
이번 포스팅에서는 파이토치로 간단한 신경망을 구축해보며 기본적인 파이토치의 신경망을 이해해보도록 하겠습니다.
1. Linear Layer
먼저 파이토치 모듈을 불러와야 합니다.
파이토치의 torch.nn 모듈에 정의된 블록 또한 사용할 것이므로 이 모듈 또한 불러옵니다.
import torch
import torch.nn as nnnn.Linear(H_in, H_out)을 사용하여 선형 레이어를 생성할 수 있습니다.
이 함수는 (N, *, H_in) 차원의 행렬을 입력 받아 (N, *, H_out) 차원의 행렬을 출력합니다.
여기서 *는 N과 H사이에 임의의 차원이 있을 수 있음을 의미합니다.
선형 계층은 Ax + b 연산을 수행하는데 여기서 A와 b는 무작위로 초기화됩니다.
예를 들어 봅시다.
3차원 행렬 (2, 3, 4)를 선형 레이어에 입력하여 (2, 3, 2) 행렬을 출력하는 것을 생각해봅시다.
그럼 (N, *, H_in)는 (2, 3, 4)이고 (N, *, H_out)는 (2, 3, 2)입니다.
아래와 같은 변환을 상상할 수 있습니다.
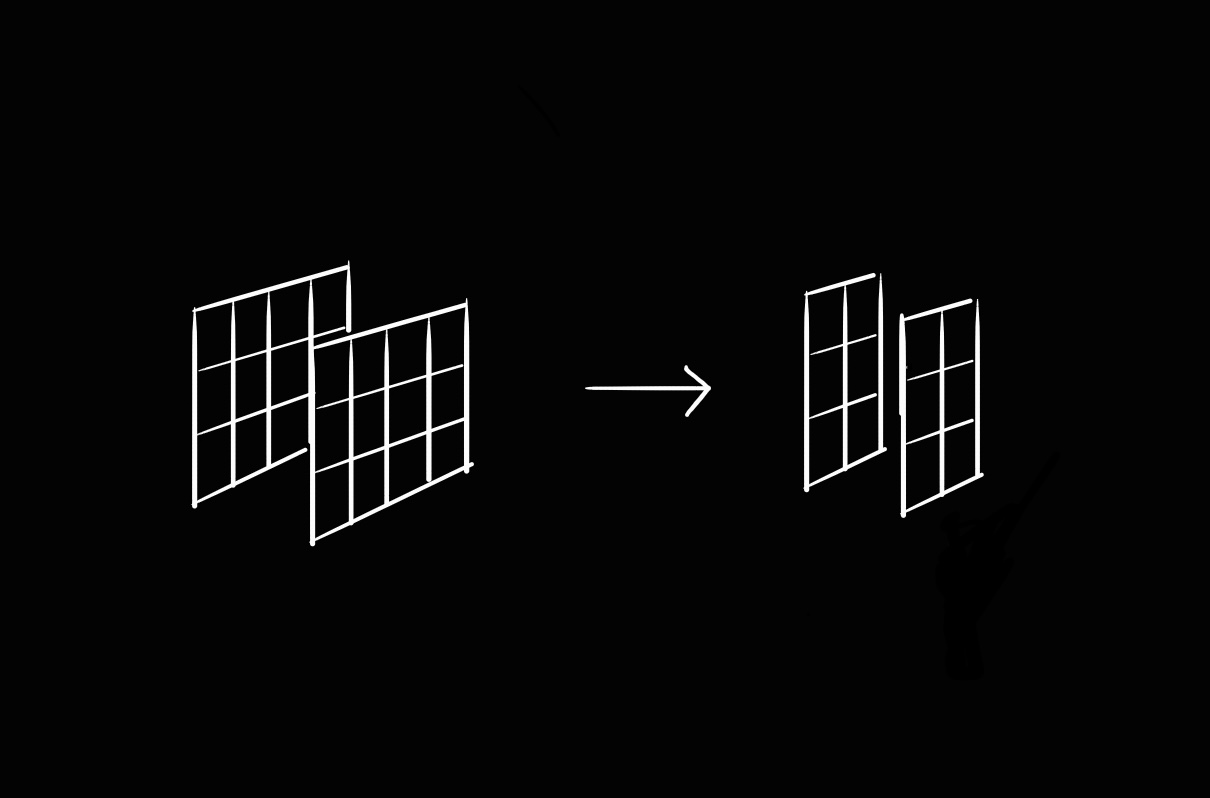
코드를 작성하기 전에 먼저 생각해봅시다.
-
입력(
input)은(2, 3, 4)차원의 행렬을 만들고 원소는 모두1로 초기화합니다. -
이 입력을 선형 레이어에 넣어야 하므로 선형 레이어를 하나 선언합니다.
-
선형 레이어는
(2, 3, 4)차원의 행렬을 입력받고(2, 3, 2)차원의 행렬을 출력합니다. -
그럼
H_in은4,H_out은2이므로nn.Linear()함수에 이 값들을 넣습니다. -
선형 레이어에
input을 넣으면(2, 3, 2)차원의 출력을 확인할 수 있습니다.
input = torch.ones(2, 3, 4) # N=2, *=3, H_in=4
linear = nn.Linear(4, 2) # (N, *, 4)을 (N, *, 2)로 선형 변환하는 레이어
linear_output = linear(input) # 변환
linear_output # 변환 결과 출력# 출력
tensor([[[-0.5229, -0.7038],
[-0.5229, -0.7038],
[-0.5229, -0.7038]],
[[-0.5229, -0.7038],
[-0.5229, -0.7038],
[-0.5229, -0.7038]]], grad_fn=<ViewBackward0>)출력의 차원을 shape함수로 확인할 수 있습니다.
linear_output.shape# 출력
torch.Size([2, 3, 2])선형 레이어의 파라미터도 parameters() 함수로 확인할 수 있습니다.
list(linear.parameters()) # Ax + b# 출력
[Parameter containing:
tensor([[-0.4312, 0.1859, -0.1404, -0.3182],
[-0.2722, -0.3900, -0.0022, 0.0443]], requires_grad=True),
Parameter containing:
tensor([ 0.1810, -0.0837], requires_grad=True)]이 결과는 선형 레이어 nn.Linear(4, 2)의 학습 가능한 가중치와 편향을 의미합니다.
(2, 4) 차원의 가중치 행렬()과 2차원 편향 벡터()를 확인할 수 있습니다.
가중치 행렬의 2는 출력 벡터의 차원이고 4는 입력 벡터의 차원입니다.
이 행렬과 벡터는 선형 변환 에 사용됩니다.
다만 가중치의 경우 가 (2, 3, 4)이므로 행렬곱을 위해 (2, 4)()의 차원을 (4, 2)() 차원의 전치 행렬로 변환해야 합니다.
2. Activation Function Layer
은닉층에서 노드가 비선형성을 추가하기 위해 활성화 함수를 활용한 뒤 출력하는 모습을 상상할 수 있습니다.
파이토치에서는 nn 모듈을 사용하여 텐서에 활성화 함수를 적용할 수 있습니다.
활성화 함수의 예로는 nn.ReLU(), nn.Sigmoid(), nn.LeakyReLU()가 있습니다.
활성화 함수는 각 요소에 대해 개별적으로 동작하므로 출력으로 얻는 텐서의 형태는 전달되는 텐서의 형태와 동일합니다.
다시 말해 활성화 함수를 거쳐도 선형 레이어의 출력 차원은 변하지 않습니다.
선형 레이어의 출력을 다시 살펴봅시다.
# 출력
tensor([[[-0.5229, -0.7038],
[-0.5229, -0.7038],
[-0.5229, -0.7038]],
[[-0.5229, -0.7038],
[-0.5229, -0.7038],
[-0.5229, -0.7038]]], grad_fn=<ViewBackward0>)현재의 출력은 입력과 가중치 행렬이 곱해진 상태입니다.
입력을 ones() 함수를 사용해 1로 초기화하였으므로 열마다 같은 값을 가지고 있습니다.
이제 nn.Sigmoid()로 비선형성을 추가해보겠습니다.
sigmoid = nn.Sigmoid()
output = sigmoid(linear_output)
output# 출력
tensor([[[0.3722, 0.3310],
[0.3722, 0.3310],
[0.3722, 0.3310]],
[[0.3722, 0.3310],
[0.3722, 0.3310],
[0.3722, 0.3310]]], grad_fn=<SigmoidBackward0>)음수였던 값들이 시그모이드 함수 통과 후 0에서 1사이의 값을 가지는 것을 확인할 수 있습니다.
3. Putting the Layers Together
지금까지 선형 레이어를 생성한 뒤 한 레이어의 출력을 다음 레이어의 입력으로 전달하는 방법을 살펴보았습니다.
텐서를 중간에 생성하여 전달하는 대신 nn.Sequential을 사용하면 더 간단합니다.
block = nn.Sequential(
nn.Linear(4, 2)
nn.Sigmoid()
)
input = torch.ones(2, 3, 4)
output = block(input)
output# 출력
tensor([[[0.5809, 0.4213],
[0.5809, 0.4213],
[0.5809, 0.4213]],
[[0.5809, 0.4213],
[0.5809, 0.4213],
[0.5809, 0.4213]]], grad_fn=<SigmoidBackward0>)nn.Sequential에 모두 정의하여 한 번에 전달이 가능함을 확인할 수 있습니다.
이 때 출력이 이전의 출력과 다른 이유는 또 다른 선형 레이어를 사용했으므로 가중치 행렬과 편향이 이전과 다르기 때문입니다.
4. Custom Modules
사전에 정의된 모듈을 사용하는 대신 nn.Module 클래스를 확장하여 직접 모듈을 만들 수도 있습니다.
커스텀 모듈은 더 복잡한 새로운 모듈을 만들 수 있다는 장점이 있습니다.
우리가 만들 커스텀 모듈은 아래와 같은 순서를 거칠 것입니다.
-
__init__함수에서input_size,hidden_size를 초기화 -
super 클래스의
__init__함수를 호출 -
초기화된 파라미터
input_size,hidden_size저장 -
모델 정의
-
forward()함수 정의
여기서 순전파 forward(x)는 model(x)와 같이 모듈에 파라미터가 전달될 때 호출되는 함수입니다.
nn.Module을 확장하는 모든 클래스는 forward(x) 함수도 구현해야 합니다.
여기서 x는 텐서입니다.
class MultilayerPerceptron(nn.Module):
def __init__(self, input_size, hidden_size):
# super의 __init__ 함수 호출
super(MultilayerPerceptron, self).__init__()
# Bookkeeping: 초기화 파라미터 저장
self.input_size = input_size
self.hidden_size = hidden_size
# 모델 정의
# 'self.model'이란 이름을 지은 건 별 뜻 없음. 다른 이름 써도 상관 없음
self.model = nn.Sequential(
nn.Linear(self.input_size, self.hidden_size),
nn.ReLU(),
nn.Linear(self.hidden_size, self.input_size),
nn.Sigmoid()
)
def forward(self, x):
output = self.model(x)
return output위와 똑같은 클래스를 아래의 코드처럼 다르게 정의할 수도 있습니다.
class MultilayerPerceptron(nn.Module):
def __init__(self, input_size, hidden_size):
super(MultilayerPerceptron, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 레이어 정의
self.linear = nn.Linear(self.input_size, self.hidden_size)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(self.hidden_size, self.input_size)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
linear = self.linear(x)
relu = self.relu(linear)
linear2 = self.linear2(relu)
output = self.sigmoid(linear2)
return output__init__메소드에 있는 개별 레이어를 정의하고 forward 메소드를 연결함으로써 nn.Sequential을 대체할 수 있음을 확인할 수 있습니다.
지금까지 클래스를 정의했습니다.
모델을 사용해봅시다.
# 샘플 입력 만들기
input = torch.randn(2, 5)
# 모델 만들기
model = MultilayerPerceptron(5, 3)
# 입력을 모델에 통과
model(input)# 출력
tensor([[0.6325, 0.5274, 0.3853, 0.5797, 0.4015],
[0.6344, 0.5300, 0.3845, 0.5832, 0.4039]], grad_fn=<SigmoidBackward0>)(2, 5) 차원의 행렬을 확인할 수 있습니다.
우리가 만든 신경망의 구조를 살펴봅시다.
self.model = nn.Sequential(
nn.Linear(self.input_size, self.hidden_size),
nn.ReLU(),
nn.Linear(self.hidden_size, self.input_size),
nn.Sigmoid()
)모델의 입력 차원 (5, 3)을 바탕으로 self.input_size에 5, self.hidden_size에 3을 대입해봅시다.
차례대로 생각해보면
-
(2, 5)차원의 입력 -
(2, 5)nn.Linear(5, 3)
-
(2, 3)nn.ReLU() -
(2, 3)nn.Linear(3, 5) -
(2, 5)nn.Sigmoid()
이므로 모델의 출력이 (2, 5)입니다.
named_parameters() 메소드와 parameters() 메소드로 모델의 파라미터를 검사할 수 있습니다.
list(model.named_parameters())[('linear.weight',
Parameter containing:
tensor([[ 0.1910, 0.0578, 0.3680, -0.0673, 0.3693],
[-0.0877, -0.0340, -0.3014, -0.3815, -0.1816],
[ 0.2189, -0.2455, 0.1729, 0.0090, 0.2746]], requires_grad=True)),
('linear.bias',
Parameter containing:
tensor([ 0.4137, -0.2857, -0.3862], requires_grad=True)),
('linear2.weight',
Parameter containing:
tensor([[-0.1609, -0.1934, 0.5306],
[-0.1987, 0.3010, 0.3944],
[ 0.0606, 0.4749, 0.4188],
[-0.2780, 0.4229, 0.4234],
[-0.1931, -0.1196, -0.0897]], requires_grad=True)),
('linear2.bias',
Parameter containing:
tensor([ 0.5512, 0.1201, -0.4703, 0.3360, -0.3890], requires_grad=True))]이 모델을 그림으로 표현하면 아래와 같습니다.
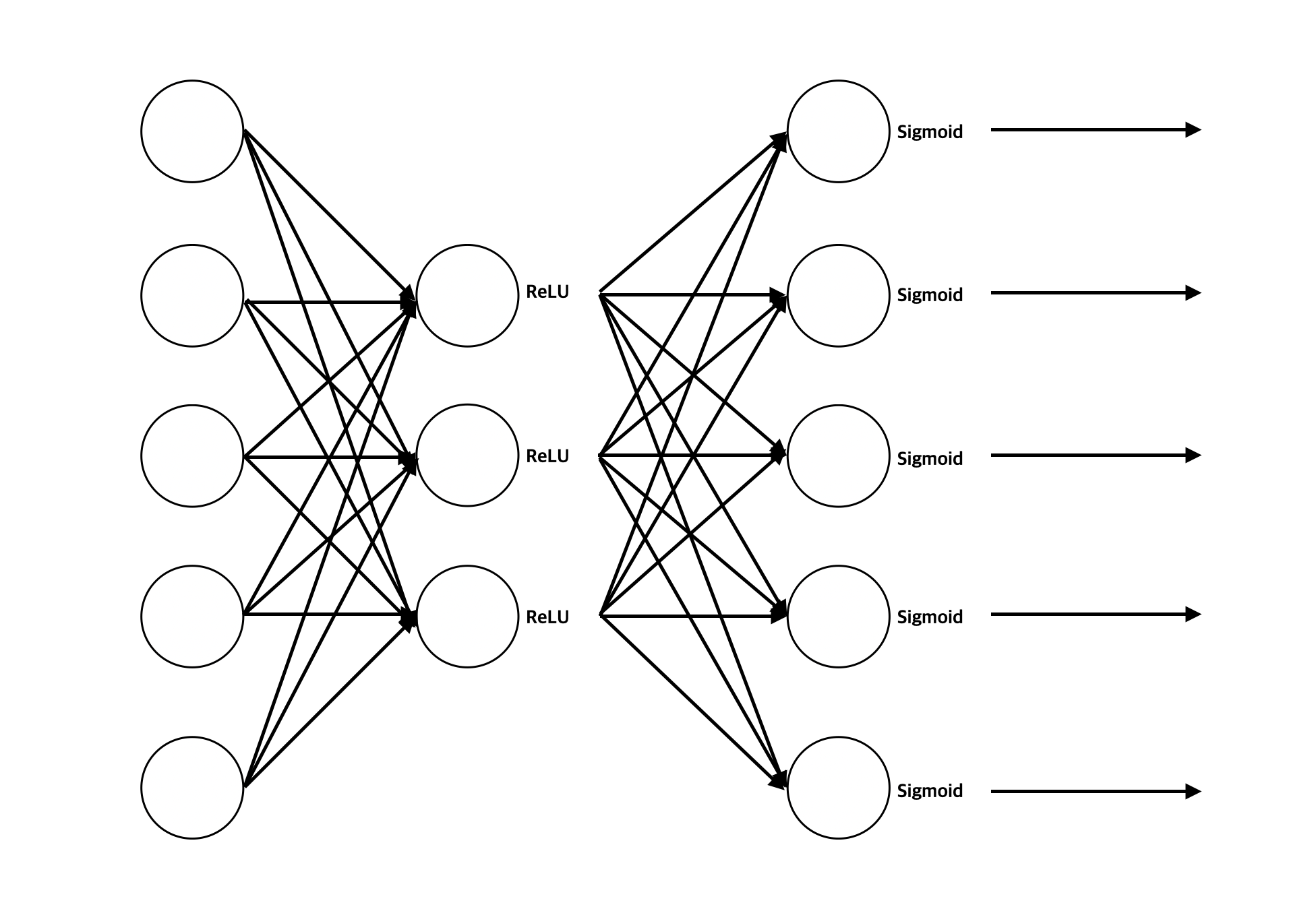
입력이 (2, 5)이므로 두 개의 샘플이 이 신경망을 각각 통과하여 (2, 5)차원의 출력을 만듭니다.
5. 정리
이번 포스팅에서는 간단한 신경망을 파이토치로 구현해봤습니다.
다음 포스팅에서는 역전파와 최적화를 사용하여 간단한 학습을 수행하는 모델을 만들어 보겠습니다.
