
이번 포스팅에서는 신경망 의존성 구문 분석을 다뤄보겠습니다.
최근에는 전통적인 의존성 구문 분석 모델보다 신경망을 이용한 모델이 더 각광 받고 있습니다.
신경망 모델이 전통적인 모델과 비슷한 성능을 보이면서도 효율이 훨씬 높기 때문입니다.
그럼 왜 신경망 모델의 효율이 더 높은 지 살펴보겠습니다.
1. Traditional Models
이전 포스팅에서 전이 기반 의존성 구문 분석 모델은 단어 그 자체, 의존 관계에 관한 레이블,
품사 태그 등 범주형 특성(categorical features)을 추출하여 사용했습니다.
범주형 특성을 사용하는 경우에 대표적인 세가지 문제가 있습니다.
Sparse
전이 기반 모델이 사용하는 범주형 특성은 앞서 언급한 요소 외에도 많고 다양합니다.
그리고 수많은 개별 특성을 조합해야 하는데 이때 조합 가능한 특성의 수는 기하급수적으로 증가합니다.
전통적인 모델은 주로 퍼셉트론, SVM, 로지스틱 회귀 등 선형 분류기를 이용하는데
데이터는 범주형이므로 원-핫 인코딩이나 indicator feature로 변환됩니다.
따라서 특성 행렬의 대부분이 0으로 이루어져 희소(sparse)합니다.
Incomplete
Incomplete이란 이론적으로 가능한 모든 의존성 트리를 만들 수 없는 경우가 발생한다는 것을 의미합니다.
이는 비투영적 의존(non-projective dependency) 처리에 어려움이 있습니다.
비투영은 의존 관계를 표현하는 화살표가 서로 교차하는 경우, 즉 어순이 고정되지 않고 자유로운 경우를 의미합니다.
반대로 투영적인 의존 관계는 이 화살표가 서로 교차하지 않는 경우, 즉 어순이 비교적 고정된 경우를 의미합니다.
기본적인 전이 기반 모델은 투영적(projective) 의존 관계에 최적화되어 있습니다.
SWAP같은 추가 전이를 통해 비투영 의존 관계를 처리할 수 있다고는 하지만
전통적인 모델에 대해서는 비효율적이라는 문제가 있습니다.
다시 말해 전통적인 모델로는 비투영적 의존같은 복잡한 관계를 처리하기 어려우므로
어순이 자유로운 언어를 처리할 때는 성능에 큰 영향을 미칠 수 있습니다.
Expensive to Compute
전통적인 전이 기반 모델은 다양한 범주형 특성을 이용하고 각 특성에도 적게는 두개, 많으면 수만가지의 범주가 존재합니다.
매 스텝마다 특성 추출을 위해 매우 큰 차원의 희소 벡터를 생성하고 이를 분류하는 연산을 반복해야 하므로 비용이 큽니다.
또한 실제 시스템에서는 단순하고 빠른 탐욕적인 탐색 방식보다 정확도가 높은 빔(beam search)을 이용하는데
계산량은 빔 크기에 비례하여 증가하므로 문장이 길어질수록 계산 비용 또한 커집니다.
하지만 신경망 모델을 이용하면 전통적인 모델의 한계점을 극복할 수 있습니다.
2. Neural Dependency Parsing
이 섹션에서는 신경망 의존성 구문 분석 모델은 의존 관계를 어떻게 파악하는지 알아보겠습니다.
신경망 의존성 구문 분석 모델은 전통적인 모델과 달리 밀집(dense)된 차원 기반의 특성 표현을 사용합니다.
전통적인 전이 기반 모델의 희소 문제를 해결하여 연산 비용을 효율적으로 사용할 수 있습니다.
설명의 용이성을 위해 탐욕적 탐색(greedy search) 및 arc-standard 전이 시스템을 사용한 신경망 모델을 예로 들겠습니다.
다시 말해 기본적인 전이를 기반으로 하면서 전이의 종류를 선택할 때는 단순히 가장 확률 값이 높은 것을 선택하겠다는 것입니다.
모델의 최종 목표는 초기 구성 상태 에서 시작하여 종결 상태(terminal configuration)에 이르기까지의 전이 시퀀스를 예측하는 것입니다.
이 종결 상태에는 의존성 트리가 내재되어 있습니다.
예측은 현재 상태에서 추출된 특성(features)을 기반으로 이루어 집니다.
그러면 일단 입력 문장에서 특성을 추출해야 하는데 이때 명시적 규칙을 사용합니다.
어떤 위치의 단어를 특성으로 사용할 지 사전에 정해놓는 것입니다.
문장에 대해 일반적으로 선택하는 특성은 다음과 같습니다.
-
: (스택)와 (버퍼)의 상단 단어들과 그 자식들의 벡터 표현
-
: 그 단어들의 품사(POS) 태그
예를 들어 -
: 그 단어들의 의존 관계명 (arc label)
예를 들어
특성 선택(feature selection)의 예시를 들어보겠습니다.
다음과 같은 특성 선택을 가정해봅시다.
-
스택과 버퍼의 상단 3개의 단어
-
스택 상위 2개 단어의 좌우측에 자식 노드 2개
-
좌측 첫번째 자식의 좌측 자식, 우측 첫번째 자식의 우측 자식
이를 트리로 표현하면 아래와 같습니다.
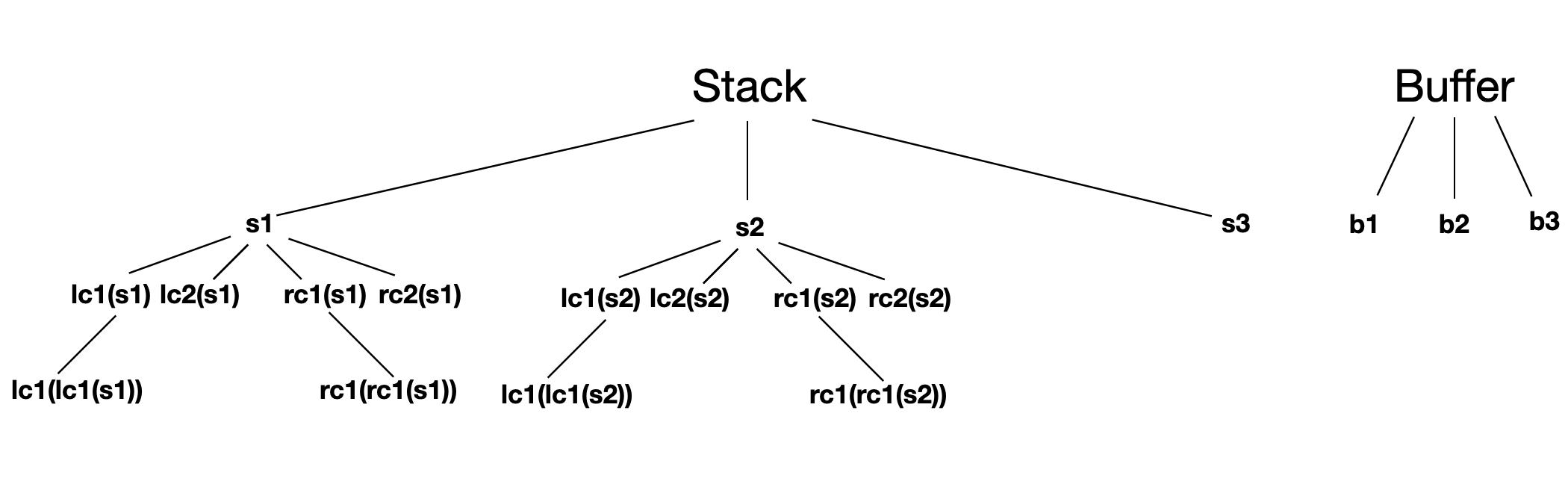
스택과 버퍼의 단어 6개, 스택 상위 2개 단어의 자식 노드 8개, 자식 노드의 자식 노드 4개를 더하면 18입니다.
따라서 로부터 18개의 특성을 추출합니다.
의 경우 의 18개 요소로부터 18개의 품사 태그 특성을 추출합니다.
은 18개의 요소로부터 스택과 버퍼의 단어 6개를 제외하여 12개의 의존 관계 레이블 특성을 추출합니다.
특징을 추출한 뒤엔 각 특성 유형에 대해 임베딩 행렬을 정의하여 원-핫 벡터를 차원의 밀집 벡터로 변환합니다.
앞서 추출한 특성 행렬 을 concat하고 이것을 입력층으로 설정합니다.
로 표현할 수 있습니다.
이를 은닉층에 입력합니다.
은닉층에서는 비선형 변환을 적용합니다.
예를 들어 활성화 함수가 ReLU라면 아래와 같이 표현할 수 있습니다.
이를 출력층으로 전달합니다.
를 통해 와 , 3개의 전이에 대한 확률 분포를 구할 수 있습니다.
탐욕적 탐색이므로 가장 확률 값이 큰 전이를 선택하고 출력합니다.
이 출력의 의미는 현재의 특성을 기반으로 스택의 단어들이 어떤 의존 관계를 가지는 지를 예측한 결과입니다.
이 결과에 따라 (스택)과 (버퍼), (의존 관계), 즉 특성을 최신화합니다.
이를 그림으로 표현하면 아래와 같습니다.
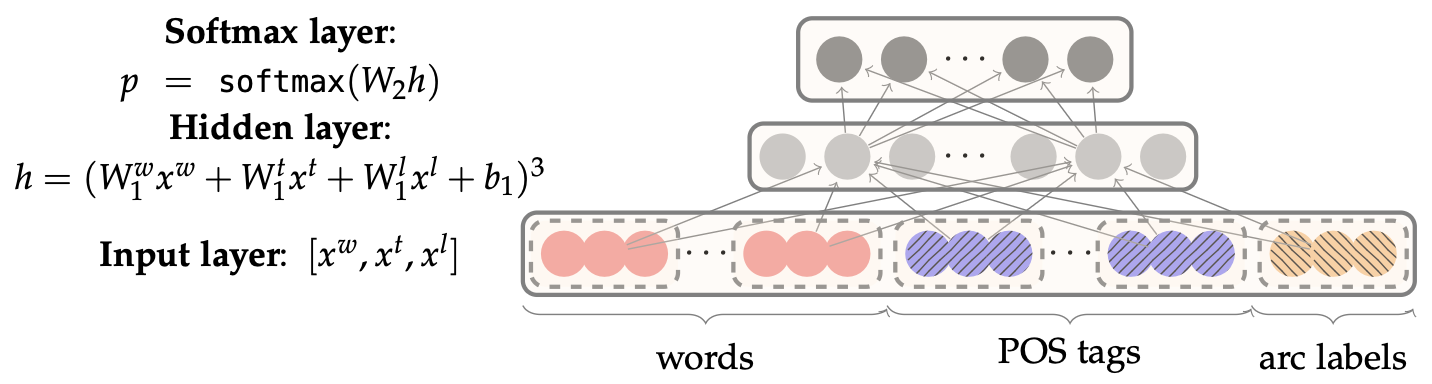
신경망 의존성 구문 분석 모델이 어떻게 동작하는지 살펴보았습니다.
이 과정을 구체적인 예를 들어서 좀 더 살펴보겠습니다.
입력 문장 가 "I read a book"일 때를 생각해봅시다.
그리고 스택에 ""와 ""가 저장된 상태에서 시작해봅시다.
스택의 맨 위의 단어 과 그 다음 단어 에 대해 이 단어들과 품사 태그, 의존 관계 정보를 가져와 특성으로 활용하도록 명령합니다.
상태는 다음과 같습니다.
스택의 맨 위 단어 은 , 그 다음 단어 는 입니다.
의 품사는 VV, 는 PP입니다.
의존 관계는 정보는 가 비어있으므로 NULL입니다.
이 모든 특성을 하나의 긴 입력 벡터로 결합하여 입력층을 구성합니다.
이를 은닉층에 입력하여 은닉 상태를 얻습니다.
출력층에서 예측을 수행합니다.
이 예측으로 전이에 대한 확률 분포를 얻을 수 있습니다.
예시 확률 분포는 다음과 같습니다.
이 결과는 가 에 의존할 확률이 임을 의미합니다.
또한 두 단어는 주어-동사의 관계(nsubj)가 강할 것이라는 의존 관계도 예측할 수 있습니다.
따라서 라는 의존 관계를 도출합니다.
그리고 이 의존 관계를 에 추가하고 를 스택에서 제거합니다.
따라서 적용 후의 결과는 아래와 같습니다.
스택과 가 최신화되었으므로 특성을 다시 추출합니다.
스택의 맨 위 단어는 , 그 다음 단어는 입니다.
의 품사는 VV, 는 NULL_POS입니다.
이제 의존 관계 정보를 활용할 수 있습니다.
는 자식인 와 관계를 갖는다는 정보도 특성으로 활용합니다.
다시 이 모든 특성을 벡터로 결합하여 로 입력층을 구성합니다.
은닉층과 출력층 거쳐 새로운 전이 상태를 예측하고 스택과 버퍼를 최신화합니다.
다시 최신화된 , , 로부터 특성을 추출합니다.
이를 끝까지 반복하면 다음과 같은 종결 상태를 얻을 수 있습니다.
3. 정리
이번 포스팅에서는 신경망 의존성 구문 분석 방식은 어떻게 의존 관계를 파악하는지 알아봤습니다.
이 방식은 밀집 벡터를 이용하여 전통적인 모델의 희소 문제를 해결할 수 있으며
비투영 의존 처리를 위한 SWAP 전이 과정 또한 전통 모델보다 더 효율적입니다.
이를 통해 의존성 구문 분석에 필요한 계산 비용을 이전보다 더 효율화할 수 있다는 점에서 의의가 있습니다.
더 발전된 형태로는 그래프 기반 의존성 구문 분석도 존재합니다.
여유가 되면 그래프 기반 의존성 구문 분석도 다뤄보도록 하겠습니다.
