사용 사례: 소셜 네트워크, 추천 시스템, 지식 그래프
주요 NoSQL 제품
MongoDB
- 가장 인기 있는 문서 데이터베이스
- JSON 형식의 BSON 문서 저장
- 풍부한 쿼리 기능과 인덱싱
- 수평적 확장 지원 (샤딩)
Redis
- 인메모리 키-값 저장소
- 초고속 읽기/쓰기 성능
- 다양한 데이터 구조 지원 (문자열, 리스트, 셋, 해시)
- 캐싱, 세션 관리에 널리 사용
Cassandra
- 분산 열 지향 데이터베이스
- 높은 가용성과 확장성
- 쓰기 성능 우수
- 대용량 데이터 처리
Elasticsearch
- 검색 및 분석 엔진
- 전문 검색(Full-text Search) 기능
- 실시간 데이터 분석
- 로그 및 이벤트 데이터 처리
Neo4j
- 그래프 데이터베이스
- 관계 중심 데이터 모델
- Cypher 쿼리 언어
- 소셜 네트워크, 추천 시스템
NoSQL 적합한 사용 사례
소셜 미디어 플랫폼
- 사용자 피드, 게시물, 댓글
- 비정형 데이터 (이미지, 동영상 메타데이터)
- 대량의 읽기/쓰기 작업
- 실시간 업데이트
IoT 및 센서 데이터
- 시계열 데이터 수집
- 초당 수만 건의 데이터 발생
- 실시간 분석 필요
- 스키마 변경 빈번
콘텐츠 관리 시스템
- 다양한 형태의 콘텐츠
- 유연한 데이터 구조
- 빠른 검색 기능
- 확장 가능한 아키텍처
실시간 분석
- 로그 데이터 분석
- 사용자 행동 추적
- 대시보드 및 리포팅
- 빅데이터 처리
캐싱 레이어
- 데이터베이스 부하 감소
- 응답 시간 단축
- 세션 관리
- 임시 데이터 저장
RDBMS vs NoSQL 비교표
| 특성 | RDBMS | NoSQL |
|---|---|---|
| 데이터 모델 | 테이블 기반 관계형 | 문서, 키-값, 열, 그래프 |
| 스키마 | 정적, 사전 정의 필수 | 동적, 유연함 |
| 확장성 | 수직 확장 (Scale-up) | 수평 확장 (Scale-out) |
| 트랜잭션 | ACID 보장 | BASE (최종 일관성) |
| 쿼리 언어 | SQL (표준화) | 제품마다 다름 |
| 데이터 무결성 | 강력함 | 상대적으로 약함 |
| 성능 | 복잡한 쿼리에 강함 | 단순 읽기/쓰기에 빠름 |
| 사용 사례 | 금융, ERP, 전자상거래 | 소셜미디어, IoT, 빅데이터 |
| 데이터 중복 | 최소화 (정규화) | 허용 (역정규화) |
| 조인 | 지원 | 제한적 또는 미지원 |
선택 가이드: RDBMS vs NoSQL
RDBMS를 선택해야 하는 경우
- 데이터 무결성과 일관성이 최우선
- 복잡한 트랜잭션 처리 필요
- 정형화된 데이터 구조
- 복잡한 조인과 쿼리 빈번
- ACID 속성 필수
- 예: 은행 시스템, 회계 시스템, ERP
NoSQL을 선택해야 하는 경우
- 대용량 데이터 처리
- 빠른 읽기/쓰기 성능 필요
- 스키마가 자주 변경됨
- 수평적 확장 필요
- 비정형/반정형 데이터
- 예: 소셜 미디어, IoT, 실시간 분석
하이브리드 접근
- 많은 현대 애플리케이션은 두 가지를 함께 사용
- RDBMS: 핵심 트랜잭션 데이터
- NoSQL: 캐싱, 세션, 로그 데이터
- 각 데이터베이스의 강점 활용
- Polyglot Persistence 패턴
2.5 SQL 언어
SQL(Structured Query Language)은 관계형 데이터베이스에서 데이터를 관리하기 위한 표준 프로그래밍 언어입니다. 1970년대부터 사용되어 온 SQL은 데이터 정의, 조작, 제어를 위한 강력하고 표준화된 도구입니다.
SQL의 개요
정의
- "Structured Query Language"의 약자
- "에스큐엘" 또는 "시퀄"로 발음
- 관계형 데이터베이스의 표준 언어
- ANSI/ISO 표준으로 제정
SQL의 역할
- 데이터베이스 레코드 삽입, 검색, 업데이트, 삭제
- 데이터베이스 스키마 생성 및 수정
- 접근 권한 설정 및 관리
- 데이터베이스 최적화 및 유지 관리
SQL의 특징
- 선언적 언어 (무엇을 할지 명시, 어떻게 할지는 DBMS가 결정)
- 집합 기반 언어 (한 번에 여러 행 처리)
- 대소문자 구분 없음 (관례적으로 키워드는 대문자)
- 세미콜론(;)으로 문장 종료
SQL의 분류
1. DDL (Data Definition Language) - 데이터 정의어
- 데이터베이스 구조를 정의하고 수정
- 주요 명령어: CREATE, ALTER, DROP, TRUNCATE
- 스키마, 테이블, 인덱스 등 생성/수정/삭제
2. DML (Data Manipulation Language) - 데이터 조작어
- 데이터를 조회하고 변경
- 주요 명령어: SELECT, INSERT, UPDATE, DELETE
- 가장 빈번하게 사용되는 SQL 명령어
3. DCL (Data Control Language) - 데이터 제어어
- 데이터 접근 권한 관리
- 주요 명령어: GRANT, REVOKE
- 사용자 권한 부여 및 회수
4. TCL (Transaction Control Language) - 트랜잭션 제어어
- 트랜잭션 관리
- 주요 명령어: COMMIT, ROLLBACK, SAVEPOINT
- 데이터 변경 사항 확정 또는 취소
DDL (Data Definition Language)
CREATE - 데이터베이스 객체 생성
-- 데이터베이스 생성
CREATE DATABASE company;
-- 테이블 생성
CREATE TABLE employees (
employee_id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
hire_date DATE,
salary DECIMAL(10, 2),
department_id INT,
FOREIGN KEY (department_id) REFERENCES departments(department_id)
);
-- 인덱스 생성
CREATE INDEX idx_last_name ON employees(last_name);ALTER - 데이터베이스 객체 수정
-- 열 추가
ALTER TABLE employees ADD COLUMN phone VARCHAR(20);
-- 열 수정
ALTER TABLE employees MODIFY COLUMN salary DECIMAL(12, 2);
-- 열 삭제
ALTER TABLE employees DROP COLUMN phone;
-- 제약 조건 추가
ALTER TABLE employees ADD CONSTRAINT chk_salary CHECK (salary > 0);DROP - 데이터베이스 객체 삭제
-- 테이블 삭제 (구조와 데이터 모두 삭제)
DROP TABLE employees;
-- 데이터베이스 삭제
DROP DATABASE company;
-- 인덱스 삭제
DROP INDEX idx_last_name ON employees;TRUNCATE - 테이블 데이터 삭제
-- 테이블의 모든 데이터 삭제 (구조는 유지)
TRUNCATE TABLE employees;
-- DELETE보다 빠르지만 롤백 불가DML (Data Manipulation Language)
SELECT - 데이터 조회
-- 기본 조회
SELECT * FROM employees;
-- 특정 열 조회
SELECT first_name, last_name, salary FROM employees;
-- 조건부 조회 (WHERE)
SELECT * FROM employees WHERE salary > 50000;
-- 정렬 (ORDER BY)
SELECT * FROM employees ORDER BY salary DESC;
-- 제한 (LIMIT)
SELECT * FROM employees LIMIT 10;
-- 집계 함수
SELECT COUNT(*) FROM employees;
SELECT AVG(salary) FROM employees;
SELECT MAX(salary), MIN(salary) FROM employees;
-- 그룹화 (GROUP BY)
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id;
-- HAVING (그룹 조건)
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id
HAVING AVG(salary) > 60000;INSERT - 데이터 삽입
-- 단일 행 삽입
INSERT INTO employees (first_name, last_name, email, hire_date, salary, department_id)
VALUES ('John', 'Doe', 'john.doe@company.com', '2024-01-15', 65000.00, 1);
-- 여러 행 삽입
INSERT INTO employees (first_name, last_name, email, hire_date, salary, department_id)
VALUES
('Jane', 'Smith', 'jane.smith@company.com', '2024-01-20', 70000.00, 2),
('Bob', 'Johnson', 'bob.johnson@company.com', '2024-02-01', 55000.00, 1);
-- 다른 테이블에서 데이터 복사
INSERT INTO employees_backup
SELECT * FROM employees WHERE department_id = 1;UPDATE - 데이터 수정
-- 특정 행 수정
UPDATE employees
SET salary = 75000.00
WHERE employee_id = 1;
-- 여러 열 수정
UPDATE employees
SET salary = salary * 1.1,
email = 'new.email@company.com'
WHERE department_id = 2;
-- 조건부 수정
UPDATE employees
SET salary = salary * 1.05
WHERE hire_date < '2023-01-01';DELETE - 데이터 삭제
-- 특정 행 삭제
DELETE FROM employees WHERE employee_id = 1;
-- 조건부 삭제
DELETE FROM employees WHERE department_id = 3;
-- 모든 행 삭제 (테이블 구조는 유지)
DELETE FROM employees;JOIN - 테이블 결합
INNER JOIN - 교집합
-- 두 테이블의 일치하는 행만 반환
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
INNER JOIN departments d ON e.department_id = d.department_id;LEFT JOIN - 왼쪽 테이블 기준
-- 왼쪽 테이블의 모든 행 + 오른쪽 테이블의 일치하는 행
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
LEFT JOIN departments d ON e.department_id = d.department_id;RIGHT JOIN - 오른쪽 테이블 기준
-- 오른쪽 테이블의 모든 행 + 왼쪽 테이블의 일치하는 행
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
RIGHT JOIN departments d ON e.department_id = d.department_id;FULL OUTER JOIN - 합집합
-- 양쪽 테이블의 모든 행 (MySQL은 미지원, UNION으로 구현)
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
LEFT JOIN departments d ON e.department_id = d.department_id
UNION
SELECT e.first_name, e.last_name, d.department_name
FROM employees e
RIGHT JOIN departments d ON e.department_id = d.department_id;CROSS JOIN - 카티션 곱
-- 모든 가능한 조합
SELECT e.first_name, d.department_name
FROM employees e
CROSS JOIN departments d;SELF JOIN - 자기 자신과 조인
-- 같은 테이블을 두 번 참조
SELECT e1.first_name AS employee, e2.first_name AS manager
FROM employees e1
INNER JOIN employees e2 ON e1.manager_id = e2.employee_id;서브쿼리 (Subquery)
단일 행 서브쿼리
-- 평균 급여보다 높은 직원 조회
SELECT first_name, last_name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);다중 행 서브쿼리
-- IN 연산자 사용
SELECT first_name, last_name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location = 'Seoul'
);
-- ANY/ALL 연산자
SELECT first_name, salary
FROM employees
WHERE salary > ANY (
SELECT salary
FROM employees
WHERE department_id = 1
);상관 서브쿼리
-- 각 부서의 평균보다 높은 급여를 받는 직원
SELECT e1.first_name, e1.salary, e1.department_id
FROM employees e1
WHERE salary > (
SELECT AVG(salary)
FROM employees e2
WHERE e2.department_id = e1.department_id
);FROM 절 서브쿼리 (인라인 뷰)
SELECT dept_avg.department_id, dept_avg.avg_salary
FROM (
SELECT department_id, AVG(salary) as avg_salary
FROM employees
GROUP BY department_id
) AS dept_avg
WHERE dept_avg.avg_salary > 60000;트랜잭션 (Transaction)
트랜잭션의 정의
- 하나의 논리적 작업 단위를 구성하는 일련의 연산들
- 모두 성공하거나 모두 실패해야 함 (All or Nothing)
ACID 속성
- Atomicity (원자성): 트랜잭션의 모든 연산이 완전히 수행되거나 전혀 수행되지 않음
- Consistency (일관성): 트랜잭션 실행 전후 데이터베이스가 일관된 상태 유지
- Isolation (격리성): 동시 실행 트랜잭션들이 서로 영향을 주지 않음
- Durability (지속성): 완료된 트랜잭션의 결과는 영구적으로 반영
트랜잭션 제어 명령어
-- 트랜잭션 시작 (암묵적으로 시작됨)
START TRANSACTION;
-- 또는
BEGIN;
-- 작업 수행
UPDATE accounts SET balance = balance - 1000 WHERE account_id = 1;
UPDATE accounts SET balance = balance + 1000 WHERE account_id = 2;
-- 트랜잭션 확정 (변경사항 영구 저장)
COMMIT;
-- 트랜잭션 취소 (변경사항 되돌림)
ROLLBACK;
-- 저장점 설정
SAVEPOINT savepoint1;
-- 특정 저장점으로 롤백
ROLLBACK TO savepoint1;트랜잭션 예시
START TRANSACTION;
-- 계좌 이체 작업
UPDATE accounts
SET balance = balance - 100000
WHERE account_id = 'A001';
UPDATE accounts
SET balance = balance + 100000
WHERE account_id = 'B001';
-- 잔액 확인
SELECT balance FROM accounts WHERE account_id = 'A001';
-- 문제 없으면 확정
COMMIT;
-- 문제 있으면 취소
-- ROLLBACK;주요 RDBMS별 SQL 특징
MySQL
- 가장 널리 사용되는 오픈소스 RDBMS
- AUTO_INCREMENT로 자동 증가 컬럼 생성
- LIMIT 절로 결과 제한
- 다양한 스토리지 엔진 (InnoDB, MyISAM)
-- MySQL 특화 문법
SELECT * FROM employees LIMIT 10 OFFSET 20;
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100)
) ENGINE=InnoDB;PostgreSQL
- 고급 기능을 갖춘 오픈소스 RDBMS
- SERIAL 타입으로 자동 증가
- 강력한 JSON 지원
- 윈도우 함수, CTE 등 고급 기능
-- PostgreSQL 특화 문법
SELECT * FROM employees LIMIT 10 OFFSET 20;
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
metadata JSONB
);
-- CTE (Common Table Expression)
WITH dept_avg AS (
SELECT department_id, AVG(salary) as avg_sal
FROM employees
GROUP BY department_id
)
SELECT * FROM dept_avg WHERE avg_sal > 60000;Oracle Database
- 엔터프라이즈급 상용 RDBMS
- SEQUENCE로 자동 증가 구현
- ROWNUM으로 결과 제한
- PL/SQL 프로시저 언어
-- Oracle 특화 문법
SELECT * FROM employees WHERE ROWNUM <= 10;
CREATE SEQUENCE emp_seq START WITH 1;
INSERT INTO employees (id, name)
VALUES (emp_seq.NEXTVAL, 'John');Microsoft SQL Server
- 마이크로소프트의 상용 RDBMS
- IDENTITY로 자동 증가
- TOP 절로 결과 제한
- T-SQL 프로시저 언어
-- SQL Server 특화 문법
SELECT TOP 10 * FROM employees;
CREATE TABLE users (
id INT IDENTITY(1,1) PRIMARY KEY,
name VARCHAR(100)
);MariaDB
- MySQL의 포크 프로젝트
- MySQL과 높은 호환성
- 추가 스토리지 엔진 (ColumnStore)
- 향상된 성능과 기능
-- MariaDB는 MySQL과 거의 동일한 문법
SELECT * FROM employees LIMIT 10;