[Spring Kafka]Kafka Consumer 제대로 알고 사용하자!!

🚨해당 글은 Spring Kafka에 대한 사용방법과 실제 업무의 경험을 곁들인 적용법을 다루고 있습니다.
Apache Kafka에 대한 내용은 다루지 않고 있음을 참고부탁드립니다.
이전글에서는 spring-kafka에서의 Producer에 관하여 정리하였었다. 이번글에서는 spring-kafka를 통한 Consumer 방식에 대해 정리하겠다.
우선은 기본적인 사용방식에 대해서 먼저 정리를 하겠다. spring-kafka 문서에서는 카프카 메세지를 수신하기 위해서 MessageListenerContainer와 message listener 또는 @KafkaListener를 사용하라고 한다.
현재 MessageListenerContainer에 지원되는 MessageListener는 8개의 Interface를 지원한다.
public interface MessageListener<K, V> {
void onMessage(ConsumerRecord<K, V> data);
}
public interface AcknowledgingMessageListener<K, V> {
void onMessage(ConsumerRecord<K, V> data, Acknowledgment acknowledgment);
}
public interface ConsumerAwareMessageListener<K, V> extends MessageListener<K, V> {
void onMessage(ConsumerRecord<K, V> data, Consumer<?, ?> consumer);
}
public interface AcknowledgingConsumerAwareMessageListener<K, V> extends MessageListener<K, V> {
void onMessage(ConsumerRecord<K, V> data, Acknowledgment acknowledgment, Consumer<?, ?> consumer);
}
public interface BatchMessageListener<K, V> {
void onMessage(List<ConsumerRecord<K, V>> data);
}
public interface BatchAcknowledgingMessageListener<K, V> {
void onMessage(List<ConsumerRecord<K, V>> data, Acknowledgment acknowledgment);
}
public interface BatchConsumerAwareMessageListener<K, V> extends BatchMessageListener<K, V> {
void onMessage(List<ConsumerRecord<K, V>> data, Consumer<?, ?> consumer);
}
public interface BatchAcknowledgingConsumerAwareMessageListener<K, V> extends BatchMessageListener<K, V> {
void onMessage(List<ConsumerRecord<K, V>> data, Acknowledgment acknowledgment, Consumer<?, ?> consumer);
}간단하게 설명하면 단건, 다건, Manual Commit, Consumer에 해당되는 조합의 Interface가 제공된다. 자세한 내용은 다음 문서에 자세히 설명되어 있다.
Message Listener Containers
MessageListenerContainer의 구현체로는 2가지가 제공된다.
- KafkaMessageListenerContainer: 싱글 스레드에서 설정 토픽 또는 파티션의 모든 메세지를 수신한다.
- ConcurrentMessageListenerContainer: 하나 이상의
KafkaMessageListenerContainer인스턴스를 제공하여 멀티 스레드를 제공한다.
@KafkaListener
spring-kafka에서 메세지 수신을 위해 제공하는 방식중 하나인 @KafkaListener는 기본 설정으로는 kafkaListenerContainerFactory으로 등록된 bean으로 ConcurrentMessageListenerContainer를 생성하여 메세지를 수신한다.
@Configuration
public class KafkaConfig {
@Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(2);
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfig());
}
@Bean
public Map<String, Object> consumerConfig() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
}
}@Component
@Slf4j
public class MyKafkaEventListener {
@KafkaListener(groupId = "myGroup", topics = "TEST")
public void test(ConsumerRecord<String, String> data, Acknowledgment acknowledgment, Consumer<String, String> consumer){
System.out.println();
}
@KafkaListener(groupId = "myGroup", topics = {"TEST1", "TEST2", "TEST3","TEST4","TEST5"})
public void test1(ConsumerRecord<String, String> data, Acknowledgment acknowledgment, Consumer<String, String> consumer){
log.info(data.topic());
acknowledgment.acknowledge();
}
}위의 설정은 기본적인 설정으로 @KafkaListener topics에 정의된 topic에 message가 수신되면 해당 메소드가 실행되게 된다.
ContainerProperties에 setAckMode를 설정하게 된다면 ConsumerConfig의 enable.auto.commit값이 false로 설정되며 직접 commit를 설정할 수 있게된다.
ContainerProperties.setAckMode를 참고하면 각 AckMode에 따라 Commit이 어떤 방식으로 수행되는지 확인 할 수 있다.
지금까지는 기본적인 사용방법에 대해서 정리하였다. 이렇게 설정된 서버의 로그를 확인해보면 내 생각과 살짝 다르게 동작하는것이 아닐까하는 로그를 확인할 수 있었다.
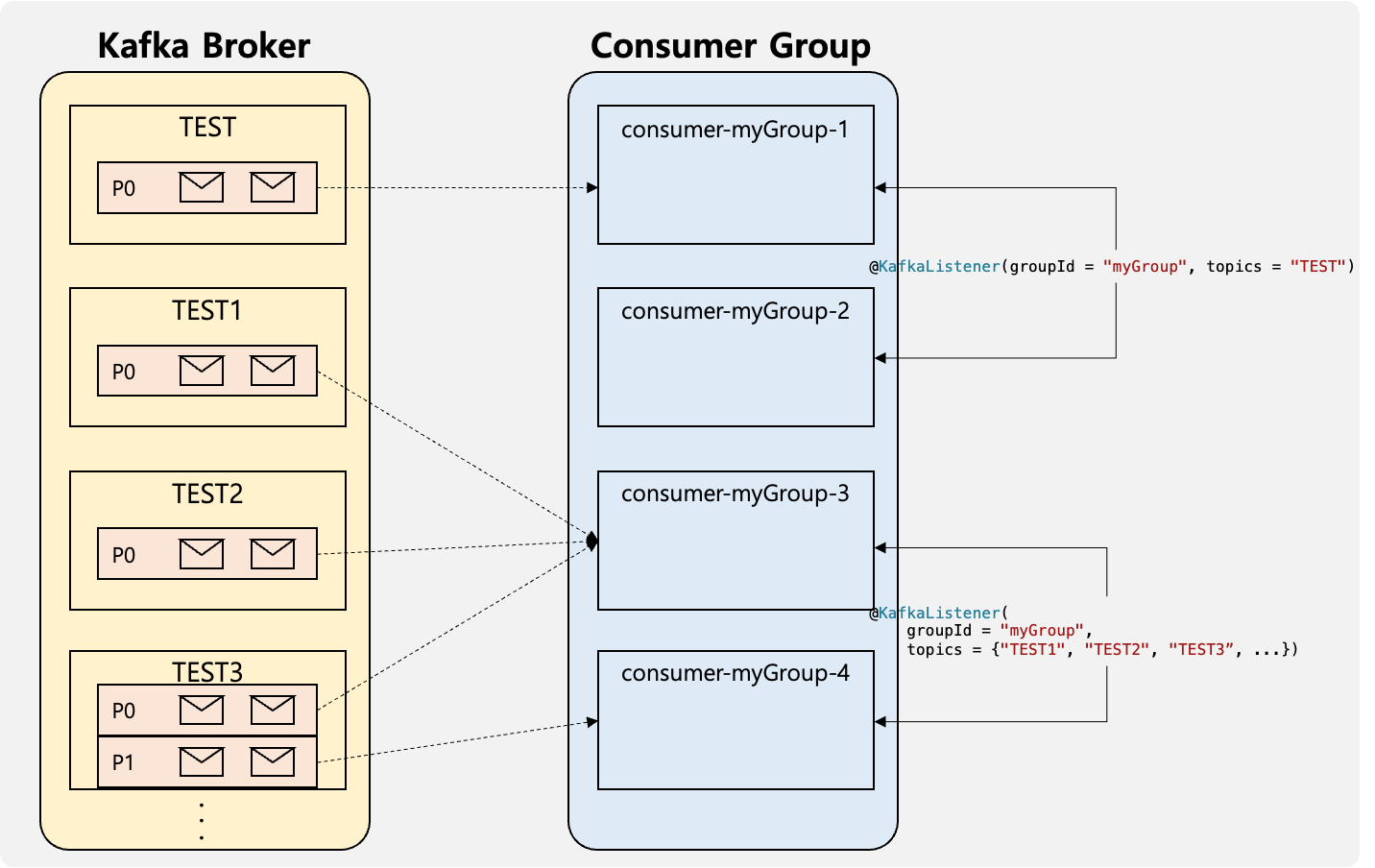
INFO 29333 --- [ntainer#0-1-C-1] o.s.k.l.KafkaMessageListenerContainer : myGroup: partitions assigned: []
INFO 29333 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-myGroup-1, groupId=myGroup] Adding newly assigned partitions: TEST-0
INFO 29333 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-myGroup-3, groupId=myGroup] Adding newly assigned partitions: TEST1-0, TEST2-0, TEST3-0, TEST4-0, TEST5-0
INFO 29333 --- [ntainer#1-1-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-myGroup-4, groupId=myGroup] Adding newly assigned partitions: TEST3-1
INFO 29333 --- [ntainer#0-0-C-1] o.s.k.l.KafkaMessageListenerContainer : myGroup: partitions assigned: [TEST-0]
INFO 29333 --- [ntainer#1-1-C-1] o.s.k.l.KafkaMessageListenerContainer : myGroup: partitions assigned: [TEST3-1]
INFO 29333 --- [ntainer#1-0-C-1] o.s.k.l.KafkaMessageListenerContainer : myGroup: partitions assigned: [TEST1-0, TEST2-0, TEST3-0, TEST4-0, TEST5-0]@KafkaListener를 2개를 선언하였으며 ConcurrentMessageListenerContainer.setConcurrency를 2를 설정하였다. 설정한 예상대로 0-0-C-1, 0-1-C-1, 1-0-C-1, 1-1-C-1 4개의 쓰레드가 생성되었다. 그러나 해당 쓰레드에서 수신하고 있는 Topic-Partition이 예상과 다르게 분배되어있는 것이였다. 나는 TEST1-5 토픽의 파티션 6개가 2개의 쓰레드에 분배되어 수신을 할것으로 생각하였다.
Partition Assignment Strategy
지금까지 순차보장을 위해 Topic에 하나의 Partition을 생성하여 사용한 경우 concurrency를 2이상 설정한 경우 수행되지 않는 쓰레드를 생성하였던 것이였다. 확인 결과 Consumer 설정 중 partition.assignment.strategy이 존재하였다.
Range Partition Assignment Strategy
기본 설정은 RangeAssignor 방식으로 Topic의 Partition이 순서대로 Consumer에 할당되는 전략이였다. 즉 Topic이 수많더라도 상관없이 해당 Topic의 Partition의 순서에 따라 Consumer가 결정되는 전략이다.
Round Robin & Sticky Partition Assignment Strategies
Round Robin 방식과 Sticky 방식은 Consumer에 Partition를 균등하게 분배하는 방식이며 두 방식의 차이는 Rebalancing이 발생할시 기존 Consumer에 할당된 Partition를 전체를 다시 재할당 하는 방식은 Round Robin 방식이며 영향을 받지 않는 Consumer와 Partition의 할당을 가능한 유지하는 방식이 Sticky 방식이다. 즉 초기 할당된 결과는 같으나 Rebalancing이 발생 할 경우 서로의 분배 결과가 다를수 있다.
@Bean
public Map<String, Object> consumerConfig() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, Arrays.asList(StickyAssignor.class));
return props;
}INFO 30569 --- [ntainer#0-1-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-myGroup-2, groupId=myGroup] Adding newly assigned partitions:
INFO 30569 --- [ntainer#0-1-C-1] o.s.k.l.KafkaMessageListenerContainer : myGroup: partitions assigned: []
INFO 30569 --- [ntainer#1-1-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-myGroup-4, groupId=myGroup] Adding newly assigned partitions: TEST2-0, TEST3-1, TEST5-0
INFO 30569 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-myGroup-1, groupId=myGroup] Adding newly assigned partitions: TEST-0
INFO 30569 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-myGroup-3, groupId=myGroup] Adding newly assigned partitions: TEST1-0, TEST3-0, TEST4-0
INFO 30569 --- [ntainer#0-0-C-1] o.s.k.l.KafkaMessageListenerContainer : myGroup: partitions assigned: [TEST-0]
INFO 30569 --- [ntainer#1-1-C-1] o.s.k.l.KafkaMessageListenerContainer : myGroup: partitions assigned: [TEST2-0, TEST3-1, TEST5-0]
INFO 30569 --- [ntainer#1-0-C-1] o.s.k.l.KafkaMessageListenerContainer : myGroup: partitions assigned: [TEST1-0, TEST3-0, TEST4-0]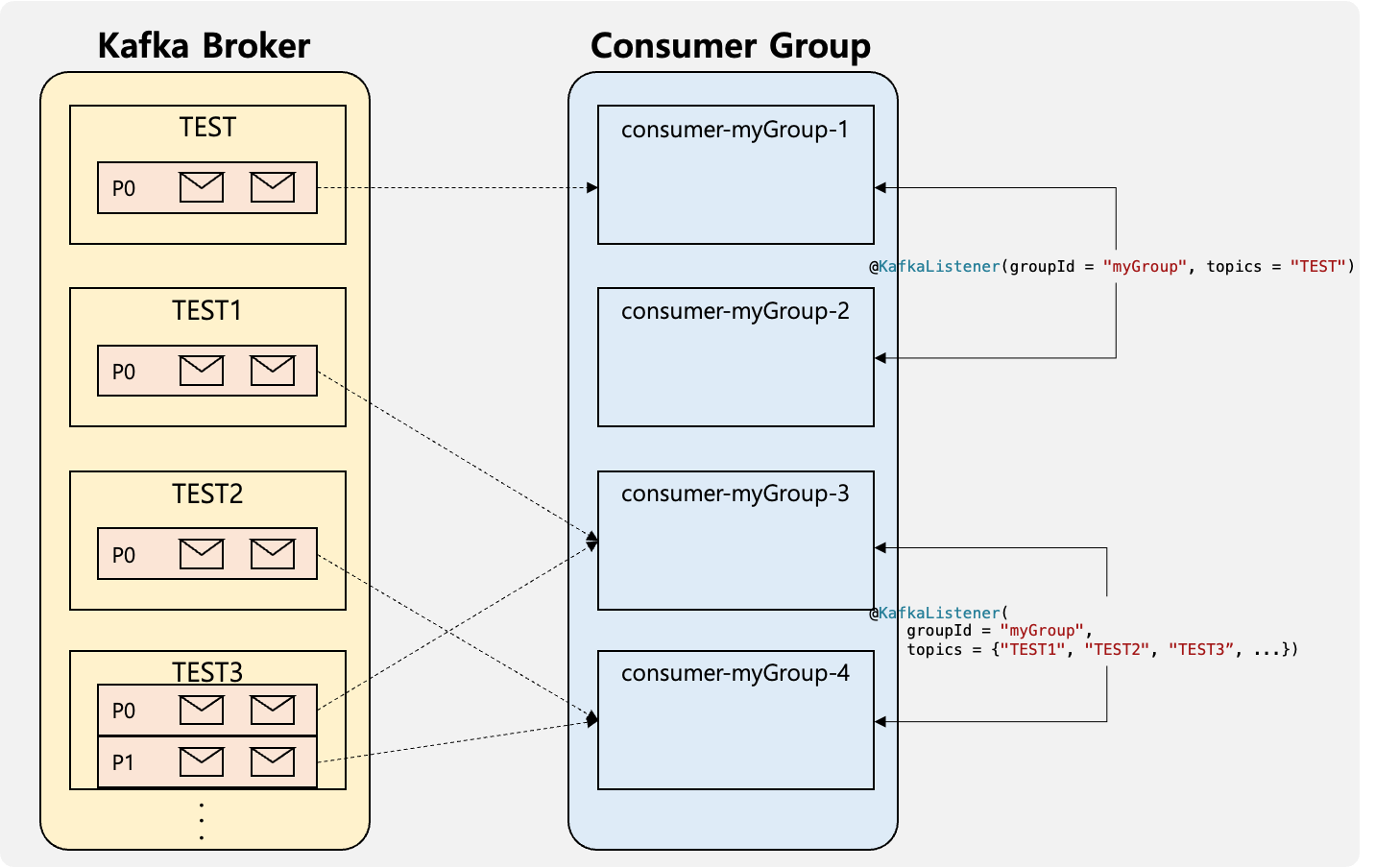
위와 같이 Round Robin 방식은 전체를 다시 재할당 하는 방식이기 때문에 Message 수신에 중단이 반드시 발생하게 된다. Sticky 방식은 기본적으로는 재할당 되는Partition은 중단이된다. 이러한 중단없이 다시 할당하는 방식은 CooperativeSticky이다. 간단하게 설명하면 두번의 Rebalancing를 통해서 첫번째 Rebalancing에서는 영향을 받는 Consumer의 Partition을 종료시키며 두번째 Rebalancing에서 할당될 Consumer 정보를 넘겨 해당 Consumer에 할당하는 방식으로 거의 중단없이 Message 수신이 가능한 방식이다. 자세한 설명은 다음 강의를 참고하면된다.
Concurrency라는 단어는 개발자 입장에서 매우 자극적인 단어이다. 이러한 단어만 보고 단순히 지금까지 ConcurrentMessageListenerContainer를 사용하며 Concurrency를 2이상 설정하여 사용하였었는데 잘못된 사용법이였던것이다. 이번 Spring Kafka 정리를 통하여 그 동안 놓치고 있었던 설정들에 대해 알 수 있었던 시간이 되었다.
