Controller
쿠버네티스는 Desired State가 기술된 오브젝트를 생성하면 해당 오브젝트의 Desired State를 보장하기 위해 리소스를 항상 감시하며 제어한다. 이렇게 오브젝트가 Desired State를 유지할 수 있도록 관리하는 역할을 하는 것이 컨트롤러이다. 즉 클러스터의 Control Plane에 위치해서 오브젝트들을 쉽게 관리하고 운영할 수 있도록 도움을 주는 오브젝트가 컨트롤러이다.
컨트롤러의 주요 기능은 다음과 같다.
- Auto Healing: 파드가 다운되거나 파드가 스케줄링 되어 있는 노드가 다운되는 등 해당 파드에서 돌아가던 서비스에 장애가 발생하게 되면 컨트롤러는 즉각 인지하고 파드를 다른 노드에 새로 만들어 준다.
- Auto Scaling: 파드에 리소스가 limit 상태가 되었을 떄 컨트롤러는 이 상태를 파악하고 파드를 하나 더 만들어줌으로써 부하를 분산시키고 파드가 죽지 않게 해준다. 이를 통해 성능 장애없이 안정적인 서비스를 운영할 수 있다.
- Software Update: 여러 파드에 대해서 버전을 업그레이드해야 할 때 컨트롤러를 통해 한번에 쉽게 할 수 있다. 도중에 문제가 생기면 롤백도 가능하다.
- Job: 일시적인 작업을 해야할 경우, 컨트롤러가 필요한 순간에만 파드를 만들어서 해당 작업을 수행하고 삭제한다. 이를 통해 그 순간에만 자원이 사용되고 작업 후에는 다시 반환되기 떄문에 효율적인 자원 활용이 가능해진다.
컨트롤러의 종류에는 여러 가지가 있다.
- Replication Controller
- ReplicaSet
- Deployment
- DaemonSet
- Job
- CronJob
- StatefulSet Controller
- Node Controller
- Service Controller
- Endpoint Controller
- Namespace Controller
- Volume Controller
Replication Controller
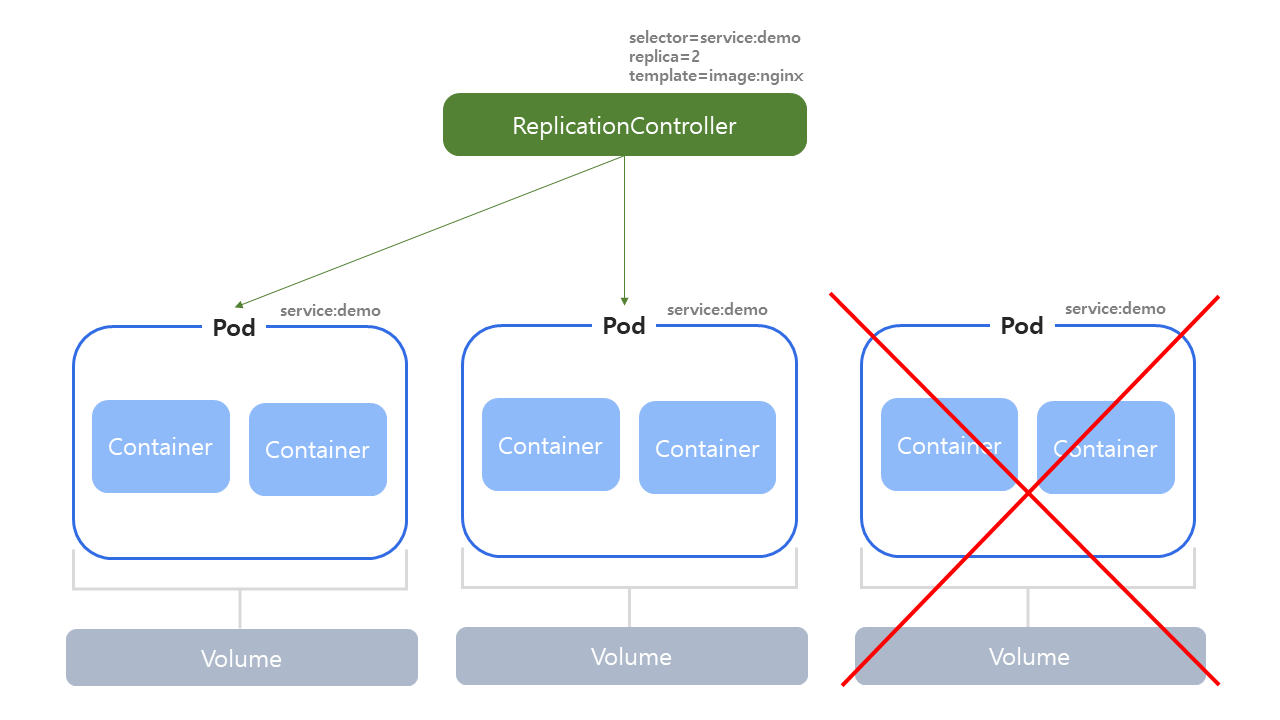
Replication Controller는 지정된 수만큼의 파드들이 항상 클러스터 내에서 실행되고 있도록 관리해주는 가장 기본적인 컨트롤러이다.
ReplicaSet
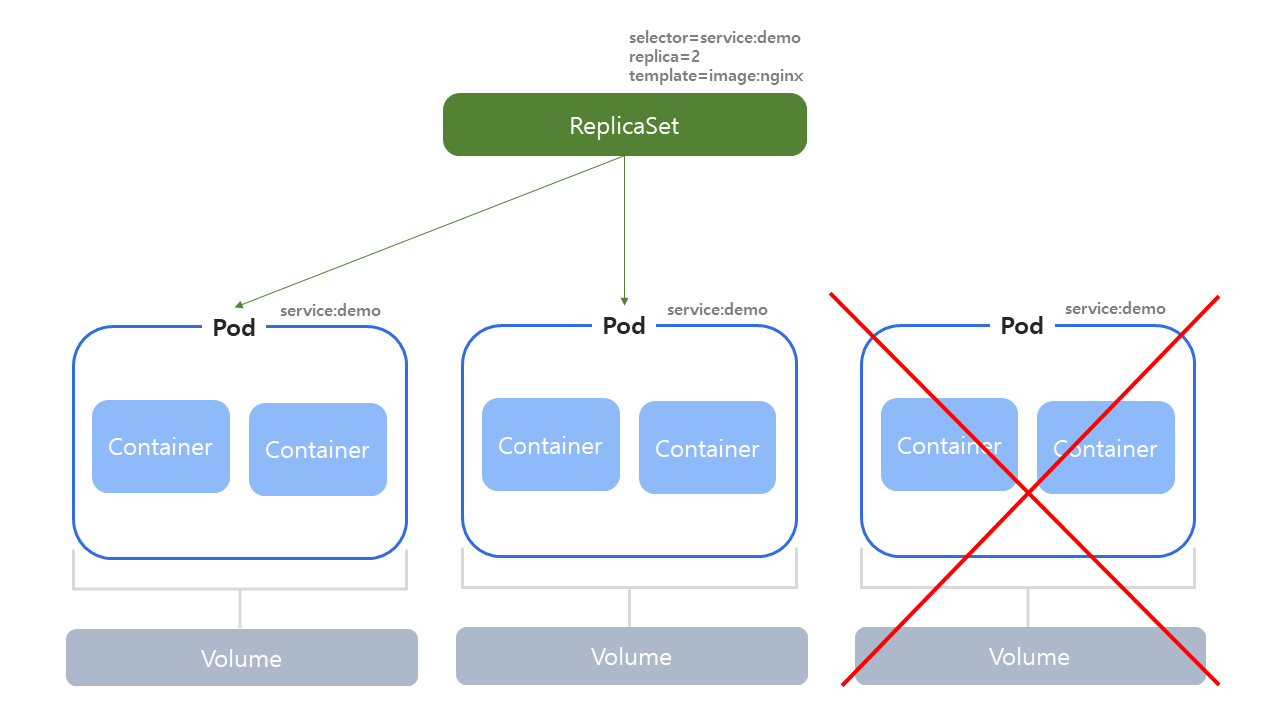
Replication Controller는 Deprecated되어 ReplicaSet으로 대체되었다. 이러한 컨트롤러를 만들 때 정의해줘야 하는 중요한 속성으로는 Template, Replicas, Selector가 있다.
Template
컨트롤러와 파드는 서비스와 파드를 연결할 때처럼 레이블과 셀렉터로 연결된다. template에는 파드에 대한 이러한 정보가 있는데 컨트롤러는 template 내용을 바탕으로 파드를 만들어주게 된다. 이러한 특성을 이용해서 애플리케이션에 대한 업그레이드가 가능하다.
Replicas
컨트롤러에서 설정하는 클러스터 안에서 기동할 파드의 개수를 replicas라고 한다. replicas만큼 파드의 개수가 관리된다. 이를 이용해 scale out, scale in이 가능하다.
Selector
Replication Controller selector의 경우 레이블로 파드를 선택할 때 key, value 중 하나만 달라도 연결하지 않지만 ReplicaSet selector의 경우 matchExpressions을 이용해 키와 밸류 값이 완전히 일치하지 않아도 조금은 유동적으로 파드와 연결이 가능하다.
- matchLabels
- matchExpressions
- Exists
- DoesNotExists
- In
- NotIn
다음은 ReplicaSet을 생성하는 예시이다.
apiVersion: v1
kind: Pod
metadata:
name: pod1
labels:
type: web
spec:
containers:
- name: container
image: kubetm/app:v1
terminationGracePeriodSeconds: 0
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replica1
spec:
replicas: 1
selector:
matchLabels:
type: web
template:
metadata:
name: pod1
labels:
type: web
spec:
containers:
- name: container
image: kubetm/app:v1
terminationGracePeriodSeconds: 0기본적으로 컨트롤러를 삭제하면 컨트롤러가 관리하는 파드들도 모두 삭제된다.
Deployment
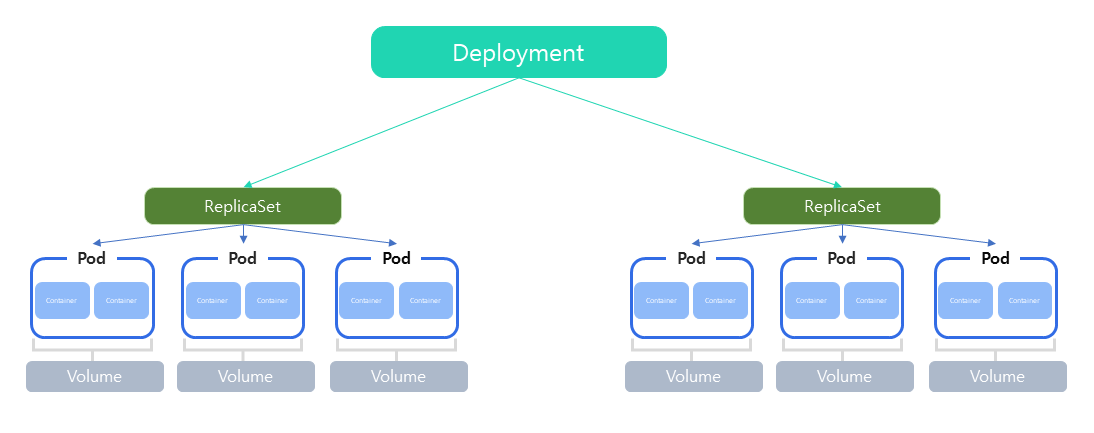
Deployment는 Pod와 ReplicaSet에 대한 배포 관리를 해주는 컨트롤러이다. Deployment는 운영 중인 애플리케이션에 대해서 새 버전을 업데이트해야 해서 재배포를 해야할 때 도움을 준다.
Deployment를 사용해서 이용 가능한 애플리케이션 업데이트 배포 전략에는 크게 4가지가 있다.
- ReCreate
- RollingUpdate
- Blue/Green
- Canary
ReCreate
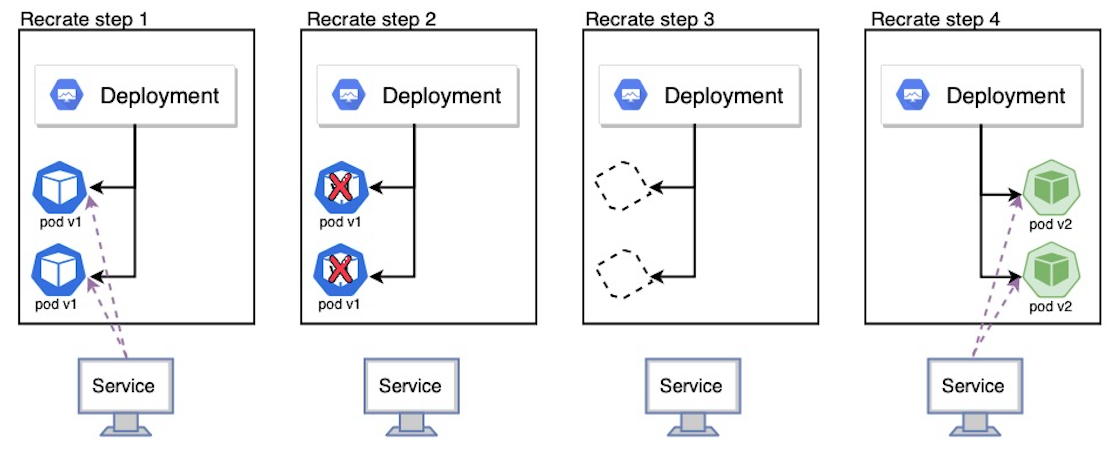
ReCreate 방식은 이전 버전의 파드를 삭제하고 새 버전의 파드들을 생성해서 애플리케이션을 업데이트하는 방식으로 자원을 효율적으로 사용할 수 있다는 장점은 있지만 downtime이 존재한다는 단점이 있다. 그렇기 때문에 중단 배포가 가능한 서비스에서만 사용한 방식이다. ReCreate 방식은 다음과 같은 단계로 진행된다.
1. Deployment에 있는 template 값을 v2로 업데이트
2. Deployment가 기존 ReplicateSet의 replcas를 0으로 만들어 v1 파드들 삭제
3. 삭제된 파드들에 대한 자원 회수
4. 변경된 내용이 반영된 새로운 ReplicaSet을 만들어 v2 파드가 생성되고 서비스들과 연결
다음은 ReCreate 방식으로 배포 관리하는 Deployment 예시이다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-1
spec:
selector:
matchLabels:
type: app
replicas: 2
strategy:
type: Recreate
revisionHistoryLimit: 1
template:
metadata:
labels:
type: app
spec:
containers:
- name: container
image: kubetm/app:v1
terminationGracePeriodSeconds: 10selector, replcas, template은 ReplicaSet을 만들 때 해당 값들을 지정하기 위한 용도로 사용된다. 이렇게 생성된 ReplicaSet은 본연의 역할대로 파드들을 생성해서 관리한다. 이 때 서비스를 만들어서 파드의 레이블에 연결하면 서비스를 통해 파드에 접근이 가능하다. strategy에는 업데이트 배포 방식이 값으로 들어간다. revisionHistoryLimit은 업데이트 이후 replicas 값이 0인 이전 버전의 ReplicaSet을 얼마나 관리할 것인지에 관한 값이다. 예를 들어 revisionHistoryLimit이 1이면 업데이트 이후 이전 버전 ReplicaSet을 하나만 남기겠다는 의미이다. 디폴트값은 1이다. 이전 버전의 ReplicaSet을 남겨두면 롤백이 가능하다.
Rolling Update
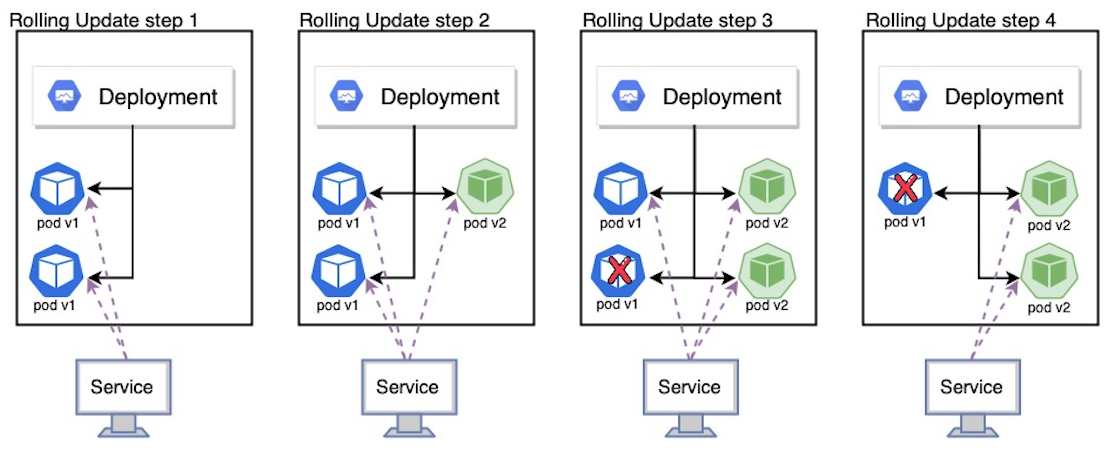
Rolling Update 방식은 새 버전의 파드를 하나 생성하고 이전 버전의 파드를 하나 삭제하면서 순차적으로 애플리케이션을 업데이트하는 방식이다. 업데이트 배포 중 중간 단계에서 사용자는 v1, v2 두 가지 파드에 모두 접근 가능하며 이 과정에서 추가적인 자원 할당이 필요하지만, ReCreate 방식과는 달리 downtime이 존재하지 않아 일반적인 무중단 배포 서비스에 적용 가능하다. Rolling Update 방식은 다음과 같은 단계로 진행된다.
1. Deployment에 있는 template 값을 v2로 업데이트
2. 변경된 내용이 반영된 새로운 ReplicaSet을 만들어 v2 파드가 생성되고 서비스들과 연결 -> v1, v2 파드 모두 접속 가능
3. 이후 순차적으로 v1 ReplicaSet replicas를 줄이면서 v1 파드를 삭제하고 v2 ReplicaSet replicas를 증가시키면서 v2 파드를 생성
4. v2 파드들만 남게 된 상태에서 배포 종료
다음은 Rolling Update 방식으로 배포 관리하는 Deployment 예시이다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-2
spec:
selector:
matchLabels:
type: app2
replicas: 2
strategy:
type: RollingUpdate
minReadySeconds: 10
template:
metadata:
labels:
type: app2
spec:
containers:
- name: container
image: kubetm/app:v1
terminationGracePeriodSeconds: 0minReadySeconds는 어느 정도의 텀을 가지고 배포할 것인지에 대한 값이다.
Blue/Green
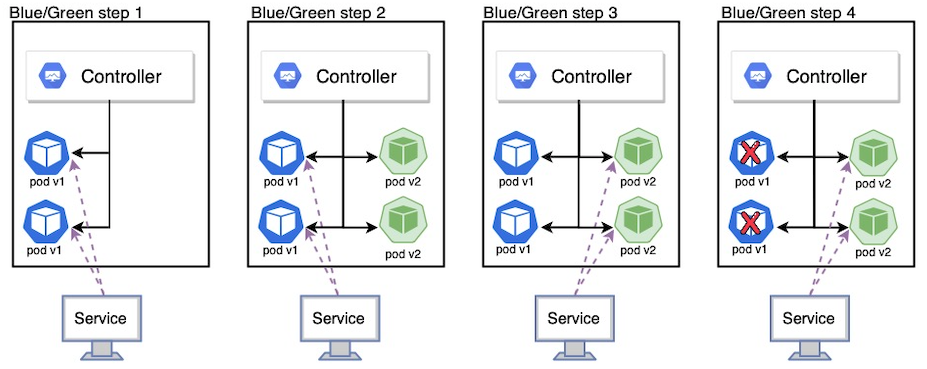
Rolling Update가 순차적으로 업데이트를 진행하는 방식이었다면 Blue/Green 배포 전략은 이전 버전에서 새로운 버전으로 트래픽을 일제히 전환하는 무중단 배포 전략이다. 새로운 버전에서 문제가 발생했을 때 빠르게 롤백이 가능하며 downtime 없이 이전 버전에서 신규 버전으로 한번에 이전이 가능하기 때문에 배포 중 자원이 2배로 필요하다는 단점이 존재하지만 가장 많이 사용되는 배포 방식이다. Deployment의 자체 기능은 아니며 Deployment나 ReplicSet과 같은 컨트롤러를 새롭게 만들어 서비스에 있는 셀렉터와 레이블을 변경하는 방식으로 구현이 가능하다. Blue/Green 방식은 다음과 같은 단계로 진행된다.
1. v2 컨트롤러를 만들어 v2 파드들을 생성
2. 서비스에 있는 셀렉터와 레이블을 변경해서 기존 파드와의 관계는 끊고 새로운 파드들과 연결
3. v2에 문제가 있으면 레이블만 바꿔서 롤백을 진행하고 문제가 없으면 기존 버전 삭제
Canary
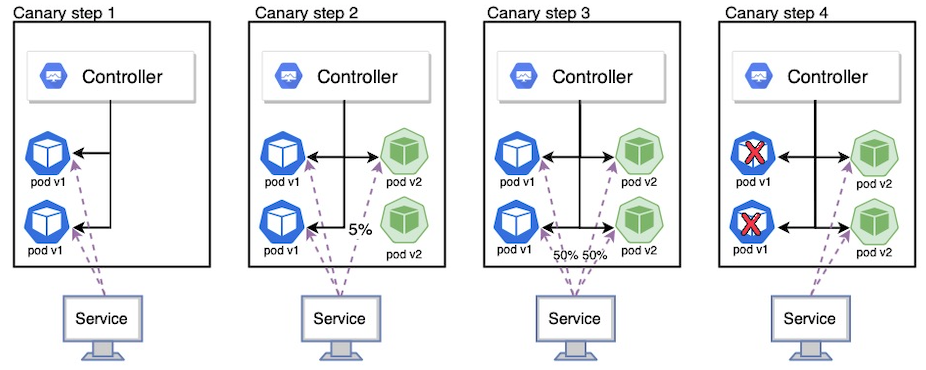
Blue/Green 방식과 유사하게 새로운 버전의 컨트롤러를 생성하여 불특정 다수에게 일종의 실험 개념으로 배포하여 테스트를 한 뒤, 문제가 없을 경우 새로운 버전의 컨트롤러만 남겨서 정식 배포를 하고 기존의 컨트롤러는 삭제하는 방식이다. Canary 방식은 다음과 같은 단계로 진행된다.
1. 테스트하고 싶은 v2 컨트롤러를 만들고 별도의 파드 레이블을 지정한 뒤, replicas를 적게 지정하여 서비스에 연결
2. v2의 replicas를 늘려서 트래픽을 조금씩 늘려서 테스트
3.. 문제가 있을 경우 replicas를 다시 0으로 줄이고 그렇지 않다면 테스트 기간 종료 뒤 v2를 증가시킨 뒤 v1을 삭제
DaemonSet
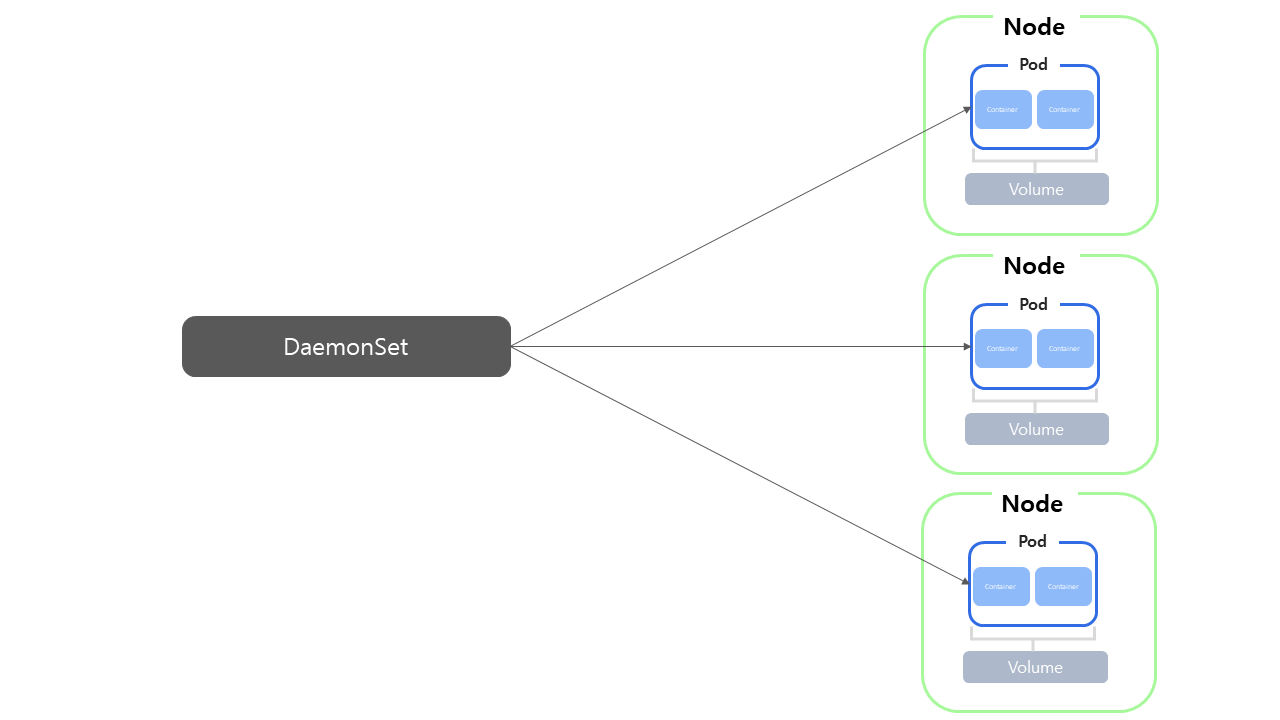
DaemonSet은 클러스터 전체에 배포가 필요한 파드를 관리해주는 컨트롤러이다. 모든 노드에 DaemonSet 파드가 하나씩 생성된다. 클러스터에 각 노드들의 자원이 다르게 남아있는 상황에서, ReplicaSet의 경우 스케줄러에 의존해서 파드들을 노드에 배치할 때 특정 노드에 자원 많이 남아있다면 해당 노드에 파드를 많이 배치하게 되지만, DaemonSet은 노드의 자원 상태와는 상관없이 모든 노드에 파드가 하나씩 생긴다는 특징이 있다. DaemonSet은 각 노드마다 설치가 되어서 사용되어야 하는 백그라운드 프로세스적인 기능들이 있는데 이를 관리하기 위한 용도로 사용된다. 대표적으로 프로메테우스와 같이 성능 모니터링을 위한 성능 지표 수집, 로그 수집, 스토리지 기능 등이 있다. 쿠버네티스 자체도 네트워킹 관리를 위해 각 노드에 데몬셋으로 프록시 역할하는 파드를 생성한다.
다음과 같이 작성할 수 있고, hostPort 18080으로 들어온 트래픽이 containerPort 8080으로 들어가게 된다.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-1
spec:
selector:
matchLabels:
type: app
template:
metadata:
labels:
type: app
spec:
containers:
- name: container
image: kubetm/app
ports:
- containerPort: 8080
hostPort: 18080다음과 같이 노드 셀렉터를 이용해 노드별로 데몬셋을 적용할 수 있다.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-2
spec:
selector:
matchLabels:
type: app
template:
metadata:
labels:
type: app
spec:
nodeSelector:
os: centos
containers:
- name: container
image: kubetm/app
ports:
- containerPort: 8080Job
일반 파드처럼 항상 실행되고 있는 서비스 프로세스가 아닌 실행 후에 작업이 끝나면 완료가 되는 일회성 성격의 작업을 수행하는 파드들을 관리해주는 컨트롤러이다. 잡으로 만들어진 파드는 프로세스가 일을 하지 않으면 종료가 된다. 종료가 되었다고 바로 삭제되는 것은 아니기 때문에 파드에 접속해서 로그를 볼 수 있다. 이후에 필요가 없다면 삭제할 수 있다.
다음과 같이 잡을 생성할 수 있다.
apiVersion: batch/v1
kind: Job
metadata:
name: job-2
spec:
completions: 6
parallelism: 2
activeDeadlineSeconds: 30
template:
spec:
restartPolicy: Never
containers:
- name: container
image: kubetm/init
command: ["sh", "-c", "echo 'job start';sleep 20; echo 'job end'"]
terminationGracePeriodSeconds: 0parallism은 해당 수만큼 잡 파드가 생겨 병행 수행하게 된다. restartPolicy은 파드 라이프 사이클과 관련이 있는데 Never, OnFailure이 있다. activeDealineSeconds 속성은 해당 시간 이후에 파드의 기능을 정지하기 위한 값이다.
CronJob
크론잡은 이러한 잡들을 주기적인 시간에 따라 생성하고 관리하기 위한 컨트롤러이다. 보통 잡을 단건으로 사용하진 않고 크론잡을 만들어서 특정 시간에 실행할 목적으로 사용한다. DB 백업, 주기적인 예약 메일 서비스 등에 사용될 수 있다.
다음과 같이 크론잡을 생성할 수 있다.
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cron-job-2
spec:
schedule: "20,21,22 * * * *"
concurrencyPolicy: Replace
jobTemplate:
spec:
template:
spec:
restartPolicy: Never
containers:
- name: container
image: kubetm/init
command: ["sh", "-c", "echo 'job start';sleep 140; echo 'job end'"]
terminationGracePeriodSeconds: 0schedule 옵션으로 크론 포현식을 통해 스케줄링 시간 주기를 정할 수 있다. concurrencyPolicy는 주기마다 잡의 동시성 정책을 제어하기 위한 옵션이다. concurrencyPolicy의 값들은 다음과 같다.
- Allow(디폴트)
- 이전에 만든 파드 상태와는 관련없이 스케줄 타임이 되면 새로운 잡을 만든다.
- Forbid
- 이전에 만든 파드가 종료되지 않고 실행 중이면 두 번째 잡은 스킵한다. 종료되는 즉시 다음 스케줄 타임에 있는 잡이 만들어진다.
- Replace
- 이전에 만든 파드가 종료되지 않았으면 다음 주기에 새로운 잡 만들어서 교체해서 실행한다.
Reference
