reverse _ 리스트의 요소 순서를 역순
📋 reverse.py
- 리스트의 요소 순서를 역순으로 만들기 ( reverse() 함수 )
- reverse() 함수는 리스트의 모든 요소 순서를 거꾸로 만들어 주는 함수
- reverse() 함수는 원본 리스트 자체가 변경됨
listdata = list(range(5)) # [0, 1, 2, 3, 4]
print(listdata)
listdata.reverse()
print(listdata) # [4, 3, 2, 1, 0]
shuffle _ 무작위로 섞기
📋 shuffle.py
리스트의 요소 무작위로 섞기 ( shuffle() 함수 )
random 모듈의 shuffle() 함수는 리스트 요소를 무작위로 섞어주는 함수
실행 결과는 매번 달라짐
frin 모듈명 import 함수명
# 리스트의 요소 무작위로 섞기 ( shuffle() 함수 )
# random 모듈의 shuffle() 함수는 리스트 요소를 무작위로 섞어주는 함수
# 실행 결과는 매번 달라짐
# frin 모듈명 import 함수명
from random import shuffle
listdata = list(range(1, 11)) # 1~10
for i in range(3): # i는 0 ~ 2까지 3번 loop 가 돌아감
shuffle(listdata) # shuffle() 함수는 무작위로 섞어줌
print(listdata) # 출력 괄과는 실행할 때마다 달라짐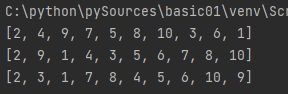
slice _ 특정 구간에 있는 요소 추출
📋 slice.py
리스트에서 특정 구간에 있는 요소 추출하기
- [1 : 4] index번호 1번 부터 3번까지 추출
- [4 : ] index번호 4번 부터 끝까지 추출
solarsys = ['태양', '수성', '금성', '지구', '화성', '목성', '토성', '천왕성', '해왕성']
rock_planets = solarsys[1:4]
gas_planets = solarsys[4:]
print('태양계의 암석형 행성: ')
print(rock_planets)
print('태양계의 가스형 행성: ');print((gas_planets))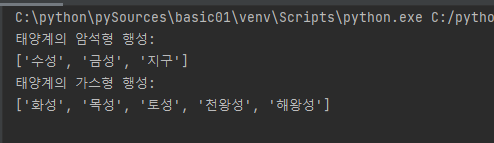
:: _ 홀수.짝수번째 요소만 추출
📋 slice2.py
리스트에서 홀수.짝수번째 요소만 추출하기
listdata = list(range(1, 21))
print(listdata)
evenList = listdata[1::2]
print(evenList)
oddList = listdata[::2]
print(oddList)
sort _ 리스트 요소 정렬
📋 sort.py
- 리스트 요소 정렬하기 ( sort() 함수 )
- sort() 함수는 리스트에 있는 요소를 오름차순으로 정렬해주는 역할을 함
- 내림차순 정렬을 하기 위해서는 sort(reverse = True)
namelist = ['Mary', 'Sams', 'Aimy', 'Tom', 'Michale', 'Bob', 'Kelly']
namelist.sort() # 리스트에 있는 요소를 오름차순으로 정렬함
print(namelist)
namelist.sort(reverse= True) # 리스트에 있는 요소를 내림차순으로 정렬
print(namelist)
sorted _ 홀수.짝수번째 요소만 추출
📋 sorted.py
- 리스트 요소 정렬하기 ( sorted() 함수 )
- 파이썬 내장함수 sorted() 함수는 리스트의 모든 요소를 정렬한 결과 리스트를 리턴함
namelist = ['Mary', 'Sams', 'Aimy', 'Tom', 'Michale', 'Bob', 'Kelly']
ret1 = sorted(namelist) # 오름차순
ret2 = sorted(namelist, reverse=True) # 내림차순
print(ret1)
print(ret2)
sum _ 리스트의 모든 요소의 합 구하기
📋 sum.py
- 리스트의 모든 요소의 합 구하기 ( sum() 함수 )
- sum() 함수는 리스트의 모든 요소의 합을 구하고 리턴함
listdata = [2, 2, 1, 3, 8, 5, 7, 6, 3, 6, 2, 3, 9, 4, 4]
ret = sum(listdata)
print(ret)
sum _ 리스트의 모든 요소의 합 구하기
📋 listln.py
리스트 내포
- 일반적인 리스트 생성법
L = []
for k in range (10):
L.append(k*k)
print(L)
위 코딩은 리스트 내포 리터럴 방식을 활용해서 아래와 같이 변경
- for 의 변수가 식으로 들어간 변수와 동일해야함
- 0, 1, 2, 3…이 k에 할당될 때마다 식을 진행하여 리스트의 원소로 할당
L = [k * k for k in range(10)]
print('리스트 내포 리터럴 방식 ->', L
sum _ 리스트의 모든 요소의 합 구하기
📋 listln.py
리스트 내포 리터럴 방식
print ("--- k=0 → 0 % 2 = 0 → if 0 → 결과가 false로 expression 수행 X --")
print ("--- k=1 → 1%2 = 1 → if 결과가 true로 expression 수행 --")
print ("--- k=2 → 2 % 2 = 0 → if 0 → 결과가 false로 expression 수행 X --")
print ("--- k=3 → 3%2 = 1 → if 결과가 true로 expression 수행 --")
L = [k * k for k in range(10) if k % 2] # 홀수의 제곱만 리스트로 형성
print(L)
sum _ 리스트의 모든 요소의 합 구하기
📋 listln03.py
print ("------------------------------------------------------------------------------")
print ("--- 리스트 내포 --")
print ("--- 20보다 작은 2의 배수와 3의 배수에 대해 그 두 수의 합이 7의 배수인 것들에 대해 --")
print ("--- 그 두 수의 곱을 출력하는 코드 --")
print ("--- 1) range(2, 20, 2) = [2, 4, 6, 8, 10, 12, 14, 16, 18] --")
print ("--- 2) range(3, 20, 3) = [3, 6, 9, 12, 15, 18] --")
print ("--- 3) i ← 20보다 작은 2의 배수, j ← 20보다 작은 3의 배수 --")
print ("--- 4) 2 + 12 = 14 ← 7의 배수 --")
print ("--- 5) 4 + 3 = 7 ← 7의 배수 --")
print ("--- 6) 18 + 3 = 21 ← 7의 배수 --")
print ("-------------------------------------------------------------------------------")
L = [(i, j, i * j) for i in range(2, 20, 2) for j in range(3, 20, 3) if (i + j) % 7 == 0]
print(L)
listln _ 리스트 내포
📋 listln04.py
리스트 내포 * 문장을 공백상태로 잘라오면서 대문자,소문자,길이를 리스트에 저장하는 코드.
split ()→ 공백을 기준으로 문자열 잘라 리스트 만들기 stuff는 리스트 내포 문법 형태 리스트 내포 안의 원소는 3개의 원소를 가진 리스트 형태로 하나 upper : 대문자로 변환, lower: 소문자로 변환, len: 단어의 길이
- i 자체가 리스트
print ("--------------------------------------------------------------------------------")
print ("--- 리스트 내포 --")
print ("--- 문장을 공백상태로 잘라오면서 대문자,소문자,길이를 --")
print ("--- 리스트에 저장하는 코드 --")
print ("--- split ()→ 공백을 기준으로 문자열 잘라 리스트 만들기 --")
print ("--- stuff는 리스트 내포 문법 형태 --")
print ("--- 리스트 내포 안의 원소는 3개의 원소를 가진 리스트 형태로 하나 --")
print ("--- upper : 대문자로 변환, lower: 소문자로 변환, len: 단어의 길이 --")
print ("--- i 자체가 리스트 --")
print ("------------------------------------------------------------------------------")
words = 'The quick brown fox jumps over the lazy dog'.split()
stuff = [[w.upper(), w.lower(), len(w)] for w in words]
for i in stuff:
print(i)
listln _ 리스트 내포
📋 tuple01.py
print ("-------------------------------------------------------------------------")
print ("--- << 튜플 연산 >> --")
print ("--- 1) t = (정수, 정수, 문자열) --")
print ("--- 2) u = t, (1, 2, 3, 4, 5) → 2개의 원소를 가진 튜플 → 원소로 튜플 가능 --")
print ("--- 3) u2 = t2, (1, 2, 3) → 원소로 리스트 가능 --")
print ("--- 4) 원소로 사전도 가능 --")
print ("--------------------------------------------------------------------------")
t = (12345, 54321, 'hello!')
u = [1, 2, 3, 4, 5]
print("t, (1, 2, 3, 4, 5) --> ", u)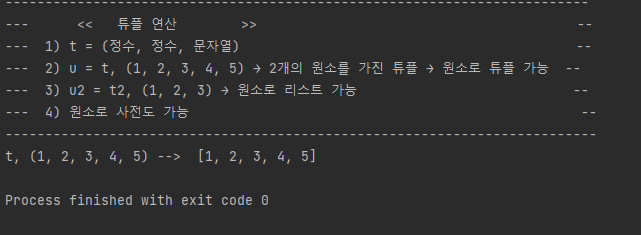
tuple 속성 readOnly
listln _ 리스트 내포
📋 tuple02.py
# 튜플 내부 원소로 리스트 가질 수 있음
# 튜플 내부 원소로 사전 가질 수 있음
t2 = [1, 2, 3]
u2 = t2, (1, 2, 4),
print("t2, (1, 2, 4) -->", u2)
t3 = {1:"abc", 2:"def"}
u3 = t3, (1,2,3),
print("t3, (1,2,3) --> ", u3)\
listln _ 리스트 내포
📋 tuple03.py
# list()와 tuple()내장 함수를 사용하여 리스트와 튜플을 상호 변환할 수 있음
T = (1,2,3,4,5)
print('T ->', T)
# T[0] = 100 --> Tuple은 변환 안함
L = list(T)
L[0] = 100
print('L ->', L)
listln _ 리스트 내포
📋 dict01.py
#딕셔너리(dictionary)
# 문제 각 Row(행)을 리스트외 Dictionary를 사용 작성
# 이중 Dictionary key : value{key : value}
address3 = {
'1': { 'name': '이순신', 'email':'hong@gmail.com', 'hp-num': '010-2234-9678'},
'2': {'name': '대조영', 'email': 'dae@gmail.com', 'hp-num': '010-1234-5679'},
'3': { 'name': '강감찬', 'email': 'kang@gmail.com', 'hp-num': '010-6783-3670'},
'4': {'name': '김유신', 'email': 'kim@gmail.com', 'hp-num': '010-7823-3578'},
}
print("address3 -> ", address3)
for key in address3:
addr_dict = address3[key]
print("addr_dict -> ", addr_dict)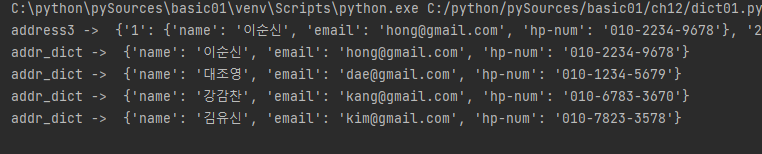
del _ 특정 요소 제거
📋 dict01.py
- 사전의 특정 요소 제거하기 ( del 키워드 )
names = {'Mary':10999, 'Sams':2111, 'Aimy':9778, 'Tom':20245,
'Michale':27115, 'Bob':5887, 'Kelly':7855}
del names['Sams']
print(names)
listln _ 리스트 내포
📋 dict_change.py
names = {'Mary':10999, 'Sams':2111, 'Aimy':9778, 'Tom':20245,
'Michale':27115, 'Bob':5887, 'Kelly':7855}
names['Aimy'] = 10000
print(names)
listln _ 리스트 내포
📋 dict_in.py
# 사전에 특정 key가 존재하는지 확인하기 ( in 키워드 )
# in 키워드를 이용하여 특정 값이 사전의 key로 존재하는지 확인할 수 있다.
names = {'Mary':10999, 'Sams':2111, 'Aimy':9778, 'Tom':20245,
'Michale':27115, 'Bob':5887, 'Kelly':7855}
k = input('이름을 입력하세요: ')
if k in names :
print('이름이 <%s> 인 출생아수는 <%d> 명 입니다.' %(k, names[k],))
else:
print('자료에 <%s> 인 이름이 존재하지 않습니다.' %k)
items() _ key:value 를 모두 추출하여 리턴
📋 dict_items.py
- 사전 요소를 모두 추출하기 ( items() 함수 )
- items() 함수는 사전에서 key:value 를 모두 추출하여 리턴
# 사전 요소를 모두 추출하기 ( items() 함수 )
# items() 함수는 사전에서 key:value 를 모두 추출하여 리턴
names = {'Mary':10999, 'Sams':2111, 'Aimy':9778, 'Tom':20245,
'Michale':27115, 'Bob':5887, 'Kelly':7855}
items = names.items()
print(items)
for item in items:
print(item)
items() _ key:value 를 모두 추출하여 리턴
📋 dict_keys.py
- 사전 요소를 모두 추출하기 ( items() 함수 )
- items() 함수는 사전에서 key:value 를 모두 추출하여 리턴
names = {'Mary':10999, 'Sams':2111, 'Aimy':9778, 'Tom':20245,
'Michale':27115, 'Bob':5887, 'Kelly':7855}
ks = names.keys()
print(ks)
for k in ks:
print('key:%s \tValue:%d' %(k, names[k]))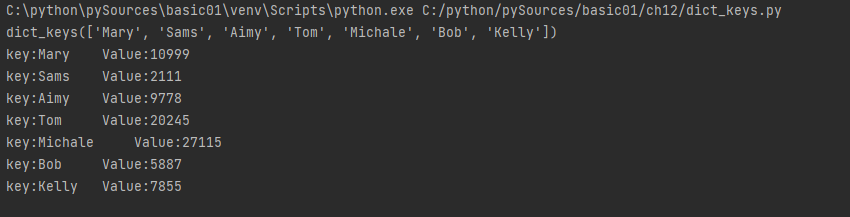
items() _ key:value 를 모두 추출하여 리턴
📋 write.py
- 파일 생성(파일 쓰기)
- test.txt 파일 생성함
file = open('test.txt', 'w') # 쓰기 모드로 열기
file.write('hello') # test.txt 파일에 'hello' 쓰기
file.close() # 파일 닫기
file.read() _ 파일 읽기
📋 read.py
- 파일 읽기
- test.txt 파일을 읽기 모드로 열고, 내용을 출력
file =open('test.txt', 'r') # 읽기 모드로'test.txt' 열기
str = file.read() # 'test.txt' 파일의 모든 내용을 읽어와서 str 변수에 저장
print(str)
write() _ 입력한 내용을 파일로 저장
📋 write_encoding.py
- 사용자가 입력한 내용을 파일로 저장 - write() 함수
text = input('파일에 저장할 내용을 입력하세요?')
f = open('data.txt', 'w')
f.write(text)
f.close()

그냥 쓰면 깨진다.
encoding='utf-8'를 넣으면 한글 안깨진다.
text = input('파일에 저장할 내용을 입력하세요?')
# f = open('data.txt', 'w')
f = open('data.txt', 'w', encoding='utf-8')
f.write(text)
f.close()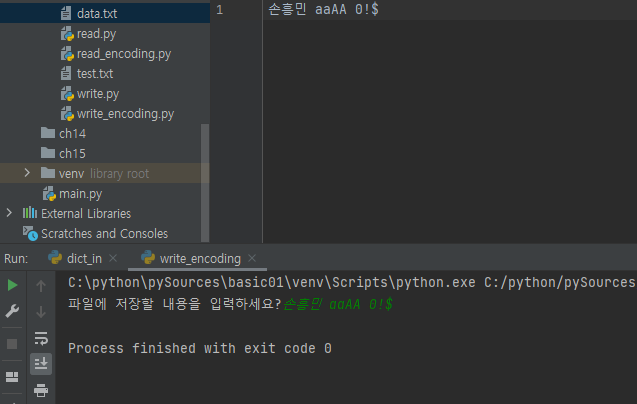
콘솔에서 READ
📋 read_encoding.py
#read
f = open('data.txt', 'r')
data = f.read()
print(data)
f.close()

공부중인 주니어 개발자