
트리 구조는 편리한 구조를 전시하는 것 외에 효율적인 탐색을 위해 사용하기도 한다.
수많은 선배 개발자들은 효율적인 탐색을 위해 고민하고 발전시켜 새로운 트리의 모습을 만드는 등 치열한 노력을 쏟았다. 그렇기 때문에 트리 구조는 가지고 있는 특징에 따라 여러 가지 이름으로 불린다. 많은 트리의 모습 중, 가장 간단하고 많이 사용하는 이진 트리(binary tree)와 이진 탐색 트리(binary search tree)에 대해 알아보자.
❤️🔥 이진 트리(Binary tree)
- 이진 트리(Binary tree)는 자식 노드가 최대 두 개인 노드들로 구성된 트리
- 두 개의 자식 노드는 왼쪽 자식 노드와 오른쪽 자식 노드로 나눌 수 있다.
- 이진 트리는 자료의 삽입, 삭제 방법에 따라 정 이진 트리(Full binary tree), 완전 이진 트리(Complete binary tree), 포화 이진 트리(Perfect binary tree)로 나뉜다.
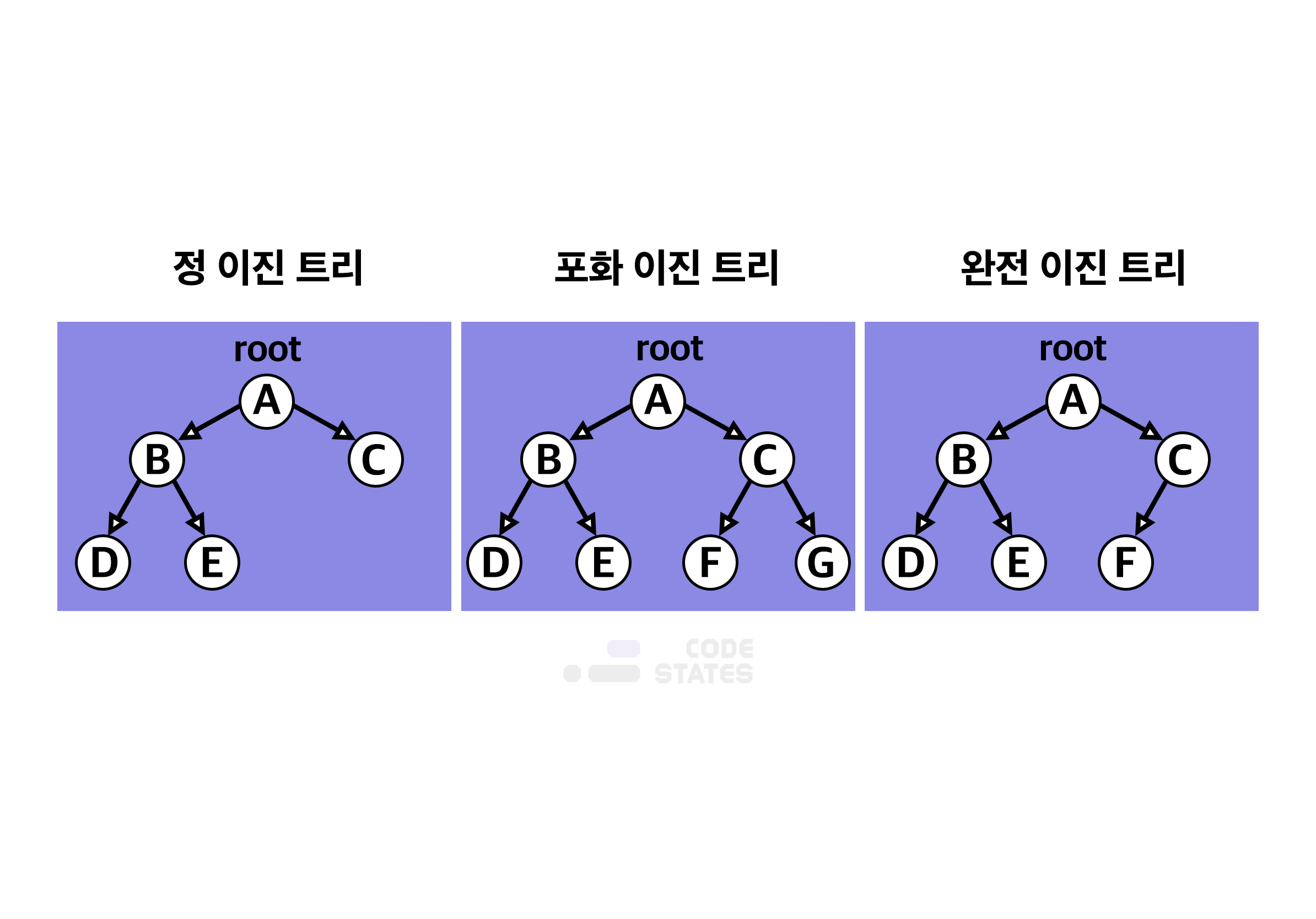
이진 트리 특징
- 정 이진 트리(Full binary tree) : 각 노드가 0개 혹은 2개의 자식 노드를 갖는다.
- 포화 이진 트리(Perfect binary tree) : 정 이진 트리이면서 완전 이진 트리인 경우. 모든 리프 노드의 레벨이 동일하고, 모든 레벨이 가득 채워져 있는 트리
- 완전 이진 트리(Complete binary tree) : 마지막 레벨을 제외한 모든 노드가 가득 차 있어야 하고, 마지막 레벨의 노드는 전부 차 있지 않아도 되지만 왼쪽이 채워져야 한다.
이러한 이진 트리는 이진 탐색 트리와 이진 힙 구현에 사용되며, 효율적인 검색과 정렬을 위해 사용된다.
❤️🔥 이진 탐색 트리(Binary Search Tree)
- 이진 탐색 트리란 이진 탐색(binary search)과 연결 리스트(linked list)를 결합한 이진트리
- 이진 탐색의 효율적인 탐색 능력을 유지하면서도, 빈번한 자료 입력과 삭제를 가능하게끔 고안
이진탐색트리 특징을 가지고 있다.
각 노드에 중복되지 않는 키(Key)가 있다.
루트노드의 왼쪽 서브 트리는 해당 노드의 키보다 작은 키를 갖는 노드들로 이루어져 있다.
루트노드의 오른쪽 서브 트리는 해당 노드의 키보다 큰 키를 갖는 노드들로 이루어져 있다.
좌우 서브트리도 모두 이진 탐색 트리여야 한다.
즉 이진 탐색 트리(Binary Search Tree)는 모든 왼쪽 자식의 값이 루트나 부모보다 작고, 모든 오른쪽 자식의 값이 루트나 부모보다 큰 값을 가지는 특징이 있다. 예를 들어서 다음과 같은 트리가 이진 탐색 트리이다.
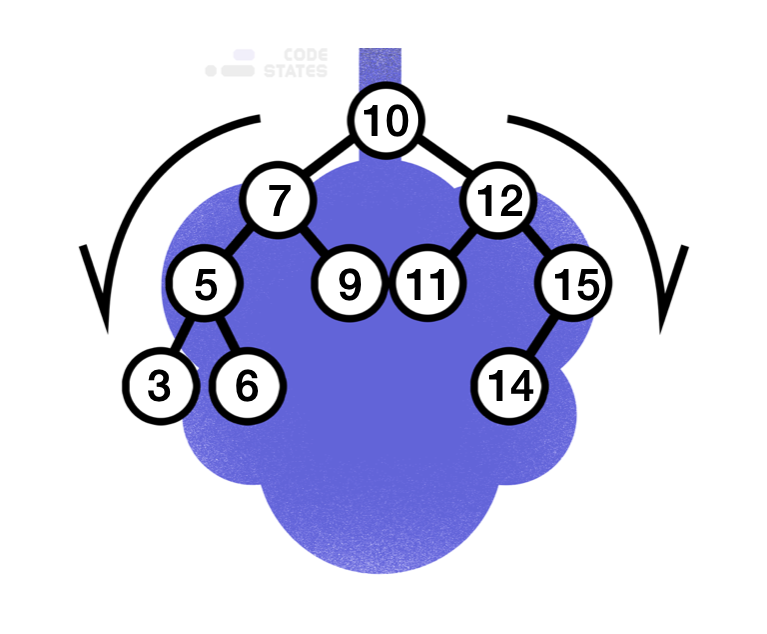
이진 탐색 트리
이진 탐색 트리는 균형 잡힌 트리가 아닐 때, 입력되는 값의 순서에 따라 한쪽으로 노드들이 몰리게 될 수 있다. 균형이 잡히지 않은 트리는 탐색하는 데 시간이 더 걸리는 경우도 있기 때문에 해결해야 할 문제이다. 이 문제를 해결하기 위해 삽입과 삭제마다 트리의 구조를 재조정하는 과정을 거치는 알고리즘을 추가할 수 있다.
이진 탐색 트리 특징
이진 탐색 트리는 기존 이진 트리보다 탐색이 빠르다는 장점이 있다. 이진 탐색 트리의 연산은 트리의 높이가 h(height)라면 o(h)의 복잡도를 가지게 된다. 이와 같은 효율적인 연산이 가능한 이유는 탐색 과정에 있다.
이진 탐색 트리의 탐색은 다음과 같은 과정을 거친다.
루트 노드의 키와 찾고자 하는 값을 비교한다. 만약 찾고자 하는 값이라면 탐색을 종료한다.
찾고자 하는 값이 루트 노드의 키보다 작다면 왼쪽 서브 트리로 탐색을 진행한다.
찾고자 하는 값이 루트 노드의 키보다 크다면 오른쪽 서브 트리로 탐색을 진행한다.
이 과정을 찾고자 하는 값을 찾을 때까지 반복해 진행한다. 만약 값을 찾지 못한다면 그대로 연산을 종료하게 된다. 이러한 탐색 과정을 거치면 최대 트리의 높이(h)만큼 탐색을 진행한다.
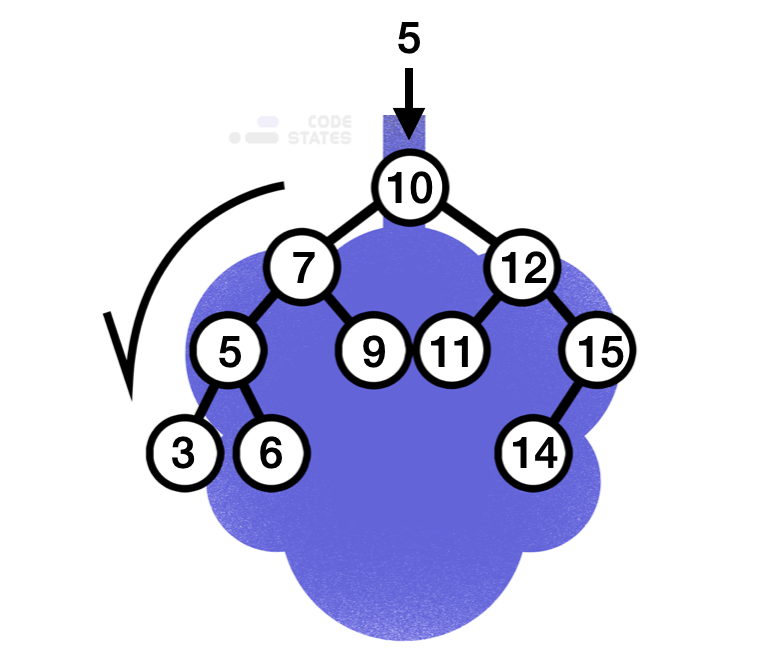
이진 탐색 트리에서 5라는 값을 찾을 때
만약 이와 같은 트리에서 5라는 값을 찾고자 하면 제일 처음에는 루트 노드와 값을 비교하게 된다. 루트 노드가 여기서는 10이므로 루트 노드보다 작기 때문에, 왼쪽 서브 트리로 탐색을 시작한다. 이후 마주친 노드는 7이고, 찾고자 하는 값은 5이므로 다시 7을 기준으로 왼쪽 서브 트리로 탐색을 진행한다. 이어 만난 값이 찾고자 하는 값이므로 탐색이 종료된다. 10부터 5까지 3번의 탐색이 이뤄졌지만, 만약 3을 찾는다면 4번의 연산이 진행되었을 것이다. 즉 트리 안의 값을 찾는다면 무조건 트리의 높이(h) 이하의 탐색이 이뤄지게 된다.
여기서 하나 알아둬야 할 점은, 트리 안에 찾고자 하는 값이 없더라도 최대 h번의 연산 및 탐색이 진행된다는 것이다. 만일 13이라는 숫자를 찾는다고 가정해보자. 마지막으로 도착하는 노드의 값은 14인데, 여기서 13은 14보다 작으므로 왼쪽 서브 트리로 탐색을 진행해야 한다. 그런데 오른쪽 서브 트리가 없으므로 14에서 탐색이 종료 되게 된다. 그렇기 때문에 트리 안에 찾고자 하는 값이 없더라도 최대 h번의 연산 및 탐색이 진행되게 되는 것이다.
