🥞 lambda _
📋 lambda03.py
- x=1 *args =2,3,4,5
- 람다(lambda) 함수 정의 -> 1. 람다 함수 정의 예
- 가변 인수를 지니는 람다 함수 정의
vargs = lambda x, *args: args+args # *args -> 가변인수
print("vargs(1,2,3,4,5) ->", vargs(1,2,3,4,5))
🥞 lambda _ 숫자2개 받아서 연산.(인덱스별로 다른 연산)
📋 lambda03.py
0,1,2,3,4 각각
+, -, *, *, /처리할 연산을 고르고
첫번째 숫자, 두번째 숫자를 받아 연산처리.
- 람다(lambda) 함수 정의 ->
- 람다 함수 사용하기
-
더하기, 빼기, 곱하기, 나누기에 해당하는 람다 함수 리스트 정의
인덱스 0은 첫 번째 인자 / 인덱스 2는 세 번째 인자로 곱셈 수행 / 리스트의 원소에 람다함수가 들어가고, 검색도 가능 -
while 1:이면 1은 true다.while true:라고 써도된다. -
return input('Select menu:')는lambda x, y : x + y,각각 인덱스를 고르는것. -
input('First operand:')는 첫번째 수. int x 가 된다.
# 리스트의 원소가 람다 함수로 들어감
# 0, 1, 2, 3
func = [lambda x, y : x + y, lambda x, y : x-y, lambda x, y : x * y , lambda x, y : x/y]
def menu():
print("0. add")
print("1. sub")
print("2. mul")
print("3. dib")
print("4. quit")
return input('Select menu:')
while 1: # 1 = true
sel = int(menu())
print("sel->", sel)
print("len(func->", len(func))
if sel < 0 or sel > len(func): # 0보다 작은값이나 4보다 큰 값
continue
if sel == len(func):
break # 조건 충족시 무한루프 빠져나옴
x = int(input('First operand:'))
y = int(input('Second operand:'))
print('Result = ', func[sel](x,y))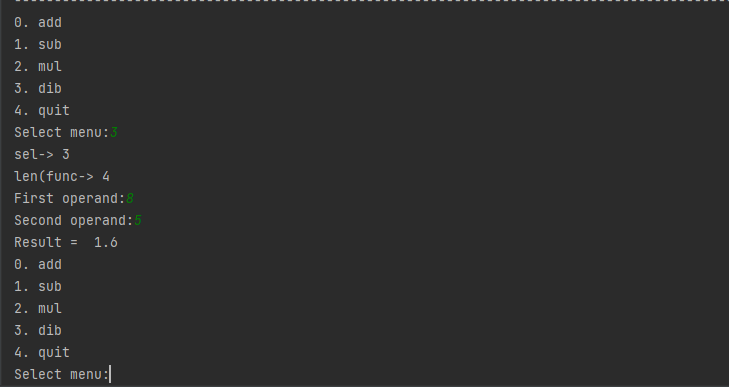
Python 정규표현식(Regular Expression)
⭐
- 대문자는 부정
- 정규식은 제대로 알아둬야한다. 자바에서도 많이 쓴다.(😬 나는 아직 잘 못써서 공부해야겠다.)
1 Regular Expression
- Text를 검색할때 Ctrl+F로 찾는것을 조금 더 발전시킨 형태
- 글자 자체가 아니라 Pattern을 사용
- 정규식 사용 사례
- 입력유효성 Check (e-Mail주소 맞는지)
- Text에서 특정부분 추출(우편번호등..)
- 특정 Text 바꾸기 (사람->남자 또는 여자)
- Text 쪼개기
2. 자주 사용하는 문자 클래스
[0-9] 또는 [a-zA-Z] 등은 무척 자주 사용하는 정규 표현식.
이렇게 자주 사용하는 정규식은 별도의 표기법으로 표현.
\d - 숫자와 매치, [0-9]와 동일한 표현식이다.
\D - 숫자가 아닌 것과 매치, [^0-9]와 동일한 표현식이다.
\s - whitespace 문자와 매치, [ \t\n\r\f\v]와 동일한 표현식이다. 맨 앞의 빈 칸은 공백문자(space)를 의미.
\S - whitespace 문자가 아닌 것과 매치, [^ \t\n\r\f\v]와 동일한 표현식.
. - \n을 제외한 모든 문자 표현식.
\w - 문자+숫자(alphanumeric)와 매치, [a-zA-Z0-9_]와 동일한 표현식.
\W - 문자+숫자(alphanumeric)가 아닌 문자와 매치, [^a-zA-Z0-9_]와 동일한 표현식.
대문자로 사용된 것은 소문자의 반대임을 추측
- Dot(.)
정규 표현식의 Dot(.) 메타 문자는 줄바꿈 문자인 \n을 제외한 모든 문자와 매치됨을 의미
예시) a.b
"a + 모든문자 + b” 즉 a와 b라는 문자 사이에 어떤 문자가 들어가도 모두 매치된다는 의미 - 반복 ()
예시) cat
이 정규식에는 반복을 의미하는 메타 문자가 사용.
여기에서 사용한 은 * 바로 앞에 있는 문자 a가 0부터 무한대로 반복될 수 있다는 의미 (caat, caaaat)
-
반복 (+) Regular Expression
-반복을 나타내는 또 다른 메타 문자로 +가 있다. +는 최소 1번 이상 반복될 때 사용한다.
-즉 *가 반복 횟수 0부터라면 +는 반복 횟수 1부터 사용
-예시) ca+t : "c + a(1번 이상 반복) + t“ -
반복 ({m,n}, ?)
여기에서 잠깐 생각해 볼 게 있다. 반복 횟수를 3회만 또는 1회부터 3회까지만으로 제한할때 사용
{ } 메타 문자를 사용하면 반복 횟수를 고정할 수 있다. {m, n} 정규식을 사용하면 반복 횟수가 m부터 n까지 매치할 수 있다. 또한 m
또는 n을 생략할 수도 있다. 만약 {3,}처럼 사용하면 반복 횟수가 3 이상인 경우이고 {,3}처럼 사용하면 반복 횟수가 3 이하를 의미
예시1) ca{2}t "c + a(반드시 2번 반복) + t"
-예시2) ca{2,5}t "c + a(2~5회 반복) + t" -
?
-반복은 아니지만 이와 비슷한 개념으로 ? 이 있다. ? 메타문자가 의미하는 것은 {0, 1} 이다.
-예시) ab?c "a + b(있어도 되고 없어도 된다) + c“ -
https://regex101.com
Regular Expression 입력 \b(https?:\/\/)?([\w.]+){1,2}(.[\w]{2,4}){1,2}\b
test String 입력
http://naver.com
https://www.naver.com
http://shop.site.co.kr
http://www.daum.net
1) /문자 표현시 Escape를 사용(\/)
2) \b : 바운더리 표현 , word boundary를 표현하며 문자와 공백사이의 문자를 의미
예시) 주로, \b를 단어 시작과 마지막에 붙여 정규 표현식에서 찾고자 하는 단어와 완전히 일치시킬 목적으로 사용.
[정규 표현식] \bcat\b
[적용문장] The cat scattered his food all over the room.
[결과] 우리가 찾으려 했던 것은 정확히 "cat"과 일치하는 단어.
scattered의 cat 앞뒤로는 각각 's'와 't'이므로 공백이 아니어서 일치 대상에서 제외
3) () : 괄호 사용 Group을 적절히 활용
4) .(dot) 문자 : 와일드카드 , \n 문자 제외하고 모든 문자 대응
실제로 .를 표시하고 싶으면 .으로 사용
5) ^ : 시작 표시
6) $ : 끝을 표시
7) https? -> http 나 https 둘다 가능
8) (https?:\/\/)? --> http 나 https:// 전체가 있을수도 없을수도 있음
9) [\w.]+ --> 문자+숫자(alphanumeric)와 매치 , +는 여러번 발생
10) {1,2} 위 9)번이 한번 또는 두번 반복
⭐⭐⭐ 정규표현식 검증 사이트 ⭐⭐⭐
Python에서 정규표현식 컴파일 옵션
- match 객체의 메서드
1) DOTALL(S) - . 이 줄바꿈 문자를 포함하여 모든 문자와 매치할 수 있도록 한다.
2) IGNORECASE(I) - 대소문자에 관계없이 매치할 수 있도록 한다.
3) MULTILINE(M) - 여러줄과 매치할 수 있도록 한다. (^, $ 메타문자의 사용과 관계가 있는 옵션이다)
4) VERBOSE(X) - verbose 모드를 사용할 수 있도록 한다. (정규식을 보기 편하게 만들수 있고 주석등을 사용할 수 있게된다.)
- 옵션을 사용할 때는 re.DOTALL처럼 전체 옵션 이름을 써도 되고 re.S처럼 약어를 써도 된다.
- match 객체의 메서드 IGNORECASE, I
re.IGNORECASE 또는 re.I 옵션은 대소문자 구별 없이 매치를 수행할 때 사용하는 옵션


- match 객체의 메서드 MULTILINE, M
re.MULTILINE 또는 re.M 옵션은 조금 후에 설명할 메타 문자인 ^, 와 연관된 옵션 이 메타 문자에 대해 간단히 설명하자면 ^는 문자열의 처음을 의미하고, $는 문자열의 마지막을 의미 예를 들어 정규식이 ^python인 경우 문자열의 처음은 항상 python으로 시작해야 매치되고, 만약 정규식이 python이라면
문자열의 마지막은 항상 python으로 끝나야 매치된다는 의미

- match 객체의 메서드 VERBOSE, X

🥞 정규식_ 폰번호 추출. 하나씩, 그룹으로
📋 regex01.py
정규식 쓸땐
import re
원하는 데이터를 추출하고 싶을때findall
import re
# 1. 정규식에 search 사용 -> 매칭되는 첫번째 pattern 반환
# compile-> pattern 을 미리 만들어 둠 , 전화번호에 해당하는 pattern
# \d는 숫자
phonenum_regex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
mo = phonenum_regex.search("My Number is 010-234-1234")
print("mo.group()->", mo.group())
print("---2. 괄호를 사용 , 정규식에 Group를 생성 , (\d\d\d) -> Group함수 사용--" )
# 2. 괄호를 사용 , 정규식에 Group를 생성 , (\d\d\d) -> Group함수 사용
phonenum_regex = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)')
mo = phonenum_regex.search("My Number is 010-567-1234")
print("mo.group(1)->", mo.group(1))
print("mo.group(2)->", mo.group(2))
print("mo.group(3)->", mo.group(3))
# tuple로 전달
print("mo.group()->", mo.group())
print("------------------------------")
# 3. findall -> 매칭되는 모든 pattern을 List로 반환
phonenum_regex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
mo = phonenum_regex.findall("cell: 315-235-5679 Work : 213-234-3456")
print("3. mo->", mo)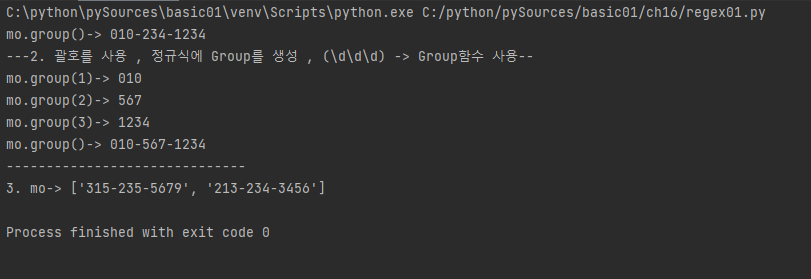
정규식 검증사이트 에 들어가서 테스트 해보기.
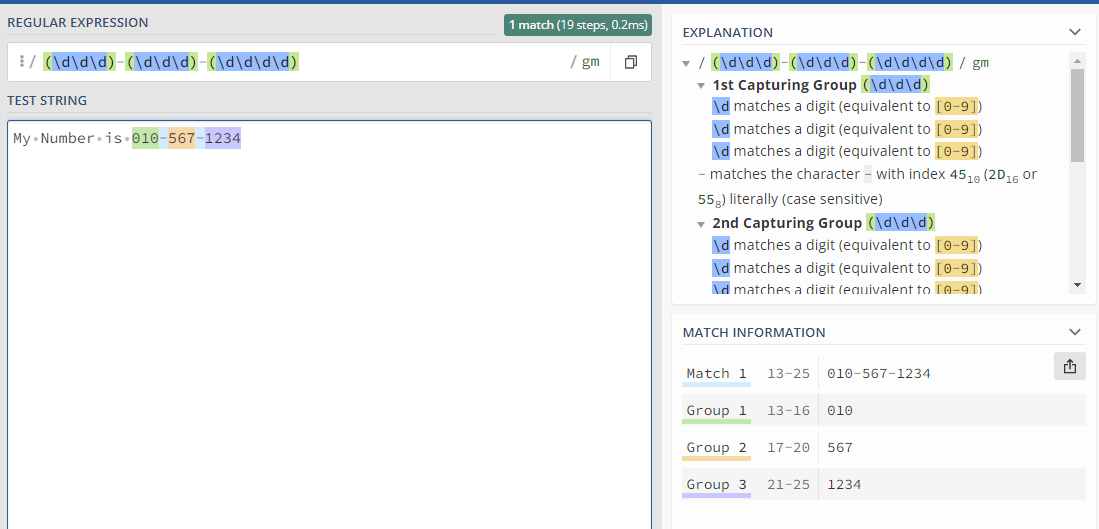
010 567 1234 이 그룹
🥞 password 유효성 검사 _ isalpha, isnumeric
📋 passwd_val.py
알파벳 + 숫자가 8보다 커야 true
# 조건 8자이상 , 영문자와 숫자가 혼합
# password='' 가 문자열림을 컴파일러에 알려줌
def validate_password(password=''):
if(len(password)) < 8:
return False
elif password.isalpha():
return False
elif password.isnumeric():
return False
else:
return True
def main():
user_password = input('input Your Password: ')
if validate_password(user_password):
print('유효한 password 입니다')
else:
print('유효하지 않은 password 입니다')
main()
import pyperclip 설치 : 외장 모듈을 import할때 아래처럼 한다.
🥞 pyperclip _버퍼에 저장
🚩 패스워드를 버퍼에 저장하는 프로그램 만들기
📋 password_locker.py
gmail':'FGHkshdkfkgkg'각각key : value.
gmail을 입력하면 패스워드를 버퍼에 카피.ctrl+V하면 바로 쓸 수 있다.
pyperclip버퍼에 저장.
import pyperclip
PASSWORDS = {
'gmail':'FGHkshdkfkgkg',
'naver':'ttakjt3456',
'daum':'qwef5678'
}
def main():
site = input('input yoru site:')
password = PASSWORDS[site]
if password:
pyperclip.copy(password)
print('Your password is Copied')
else:
print('Not Valid Site')
main()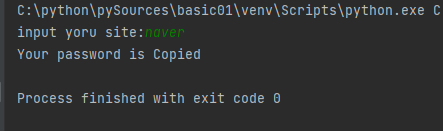
🥞 pyperclip _e-mail 추출기
📋 regex02.py
'''볼보셀 하면 멀티라인.[a-zA*Z0-9._%+-]
gm
Match a single character present in the list below [a-zA*Z0-9._%+-]
a-z matches a single character in the range between a (index 97) and z (index 122) (case sensitive)
A*Zmatches a single character in the list A*Z (case sensitive)
0-9matches a single character in the range between 0 (index 48) and 9 (index 57) (case sensitive)
._%+-matches a single character in the list ._%+- (case sensitive)
# e-mail 추출기
# 1.pyperclip 모듈을 사용 복사와 붙여넣기
# 2.regex만듦 , e-mail 주소 매칭
# 3. 모든 매치를 찾는다
# 4. 매칭된 String을 하나의 문자열로 만든다
# 5. 매칭된 문자열이 없으면 간단한 메세지 출력
import re
import pyperclip
# Create e-Mail regex --> VERBOSE, X
# ''' -> MultiLine
email_regex = re.compile(r'''(
[a-zA*Z0-9._%+-]+ # username
@ # @ sysbol
)''', re.VERBOSE)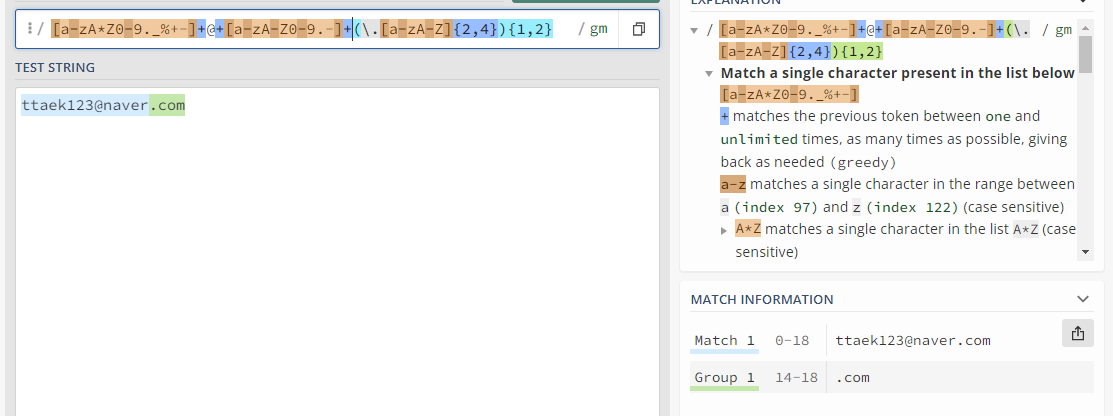
🥞 pyperclip _ e-mail 추출
📋 regex02.py
📌 설명은 월요일에!
- e-mail 추출기
- 1.pyperclip 모듈을 사용 복사와 붙여넣기
- 2.regex만듦 , e-mail 주소 매칭
- 모든 매치를 찾는다
- 매칭된 String을 하나의 문자열로 만든다
- 매칭된 문자열이 없으면 간단한 메세지 출력
import re
import pyperclip
# Create e-Mail regex --> VERBOSE, X
# ''' -> MultiLine
email_regex = re.compile(r'''(
[a-zA*Z0-9._%+-]+ # username
@ # @ sysbol
[a-zA-Z0-9.-] # domain name
(\.[a-zA-Z]{2,4}){1,2} # dot-something
)''', re.VERBOSE)
# ClipBoard에 복사된 내용에서 e-Mail Pattern과 매치되는 Text를 찾음
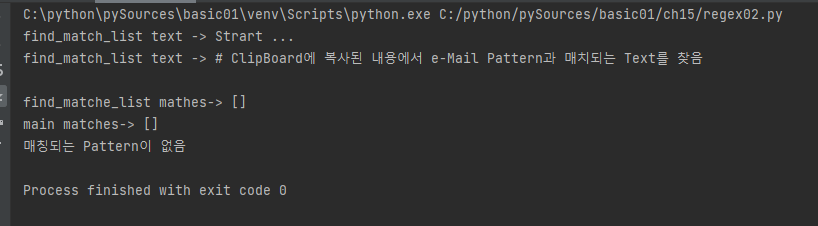
def find_match_list():
text = pyperclip.paste()
mathes = []
print("find_match_list text -> Strart ...")
print("find_match_list text ->", text)
for email in email_regex.findall(text):
mathes.append(email[0])
print("find_matche_list mathes->", mathes)
return mathes
def copy_result_to_clipboard(mathes):
if len(mathes) > 0:
pyperclip.copy('\n'.join(mathes))
print('ClipBoard에 복사 됨')
else:
print('매칭되는 Pattern이 없음')
def main():
matches = find_match_list()
print("main matches->", matches)
copy_result_to_clipboard(matches)
main()