
1. Data Preprocessing
대부분의 머신러닝 모델과 마찬가지로 신경망이 주어진 태스크에서 합리적인 성능을 얻기 위해서는 기본적인 전처리 절차가 매우 중요합니다.
입력 분포가 일정해야 뉴런의 활성화 분포도 안정적으로 유지되기 때문입니다.
입력 분포가 일정하지 않으면 한 레이어의 출력이 너무 크거나 작아지고 이로 인해 vanishing/exploding gradient 문제가 발생할 수 있습니다.
자주 사용되는 데이터 전처리 기법들은 다음과 같습니다.
1) Mean Subtraction
평균 제거는 입력 데이터 집합 가 주어졌을 때 데이터를 0 중심(zero-centered)으로 만들기 위해 각 샘플에서 평균 벡터를 빼주는 것입니다.
실전에서 평균은 오직 학습 데이터셋만을 기반으로 계산합니다.
그리고 계산된 평균을 학습, 검증, 테스트셋 모두에 같이 적용합닌다.
2) Normalization
정규화는 모든 입력 피처들의 값 범위가 비슷한 크기(magnitude)를 갖도록 스케일을 조정하는 것입니다.
각 입력 피처가 서로 다른 단위를 갖더라도 초기에는 모든 특성을 동등하고 중요하게 고려하고자 할 때 유용합니다.
평균 제거만큼 자주 사용되지는 않으나 데이터 전처리에서 일반적으로 사용되는 기법입니다.
3) Whitening
화이트닝은 특성 간 상관관계가 0이면서 각 특성의 분산이 1이 되도록 데이터를 변환합니다.
아래의 순서를 통해 데이터를 변환합니다.
- 데이터에서 평균을 제거하여 를 만든다.
- 에 대해 SVD(Singular Value Decomposition)를 수행해서 행렬 를 얻는다.
- 를 의 열 방향 기저로 투영한다.
- 그 결과를 각 고유값(singular value)으로 나눠서 스케일을 통일한다.
고유값이 0인 경우엔 아주 작은 수로 나눠서 계산을 안정화한다.
실전에서는 평균 제거 + 정규화 조합이 기본입니다.
화이트닝은 데이터의 차원이 너무 큰 경우나 고속 학습이 필요한 경우엔 계산 비용이 너무 커지므로 잘 쓰이지 않습니다.
신경망을 실전에 활용할 때 기본적으로 평균 제거와 정규화를 사용하자.
2. Parameter Initialization
신경망에서 최고 성능 달성을 위한 핵심 단계 중 하나가 바로 파라미터를 합리적인 방식으로 초기화하는 것입니다.
예를 들어 가중치를 0을 중심으로 하는 작은 난수(small random numbers)로
초기화하는 방법이 있는데 이 방법은 실제로 많은 경우에서 충분히 잘 작동합니다.
하지만 조금 더 합리적인 방법이 있지 않을까요?
Understanding the difficulty of training deep feedforward neural networks(2010)에서 Xavier et al는 다양한 가중치/편향 초기화 방식이 학습 동작(dynamics)에 어떤 영향을 주는지 연구했습니다.
연구 결과, sigmoid와 tanh을 활성화 함수로 사용할 경우 특정한 초기화 방식을 사용하면 더 빠른 수렴 속도와 더 낮은 오류율을 얻을 수 있습니다.
어떻게 파라미터를 초기화하는지 살펴봅시다.
파라미터 행렬 의 각 원소는 아래의 균등 분포에서 무작위 초기화됩니다.
여기서 은 의 입력 유닛 개수 (fan-in), 은 의 출력 유닛 개수 (fan-out)입니다.
그리고 이 초기화 방법에서는 편향항은 0으로 초기화합니다.
이 초기화의 목적은 각 레이어의 출력값 분산과 역전파 때 기울기의 분산이 일정하게 유지되도록 하기 위함입니다.
분산이 일정하게 유지되지 않으면 레이어가 깊어질수록 기울기의 분산(정보량의 proxy)이 점점 줄어들어 학습이 느려지거나 멈추는 문제가 발생할 수 있습니다.
활성화 함수에 잘 맞는 가중치 초기화 방법이 있으므로 모델을 만들 때
내가 사용할 활성화 함수에 잘 맞는 가중치 초기화 방법을 사용하자.
3. Learning Strategies
학습 중 모델 파라미터의 업데이트 속도 및 크기는 학습률(learning rate)에 의해 제어됩니다.
가장 기본적인 경사 하강법(gradient descent)에서의 업데이트 공식은 다음과 같습니다.
여기서 는 학습률, 는 현재 스텝 의 파라미터에 대한 손실의 기울기입니다.
"빠르게 수렴하려면 학습률을 크게 잡으면 되겠지?"라고 생각할 수 있습니다.
하지만 실제로 학습률이 너무 크면 다음과 같은 문제가 발생할 수 있습니다.
-
Overshooting: 손실 함수의 최솟값을 지나쳐버리는 문제
-
Diverge: 손실이 오히려 발생하는 문제
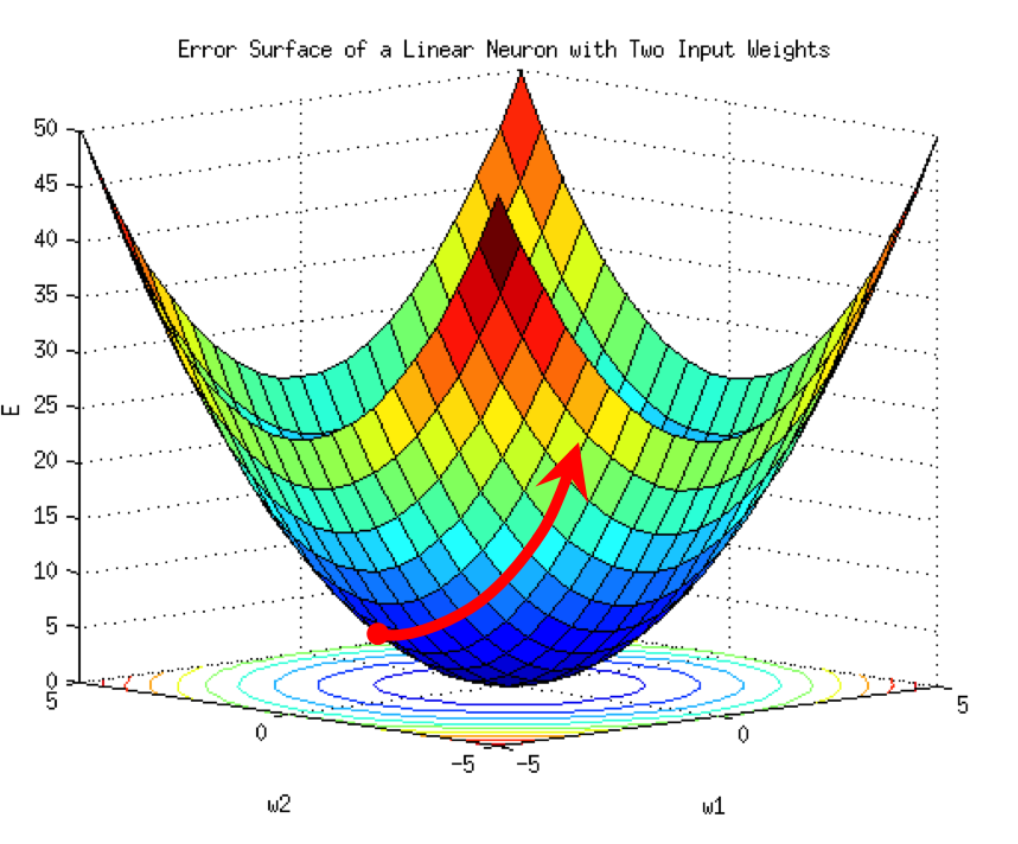
위 피규어는 비볼록(non-convex)한 함수에서 학습률이 너무 커질 경우의 문제를 보여줍니다.
업데이트 방향은 맞지만 학습률이 너무 크면 너무 멀리 이동하여 최솟값을 지나쳐버립니다.
볼록(convex)한 함수 또한 학습률이 너무 크면 발산 문제가 발생할 수 있습니다.
대부분의 신경망은 비볼록 함수로 구성되어 있어 큰 학습률은 대부분 위험합니다.
그럼 학습률을 작게 설정하면 어떨까요?
작은 학습률을 사용하는 것은 가장 단순한 해결책이며 파라미터 공간을 더 세밀하게 스캔하게 해줍니다.
하지만 학습률이 너무 작은 경우 다음과 같은 문제가 발생할 수 있습니다.
-
수렴이 너무 오래 걸린다.
-
Local minima에 갇힐 위험이 크다.
따라서 학습률도 다른 하이퍼파라미터처럼 잘 조율되어야 합니다.
다음은 학습률을 조율하는 전략입니다.
1) Scaling Learning Rate
Ronan Collobert의 학습률 스케일링을 예로 살펴보겠습니다.
뉴런의 입력 수(fan-in) 기준으로 가중치 의 학습률을 조절하는 방식입니다.
2) Annealing
학습률 감소는 여러 반복 후 학습률을 점차 줄이는 방식입니다.
초반에는 큰 학습률로 빠르게 최솟값에 근접하고 후반에는 작은 학습률로 더 정밀하게 수렴하도록 합니다.
예를 들어 매 학습 회 마다 를 특정 비율만큼 줄이는 방식으로 학습률을 감소시킬 수 있습니다.
3) Exponential Decay
지수적 감소는 현재 반복 수 에 대한 학습률 , 즉 가 다음을 따릅니다.
여기서 은 초기 학습률이고 는 감소 속도를 조절하는 하이퍼파라미터입니다.
다른 접근 방법인 타임 기반의 지수적 감소는 아래와 같습니다.
여기서 은 시작 학습률을 표현하며 하이퍼파라미터입니다.
또한 하이퍼파라미터이며 학습률 감소의 시작 시점을 표현합니다.
학습률은 너무 커도 문제, 너무 작아도 문제이므로 조율되어야 한다.
4. Momentum Updates
모멘텀은 기존 경사 하강법의 변형으로써 물리학에서의 운동(dynamic)과 속도(velocity) 개념에 영감을 받았습니다.
다음 파라미터 x에 대한 모멘텀을 업데이트하는 pseudocode를 살펴봅시다.
v = mu * v - alpha * grad_x
x += v여기서 v()는 현재까지 누적된 속도, mu()는 모멘텀 계수, alpha()는 학습률, grad_x()은 현재의 기울기입니다.
기존의 경사 방향(grad)과 함께 속도도 반영합니다.
공이 경사면을 굴러 내려가듯이 기울기가 지속되면 점점 더 빨라지고 기울기가 변해도 급격히 튀지 않고 부드럽게 반응합니다.
일반적인 경사 하강법은 매 스텝마다 오직 현재 기울기만을 고려하는데 실제로는 일정한 방향으로 기울기가 지속되는 경우가 많습니다.
따라서 이 경우 속도를 더해서 더 빠르고 부드럽게 수렴할 수 있습니다.
앞서 살펴본 pseudocode를 수식화하면 다음과 같습니다.
모멘텀은 경사 방향과 속도를 반영해 기울기를 빠르고 부드럽게 수렴시킬 수 있다.
