현대 데이터 처리 환경에는 데이터를 수집하고, 처리하는 다양한 방법이 존재한다.
다양한 방법 중 이번에 batch작업과 ETL 작업에 대해 알아보려 한다.
이들은 데이터 관리의 핵심적인 역할을 한다. 두가지 방식 모두 대량의 데이터를 효율적으로 처리하지만, 어떠한 점에서 다른부분이 있는지 알아보고자 한다.
Batch ( 배치 )
배치란 프로세싱 작업을 매 건 마다 하는 것이 아니라 일정 시간 또는 요청 건수 처럼 특정 조건에 맞을 때 까지 요청을 쌓아놨다가 한번에 처리하는 것을 말한다.
즉, 데이터 처리 주기를 일정조건에 따라 모았다가 한번에 처리하는 방식을 배치방법의 데이터 처리라고 한다. ( 주로 시간을 기준으로 처리하는 경우가 흔한 것 같다.)
ETL ( Extract, Transform, Load )
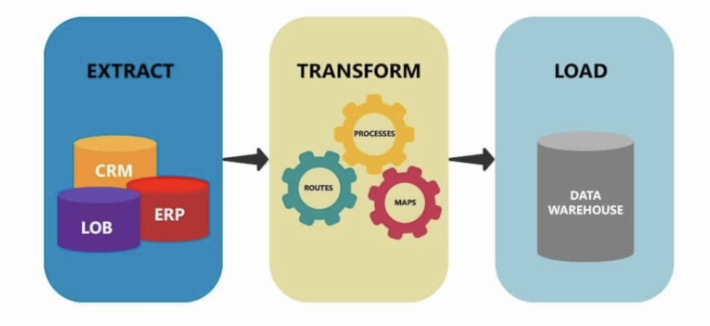
요즘은 ETL 라는 말을 많이 봐왔을 텐데 이는 Extract(추출), Transform(변환), Load(적재) 처럼 말 그대로 데이터를 추출하고, 목적에 따라 변환, 적재하는 작업을 의미한다.
간략하게 ETL 이 무엇을 의미하고, 어떤 작업을 하는지 알아보자.
Extract ( 추출 )
- 외부 데이터 소스로부터 원하는 데이터를 추출하는 단계를 말한다.
- 데이터를 추출하고 로드해야 하기 때문에 I/O 작업이 중점적으로 진행된다.
- 만약 네트워크 I/O 작업이 필요하다면 많은 네트워크 I/O 비용이 발생된다.
- 데이터를 추출하고 이 후 작업을 진행해야 하기 때문에 메모리를 주로 사용한다 따라서 많은 메모리 공간이 필요할 수 있다.
- 다음 단계인 Transform 을 빠르게 수행하기 위해 Transform 이 수행되어야 하는 컴퓨팅 리소스와 같은 위치의 디스크나 메모리에 데이터를 로드하는 것이 효과적이다.
Transform ( 변환 )
- 추출된 데이터를 원하는 용도에 맞게 데이터를 변환하는 작업을 말한다.
- 데이터를 변환해야 하는 작업이므로 여러 계산을 하기 때문에 CPU 작업을 위주로 진행된다.
- 또한 데이터를 여러 단계에 거쳐 변환하기 때문에 여유로운 메모리 공간이 필요하다.
Load ( 적재 )
- 목적에 맞게 추출된 데이터를 적절히 변환하여 최종적인 만든 데이터를 원하는 공간에 적재하는 과정을 말한다.
- 데이터를 읽고 써야하기 때문에 I/O 작업이 중점적으로 진행된다.
- E,T 작업을 진행한 공간과는 다른 공간에 저장해야 하는 경우가 많고 외부 저장소에 쓰기 위해 네트워크 중점적인 I/O 작업이 발생한다.
각 단어들이 의미하는바는 위와 같지만 간단하게 말해 ETL 이란 원본 데이터소스로 부터 필요에 따른 데이터를 추출하여 목적에 맞게 데이터를 변환하여 데이터를 저장 또는 전송하는 흐름을 말한다.
보통 ETL 은 여러 맥락에서 사용되는 용어인데 다음과 같은상황에서 ETL 이란 용어가 사용될 수 있다.
- 주기적으로 데이터를 변환하는 작업.
- 반복적/주기적으로 데이터를 처리하는 작업.
- ETL 프레임워크 또는 소프트웨어를 말하는 경우도 있다.
- 데이터 파이프라인
ETL 작업은 어떻게 하는거지 ?
ETL 작업을 위해 가장 많이 사용되는 프레임워크로는 Airbnb 에서 시작된 오픈소스 프로젝트로 Airflow이 가장 많이 사용된다.
가장 많이 사용되는 만큼 다양한 클라우드 서비스에서 해당 프레임워크를 지원하고 ( AWS,GCP ..)
ETL작업이 현대 데이터처리에서 핵심적인 역할을 하기때문에 ETL 과 관련된 SaaS ( Software as a Service) 형태로 서비스하는 경우도 많다 ( FiveTran, Stitch Data ..)
Batch랑 ETL 이 그래서 무슨 차이가 있는거야 ?
-
정의
Batch : 대량의 데이터를 한번에 처리하기에 적합한 방식으로, 실시간 데이터 처리를 하기엔 적합하지 않은 처리방식
ETL : ETL 과정을 포함한 데이터 처리방식이다. 다양한 데이터 소스로부터 데이터 추출 및 변환 적재를 목표로 하는 작업방식을 말한다. -
목적과 사례
Batch : 대량의 데이터를 정기적으로 처리하여 결과를 얻는 것이며, 예를 들어 일일 매출 보고서 생성, 로그 파일 분석 등이 있다.
ETL : 다양한 데이터 소스에서 데이터를 통합하고, 품질을 보장하여 데이터 웨어하우스나 데이터 레이크에 적재하는 것입니다. 예를 들어, 여러 시스템에서 고객 정보를 통합하여 분석하는 경우를 들 수 있다. -
처리방식
Batch : 주기적으로 실행되며, 대량의 데이터를 한 번에 처리한다. 예를 들어, 매일 자정에 실행되는 스크립트를 예로 들 수 있다.
ETL : 데이터의 추출, 변환, 적재가 포함되며, 이 과정에서 Batch 작업이 사용될 수 있습니다. ETL 프로세스는 데이터 품질 및 통합을 중시한다. -
실시간 처리
Batch : 실시간 처리에 적합하지 않고, 특정 주기로 실행된다는 특징이 있다.
ETL : 실시간 ETL( 또는 ELT ) 방식을 사용할 수 있고 이는 데이터가 생성되는 즉시 반영할 수 있다.
Batch, ETL은 데이터 처리에 핵심적인 역할을 하지만 그 목적과 처리방식에 따라 차이점을 보인다.
ETL 작업 가운데 Batch작업은 하나의 작업이라고 볼 수 있지만, Batch 작업은 대량의 데이터 처리에 목적을 두고, ETL은 데이터의 통합과 품질에 중점을 둔다는 점이 다르다면 다르다고 볼 수 있을 것 같다.
ETL작업의 핵심적인 디자인패턴.
- 데이터 정합성
데이터를 처리할 때 가장 먼저 고려해야하는 점은 데이터의 정합성이다.
데이터의 정합성이란, 어떤 데이터의 조합이 있을 때 각 데이터의 조합을 통해 생성한 결과 데이터가 논리적으로 맞아야 한다는 것을 의미한다.
실제로 운영할 때 데이터 정합성에 맞게 로직을 구현했더라도 특별한 상황에 의해 의도했던 데이터와 다른 형태의 데이터가 수집될 수 있다.
그렇기 때문에 데이터 정합성을 지키기 위해 데이터 파이프라인을 구현할 때 정합성 보장을 위한 작업을 해줘야 한다.
다음과 같은 예시 처럼 데이터 정합성을 보장하기 위한 절차를 밟을 수 있다.- 데이터 저장과정에서 네트워크 순단과 같은 원인으로 인해 "중복" 처리된 데이터를 이벤트를 특정 컬럼을 기준으로 중복 제거한다 ( ID 같은 값이 될 수 있다. )
- 특정 시간내에 동일한 유저로부터 동일하게 발생한 이벤트의 "중복" 을 제거한다. ( 특정 페이지 이동을 위해 사용자가 한번 눌러야하는데 실수로 2번 연달아 눌린경우 등이 이에 해당될 수 있다. )
- 저장할 때 Time partition에 맞지 않는 Tiemstamp 를 제거한다.
- 메타DB로부터 매핑할 수 없는 컬럼의 값을 가진 이벤트 등을 DROP,INVALID 등으로 처리한다.
개발자들이 위와 같이 데이터 정합성 보장을 위한 로직을 추가하여 데이터 정합성 체크할 수 있다.
- Idempotent
Idempotent란, 동일한 Input 은 항상,언제나 동일한 Output을 내뱉는 것을 의미한다.
피카츄 인형이 가득한 인형뽑기기계에서 피카츄 인형을 뽑는 경우 Idempotent 하다고 볼 수 있을까?
이는 그렇지 않다 언제나 피카츄 인형을 뽑을 수 없기 때문이다.
배치작업은 원본 데이터 소스만 있다면 언제든 재처리를 통해 데이터를 수집할 수 있다는 장점이 있다 하지만 재처리 시점마다 각각 다른 처리결과를 얻는다면 이 데이터 파이프라인은 신뢰할 수 있을까?
그렇지않다. 그렇기 때문에 idempotent한 데이터 파이프라인을 구현하여야만 한다.
이처럼 언제나 동일한 Input을 통해 동일한 Output 결과를 얻을 수 있는 것을 지켜주어야 데이터 파이프라인의 신뢰성이 올라갈 것이다.
