시계열 데이터 전처리와 통계적 진단
1. 시계열 데이터의 정의와 특성
1.1 시계열 데이터란 무엇인가
시계열 데이터(Time Series Data)는
시간의 흐름에 따라 순차적으로 관측된 데이터를 의미한다.
수학적으로는 시간 ( t )에 대해 정의된 확률 변수 ( X_t )의 집합으로 표현된다.
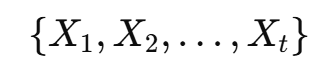
이 정의에서 중요한 점은 다음 두 가지다.
- 각 관측값은 확률 변수이다
- 관측값들은 서로 독립적이지 않다
1.2 일반 데이터와의 차이점
일반적인 머신러닝 데이터는 다음 가정을 암묵적으로 가진다.
- 각 샘플은 독립적이다 (i.i.d.)
- 행의 순서는 의미가 없다
시계열 데이터는 이 가정을 모두 위반한다.
- 시간 순서가 의미를 가진다
- 과거 값이 현재 값에 영향을 준다
- 데이터 분포가 시간에 따라 변할 수 있다
따라서 시계열 데이터는
별도의 전처리와 분석 체계가 필요하다.
2. 시계열 전처리의 목적
2.1 전처리의 재정의
시계열 전처리는 단순히 데이터를 깨끗하게 만드는 작업이 아니다.
시계열 전처리의 목적은 다음과 같다.
시간 구조를 유지한 채
데이터 생성 과정을 단순한 통계적 구조로 변환하여
모델이 학습 가능한 형태로 만드는 것
2.2 시계열 전처리의 핵심 원칙
- 시간 순서를 절대 훼손하지 않는다
- 결측과 이상을 삭제가 아닌 해석의 대상으로 본다
- 통계적 성질을 확인한 뒤 피처를 설계한다
3. 시간 인덱스와 샘플링 구조
3.1 시간 인덱스의 역할
시계열 데이터에서 시간 인덱스는
단순한 컬럼이 아니라 좌표계에 해당한다.
df = df.sort_index()이 작업은 모든 시계열 분석의 전제 조건이다.
3.2 불규칙 샘플링 문제
현실 데이터에서는 다음과 같은 상황이 빈번하다.
- 기록 누락
- 이벤트 기반 수집
- 센서 지연
이 경우 모델은 실제 현상이 아니라
샘플링 간격의 불규칙성을 학습하게 된다.
이를 해결하기 위해 시간 단위를 명시적으로 통일해야 한다.
4. Resampling (리샘플링)
4.1 Resampling의 정의
Resampling은
시간 단위를 기준으로 데이터를 재집계하는 과정이다.
df = df.resample("1H").mean()4.2 다운샘플링과 업샘플링
다운샘플링
- 짧은 간격 → 긴 간격
- 노이즈 감소
- 장기 추세 강조
업샘플링
- 긴 간격 → 짧은 간격
- 결측치 증가
- 보간 필수
Resampling은 항상
결측치 처리 전략과 함께 설계되어야 한다.
5. 시계열 결측치 처리
5.1 시계열에서 결측의 의미
시계열에서 결측은
“값이 0”이 아니라
해당 시점에 관측이 이루어지지 않았음을 의미한다.
따라서 단순 삭제는
시간 구조를 붕괴시킨다.
5.2 선형 보간 (Linear Interpolation)
df['value'] = df['value'].interpolate(method='linear')- 연속적인 변화 가정
- 짧은 결측 구간에 적합
- 물리량 데이터에 자주 사용
5.3 이전 값 채우기 (Forward Fill)
df['value'] = df['value'].ffill()- 상태 유지 가정
- 설정 값, 장비 모드에 적합
- 장기 결측 시 왜곡 가능
6. 이상치 처리
6.1 시계열 이상치의 특성
시계열 이상치는 다음 중 하나일 수 있다.
- 측정 오류
- 시스템 상태 변화
- 실제 이벤트 발생
따라서 이상치는
무조건 제거 대상이 아니다.
6.2 통계적 방법의 한계
IQR, z-score는
시간 순서를 고려하지 않는다.
실무에서는 이상치를 제거하기보다
이상치 여부를 피처로 활용하는 경우가 많다.
7. 정상성 (Stationarity)
7.1 정상성의 정의
정상성이란
시계열의 통계적 성질이 시간에 따라 변하지 않는 상태를 의미한다.
- 평균 일정
- 분산 일정
- 자기상관 구조 일정
7.2 정상성의 중요성
- 대부분의 시계열 모델은 정상성 가정
- 비정상 시계열은 예측 불안정
- 과거 데이터가 미래를 설명하지 못함
7.3 정상성 검정 (ADF Test)
from statsmodels.tsa.stattools import adfuller
adfuller(df['value'])[1]- p-value < 0.05 → 정상
- p-value ≥ 0.05 → 비정상
8. 차분 (Differencing)
8.1 차분의 의미
차분은
시계열을 값의 문제에서
변화량의 문제로 변환한다.
df['diff'] = df['value'].diff()8.2 차분의 효과
- 추세 제거
- 정상성 확보
- 자기상관 구조 단순화
9. 추세와 계절성 분해
9.1 시계열 구성 요소
시계열은 일반적으로 다음으로 구성된다.
- 추세 (Trend)
- 계절성 (Seasonality)
- 불규칙 성분 (Residual)
9.2 시계열 분해
from statsmodels.tsa.seasonal import seasonal_decompose
seasonal_decompose(df['value'], period=24)이를 통해
시계열 구조를 시각적으로 확인할 수 있다.
10. 자기상관 분석
10.1 자기상관의 개념
자기상관은 현재 값과 과거 값 사이의 상관 관계다.
10.2 ACF / PACF
- ACF: 전체 자기상관 구조
- PACF: 순수한 lag 영향
이는 Lag Feature 설계의 기준이 된다.
11. Lag 및 Rolling Feature
11.1 Lag Feature
df['lag_1'] = df['value'].shift(1)과거 정보를
명시적 입력 변수로 변환한다.
11.2 Rolling Feature
df['rolling_mean'] = df['value'].rolling(7).mean()최근 구간의 상태를 요약한다.
12. 정리
이 장에서 다룬 시계열 전처리는
다음 흐름으로 정리된다.
- 시간 인덱스 정렬
- Resampling
- 결측치 처리
- 이상치 해석
- 정상성 진단
- 차분 및 변환
- 자기상관 분석
- 피처 엔지니어링
