sort
📋 sort.py
- 문자열 정렬하기 (sorted() 함수 )
- sorted() 함수 : 특정 변수에 저장된 값을 오름차순 정렬해주는 함수 ( 1,2,3... 사전순 정렬)
sorted만 써도 저렇게 알아서 되어서 신기하다.- 기본 오름차순.
reverse=True를 쓰면 내림차순 정렬
strdate = input('정렬할 문자열을 입력하세요?')
ret1 = sorted(strdate) # 오름차순 정렬(a b c ...)
ret2 = sorted(strdate, reverse=True) # 내림차순 정렬
print(ret1)
print(ret2)
ret1 = ''.join(ret1)
ret2 = ' '.join(ret2)
print('오름차순으로 정렬된 문자열은 <' + ret1 + '> 입니다.')
print('내림차순으로 정렬된 문자열은 <' + ret2 + '> 입니다.')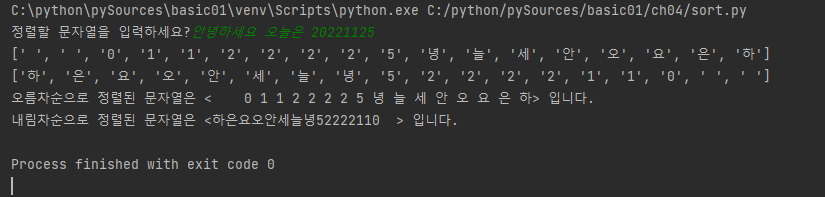
spilt
📋 spilt.py
- 문자열을 특정문자로 분리하기 ( split() 함수 )
- split() 함수는 구분자(separator)로 구분되어 있는 문자열을 파싱(parsing)하는 역할을 한다.
url = 'http://www.naver.com/news/today=20160831'
log = 'name:홍길동 age:17 sex:남자 nation:조선'
ret1 = url.split('/') # url 변수에 저장된 데이터를 구분자 ('/')로 파싱
print(ret1)
# 결과 : ['http:', '', 'www.naver.com', 'news', 'today=20160831']
ret2 = log.split() # log 변수에 저장된데이터를 공백으로 파싱
print(ret2)
# 결과 : ['name:홍길동', 'age:17', 'sex:남자', 'nation:조선']
for data in ret2:
d1, d2 = data.split(':') # data 변수에 저장된 데이터를 구분자(':')로 파싱
print('%s -> %s' % (d1, d2))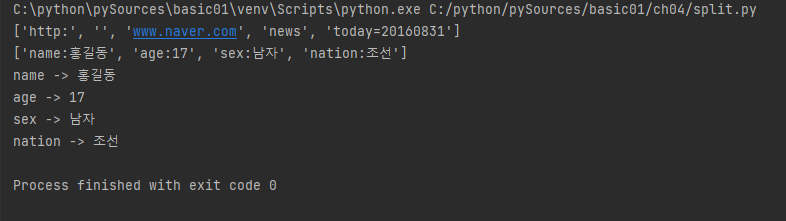
문자열로 변환 str
📋 str.py
- 수치형 자료를 문자열로 변환하기 ( str() 함수 )
num1 = 1234
num2 = 3.14
numstr1 = str(num1)
numstr2 = str(num2)
print(type(numstr1)) # 정수를 문자열로 변환
print(type(numstr2)) # 실수를 문자열로 변환
print('num1을 문자열로 변환한 값은 "%s" 입니다.' %numstr1)
print('num2을 문자열로 변환한 값은 "%s" 입니다.' %numstr2)
print('num1을 문자열로 변환한 값은 "%d" 입니다.' %num1)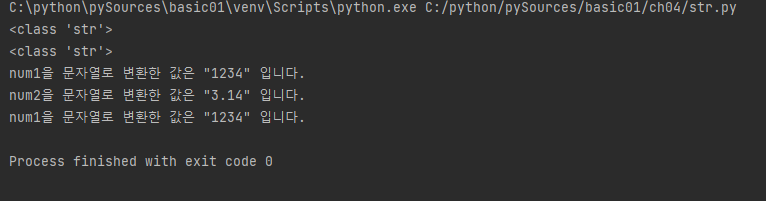
공백 제거 strip
📋 strip.py
문자열을 특정 문자열로 결합하기
- 문자열 좌.우 좌우공백 제거하기 ( lstrip(), rstrip(), strip() 함수 )
- lstrip() : 문자열 좌측의 공백을 없애주는 함수
- rstrip() : 문자열 우측의 공백을 없애주는 함수
- strip() : 문자열 좌.우의 공백을 없애주는 함수
txt = ' 양쪽에 공백이 있는 문자열입니다. '
ret1 = txt.lstrip()
ret2 = txt.rstrip()
ret3 = txt.strip()
print('<' + txt + '>')
print('<' + ret1 + '>')
print('<' + ret2 + '>')
print('<' + ret3 + '>')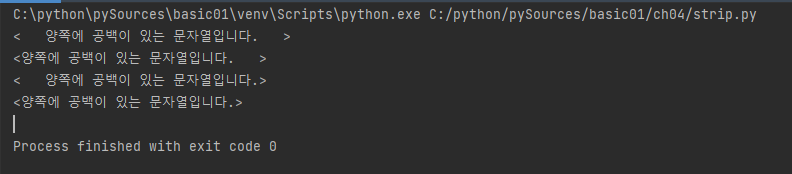
리스트 조작 L
📋 list01.py
L = [1,2,3,4]
print (type(L))
print("len(L)->", len(L))
print("L[1] ->", L[1])
print("L[-1] ->", L[-1]) # 맨뒤
print("L[1:3] ->", L[1:3]) # 인덱스 1,2 까지
print("L + L ->", L + L)
print("L * 3 ->", L * 3)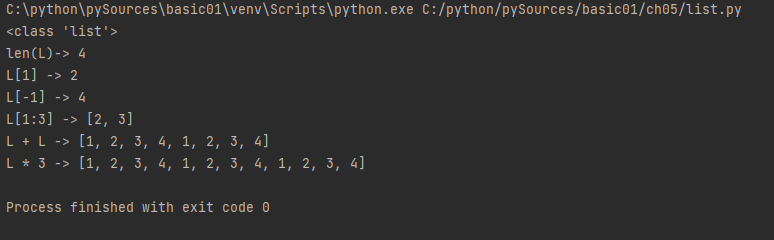
리스트안에 리스트
📋 list02.py
kk=[1,2,3,['a','b','c']]
print("kk ->", kk)
print("kk [-1][1] ->", kk[-1][1])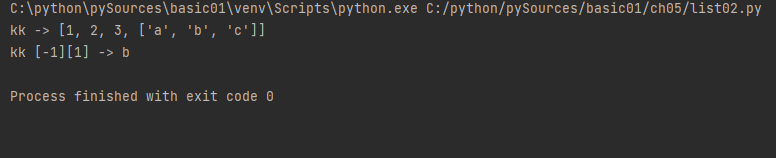
리스트안에 리스트
📋 list03.py
# range : List나 Tuple를 사용, 저장하지 않더라도 특정범위의
# 숫자 시퀀스 생성
# range(start,stop,step) step 안주면 기본 1
L = range(10)
print(L)
print("L[::2] ->", L[::2]) # start : end : jump
A = L[::2]
for aa in A :
print('A -> ', aa)
B = L[3::3]
for bb in B :
print('B -> ', bb)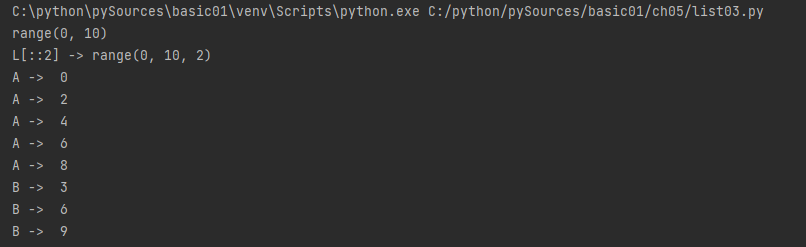
tuple 특징_ Read Only
📋 tuple01.py
# Tuple은 List의 Read Only 값을 정해주면 재할당 불가.
t = (1,2,3,4,5)
print("len(t) ->", len(t))
print("t[[0] ->", t[0])
print(t[-1])
print("t[0:2] ->", t[0:2])
print("t[::2] ->", t[::2])
print("t * t + t ->", t + t + t)
print(t * 3)
#t[1] = 7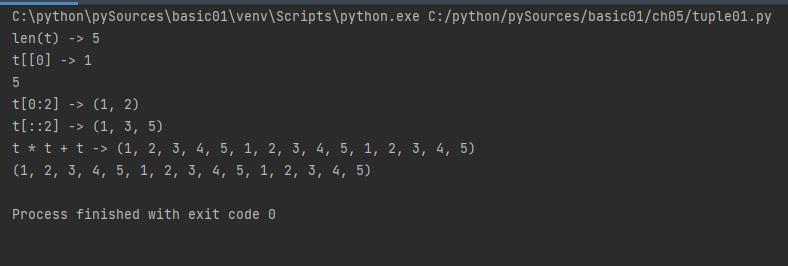
tuple 특징_ Read Only
📋 tuple02.py
# tuple은 정의할때 괄호 붙이지 않아도 됨
colors = 'red', 'green', 'blue', 'yellow', 'orange'
print('colors ->', colors)
print('colors len ->', len(colors))
# unpacking 하나씩 뽑는것
a, b, c, d, e = colors
print('a ->', a)
print('c ->', c)
# 마지막 item 가져오기
the_last = colors[-1]
print('the_last ->', the_last)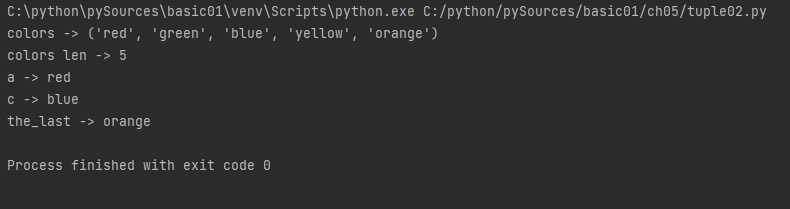
key value 로 값변경
📋 dictionary.py
d = {'one': 'hana', 'two': 'dul', 'three': 'set'}
d['four'] = 'net' # 새 항목 삽입
print("d1 ->", d)
d['one'] = 1 # 기존항목 값 변경
print("d2 ->", d)
print('one' in d) # 키에 대한 멤버쉽 테스트
key value 로 값변경
📋 dictionary02.py
d3 = {'one': 1, 'two': '둘', 'three': '삼', 'four': '사'}
print("d3.keys() ->", d3.keys()) # 키만 리스트로 추출, 임의의 순서
print("type(d3.keys()) ->", type(d3.keys())) # 키만 리스트로 추출, 임의의 순서
print("type(d3.values()) ->", type(d3.values())) # 값만 리스트로 추출, 임의의 순서
print("d3.values() ->", d3.values()) # 값만 리스트로 추출, 임의의 순서
print("d3.items() ->", d3.items()) # 키와 값의 듀플을 리스트로 반환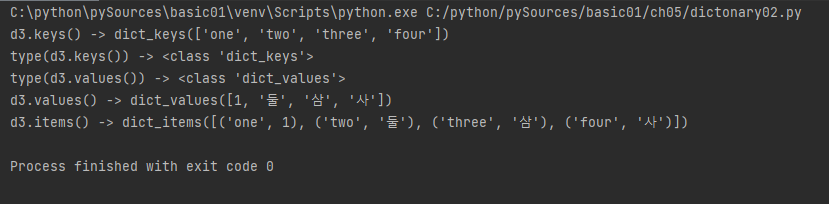
시퀀스 자료형
- 저장된 각 요소를 정수 Index를 이용하여 참조가 가능한 자료형
- 시퀀스(Sequence) 자료형 유형 : 문자열, 리스트, 튜플
- 문자열: 시퀀스 자료형의 대표적인 자료형
- 시퀀스 자료형이 가지고 있는 공통적인 연산 존재
슬라이싱 (Slicing) s[1:3] s[-30:100]
📋 seq01.py
# 시퀀스 자료형의 지원 연산 슬라이싱
print ("---------------------------")
# 0123456
s = 'abcdef'
print("s[1:3]", s[1:3])
print("s[1:]", s[1:])
print("s[:]", s[:])
print("s[-100:100]", s[-100:100]) # -100 -> 처음값, 100 -> 마지막값
print("s[-30:100]", s[-30:100])
print("s[-2:100]", s[-2:100])
print("s[-1:100]", s[-1:100])
# 시퀀스 자료형의 지원 연산 확장 슬라이싱
# L[start:end:step]: 인덱싱되어지는 각 원소들 사이의 거리가 인덱스 기준으로 step 만큼 떨어짐
print ("---------------------------")
print("s[::2]", s[::2]) # step 2씩
print("s[::1]", s[::1]) # step 1씩
print("s[1::2]", s[1::2]) # step 2씩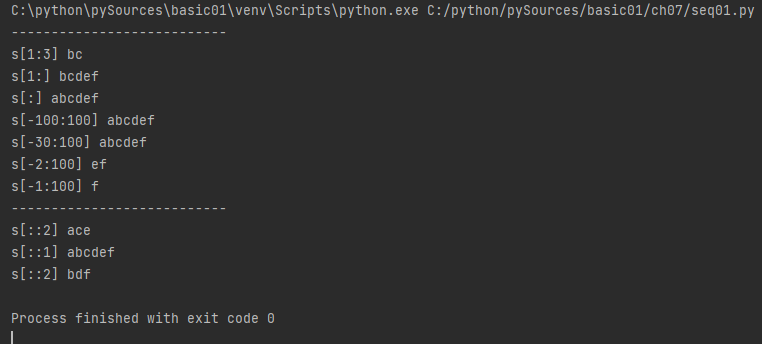
📋 seq02.py
# 시퀀스 자료형의 지원 연산 -> 멤버십 테스트
print ("---------------------------")
s = 'abcde'
print("'c' in s ", 'c'in s )
t = (1, 2, 3, 4, 5)
print("2 in t ", 2 in t)
print("10 in t ", 10 in t)
print("10 not in t ", 10 not in t)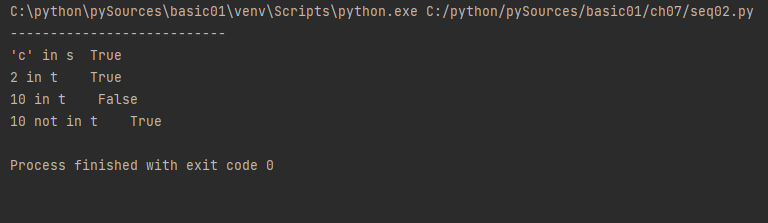
중간에 문자 삽입
📋 seq03.py
print ("-----문자열 정의 및 기초 연산 -> 문자열 연산------")
print ("-----문자열 변경을 위해서는 여러 Slicing 연결 활용 ------")
print ("-----[주의] 문자열 자체가 변경되는 것이 아니라 새로운 문자열을 생성하여 재 할당하는 것임 ------")
print ("-----[주의] 연결되어 새로운 문자열이 된 것이지 수정된 것이 아님 ------")
print ()
# 01234
s = 'spam and egg'
s = s[:4] + ', cheese, ' + s[5:]
print("s[:4] + ', cheese, ' + s[5:]", s)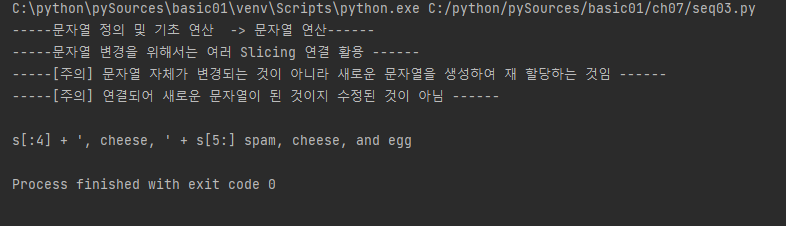
대문자 소문자 변환
.title .capitalize
📋 strMethod01.py
print ("---------------------------")
print ("------ 문자열 메소드 ------")
s = 'i like programming.'
print("s.upper()", s.upper())
print("s.upper().lower()", s.upper().lower())
print("'I like Programming'.swapcase()", 'I like Programming'.swapcase()) # 대문자느 소문자로, 소문자는 대문자로
print("s.capitalize()", s.capitalize()) # 처 문자를 대문자로 변환
print("s.title()", s.title()) # 각 단어의 첫문자를 대문자로 변환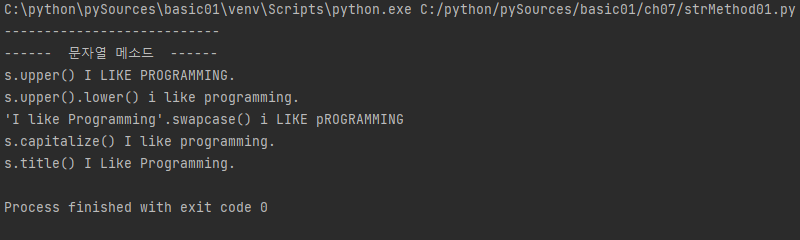

공부중인 주니어 개발자