논문 제목 : Recurrent Auto-Encoder with Multi-Resolution Ensemble and Predictive Coding for Multivariate Time-Series Anomaly Detection
0. Abstract
실세계 애플리케이션에서는 대규모 다변량 시계열 데이터가 광범위하게 활용되고 있으며, 이에 따라 다변량 시계열 이상 탐지는 다양한 산업 분야에서 핵심적인 역할을 수행하고 있다. 시계열 기반 이상 탐지는 설비 오작동을 사전에 감지하고 유지보수 비용을 절감함으로써 전반적인 시스템 생산성을 향상시키는 데 기여한다.
그러나 실제 시계열 데이터는 복잡한 비선형 시간적 종속성을 포함하고 있어, 정상 패턴을 정확히 모델링하는 것이 어렵다. 이러한 문제를 해결하기 위해서는 정상 동작의 시간적 동역학을 효과적으로 표현할 수 있는 풍부한 잠재 표현 학습이 필수적이다.
본 연구는 다중 해상도 앙상블(Multi-Resolution Ensemble)과 예측 코딩(Predictive Coding)을 결합한 비지도 다변량 시계열 이상 탐지 모델 RAE-MEPC를 제안한다. 제안 모델은 입력 시계열로부터 다양한 시간 스케일의 종속성을 포착하기 위해 다중 해상도 앙상블 인코딩 구조를 도입한다. 인코더는 서로 다른 인코딩 길이를 갖는 여러 서브 인코더로부터 추출된 시간적 특징을 계층적으로 집계하여, 정상 동작에 대한 다중 스케일 표현을 형성한다.
디코더는 이에 대응하는 다중 해상도 앙상블 디코딩 방식을 사용하여 입력 시계열을 재구성하며, 저해상도 표현이 고해상도 서브 디코더의 복원을 보조하는 구조를 갖는다. 또한 예측 코딩 모듈을 추가하여, 모델이 단순 재구성뿐 아니라 미래 시점 예측을 동시에 학습하도록 설계함으로써 시계열의 장기적 시간 의존성을 보다 효과적으로 반영한다.
1. Introduction
스마트 팩토리, 발전소, 사이버 보안 시스템과 같은 복잡한 산업 환경에서는 대규모 다변량 시계열 데이터가 지속적으로 축적되고 있다. 이러한 시스템의 안정적인 운영을 위해서는 작동 상태를 지속적으로 모니터링하고 잠재적인 위협을 조기에 식별하는 것이 중요하다. 특히 이상 징후에 대한 적절한 대응이 이루어지지 않을 경우 실제 사고로 이어질 수 있으며, 이는 상당한 경제적 손실과 운영 중단을 초래할 수 있다.
일반적으로 이상(anomaly)은 정상 관측 패턴에서 크게 벗어나는 데이터 포인트로 정의된다. 시계열 이상 탐지의 목적은 주어진 길이의 시계열 데이터에서 각 시점별 이상 여부를 판단하는 데 있다. 따라서 데이터를 지속적으로 생성하는 산업 시스템에서는 시스템 생산성을 향상시키기 위해 정확하고 신뢰할 수 있는 시계열 이상 탐지 모델이 요구된다.
효과적인 시계열 이상 탐지 방법은 정상 시계열 데이터에 내재된 비선형 시간적 정보를 충분히 포착하는 동시에, 사전에 관측되지 않은 이상 패턴까지 탐지할 수 있어야 한다. 그러나 이 문제는 여러 측면에서 어려움을 가진다.
첫째, 실제 환경에서는 이상 데이터의 수집이 매우 제한적이다. 이로 인해 대부분의 시계열 이상 탐지는 정상 데이터만을 이용한 비지도 학습 방식으로 수행된다.
둘째, 다변량 시계열 데이터는 복잡한 시간적 종속성과 확률적 변동성을 동시에 포함하고 있다. 기존 연구들은 이러한 문제를 해결하기 위해 정상 시계열의 장기적 종속성을 효과적으로 표현하는 잠재 표현 학습에 초점을 맞추어 왔다.
딥러닝 기반 시계열 이상 탐지 방법은 크게 예측 기반 방법과 재구성 기반 방법으로 구분된다.
예측 기반 방법은 과거 시계열을 입력으로 미래 값을 예측함으로써 정상 패턴을 학습한다. 이 접근은 정상 데이터로만 학습된 예측 모델이 비정상 패턴을 정확히 예측하지 못할 것이라는 가정에 기반한다. 추론 단계에서는 실제 관측값과 예측값 간의 오차가 사전에 정의된 임계값을 초과할 경우 해당 시점을 이상으로 판단한다. 이러한 방식은 시계열의 시간적 흐름을 직접적으로 모델링할 수 있다는 장점이 있다.
반면, 재구성 기반 방법은 정상 시계열 데이터를 잠재 공간으로 압축한 뒤 이를 다시 복원하는 과정을 통해 정상 패턴을 학습한다. 이 접근은 정상 데이터로만 학습된 모델이 이상 데이터를 제대로 재구성하지 못하며, 그 결과 재구성 오류가 크게 증가한다는 가정을 사용한다. 대부분의 재구성 기반 방법은 오토인코더 구조를 활용하며, 입력과 재구성 출력 간의 차이를 이상 점수로 사용한다.
일부 연구에서는 생성 모델을 결합하여 정상 데이터 분포를 보다 정밀하게 학습하려는 시도도 이루어지고 있다. 이러한 방법들은 생성자와 판별자 간의 적대적 학습을 통해 정상 분포를 모델링하고, 재구성 확률이 낮은 샘플을 이상치로 판단한다. 그러나 이 계열의 방법들은 학습 불안정성과 모드 붕괴 문제로 인해 실제 적용에서 제약이 존재한다.
본 연구에서는 예측 기반 접근과 재구성 기반 접근의 장점을 결합하여 보다 유익한 시계열 표현을 학습하기 위해, 다중 해상도 앙상블과 예측 코딩을 결합한 순환 오토인코더 모델 RAE-MEPC를 제안한다.
제안 모델은 인코딩 및 디코딩 단계 모두에서 서로 다른 시간 해상도를 활용하여 시계열의 다중 스케일 종속성을 학습한다. 인코더는 서로 다른 인코딩 길이를 갖는 여러 서브 인코더로 구성되며, 각 서브 인코더는 서로 다른 시간 스케일의 특징을 추출한다. 짧은 인코딩 길이는 전역 패턴을 포착하는 데 유리하며, 긴 인코딩 길이는 보다 세밀한 국소 패턴을 포착한다. 이후 이 특징들은 계층적으로 통합되어 최종 잠재 표현을 형성한다.
디코딩 단계에서는 다중 해상도 앙상블 구조를 통해 입력 시계열을 재구성하며, 가장 높은 해상도의 출력이 최종 재구성 결과로 사용된다. 또한 재구성 디코더와 함께 예측 디코더를 추가하여, 과거 잠재 특징으로부터 미래 시계열을 예측하도록 학습한다. 이를 통해 모델은 단순 재구성뿐 아니라 시간적 예측 관점에서도 정상 패턴을 학습하게 된다.
모델이 정상 데이터로 학습된 이후에는 입력 시계열과 재구성 결과 간의 차이를 기반으로 이상 여부를 판단한다.
본 연구의 주요 기여는 다음과 같다.
- 다변량 시계열의 다중 스케일 종속성을 학습하기 위한 다중 해상도 앙상블 인코딩 구조를 제안한다.
- 재구성과 예측을 동시에 수행하는 예측 코딩 메커니즘을 도입하여 시간적 표현 품질을 향상시킨다.
- 단변량 및 다변량 시계열 데이터셋 전반에서 기존 벤치마크 모델 대비 우수한 이상 탐지 성능을 확인한다.
2. Method
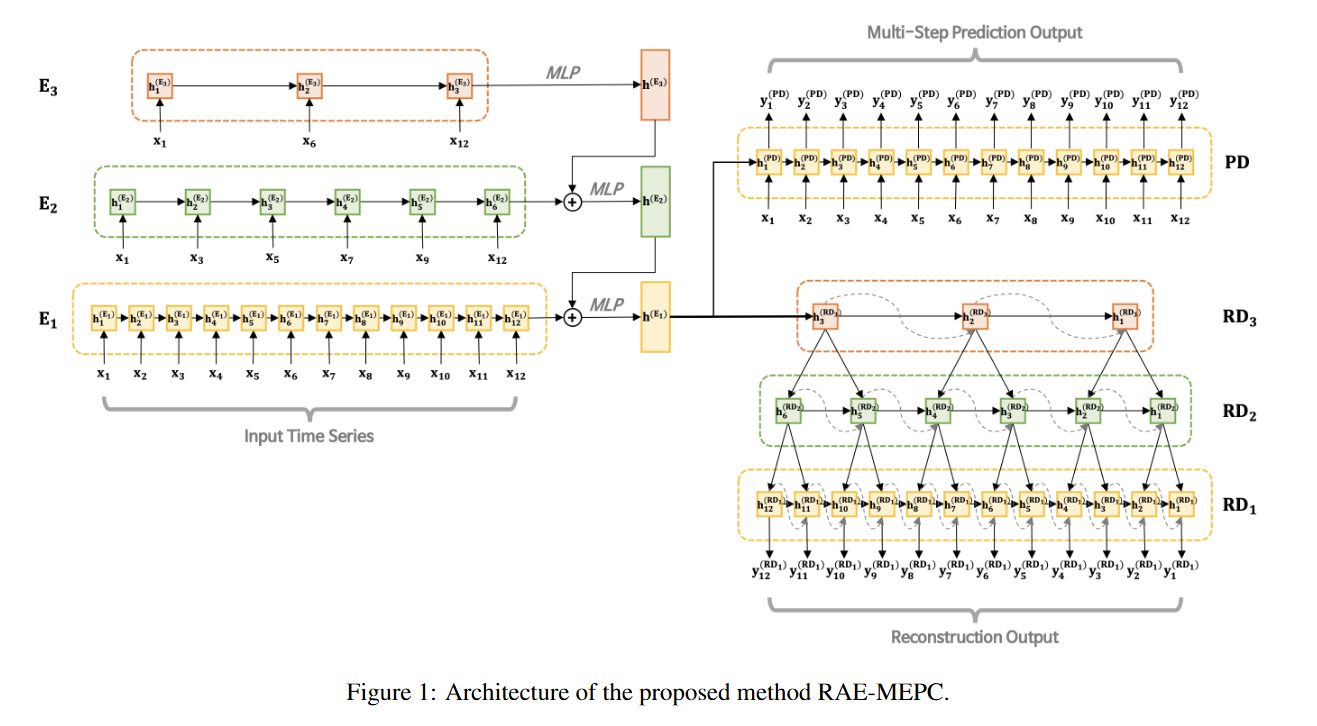
본 연구에서 제안된 방법은 인코딩된 특징들을 기반으로 입력 시계열을 재구성하고 미래 시계열을 예측하여 정상 패턴을 학습하는 것을 목표로 한다. 데이터는 다변량 시계열이며, 훈련 데이터의 대부분은 정상이라는 가정하에 기반하여 비지도 학습 방식으로 이상치를 탐지한다. 제안된 모델은 인코더와 두개의 디코더로 구성되며, 두 개의 디코더는 각각 입력 시계열을 재구성하고 미래 타임스텝을 예측하기 위해 사용된다.
2.1 Network 구조
2.1.1 Multi-Resolution Ensemble Encoding
제안된 모델의 인코더의 목표는 여러 스케일에서 입력 시계열로부터 시간적 특징을 추출하는 것이다. 인코더는 서로 다른 길이를 가진 개의 서브 인코더를 가진다. k번째 서브 인코더 는 길이 의 시계열에서 시간적 특징을 포착한다. 이 인코딩의 길이는 식 (1) 에 표시된 대로 정의된다.
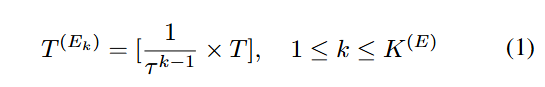
여기서 은 인코딩 길이를 결정하는 하이퍼파라미미터이며, 각 서브 인코더는 자신의 인코딩 길이와 일치하는 길이를 가진 시계열을 받는다. 원본 입력 시계열의 다중 스케일 종속성을 학습하기 위해 각 서브 인코더의 입력은 원본 입력과 유사한 형태를 가진다. 따라서 각 서브 인코더의 입력 시퀀스 는 식 (2)에 표시된 대로 원본 시간 창 X를 길이 의 부분 시퀀스로 다운 샘플링하여 얻는다.
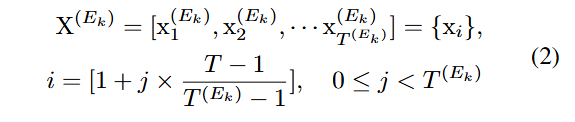
제안된 모델의 모든 서브 인코더는 LSTM이ek.
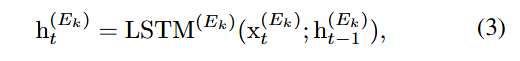
짧은 인코딩 길이를 가진 저해상도 서브인코더는 거시적인 시간적 특성을 추출하고, 더 긴 인코딩 길이를 가진 고해상도 서브 인코더는 지역적인 시간적 패턴에 집중할 수 있다. 마지막으로 통합된 인코딩 표현은 낮은 해상도 ~ 높은 해상도 까지의 마지막 은닉 상태를 계층적으로 집계하여 얻어진다.
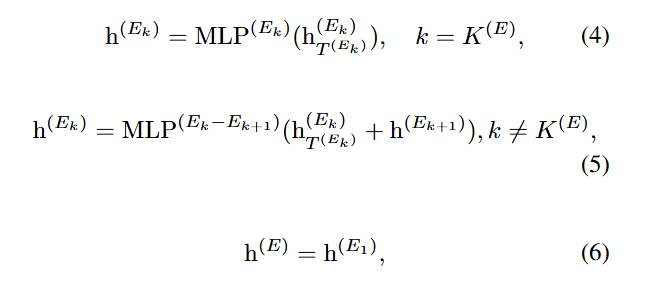
여기서 는 와 의 정보를 통합하는 fully connected Layer이다.
는 의 마지막 은닉 상태이고 는 부터 까지 통합된 특징이다.
는 모든 서브 인코더의 출력 앙상블로 부터 얻어진 최종 인코딩 representation이다. 이로써 RAE-MEPC의 인코더는 다중 해상도 앙상블 인코딩을 도입하여 general 하고 local 특징을 모두 가진 다중 스케일 종속성을 포착할 수 있다.
2.1.2 Multi-Resolution Ensemble Decoding
디코딩은 인코딩의 역순으로 입력 시계열을 구성한다. 서브 디코더의 해상도는 서브 인코더와 동일하며, 각 서브 디코더는 teacher forcing 없이 최종 인코딩된 표현을 기반으로 디코딩 길이의 입력 시계열을 재구성한다.
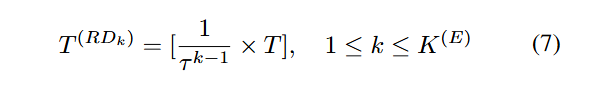
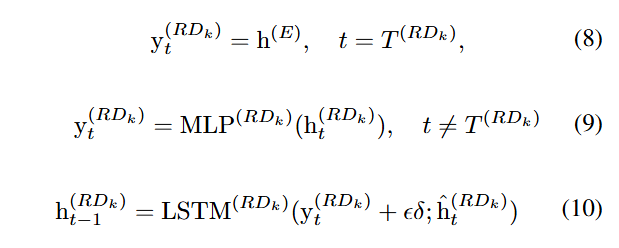
추가로 각 서브 디코더에는 LSTM 입력에 작은양의 노이즈가 추가되는데, 입력 패턴의 부분적 손상에 대한 강건성을 향상시키기 위함이다.
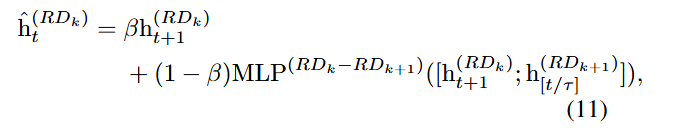
여기서 는 서브 디코더 의 이전 은닉 상태이며,
는 더 거친 해상도를 갖는 인접 서브 디코더 의 해당 은닉 상태이다.
는 더 거친 디코더의 정보를 반영하는 정도를 조절하는 하이퍼파라미터이다.
더 작은 값을 사용함으로써 각 디코딩 단계에서 저해상도 정보가 보다 적극적으로 활용되도록 설정하였다.
이 과정을 통해 재구성 디코더는 상위 해상도의 출력을 생성할 때, 더 거친 해상도의 정보를 직접 참조함으로써 다중 해상도 정보를 효과적으로 통합할 수 있다.
다중 해상도 앙상블 디코딩 이후, 역순으로 재구성된 입력 시계열은 최고 해상도 디코더로부터 획득된다.
마지막으로, 식 (12)에 나타낸 바와 같이 재구성 디코더의 출력을 다시 역순으로 변환하여 최종 재구성 출력 을 얻는다.
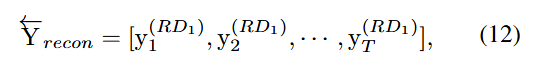
2.1.3 Predictive Coding
본 연구에선, 입력 시계열의 장기 의존성을 추출하기 위해 predictive coding 을 도입한다. 예측 디코더의 목표는 인코더로부터 압축된 표현을 기반으로 T/2시점 이후의 미래 시계열을 예측하는 것이다. 제안된 모델에서 예측 디코더는 다음과 같이 예측 작업을 수행한다.
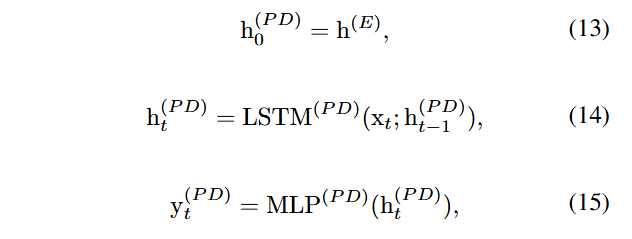
여기서 와 는 각각 예측 디코더의 번째 시점에서의 은닉 상태와 예측된 출력이다.
는 출력 생성을 위한 완전 연결 계층(fully connected layer)이며, 는 시간적 의존성을 모델링하기 위해 예측 디코더 내부에 사용된 LSTM 모델이다.
마지막으로, 예측 디코더는 식 (16)에 나타낸 바와 같이 시점 이후의 미래 시계열 를 예측한다.
예측 디코더는 예측 작업의 관점에서 시간적 의존성을 반영함으로써, 인코더가 정상 시계열로부터 보다 유익한 잠재 패턴을 학습하도록 유도한다.
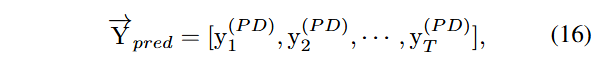
2.2 Objective Function
제안된 모델의 손실함수는 세가지 항으로 구성되는데,
- 재구성 오류
- 다중 Shape Constraint Loss
- 예측 오류
Reconstruction Loss
재구성 손실 은 입력 시계열과 최고 해상도 서브 디코더 의 재구성 출력 간 평균 제곱 오차로 정의된다.
이 손실은 재구성된 출력이 원본 입력 시계열과 최대한 유사하도록 유도한다.
Shape Constraint Loss
다중 해상도 형상 강제 손실 은 RAMED에서 제안된 방식으로, 서로 다른 해상도의 서브 디코더들이 입력 시계열과 일관된 시간적 추세를 학습하도록 유도하기 위해 도입되었다.
다중 해상도 앙상블 디코딩 구조에서는 각 서브 디코더가 서로 다른 시간 스케일의 출력을 생성하므로, 모든 해상도에서 입력과 유사한 패턴을 유지하는 것이 중요하다. 이미 이 최고 해상도 출력의 재구성을 보장하므로, 은 이를 제외한 나머지 서브 디코더들에 대해서만 정의된다.
이 손실은 서로 다른 길이의 시계열 간 거리를 계산할 수 있는 DTW 기반으로 정의되며, DTW의 비미분 가능 문제를 해결하기 위해 smoothed DTW (sDTW)를 사용한다.
sDTW는 다음과 같이 정의된다.
여기서 는 DTW 정렬 경로 행렬이며, 는 두 시계열 간 유클리드 거리로 구성된 정렬 비용 행렬이다. 는 스무딩 강도를 제어하는 하이퍼파라미터이다.
이를 기반으로 는 다음과 같이 정의된다.
이 손실은 서로 다른 해상도의 서브 디코더들이 입력과 유사한 시간적 구조를 유지하도록 강제한다.
Prediction Loss
예측 손실 는 예측 디코더의 출력과 실제 미래 시계열 간 평균 제곱 오차로 정의된다.
이 손실은 예측 디코더가 시점 이후의 미래 시계열을 정확히 예측하도록 유도하며, 동시에 인코더가 예측에 유용한 추가적인 시간 정보를 학습하도록 돕는다.
Total Loss
위 세 가지 손실 항을 결합하여 RAE-MEPC의 총 손실은 다음과 같이 정의된다.
여기서 와 는 각각 형상 손실과 예측 손실의 중요도를 조절하는 하이퍼파라미터이다.
3. 현업 아이디어 적용
방법1. 해상도 분할
- S를 기준으로 해상도를 분할하여, 각 서브 인코더가 입력받는 s를 해당 S의 중요 s만 한정하거나 Attention을 추가하여 학습하도록 함
- 만약, 도메인 지식으로 추가한다면, 입력에 중요도를 직접 곱하여 추가하며 손실함수에도 이를 반영 (중요도 높은 s에 더 큰 패널티 부여식으로..)
방법2. S(t-1) -> S(t) 를 예측하는 모델
- 두 단계의 물리적 인과관계를 학습하여 S간의 관계를 학습하게 함
+) 추가 방법 손실 함수에 R set값 추가
- 단, rd 만 하는 값도 존재하기 때문에 이 부분은 고려 필요
