⭐️
-
@XToOne(OneToOne, ManyToOne)을 사용할 경우 기본이 즉시로딩이므로(fetch = FetchType.LAZY)처리 해줘야한다.shift + option + command를 눌러@ManyToOne을 검색하여 FetchType을 LAZY로 넣어준다
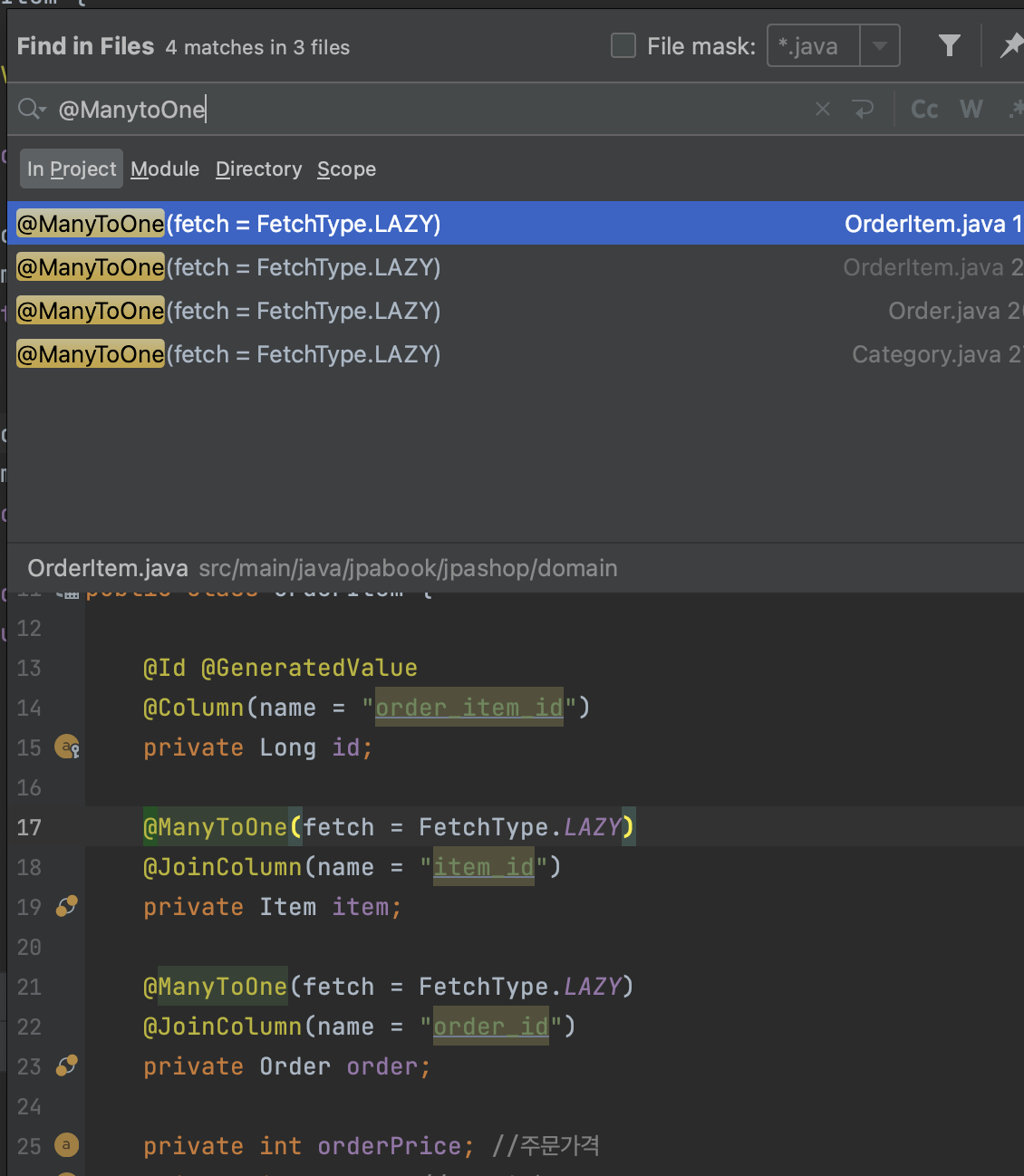
이때option + enter를 눌러static import를 눌러 아래처럼 만들 수 있다.

-
관계형 DB에서는 컬렉션 관계를 양쪽에 다 가질 수 있는것이 아니기 때문에 다대다 관계를 일대다, 다대일로 풀어 내기 위한 중간 테이블이 필요하다.
-
카테고리는 계층구조
-
카테고리에선 셀프로 양방향 연결관계를 걸었다.
- 이름만 같고 다른 entity를 걸었다 라고 생각하면된다.
@ManyToOne
@JoinColumn(name = "parent_id")
private Category parent;
@OneToMany(mappedBy = "parent")
private List<Category> child = new ArrayList<>();-
@OneToOne을 그냥 걸면 문제가 생긴다 -> 처리해줘야함. -
FK는 꼭 넣어야하나?
시스템마다 다르다. 실시간 트레픽, 서비스가 중요한 거면 인덱스로 잡아도 된다. 그러나 돈과 관련된것처럼 데이터가 딱딱 맞아야 하는 경우 FK사용이 중요하다. -
Getter는 다 열고 Setter는 최소한으로 써라
-
실무에서 ManytoMany는 절대 사용하지 말아라. (운영에 어려움)
실행하면 코솔창에 아래처럼 뜬다.
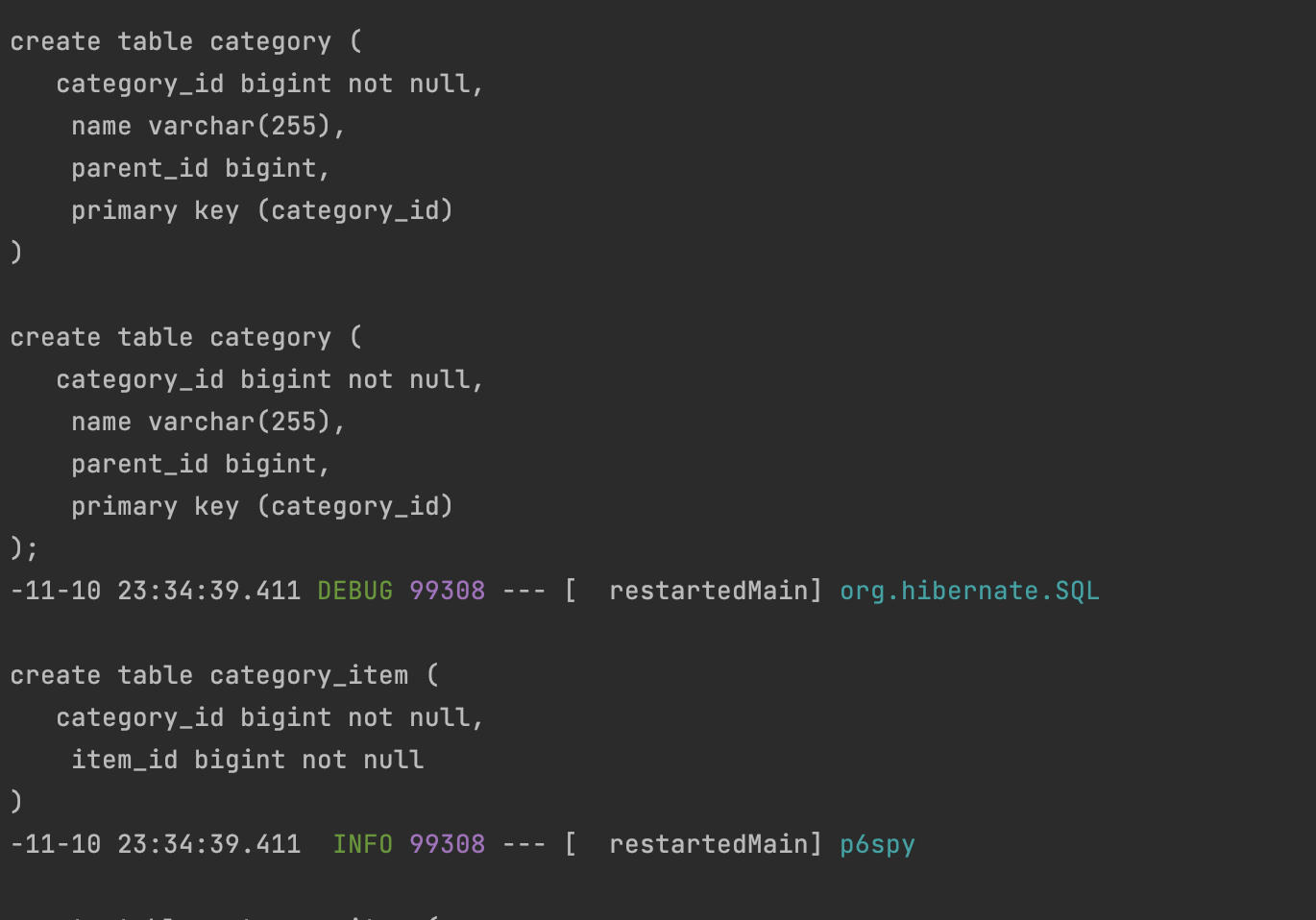
이때 이걸갖고 바로 사용하면 안되고 스크립트를 보고 정리하여 DDl에 사용해야한다.
🚨 엔티티 설계시 주의점
1. 엔티티에는 가급적 Setter를 사용하지 말기
- Setter가 모두 열려있으면 변경 포인트가 너무 많아서, 유지보수가 어렵다. -> 나중에 리펙토링으로 Setter 제거
2. 모든 연관관계는 지연 로딩으로 설정 ⭐️⭐️⭐️
-
즉시로딩( EAGER )은 예측이 어렵고, 어떤 SQL이 실행될지 추적하기 어렵다. (디폴드값이 EAGER)
특히 JPQL을 실행할 때 N+1 문제가 자주 발생한다. -
⭐️⭐️⭐️ 실무에서 모든 연관관계는 지연로딩( LAZY )으로 설정해야 한다.
-
연관된 엔티티를 함께 DB에서 조회해야 하면, fetch join 또는 엔티티 그래프 기능을 사용한다.
-
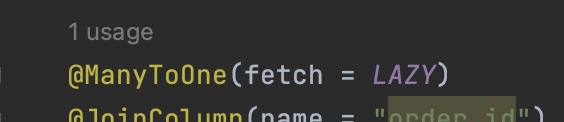
@XToOne(OneToOne, ManyToOne)관계는 기본이 즉시로딩이므로 직접 지연로딩으로 설정해야 한다. (*@OneToMany는 기본이 lazy)
N+1 문제
예를들면 :
EAGER일때 -> JPQL에서select o From order o;을 날리면 SQL로select * from order;이 된다.
이때 데이터가 100건이라 하면 100+1(order)의 단건 쿼리가 날라간다.
3. 컬렉션은 필드에서 초기화 하자.
-
컬렉션은 필드에서 바로 초기화 하는 것이 안전하다.
-
null문제에서 안전하다. -
하이버네이트는 엔티티를 영속화 할 때, 컬랙션을 감싸서 하이버네이트가 제공하는 내장 컬렉션으로 변경한다.
만약 getOrders() 처럼 임의의 메서드에서 컬력션을 잘못 생성하면 하이버네이트 내부 메커니즘에 문 제가 발생할 수 있다. 따라서 필드레벨에서 생성하는 것이 가장 안전하고, 코드도 간결하다
예시
Member member = new Member();
System.out.println(member.getOrders().getClass());
em.persist(team);
System.out.println(member.getOrders().getClass());
//출력 결과
class java.util.ArrayList
class org.hibernate.collection.internal.PersistentBag4. 테이블, 컬럼명 생성 전략
-
스프링 부트에서 하이버네이트 기본 매핑 전략을 변경해서 실제 테이블 필드명은 다르다.
-
하이버네이트 기존 구현: 엔티티의 필드명을 그대로 테이블의 컬럼명으로 사용 ( SpringPhysicalNamingStrategy )
-
스프링 부트 신규 설정 (엔티티(필드) 테이블(컬럼))
1. 카멜 케이스 언더스코어(memberPoint member_point)
2. .(점) _(언더스코어)
3. 대문자 -> 소문자

적용 2 단계
-
논리명 생성:
명시적으로 컬럼, 테이블명을 직접 적지 않으면 ImplicitNamingStrategy 사용
spring.jpa.hibernate.naming.implicit-strategy: 테이블이나, 컬럼명을 명시하지 않을 때 논리명 적용, -
물리명 적용:
spring.jpa.hibernate.naming.physical-strategy: 모든 논리명에 적용됨, 실제 테이블에 적용 (username usernm 등으로 회사 룰로 바꿀 수 있음)
Cascade
cascade = CascadeType.ALL를 넣어주면 insert delete 가 같이 된다.
@OneToOne(fetch = LAZY, cascade = CascadeType.ALL)
@JoinColumn(name = "delivery_id")
private Delivery delivery;연관관계 편입 메서드
- 양방향으로 연결시킬때 사용한다.
📋 order.java
public void setMember(Member member) {
this.member = member;
member.getOrders().add(this);
}
public void addOrderItem(OrderItem orderItem) {
orderItems.add(orderItem);
orderItem.setOrder(this);
}
public void setDelivery(Delivery delivery) {
this.delivery = delivery;
delivery.setOrder(this);
}